
As GPUs se tornaram parte essencial da infraestrutura moderna em nuvem. Com cada vez mais times adotando IA, machine learning e grandes modelos de linguagem (LLMs) para evoluir suas aplicações, o uso de GPU cresce em ritmo acelerado, e os custos de Kubernetes na nuvem para sustentar esses workloads acompanham essa curva. Essa tendência traz uma nova camada de complexidade ao gerenciamento de recursos no Kubernetes: a otimização da utilização de GPU.
"Ao contrário de outros recursos do Kubernetes, as requisições de GPU funcionam de um jeito diferente: ou o pod tem acesso à GPU inteira, ou não tem acesso nenhum. Sem alocação fracionada, é comum que as GPUs fiquem subutilizadas, gerando desperdício. Como as GPUs podem representar até 75% do custo de infraestrutura por hora, qualquer ineficiência se converte em prejuízo financeiro relevante. Por isso, eliminar a superalocação tem um impacto enorme e abre espaço para uma economia significativa", afirma Eli Birger, CTO da PerfectScale by DoiT. "Sem visibilidade do uso real da GPU, os Engineers ficam sem os insights necessários para fazer right-sizing dos workloads, aplicar estratégias avançadas de scheduling de pods e tomar decisões de infraestrutura orientadas por dados."
Para ajudar os times a vencer esses desafios, é com satisfação que apresentamos o GPU Visibility da PerfectScale by DoiT — o recurso que dá uma visão clara do uso de GPU nos seus clusters Kubernetes, ajudando a identificar ineficiências, fazer right-sizing dos workloads e tirar o máximo proveito dos recursos de GPU.
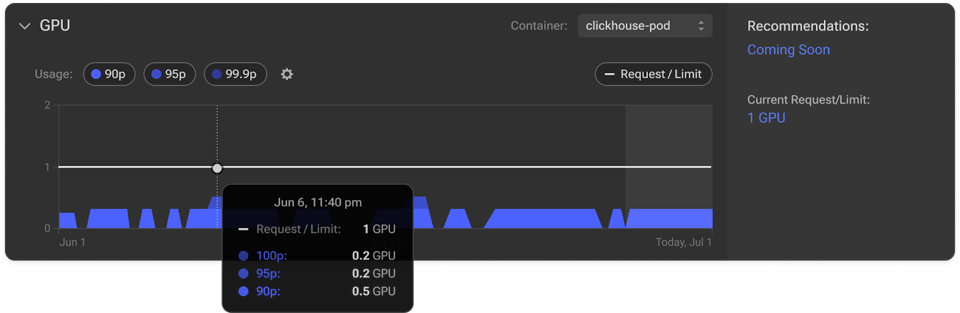
Vamos ver de perto como o GPU Visibility revela ineficiências e facilita a otimização do uso de GPU.
O que o GPU Visibility entrega?
O recurso de GPU do PerfectScale é uma solução robusta que coleta métricas de utilização de GPU e oferece visibilidade profunda no contexto do cluster inteiro. Essa visão permite analisar o ambiente Kubernetes com precisão e abre caminho para uma otimização certeira, baseada em dados.
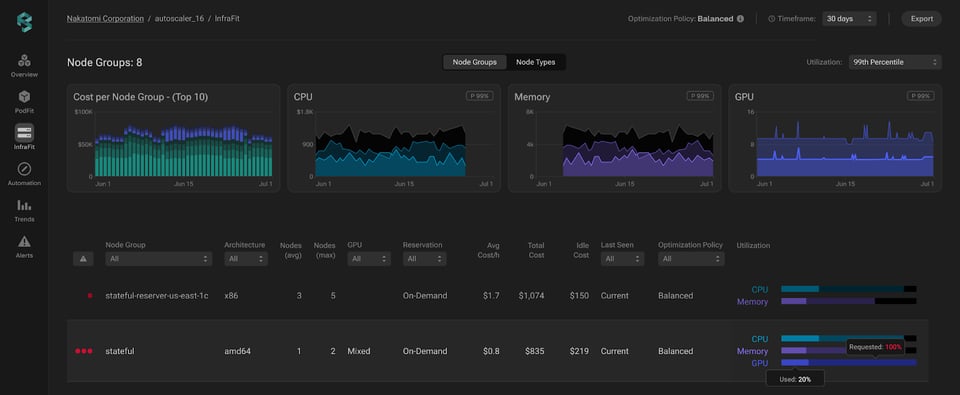
Acesse o Infrafit do PerfectScale para conferir insights detalhados sobre o uso de GPU dos seus node groups. O gráfico de utilização mostra com clareza o uso e as requisições de GPU em toda a infraestrutura. Essa visualização é especialmente útil para identificar rapidamente capacidade de GPU subutilizada ou ociosa, priorizar a otimização nas áreas mais críticas, reduzir desperdícios e ganhar eficiência de custo no geral.
Quando uma área problemática aparece, basta clicar no node group correspondente para abrir uma visão de infraestrutura mais detalhada. Esse nível de granularidade traz um detalhamento completo de cada instância do grupo, junto com as principais métricas de cada uma.
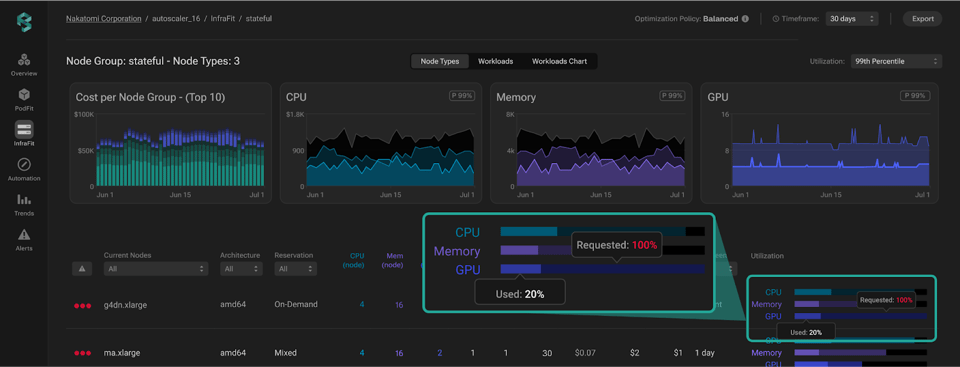
Depois de localizar o problema, o próximo passo é decidir como resolver. A plataforma ajuda a entender o que está acontecendo (GPUs sem uso pleno, workloads provisionados com mais recursos do que precisam ou instâncias rodando praticamente à toa) e a escolher a estratégia certa para cada caso. Você pode, por exemplo, fazer right-sizing das instâncias para encaixar melhor o workload, balancear a carga e melhorar o bin-packing, ou simplesmente desligar instâncias que não são necessárias.
Explorando cenários de uso
Right-sizing de instâncias de GPU
Em muitos casos, os workloads não precisam de toda a capacidade da máquina de GPU. Ao identificar instâncias subutilizadas, dá para trocar opções caras por máquinas menores e mais econômicas, mais adequadas à tarefa. O resultado é menos gasto desnecessário, sem comprometer o desempenho.
Para tomar decisões com confiança e embasadas em dados, é só usar o GPU Visibility do PerfectScale e identificar onde esse ajuste faz mais sentido.
Aproveitando a GPU ao máximo com GPU splitting
Migrar para instâncias de GPU menores costuma ser uma ótima saída para reduzir custos, mas nem sempre é a melhor ou a mais eficaz.
Alguns workloads, como pipelines de ML compartilhados, não escalam bem quando divididos em máquinas separadas e podem exigir um controle de recursos mais rigoroso. Nesses casos, instâncias menores sozinhas talvez não entreguem o desempenho, a eficiência ou a flexibilidade que você precisa.
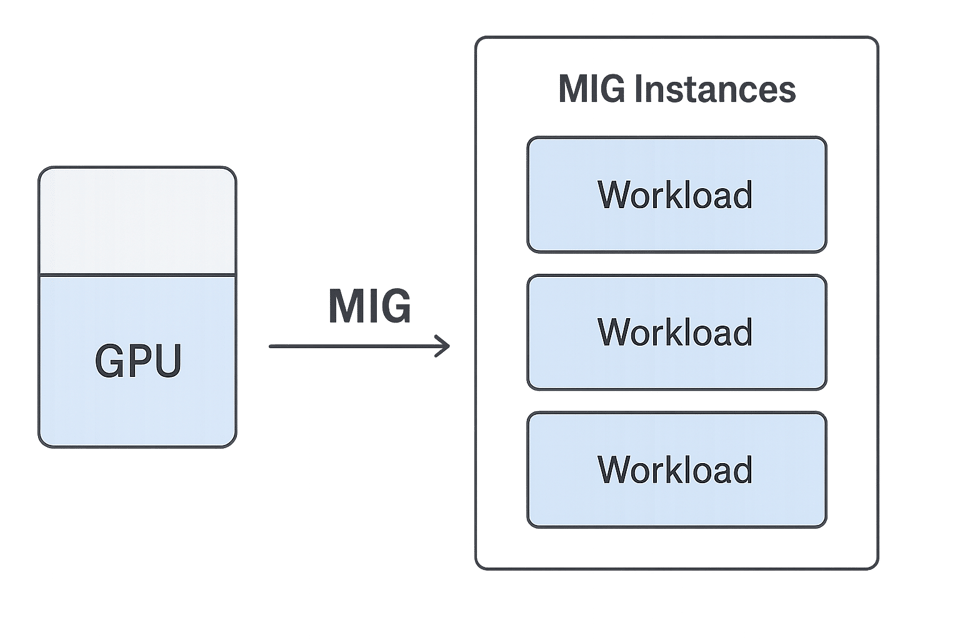
É aí que entra a Multi-Instance GPU (MIG) da NVIDIA. A MIG permite dividir uma GPU física em várias unidades menores e isoladas, cada uma com seu próprio compute, memória e largura de banda. Esses pedaços funcionam como GPUs independentes, então você roda vários jobs pequenos ou paralelos ao mesmo tempo, sem conflitos.
O PerfectScale facilita identificar GPUs subutilizadas rodando workloads que não exigem toda a capacidade. Em vez de migrar para uma máquina menor, você mantém a GPU maior e divide em instâncias MIG, ajustando cada fatia ao que cada workload realmente precisa.
Mais eficiência com o KAI Scheduler
Algumas tarefas não precisam de GPU o tempo todo — é o caso de workloads efêmeros, jobs de CI/CD ou etapas de treinamento de modelo com longas esperas de CPU. Elas usam a GPU só por um curto período, e dedicar uma GPU inteira a cada um desses jobs significa jogar recursos e dinheiro fora.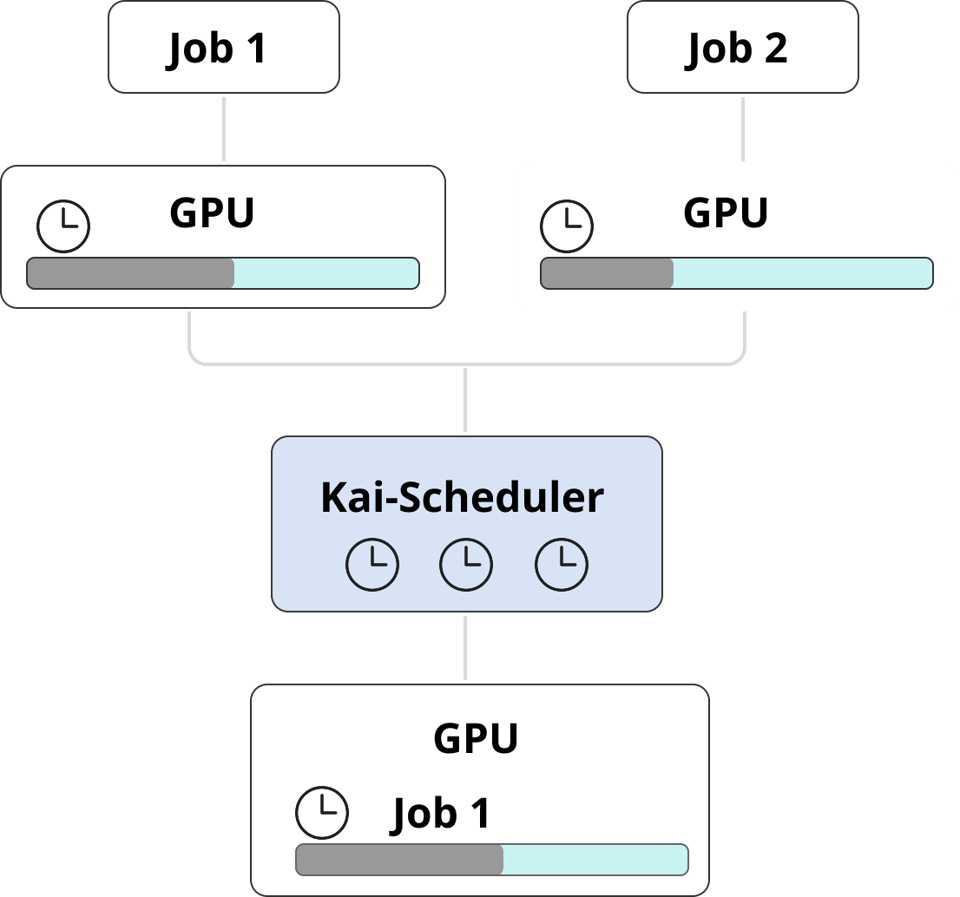
Com o GPU Visibility do PerfectScale, fica simples flagrar esses padrões — workloads que não usam por completo a GPU alocada. Identificou? Aí é só implementar o Kai-Scheduler para consolidar vários jobs em uma única GPU, maximizando o uso e reduzindo custos sem abrir mão do desempenho.
Você viu como o PerfectScale ajuda a descobrir desperdícios de GPU e a aplicar estratégias inteligentes de otimização. Agora é hora de colocar isso em prática!
Mergulhe no nosso Portal de Documentação ou agende uma sessão técnica com nosso time para um suporte especializado.
Ainda não usa o PerfectScale? Comece de graça hoje mesmo e simplifique sua jornada de otimização no K8s.