
GPUs sind aus moderner Cloud-Infrastruktur nicht mehr wegzudenken. Da immer mehr Teams auf KI, Machine Learning und Large Language Models (LLMs) setzen, um ihre Anwendungen weiterzuentwickeln, steigt die GPU-Nutzung rasant – und damit auch die Kubernetes-Kosten für den Betrieb solcher workloads. Dieser Trend bringt eine neue Komplexitätsebene ins Kubernetes-Ressourcenmanagement: die Optimierung der GPU-Auslastung.
"GPU-Anforderungen funktionieren anders als andere Kubernetes-Ressourcen: Ein Pod erhält entweder Zugriff auf eine komplette GPU – oder gar keinen. Ohne anteilige Zuweisung bleiben GPUs häufig unterausgelastet, und es entsteht GPU-Waste. Da GPUs bis zu 75 % der stündlichen Infrastrukturkosten ausmachen können, schlägt jede Ineffizienz finanziell deutlich zu Buche. Wer Überallokation beseitigt, kann daher enorme Einsparungen realisieren", sagt Eli Birger, CTO von PerfectScale by DoiT. "Ohne Einblick in die tatsächliche GPU-Auslastung fehlt Engineers schlicht die Grundlage, um workloads via Right-Sizing passgenau zu dimensionieren, ausgefeilte Pod-Scheduling-Strategien umzusetzen und Infrastrukturentscheidungen datenbasiert zu treffen."
Damit Teams diese Herausforderungen meistern, freuen wir uns, GPU Visibility von PerfectScale by DoiT vorzustellen – die Funktion, die Ihnen einen klaren Überblick über die GPU-Nutzung in Ihren Kubernetes-Clustern verschafft. So decken Sie Ineffizienzen auf, dimensionieren workloads passgenau und schöpfen Ihre GPU-Ressourcen voll aus.
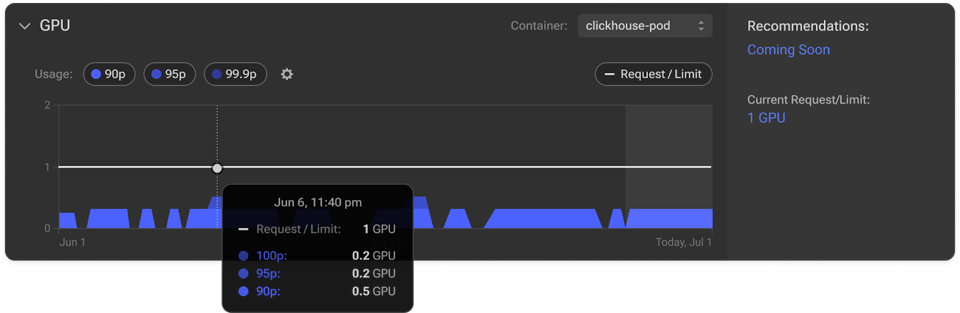
Schauen wir uns genauer an, wie GPU Visibility Ineffizienzen aufdeckt und die GPU-Auslastung mühelos optimiert.
Was leistet GPU Visibility?
Die GPU-Funktion von PerfectScale ist eine leistungsstarke Lösung: Sie erfasst Metriken zur GPU-Auslastung und liefert tiefe Einblicke im Kontext des gesamten Clusters. Damit lässt sich die Kubernetes-Umgebung präzise analysieren – die Basis für datenbasierte Optimierung mit echter Wirkung.
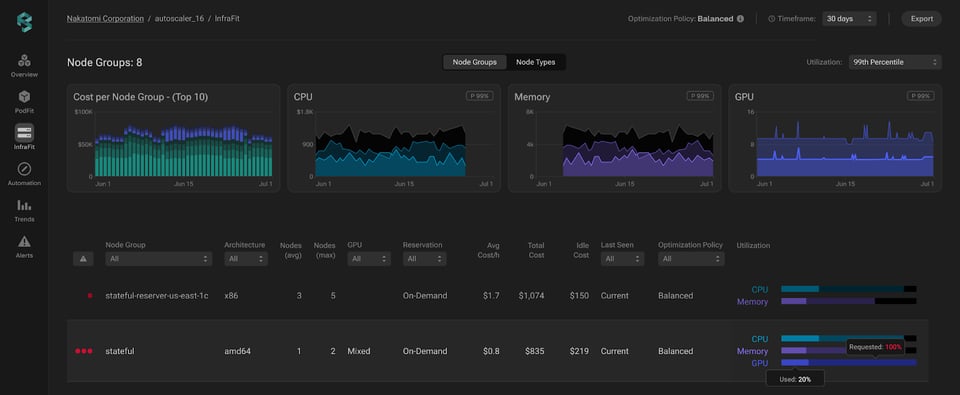
Öffnen Sie Infrafit in PerfectScale, um detaillierte Einblicke in die GPU-Auslastung Ihrer Node Groups zu erhalten. Das Auslastungsdiagramm zeigt klar, wie sich GPU-Nutzung und -Anforderungen in Ihrer Infrastruktur verteilen. Damit erkennen Sie unterausgelastete oder ungenutzte GPU-Kapazitäten auf einen Blick, setzen Optimierungsmaßnahmen gezielt dort an, wo sie am meisten bringen, reduzieren GPU-Waste und steigern die Kosteneffizienz insgesamt.
Sobald ein Problembereich identifiziert ist, klicken Sie einfach auf die jeweilige Node Group und wechseln in eine detailliertere Infrastrukturansicht. Diese Granularität liefert eine umfassende Aufschlüsselung der einzelnen Instanzen innerhalb der Gruppe samt der wichtigsten Kennzahlen pro Instanz.
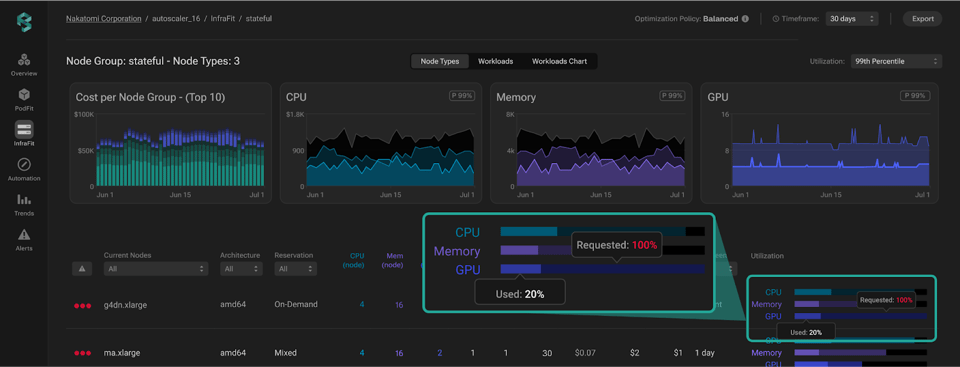
Ist das Problem dank dieser Transparenz erkannt, geht es im nächsten Schritt darum, die richtige Lösung zu wählen. Die Plattform zeigt Ihnen genau, wo der Schuh drückt: GPUs werden nicht voll genutzt, einzelne workloads sind mit mehr Ressourcen ausgestattet als nötig, oder bestimmte Instanzen laufen weitgehend im Leerlauf. Auf dieser Basis wählen Sie die passende Strategie – etwa Right-Sizing der Instanzen für einen besseren Fit zum Workload, eine gleichmäßigere Lastverteilung mit verbessertem Bin-Packing oder das Abschalten nicht benötigter Instanzen.
Anwendungsszenarien im Überblick
Right-Sizing von GPU-Instanzen
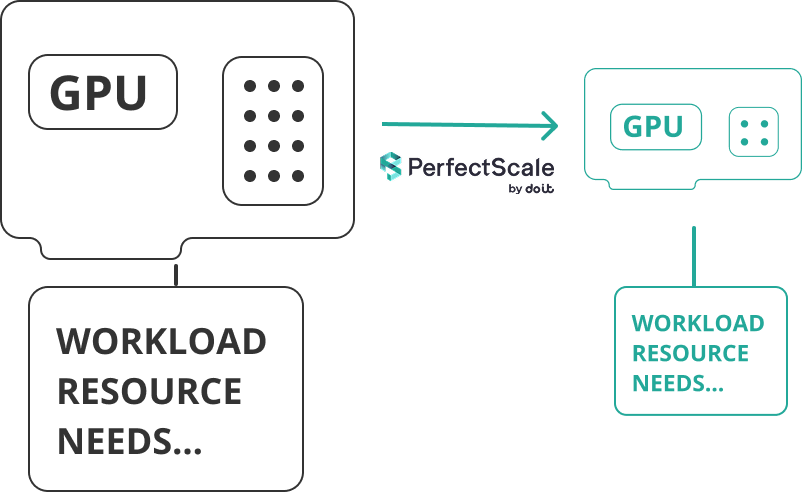
In vielen Fällen brauchen workloads gar nicht die volle Kapazität der GPU-Maschine. Wer unterausgelastete Instanzen erkennt, kann teure Instanzen durch kleinere, kosteneffizientere ersetzen, die besser zur Aufgabe passen. So senken Sie unnötige Ausgaben, ohne bei der Performance Abstriche zu machen.
Für fundierte, datengestützte Entscheidungen nutzen Sie die GPU Visibility von PerfectScale und sehen sofort, wo sich eine solche Anpassung am meisten lohnt.
Maximale Auslastung durch GPU-Splitting
Der Wechsel auf kleinere GPU-Instanzen ist häufig ein guter Hebel zur Kostensenkung – aber nicht immer der beste oder wirksamste.
Manche workloads, etwa gemeinsam genutzte ML-Pipelines, lassen sich schlecht auf separate Maschinen verteilen und brauchen eine engere Ressourcenkontrolle. In solchen Fällen liefern kleinere Instanzen allein womöglich nicht die gewünschte Leistung, Effizienz oder Flexibilität.
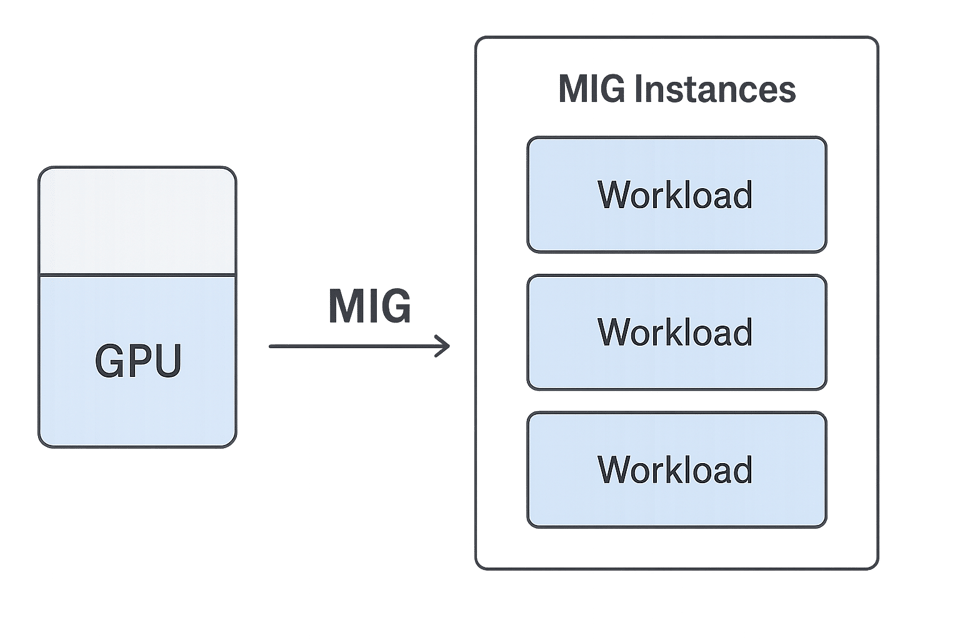
Hier kommt NVIDIAs Multi-Instance GPU (MIG) ins Spiel. Mit MIG lässt sich eine physische GPU in mehrere kleinere, isolierte Einheiten aufteilen – jede mit eigener Compute-Leistung, eigenem Speicher und eigener Bandbreite. Diese Einheiten verhalten sich wie eigenständige GPUs, sodass Sie mehrere kleine oder parallele Jobs gleichzeitig und konfliktfrei ausführen.
PerfectScale macht es leicht, unterausgelastete GPUs zu identifizieren, auf denen workloads ohne hohen Kapazitätsbedarf laufen. Statt auf eine kleinere Maschine zu wechseln, behalten Sie die größere GPU und teilen sie in MIG-Instanzen auf – jede Slice exakt auf die jeweilige Workload-Anforderung zugeschnitten.
Mehr Effizienz mit dem KAI Scheduler
Manche Aufgaben brauchen nicht durchgehend eine GPU – etwa kurzlebige workloads, CI/CD-Jobs oder Trainingsschritte mit langen CPU-Wartezeiten. Sie greifen nur kurz auf die GPU zu, und jedem einzelnen Job eine eigene GPU zuzuweisen, verschwendet massiv Ressourcen und Budget.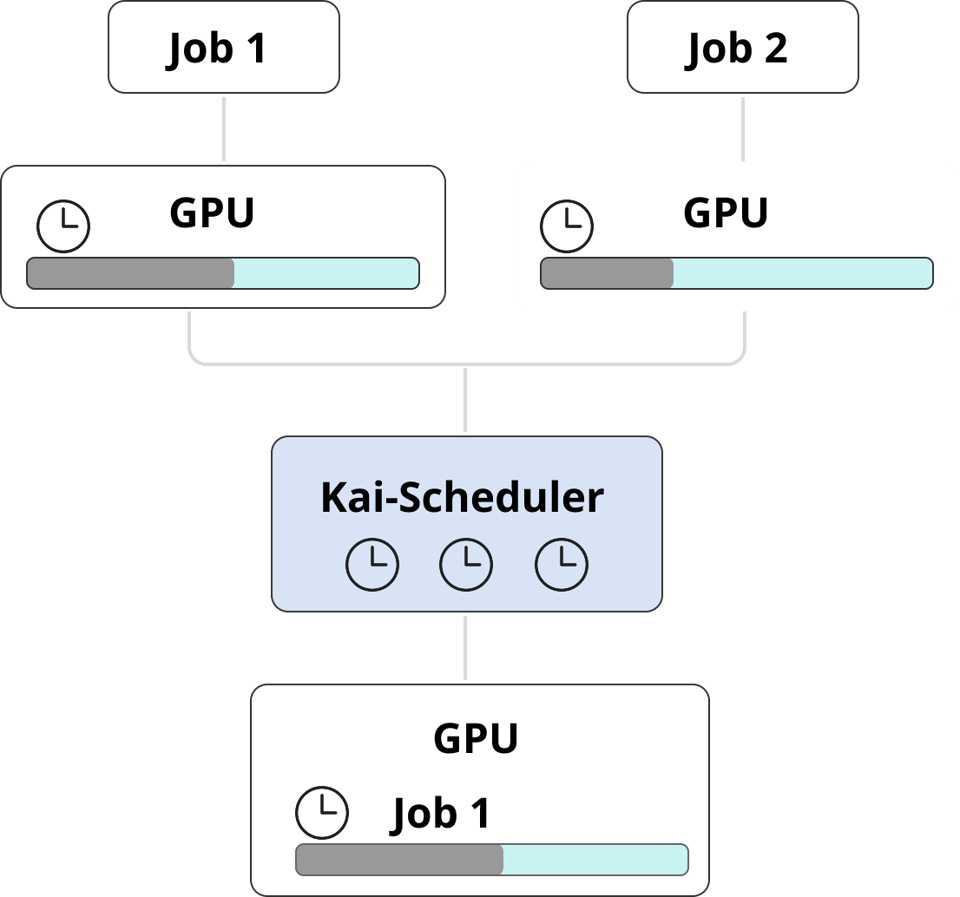
Mit der GPU Visibility von PerfectScale erkennen Sie genau solche Muster mühelos – etwa workloads, die ihre zugewiesene GPU nicht ausschöpfen. Sind sie identifiziert, können Sie den Kai-Scheduler einsetzen, um mehrere Jobs auf einer einzigen GPU zu bündeln, die Auslastung zu maximieren und Kosten zu senken – ohne Abstriche bei der Performance.
Sie haben gesehen, wie PerfectScale GPU-Waste sichtbar macht und smarte Optimierungsstrategien ermöglicht. Zeit, das in die Praxis zu bringen!
Tauchen Sie tiefer in unser Documentation Portal ein oder vereinbaren Sie eine technische Session mit unserem Team – wir unterstützen Sie persönlich.
Sie nutzen PerfectScale noch nicht? Starten Sie noch heute kostenlos und vereinfachen Sie Ihre K8s-Optimierung.