
Las GPU se han vuelto parte esencial de la infraestructura cloud moderna. A medida que más equipos adoptan IA, machine learning y modelos de lenguaje de gran tamaño (LLM) para hacer evolucionar sus aplicaciones, el uso de GPU crece a toda velocidad, y con él los costos cloud de Kubernetes para sostener esos workloads. Esta tendencia agrega una nueva capa de complejidad a la gestión de recursos en Kubernetes: la optimización del uso de GPU.
"A diferencia de otros recursos de Kubernetes, las solicitudes de GPU se manejan de forma distinta: un pod accede a una GPU completa o a ninguna. Sin asignación fraccionada, las GPU suelen quedar subutilizadas, lo que se traduce en pérdida de GPU. Como las GPU pueden representar hasta el 75% del costo de infraestructura por hora, cualquier ineficiencia se convierte en una pérdida financiera relevante. Por eso, eliminar la sobreasignación puede tener un impacto enorme y generar ahorros significativos", comentó Eli Birger, CTO de PerfectScale by DoiT. "Sin visibilidad sobre el uso real de la GPU, los Engineers no tienen la información que necesitan para hacer right-sizing de los workloads, aplicar estrategias avanzadas de scheduling de pods y tomar decisiones de infraestructura basadas en datos".
Para ayudar a los equipos a superar estos retos, nos entusiasma presentar GPU Visibility de PerfectScale by DoiT: la funcionalidad que te muestra con claridad el uso de GPU en todos tus clústeres de Kubernetes y te ayuda a detectar ineficiencias, hacer right-sizing de los workloads y sacarle el máximo provecho a tus recursos de GPU.
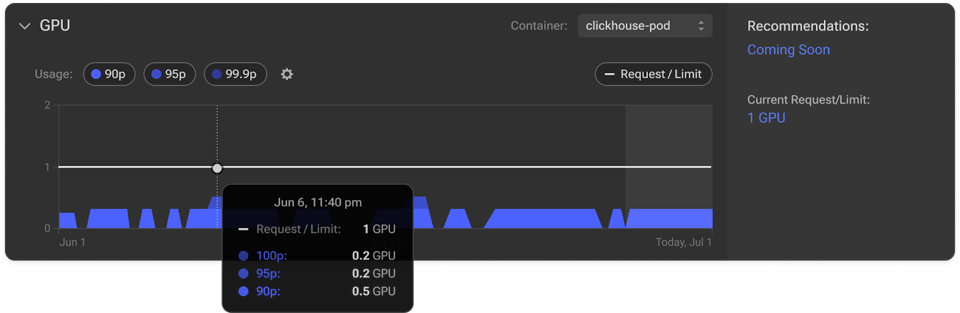
Veamos en detalle cómo GPU Visibility ayuda a descubrir ineficiencias y a optimizar el uso de la GPU sin complicaciones.
¿Qué te aporta GPU Visibility?
La funcionalidad de GPU de PerfectScale es una solución potente que recopila métricas de uso y ofrece visibilidad profunda en el contexto de todo el clúster. Esta vista permite analizar con precisión el entorno de Kubernetes y abre la puerta a una optimización exacta basada en datos.
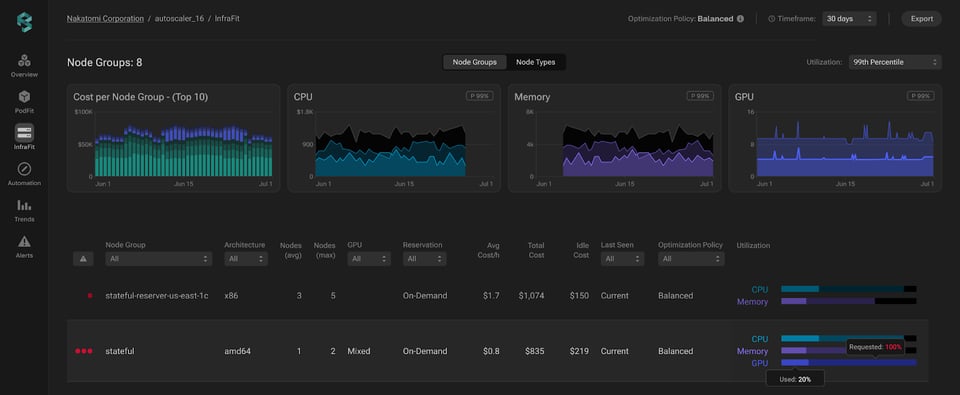
Entra a Infrafit de PerfectScale y accede al detalle de uso de GPU de tus grupos de nodos. El gráfico de utilización muestra con claridad cómo se usan y se solicitan las GPU en toda tu infraestructura. Esta vista resulta especialmente útil para detectar de un vistazo capacidad de GPU subutilizada o inactiva, priorizar la optimización en las áreas más críticas, reducir la pérdida de GPU y mejorar la eficiencia de costos en general.
Cuando se identifica un área problemática, basta con hacer clic en el grupo de nodos correspondiente para entrar a una vista de infraestructura más detallada. Este nivel de granularidad ofrece un desglose completo de cada instancia del grupo, junto con sus métricas clave.
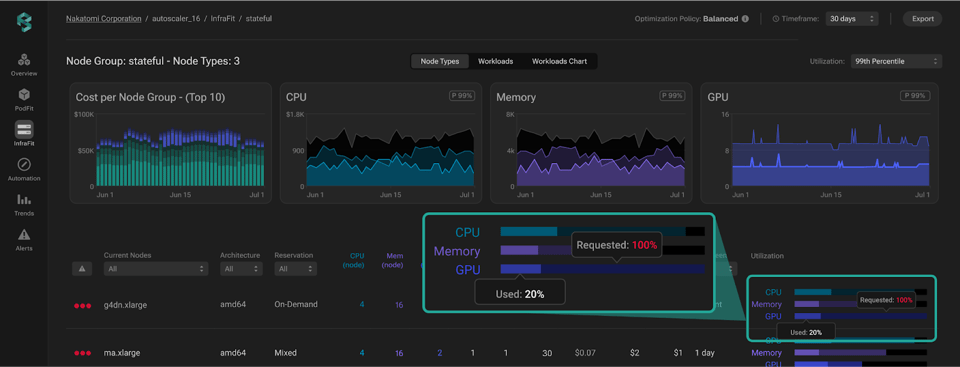
Una vez detectado el problema, el siguiente paso es decidir cómo resolverlo. La plataforma te ayuda a entender qué está fallando (GPU que no se aprovechan al máximo, workloads aprovisionados con más recursos de los que necesitan o instancias prácticamente ociosas) y a elegir la estrategia adecuada. Por ejemplo, puedes hacer right-sizing de las instancias para que se ajusten mejor al workload, balancear la carga y mejorar el bin-packing, o apagar las instancias que no se necesitan.
Casos de uso
Right-sizing de instancias de GPU
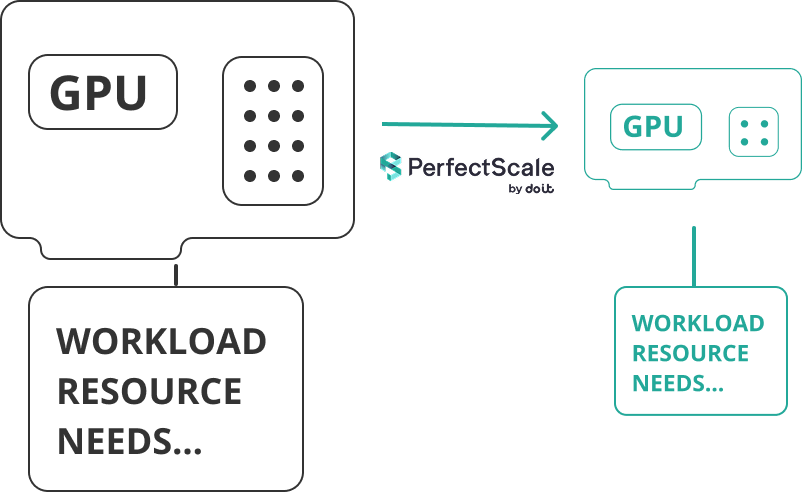
Muchas veces, los workloads no necesitan toda la capacidad de la máquina con GPU. Al identificar las instancias subutilizadas, puedes reemplazar las más costosas por otras más pequeñas y rentables que se ajusten mejor a la tarea. Así se reduce el gasto innecesario sin dejar de cumplir con los requisitos de rendimiento.
Para tomar decisiones seguras y basadas en datos, puedes apoyarte sin fricción en la visibilidad de GPU de PerfectScale y descubrir dónde tiene más sentido este ajuste.
Maximizar el uso con GPU splitting
Cambiar a instancias de GPU más pequeñas suele ser una buena forma de reducir costos, pero no siempre es el enfoque más adecuado ni el más efectivo.
Algunos workloads, como los pipelines de ML compartidos, no escalan bien al dividirse entre máquinas separadas y pueden requerir un control más estricto de los recursos. En esos casos, las instancias más pequeñas por sí solas no siempre ofrecen el rendimiento, la eficiencia o la flexibilidad que se busca.
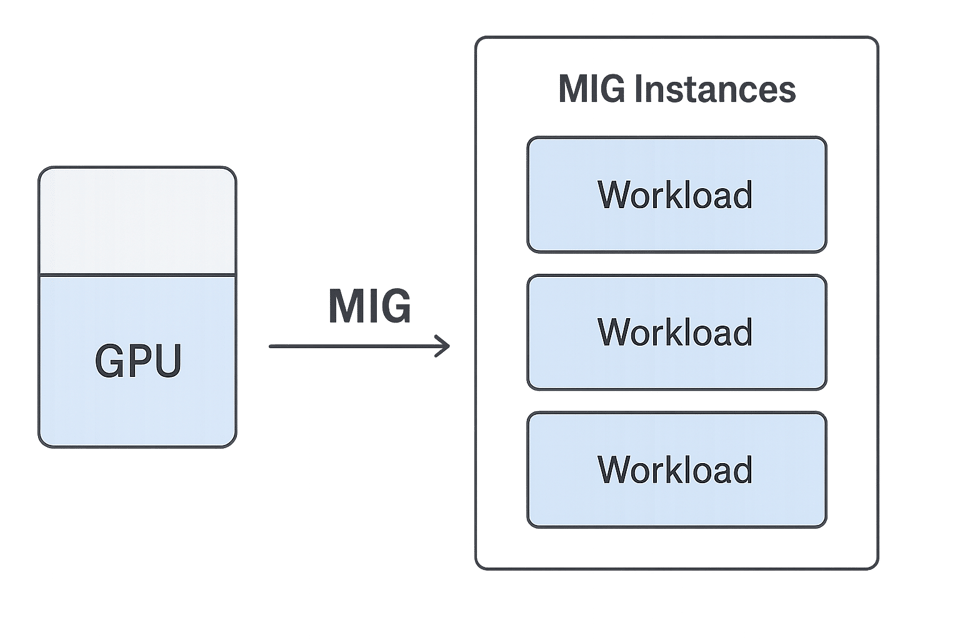
Aquí es donde entra Multi-Instance GPU (MIG) de NVIDIA. MIG te permite dividir una GPU física en varias unidades más pequeñas y aisladas, cada una con su propio cómputo, memoria y ancho de banda. Estas porciones funcionan como GPU independientes, por lo que puedes ejecutar varios trabajos pequeños o en paralelo al mismo tiempo y sin conflictos.
PerfectScale facilita ubicar las GPU subutilizadas que ejecutan workloads que no necesitan toda la capacidad. En lugar de cambiar a una máquina más pequeña, puedes conservar la GPU grande y dividirla en instancias MIG, ajustando cada porción a las necesidades específicas de cada workload.
Más eficiencia con KAI Scheduler
Algunas tareas no necesitan una GPU todo el tiempo: workloads efímeros, jobs de CI/CD o pasos de entrenamiento de modelos con largas esperas de CPU. Solo la usan por un período corto, y dedicarle una GPU exclusiva a cada una desperdicia recursos y dinero.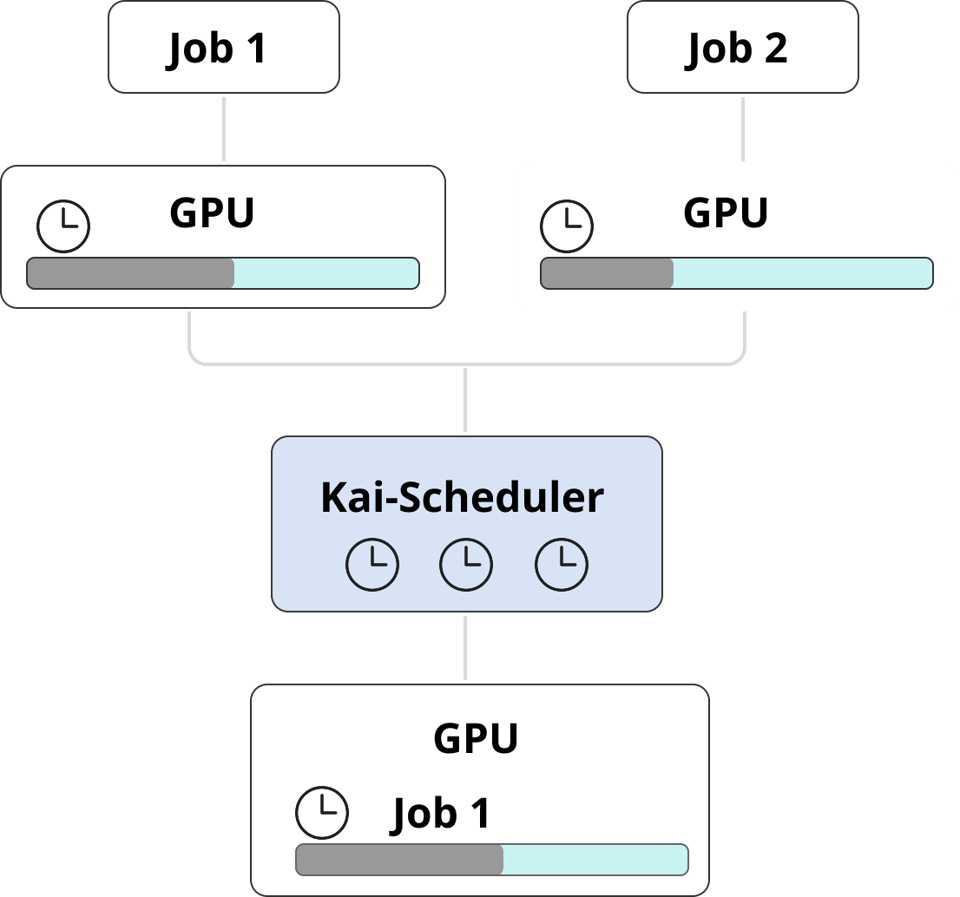
Con la visibilidad de GPU de PerfectScale puedes detectar fácilmente este tipo de patrones, como workloads que no aprovechan por completo la GPU asignada. Una vez identificados, puedes implementar Kai-Scheduler para consolidar varios jobs en una sola GPU, maximizando el uso y reduciendo costos sin sacrificar rendimiento.
Ya viste cómo PerfectScale ayuda a descubrir la pérdida de GPU y a aplicar estrategias inteligentes de optimización. ¡Es momento de poner esa información a trabajar!
Explora a fondo nuestro Portal de Documentación o agenda una sesión técnica con nuestro equipo para recibir asesoría experta.
¿Aún no usas PerfectScale? Empieza gratis hoy mismo y simplifica la optimización de tus K8s.