Découvrez comment déployer des LLM sur Google Cloud avec les experts IA de DoiT. Conseils pratiques sur le choix du modèle, la maîtrise des coûts, la mise en œuvre du RAG avec Google Workspace, les stratégies de test d'API et un guide pas à pas pour votre parcours GenAI.

De plus en plus d'entreprises cherchent à intégrer les Large Language Models (LLM) à leurs produits et services, et nous recevons régulièrement des questions sur :
- Comment choisir le bon modèle de fondation pour votre cas d'usage,
- Comment maîtriser les coûts unitaires de votre déploiement GenAI, et
- L'observabilité des LLM après mise en production
...ou tout simplement par où commencer un projet LLM.
C'est pourquoi nous avons organisé une Q&R en direct à destination des clients Google Cloud, à différents stades de maturité GenAI. Des entreprises encore en phase d'expérimentation comme d'autres déjà en production se sont jointes à la session pour interroger trois experts AI/ML de DoiT (Eduardo Mota, Jared Burns, Sascha Heyer) sur tous les aspects de la mise en œuvre des LLM sur Google Cloud.
Nous avons synthétisé les enseignements clés ci-dessous, des premiers pas avec la GenAI sur Google Cloud aux sujets plus avancés, comme l'exploitation des données Google Workspace de votre entreprise pour la Retrieval-Augmented Generation (RAG).
Se lancer dans la GenAI sur Google Cloud
Question initiale : Comment une entreprise peut-elle se lancer dans la GenAI sur Google Cloud ?
Pour répondre, Eduardo a présenté le GenAI Implementation Journey que nous suivons pour aider les entreprises à concevoir des solutions GenAI sur mesure dans le cadre de nos GenAI Accelerators.
Ce parcours couvre toutes les étapes, de l'idéation à la mise à l'échelle en production, sans oublier l'observabilité tout au long du processus.
Nous nous sommes concentrés ici sur les phases d'idéation, de prompt design et de PoC.
Idéation des cas d'usage GenAI
Lors d'une réflexion sur des implémentations basées sur les LLM, il est essentiel d'aligner ce que vous cherchez à construire sur vos objectifs métier.
Quelques questions pour stimuler la réflexion :
- Classification : Si je pouvais identifier ______ dans ________, je pourrais ________
- Ex. Si je pouvais détecter les rayures sur une voiture à partir d'images de caméras de surveillance, je pourrais améliorer le processus de check-in et de check-out de notre flotte de location.
- Personnalisation : Si je savais quels ________ sont les plus susceptibles de _________, je pourrais _______
- Ex. Si je savais quels services sont les plus à même de fidéliser un client, je pourrais proposer des offres de rétention personnalisées.
- Systèmes experts : Si je pouvais identifier ________ avec _________, je pourrais ___________
- Ex. Si je pouvais identifier le persona client à partir de son historique de données, je pourrais lui proposer un accompagnement sur mesure.
De manière générale, lors de la recherche d'idées d'implémentation GenAI, nous conseillons aux entreprises de raisonner en termes d'expériences personnalisées plutôt que de processus génériques.
Par exemple :
- Générique : nous voulons permettre aux clients de commander à manger en ligne avec rachat de commandes précédentes, et générer des up-sells fondés sur des personas marketing.
- Personnalisé : en exploitant les données individuelles du client et les informations du restaurant, nous pouvons proposer une expérience de commande de qualité qui réduit le temps de commande et génère des up-sells à forte valeur ajoutée.
Si vous êtes davantage un décideur métier qu'un profil technique, Google Cloud propose également GenAI Navigator, qui vous pose une série de questions selon trois axes (Stratégie, Infrastructure et Compétences) afin de vous recommander la meilleure approche pour vous lancer dans la GenAI sur Google Cloud.
Prompt design pour les LLM
Une fois votre idée précisée, l'étape suivante consiste à expérimenter des prompts dans Vertex AI Studio — vous pouvez même bénéficier de 300 $ de crédits gratuits, voire davantage via des programmes comme l'AI Startup program de Google Cloud.
Mais il ne s'agit pas d'expérimenter pour expérimenter. Vous devez avoir un objectif précis en tête et suivre les étapes clés du processus de prompt design qu'Eduardo a mises en avant :
Définir le résultat attendu : formulez clairement ce que votre modèle doit produire. Cela peut aller de résultats de classification à des recommandations personnalisées ou à des analyses complexes.
Mettre en place des mesures de sécurité : installez des garde-fous face aux risques potentiels, comme l'injection de prompt et les sorties LLM erronées. Nous avons traité ces risques en détail dans un épisode du podcast Cloud Masters consacré aux risques de sécurité des LLM et aux stratégies d'atténuation :
Identifier le contexte requis pour la sortie souhaitée : demandez-vous de quelles informations le modèle a besoin — données, éléments de contexte, instructions spécifiques — pour produire le résultat attendu.
Créer 2 ou 3 prompts avec différentes techniques : testez des approches comme le few-shot learning, le chain-of-thought reasoning ou les approches multi-prompt. Chaque technique peut produire des résultats différents : il vaut la peine d'explorer plusieurs méthodes.
Évaluer les prompts avec différents modèles : vous avez accès à un large éventail de modèles dans Vertex AI Studio. Testez-en plusieurs ! Vous comprendrez ainsi comment chacun réagit à vos prompts et pourrez optimiser performance et précision.
Preuve de concept (PoC) GenAI
Une fois vos prompts éprouvés, l'étape suivante consiste à développer une preuve de concept. Eduardo a mis en avant plusieurs prérequis pour un PoC réussi :
- Définir des critères de succès clairs
- Constituer un groupe de test d'au moins 10 utilisateurs
- Tirer parti des services managés Google comme text-bison, Gemini, Cloud Functions, etc.
- Recueillir les retours des utilisateurs
- Définir des indicateurs de performance
- Établir des benchmarks de performance
Comme Eduardo l'a expliqué à Data Science Central, les retours de votre groupe de test initial sont essentiels. Vous voulez recueillir les retours des utilisateurs, même lorsque l'expérience n'a pas été positive. Assurez-vous d'avoir défini des benchmarks standards, puis surveillez chaque entrée et chaque sortie produites par votre GenAI. Rien qu'en évaluant ces éléments, vous pouvez identifier les ajustements de workloads nécessaires pour passer à la vitesse supérieure. L'objectif : itérer rapidement à partir des retours pour combler les écarts dans le parcours client.
Dans un précédent épisode du podcast Cloud Masters, Sascha et Eduardo ont également expliqué pourquoi il est important d'avoir une observabilité en place pour suivre les entrées, sorties et requêtes des LLM.
Si vous voulez mettre la main à la pâte rapidement avec la GenAI mais n'êtes pas encore prêt à développer un PoC sur vos propres données, Google Cloud propose les solutions Jump Start.
Il s'agit de déploiements open-source en un clic qui :
- Fournissent une infrastructure as code prête à l'emploi via un dépôt GitHub
- Permettent un déploiement simple dans votre propre projet
- Offrent une architecture end-to-end complète, à explorer et à modifier
Par exemple, le schéma ci-dessous illustre l'architecture de l'infrastructure applicative pour une solution GenAI Knowledge Base issue du Jump Start correspondant de Google Cloud :

Générer des sorties JSON avec Vertex AI
Question initiale : Comment obtenir des réponses LLM en JSON avec un format clairement défini ?
Les sorties des LLM sont souvent non structurées. Si cette flexibilité peut être utile pour des tâches créatives ou conversationnelles, elle devient problématique dès qu'il s'agit de bâtir des applications en production qui doivent traiter ces sorties de manière programmatique.
Imaginez devoir construire un système de recommandation produit pour un site e-commerce où chaque suggestion doit comporter des attributs précis comme le prix, la catégorie et la disponibilité, à partir de données non structurées. Ou encore un système de support client qui doit extraire les détails du ticket, le niveau de priorité et les actions suggérées dans un format cohérent.
Dans ces scénarios, obtenir des réponses dans un format JSON structuré devient indispensable. Sans sorties structurées, il faudrait une logique de parsing complexe, susceptible de casser à la moindre variation du format de réponse du LLM.
Au moment où la question a été posée, Google Cloud venait de lancer Controlled generation en private preview, qui permet aux développeurs de spécifier précisément les formats de sortie de leurs réponses LLM. Depuis le 5 septembre 2024, Gemini 1.5 Pro et Flash prennent pleinement en charge Controlled generation.
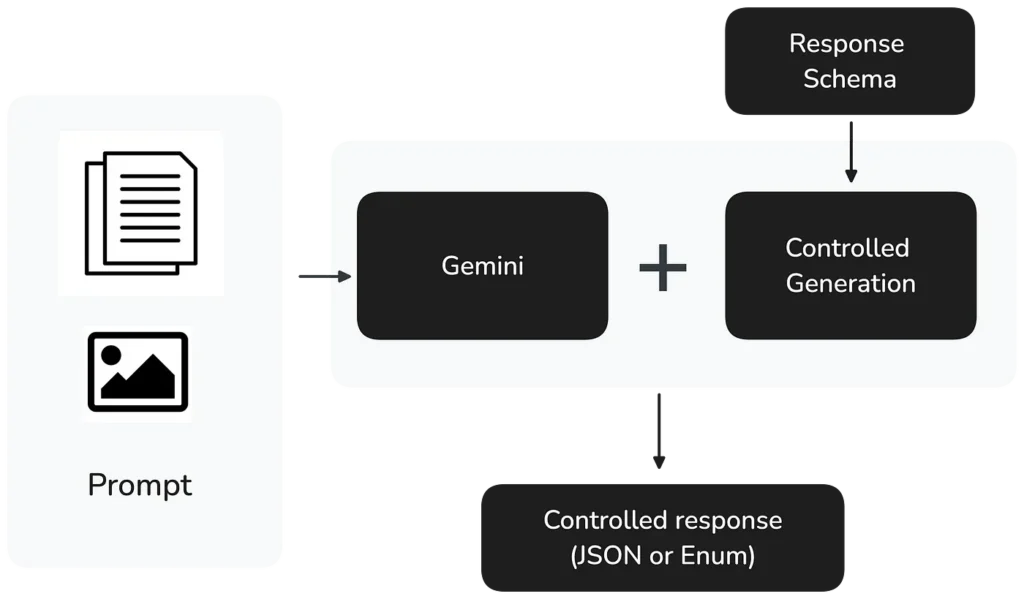
La mise en œuvre est simple : les développeurs peuvent spécifier :
- Un type MIME de réponse pour garantir une sortie JSON ou Enum valide
- Un schéma de réponse pour définir précisément la structure attendue
Sascha détaille Controlled generation dans son article de blog : si vous souhaitez plonger dans un notebook Google Colab et expérimenter avec du code, jetez-y un œil.
Mettre en œuvre le RAG avec les données Google Workspace
Question initiale : Existe-t-il un moyen d'entraîner des LLM Google Cloud sur des sous-ensembles de nos données Google Workspace ? Par exemple, comment entraîner un LLM à partir de My Drive, d'un Drive partagé ou d'un dossier, puis interroger les informations contenues dans ce jeu de données ? Je voudrais éviter de copier toutes les données dans GCS pour l'entraînement.
La Retrieval Augmented Generation (RAG) est une technique qui permet d'enrichir les réponses des LLM en y intégrant des informations extérieures aux données d'entraînement du modèle. Plutôt que de s'appuyer uniquement sur ces données, le RAG va chercher des informations pertinentes dans les documents et données que vous fournissez, et s'en sert pour produire des réponses plus précises et contextuelles.
Une application particulièrement utile du RAG en entreprise consiste à l'intégrer aux données Google Workspace (Docs, Sheets, Drive, etc.). Quelques cas d'usage :
- Créer une base de connaissances alimentée par l'IA à partir de la documentation interne
- Construire des systèmes de support client qui s'appuient sur la documentation produit stockée dans Drive
- Développer des outils de recherche internes capables de comprendre et de résumer le contenu de plusieurs documents Workspace
Par exemple, une équipe commerciale pourrait utiliser le RAG pour retrouver et résumer rapidement des études de cas pertinentes dans son Drive ; les RH, de leur côté, pourraient bâtir un système qui répond aux questions des collaborateurs en s'appuyant sur les documents de politique interne.
Comme Jared l'a expliqué dans l'extrait ci-dessous, Google Cloud propose plusieurs options pour mettre en œuvre le RAG dans Vertex AI :
- Vertex AI Search : génère et stocke les embeddings pour la récupération de documents
- Retrievers personnalisés : construisez votre propre système de récupération
- LlamaIndex : un outil open-source adopté par Google comme solution RAG managée
Jared a ensuite montré comment mettre en œuvre le RAG sur des données Google Drive avec LlamaIndex. Plus précisément, il a :
- Créé un corpus RAG pour stocker les données documentaires
- Importé des fichiers depuis un dossier Google Drive contenant le rapport de résultats du T1 2024 d'Alphabet, parmi d'autres fichiers
- Vérifié l'import en contrôlant le nombre de fichiers importés
- Testé la fonctionnalité de retriever en posant la question : Quel a été le chiffre d'affaires d'Alphabet au T1 2024 ?
- Généré une réponse avec Gemini 1.0, qui a fidèlement rapporté le chiffre d'affaires d'Alphabet au T1 2024 — information directement extraite du rapport téléversé.
Simuler les réponses d'API pour tester les LLM
Question initiale : dans Vertex AI Agent Builder , est-il possible de simuler un appel d'outil à des fins de test ? Par exemple si l'API que nous comptons utiliser n'a pas encore été développée ?
Si les tests sont importants en règle générale dans le développement logiciel et la conception d'API, ils sont particulièrement critiques pour les applications basées sur les LLM en raison de leur nature probabiliste. Un même prompt peut générer des réponses différentes à chaque exécution, ce qui rend indispensable la mise en place d'environnements de test contrôlés capables de valider un comportement cohérent des agents.
En parallèle, tester des applications reposant sur des agents LLM personnalisés n'a rien d'évident. Ces agents doivent fréquemment interagir avec des API externes ; or s'appuyer sur de vrais appels d'API en phase de test entraîne des coûts, de la latence et d'éventuels problèmes de fiabilité liés aux limites de débit ou aux interruptions de service. De plus, les API externes peuvent renvoyer des réponses variables selon les données en temps réel, ce qui complique le test cohérent de scénarios spécifiques ou de cas limites.
Mettre en place des réponses d'API simulées (mocks) permet à vos développeurs de tester le comportement des agents dans un environnement contrôlé, et garantit des cycles de test fiables et efficaces.
Eduardo a présenté une approche simple pour simuler des réponses d'API avec Google Cloud Functions, en évoquant deux options de mise en œuvre :
Fonction mock dédiée
- Créer une Cloud Function dédiée qui sert d'API simulée
- Configurer l'agent pour qu'il appelle cette fonction mock pendant les tests
Mock en ligne
- Implémenter la réponse simulée directement dans la Cloud Function existante
- Renvoyer des réponses prédéfinies au lieu de réaliser de véritables appels d'API
Comme vous maîtrisez entièrement l'implémentation de la fonction, vous pouvez définir des réponses simulées qui reflètent la structure réelle de l'API, choisir quand renvoyer une réponse mock ou réelle, et garantir des formats de réponse cohérents pour le traitement par l'agent.
Le point principal à surveiller : vos réponses simulées doivent conserver la même structure et le même format que ceux que votre agent attend de la véritable API.
En mettant en place une simulation d'API rigoureuse, vous pouvez développer et tester vos agents basés sur les LLM plus efficacement, tout en gardant le contrôle sur leur environnement de test.
Transmettre des paramètres entre agents avec Vertex AI Agent Builder
Question initiale : Avec Agent Builder, comment transmettre de manière fiable des paramètres entre agents ?
Imaginez un système d'IA dans lequel plusieurs agents spécialisés doivent collaborer. L'un gère les demandes clients, un autre les informations de stock, et un troisième le traitement des commandes. Ces agents doivent partager les informations entre eux de manière fluide et fiable. C'est là qu'intervient la transmission de paramètres.
Par exemple, lorsqu'un client souhaite commander un produit, l'agent de service client doit transmettre l'identifiant produit à l'agent de stock pour vérifier la disponibilité, puis transmettre l'identifiant et la quantité à l'agent de traitement de commande. Maîtriser ce flux d'informations est crucial pour bâtir des systèmes d'IA efficaces.
Cependant, même si les agents IA sont globalement performants pour comprendre et partager des informations, leur nature probabiliste fait qu'ils peuvent occasionnellement mal gérer ces transmissions. Dans un contexte métier où la précision est critique, il faut s'assurer que ces échanges sont fiables à 100 %.
Eduardo a montré comment transmettre des paramètres entre agents avec Vertex AI Agent Builder, et a évoqué la mise en place d'une validation par code tout au long du flux pour garantir que les bons paramètres sont bien transmis.
Si Agent Builder de Vertex AI facilite la création d'agents IA capables de collaborer, la mise en place d'une validation rigoureuse des paramètres garantit que votre système fonctionne de manière fiable en conditions réelles. En implémentant un orchestrateur pour piloter la transmission des paramètres et en enrichissant vos agents d'exemples pertinents, vous pouvez construire des systèmes IA robustes qui partagent l'information de façon fiable.
Pensez à mettre en place une logique de validation complète et à conserver des journaux détaillés des opérations de transmission de paramètres. Cet investissement initial dans une gestion fiable des paramètres vous fera gagner un temps considérable à mesure que vos applications IA gagneront en complexité.
Conclusion
Nous avons couvert un peu plus de la moitié des questions posées lors de notre Q&R en direct sur la mise en œuvre des LLM sur Google Cloud. Que vous débutiez avec la GenAI ou cherchiez à optimiser une implémentation existante, ces éléments devraient vous fournir une base solide.
Pour l'ensemble des enseignements, y compris des sujets comme le traitement de documents, les bonnes pratiques LLM pour les applications natives iOS et la structuration de transcripts, consultez notre playlist YouTube complète de la session.
Mettre en œuvre des LLM sur Google Cloud, c'est combiner technologie et expertise humaine. La GenAI étant une technologie relativement récente, un accompagnement expérimenté permet d'éviter les écueils classiques et d'accélérer votre passage en production.
Si vous souhaitez être accompagné dans votre déploiement GenAI sur Google Cloud, contactez notre équipe d'experts AI/ML pour en savoir plus sur notre GenAI Accelerator pour Google Cloud : nous vous aidons à concevoir et à mettre à l'échelle vos applications basées sur les LLM en toute efficacité.