DoiTのAIエキスパートが解説する、Google CloudでのLLM実装の進め方。モデル選定からコスト管理、Google WorkspaceとのRAG連携、APIテスト戦略まで、GenAI活用を一歩ずつ前に進めるための実践知をお届けします。

大規模言語モデル(LLM)を自社の製品やサービスに組み込もうとする企業が急速に増えるなか、私たちのもとには次のような質問が数多く寄せられています。
……あるいは、そもそもLLMプロジェクトをどこから_着手_すべきか、という根本的な悩みも少なくありません。
そこで開催したのが、GenAI活用のフェーズが異なるGoogle Cloudのお客様を対象としたライブQ&Aです。AIをまだ試行段階で触っている企業から、すでに本番環境で運用している企業まで幅広く参加し、DoiTのAI/MLエキスパート3名(Eduardo Mota、Jared Burns、Sascha Heyer)に、Google CloudでのLLM実装に関するあらゆる疑問をぶつけてもらいました。
本記事ではその要点を、Google CloudでのGenAI導入の第一歩から、自社のGoogle Workspaceデータを活用したRAG(検索拡張生成)といった応用トピックまで、まとめてご紹介します。
Google CloudでGenAIを始めるには
質問: 企業としてGoogle CloudでGenAIに取り組むには、何から始めればよいですか?
これに対しEduardoは、私たちがGenAI Acceleratorsを通じてお客様の独自GenAIソリューション構築を支援する際に必ず通る「GenAI実装ジャーニー」を紹介しました。
このジャーニーは、アイデア出しから本番環境でのスケーリング(そして全工程を支えるオブザーバビリティ)までを一貫してカバーします。
今回のセッションでは特に、アイデア出し・プロンプト設計・PoCの3つのフェーズに焦点を当てました。
GenAIユースケースのアイデア出し
LLMを使った実装を検討するときは、何を作りたいのかをビジネス目標としっかり結びつけることが大切です。
アイデアを引き出すには、次のような問いを自分に投げかけてみるとよいでしょう。
- 分類:「もし______の中から________を識別できれば、________ができる」
- 例:「監視カメラの画像から車の傷を識別できれば、レンタカーのチェックイン・チェックアウトをよりスムーズにできる」
- パーソナライズ:「もしどの________が_________しやすいかを把握できれば、_______ができる」
- 例:「どのサービスが顧客のリテンションにつながりやすいかが分かれば、一人ひとりに合わせたリテンション施策を打てる」
- エキスパートシステム:「もし_________を使って________を識別できれば、___________ができる」
- 例:「顧客個別の履歴データからペルソナを特定できれば、その人に最適化したガイダンスを提供できる」
GenAI活用のアイデアを練るときは、汎用的なプロセスではなく_パーソナライズされた_体験を起点に考えるよう、私たちはお客様にお伝えしています。
たとえば、こんな違いです。
- 汎用的:オンラインで食事を注文できるようにし、過去注文の再購入機能を備え、マーケティングペルソナに基づくアップセルを提供する。
- パーソナライズ:顧客個人のデータと店舗情報を組み合わせ、注文時間を短縮しつつ、価値の高いアップセルを盛り込んだ高品質な注文体験を提供する。
技術寄りというよりビジネスサイドの方には、Google CloudのGenAI Navigatorもおすすめです。戦略・インフラ・スキルの3カテゴリで質問に答えていくと、Google CloudでGenAIを始めるための推奨アクションが提示されます。
LLMプロンプト設計
取り組むテーマが固まったら、次はVertex AI Studioでプロンプトを試してみましょう。300ドル分の無料クレジットが利用でき、Google CloudのAI Startupプログラムなどを活用すればさらに上乗せも可能です。
ただし、実験のための実験は禁物です。明確なゴールを設定したうえで、Eduardoが示した次のプロンプト設計の主要ステップを踏みましょう。
得たい出力を定義する:モデルに何を生成してほしいかを言語化します。分類結果、パーソナライズされたレコメンド、複雑な分析など、出力の幅は広く取れます。
セキュリティ対策を組み込む:プロンプトインジェクションやLLMの誤出力といったリスクに備えてセーフガードを設定します。注意すべきリスクは、過去のCloud Mastersポッドキャスト「LLMのセキュリティリスクと緩和策」でも詳しく取り上げています。
必要なコンテキストを洗い出す:望む出力を生成するために、モデルにどんな情報(データ・背景・具体的な指示)を与えるべきかを考えます。
異なる手法で2〜3パターンのプロンプトを作る:Few-shot学習、Chain-of-Thought、マルチプロンプトなど、手法によって結果は変わります。複数試す価値は十分にあります。
複数のモデルでプロンプトを評価する:Vertex AI Studioでは多彩なモデルを使えます。いくつか試して、モデルごとの応答の違いを把握し、性能と精度の両面で最適化していきましょう。
GenAIのPoC(概念実証)
プロンプト設計を一通り試したら、次はPoCの構築です。Eduardoは、PoCを成功させるための主な要件として次の項目を挙げました。
- 明確な成功基準を定める
- 10名以上のテストグループを確保する
- text-bison、Gemini、Cloud FunctionsなどのGoogleマネージドサービスを活用する
- ユーザーからのフィードバックを集める
- パフォーマンス指標を設ける
- パフォーマンスのベンチマークを設定する
EduardoがData Science Centralのインタビューでも語っているとおり、初期テストグループからのフィードバックは何より重要です。「ポジティブな体験でなくても、ユーザーの声を集めることが大切です。標準のベンチマークを定めたうえで、GenAIに入る入力と出てくる出力を一つ残らずモニタリングしてください。これだけでも、ワークロードをワンランク引き上げるために必要な調整が見えてきます」。フィードバックを起点に素早く反復し、顧客体験のギャップを埋めていく——これがPoCの狙いです。
過去のCloud Mastersポッドキャストでも、SaschaとEduardoはLLMの入力・出力・リクエストといった指標に対するオブザーバビリティを整えることの重要性について話しています。
「GenAIをまずは触ってみたいけれど、自社データを使ったPoCにはまだ手が届かない」という方には、Google CloudのJump Startソリューションがおすすめです。
これはワンクリックで使えるオープンソースのデプロイメントで、次の特徴があります。
- すぐ使えるInfrastructure as CodeをGitHubリポジトリで提供
- 自分のプロジェクトに簡単にデプロイ可能
- そのまま探索・改変できるエンドツーエンドのアーキテクチャを提供
たとえば下図は、Google CloudのJump Startで提供されるGenAIナレッジベースソリューションのアプリケーションインフラのアーキテクチャです。

Vertex AIで構造化されたJSONを生成する
質問: フォーマットを明確に定義したJSONでLLMの応答を受け取るには、どうすればよいですか?
LLMの出力は基本的に非構造化です。創造的な作業や対話には便利な柔軟さですが、出力をプログラムから処理して動かす本番アプリケーションでは、この自由度が悩みの種になります。
たとえばECの商品レコメンドシステムで、各レコメンドに価格・カテゴリ・在庫といった属性が必要なのに、応答が非構造化テキストで返ってきたら——あるいは、チケットの詳細・優先度・推奨アクションを一定のフォーマットで取り出したいカスタマーサポートシステムで、毎回異なる形式が返ってきたら——どうでしょうか。
こうしたケースでは、構造化されたJSONで応答を受け取ることが必須になります。さもないと、LLMの応答フォーマットがほんの少し変わるだけで壊れる、複雑なパース処理を書き続けることになります。
この質問が出た当時、Google CloudはControlled generationをプライベートプレビューでリリースしたばかりでした。LLMの出力フォーマットを開発者側で正確に指定できる機能です。2024年9月5日以降、Gemini 1.5 ProとFlashがControlled generationを正式にサポートしています。
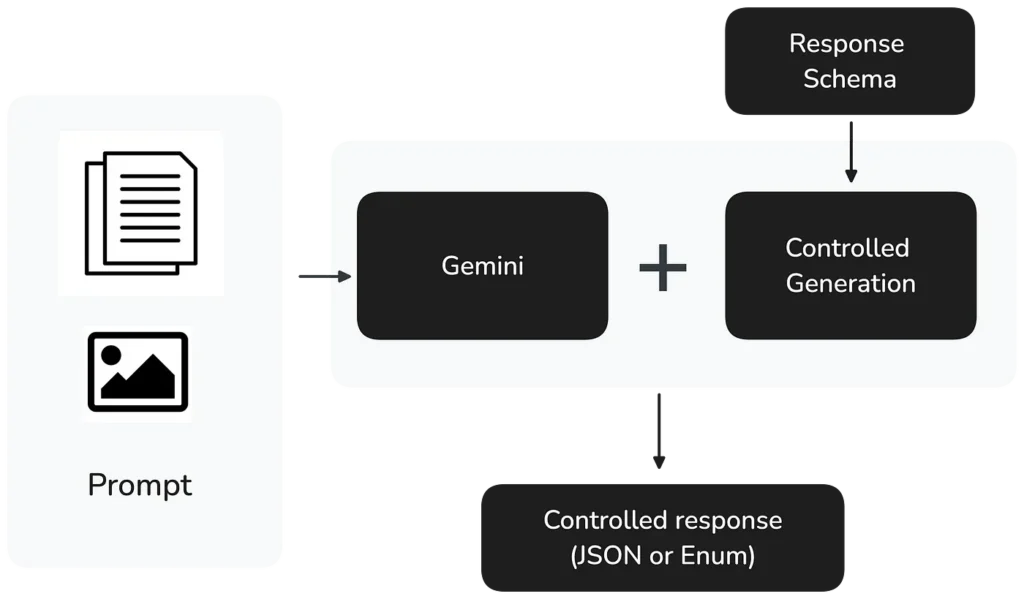
実装はシンプルで、開発者は次の2点を指定するだけです。
- 有効なJSONまたはEnum出力を保証するレスポンスのMIMEタイプ
- 必要な構造を厳密に定義するレスポンススキーマ
Controlled generationの詳細は、Saschaのブログ記事でも解説しています。Google Colabでコードを動かしながら学びたい方は、ぜひそちらもご覧ください。
Google WorkspaceデータでRAGを実装する
質問: Google Cloud上のLLMを、自社のGoogle Workspaceデータの一部だけで学習させる方法はありますか? たとえば、マイドライブや共有ドライブ・フォルダを対象にLLMを学習させ、そのデータに含まれる情報を問い合わせたいのですが、学習のために全データをGCSにコピーするのは避けたいです。
RAG(検索拡張生成)は、モデルの学習データの外側にある情報を取り込んでLLMの応答を強化する手法です。学習データだけに頼るのではなく、ユーザーが用意したドキュメントやデータから関連情報を取得し、それを根拠にしてより正確で文脈に沿った応答を生成します。
企業にとって有用なRAG活用の一つが、自社のGoogle Workspaceデータ(ドキュメント、スプレッドシート、ドライブなど)との連携です。たとえば次のような場面で力を発揮します。
- 社内ドキュメントを基にAI駆動のナレッジベースを構築する
- ドライブに保管された製品ドキュメントを参照するカスタマーサポートを構築する
- 複数のWorkspaceドキュメントを横断して内容を理解・要約できる社内検索ツールを開発する
たとえば営業チームならドライブ内の関連事例を素早く見つけて要約させられますし、人事部門なら社内ポリシー文書をもとに従業員の質問に答えるシステムを組めます。
下のクリップでJaredが紹介しているように、Google CloudはVertex AI上でRAGを実装する複数の選択肢を提供しています。
- Vertex AI Search:ドキュメント検索用の埋め込みを生成・保存
- カスタムリトリーバー:独自の検索システムを構築
- LlamaIndex:GoogleがマネージドRAGソリューションとして採用したオープンソースツール
続けてJaredは、LlamaIndexを使ってGoogle DriveデータでRAGを実装する流れを次のように解説しました。
- ドキュメントデータを格納するRAGコーパスを作成
- Alphabetの2024年第1四半期決算資料などを含むGoogle Driveフォルダからファイルをインポート
- インポート済みファイル数を確認して取り込みを検証
- 「Alphabetの2024年第1四半期の売上は?」という質問でリトリーバーの動作をテスト
- Gemini 1.0で応答を生成。アップロードした決算資料から取り出された2024年第1四半期の売上が正確に返答された
LLMテストのためのAPIレスポンスのモック化
質問 : Vertex AI Agent Builderで、テスト用にツール呼び出しをモック化することはできますか? たとえば、これから利用するAPIがまだ開発中の場合などです。
テストはソフトウェア開発やAPI開発全般で重要ですが、LLMベースのアプリケーションでは確率的な挙動という性質上、その重要性がさらに増します。同じプロンプトでも毎回異なる応答が返り得るからこそ、エージェントの一貫した振る舞いを検証できる、コントロールされたテスト環境が欠かせません。
同時に、LLMベースのカスタムエージェントを開発する際のテストは一筋縄ではいきません。エージェントは外部APIと頻繁にやり取りしますが、テスト中に実APIを叩けばコストもレイテンシもかかり、レート制限や障害による信頼性の問題も出てきます。さらに、外部APIはリアルタイムデータに応じて応答が変わるため、特定のシナリオやエッジケースを安定して再現することが難しくなります。
モックAPIレスポンスを用意すれば、開発者はコントロールされた環境でエージェントの挙動を検証でき、信頼性が高く効率的なテストサイクルを回せます。
Eduardoは、Google Cloud Functionsを使ってAPIレスポンスをモック化するシンプルな方法を、2つの実装パターンで紹介しました。
独立したモック関数
- モックAPI専用のCloud Functionを用意する
- テスト時にはエージェントがそのモック関数を呼び出すように設定する
インラインモック
- 既存のCloud Function内に直接モックレスポンスを実装する
- 実APIを呼び出す代わりに、あらかじめ定義したレスポンスを返す
関数の実装を完全に自分でコントロールできるため、実APIの構造に合わせたカスタムモックを定義したり、モックと実レスポンスの切り替えを制御したり、エージェントが処理しやすい一貫したフォーマットを保ったりできます。
気をつけたい一番のポイントは、モックレスポンスの構造とフォーマットを、エージェントが実APIに期待する形と完全に揃えておくことです。
適切にAPIモックを組み込めば、テスト環境を自分の手のひらに収めながら、LLMベースエージェントの開発・検証をぐっと効率化できます。
Vertex AI Agent Builderでエージェント間のパラメータを受け渡す
質問: Agent Builderで、エージェント間のパラメータ受け渡しを確実に行うにはどうすればよいですか?
役割の異なる複数のエージェントが連携するAIシステムを思い浮かべてください。あるエージェントは顧客の問い合わせに対応し、別のエージェントは在庫情報を扱い、さらに別のエージェントが注文を処理する——そんな構成です。これらのエージェントが互いにスムーズかつ確実に情報を渡し合えるかどうかが鍵を握ります。そこで重要になるのがパラメータの受け渡しです。
たとえば、顧客が商品の注文について問い合わせた場合、カスタマーサービス用のエージェントは在庫エージェントに商品IDを渡して在庫を確認し、続けて商品IDと数量の両方を注文処理エージェントに引き継ぐ必要があります。この情報の流れを正しく組むことが、有効なAIシステムを作るうえで不可欠です。
とはいえ、AIエージェントは情報の理解や共有自体は得意でも、確率的な挙動ゆえに、こうした受け渡しを取り違えてしまうことがあります。正確性が問われるビジネスシーンでは、引き継ぎが100%確実に行われる仕組みが必要です。
EduardoはVertex AI Agent Builderでエージェント間のパラメータを受け渡すデモを行い、適切なパラメータが渡されているかをコードで検証する方法もあわせて解説しました。
Vertex AIのAgent Builderを使えば、連携するAIエージェントを手軽に組み立てられますが、適切なパラメータ検証を組み込むことで、現実の運用環境でも安定して動くシステムになります。パラメータ受け渡しを管理するオーケストレーターを実装し、良質な例を使ってエージェントを育てれば、情報共有を堅実にこなす堅牢なAIシステムを構築できます。
包括的な検証ロジックを実装し、パラメータ受け渡しの操作ログをきちんと残すことを忘れないでください。信頼性の高いパラメータ処理への先行投資は、AIアプリケーションが拡大・複雑化していくほど、大きな時間と労力の節約として返ってきます。
まとめ
Google CloudでのLLM実装をテーマにしたライブQ&Aで寄せられた質問のうち、本記事で取り上げたのは半数強です。GenAIにこれから取り組む方も、すでにある実装をブラッシュアップしたい方も、本記事を確かな出発点として活用いただけるはずです。
ドキュメント処理、iOSネイティブアプリ向けLLMのベストプラクティス、トランスクリプトの構造化など、本記事に収まりきらなかった内容も含めた全体像は、Q&AセッションのYouTubeプレイリストでご覧いただけます。
Google CloudでのLLM実装には、テクノロジーと人の知見の両方が欠かせません。GenAIはまだ新しい技術領域だからこそ、経験豊富な伴走者がいれば、よくある落とし穴を避け、本番投入までの道のりを確実に短縮できます。
Google CloudでのGenAI実装にサポートが必要でしたら、ぜひDoiTのAI/MLエキスパートチームまでお問い合わせください。GenAI Accelerator for Google Cloudを通じて、LLMベースのアプリケーション構築とスケールを効率的にご支援します。