Gli esperti AI di DoiT spiegano come implementare gli LLM su Google Cloud: scelta del modello, controllo dei costi, RAG con Google Workspace, strategie di test delle API e una guida passo passo per il Suo percorso GenAI.

Sempre più aziende vogliono integrare i Large Language Model (LLM) nei propri prodotti e servizi e, nel tempo, ci siamo trovati a rispondere a numerose domande su:
- come scegliere il Foundational Model giusto per il proprio caso d'uso,
- come mantenere stabili i costi unitari del proprio deployment GenAI e
- l'osservabilità degli LLM dopo il deployment
...o semplicemente da dove cominciare con un progetto LLM.
Per questo abbiamo organizzato un Q&A live rivolto ai clienti Google Cloud che si trovano in fasi diverse del percorso verso la GenAI: da chi è ancora in fase sperimentale a chi ha già un deployment in produzione. I partecipanti hanno potuto rivolgere a tre esperti AI/ML di DoiT (Eduardo Mota, Jared Burns e Sascha Heyer) qualsiasi domanda sull'implementazione degli LLM su Google Cloud.
Qui di seguito abbiamo riassunto i punti chiave: dai primi passi con la GenAI su Google Cloud fino ad argomenti più avanzati, come sfruttare i dati di Google Workspace della propria azienda per il Retrieval-Augmented Generation (RAG).
Primi passi con la GenAI su Google Cloud
Domanda originale: Come dovrebbe iniziare un'azienda con la GenAI su Google Cloud?
Per rispondere, Eduardo ha riassunto il GenAI Implementation Journey che proponiamo alle aziende quando le accompagniamo nella creazione di soluzioni GenAI su misura tramite i nostri GenAI Accelerators.
Il percorso copre tutte le tappe, dall'ideazione fino allo scaling del deployment in produzione, con l'osservabilità presente lungo l'intero processo.
Nello specifico, ci siamo concentrati sulle fasi di ideazione, prompt design e PoC.
Ideazione dei casi d'uso GenAI
Quando si pensa a possibili implementazioni basate su LLM, è fondamentale allineare ciò che si vuole costruire agli obiettivi di business.
Ecco alcune domande utili per far emergere le idee:
- Classificazione: "Se riuscissi a identificare ______ in ________, potrei ________"
- Es. "Se riuscissi a riconoscere i graffi di un'auto nelle immagini di una telecamera di sorveglianza, potrei migliorare il processo di check-in e check-out delle auto a noleggio"
- Personalizzazione: "Se sapessi quali ________ hanno maggiori probabilità di _________, potrei _______"
- Es. "Se sapessi quali servizi hanno maggiori probabilità di trattenere un cliente, potrei proporgli offerte di retention personalizzate"
- Sistemi esperti: "Se riuscissi a identificare ________ con _________, potrei ___________"
- Es. "Se riuscissi a identificare la persona del cliente a partire dai suoi dati storici, potrei offrirgli una guida su misura"
In generale, durante il brainstorming sulle possibili implementazioni GenAI, suggeriamo alle aziende di pensare a esperienze personalizzate più che a processi generici.
Ad esempio:
- Generico: vogliamo permettere ai clienti di ordinare cibo online, riproporre gli ordini precedenti e creare up-sell basati su personas di marketing.
- Personalizzato: sfruttando i dati individuali del cliente e le informazioni del ristorante, possiamo offrire un'esperienza d'ordine di alta qualità che riduca i tempi e proponga up-sell di reale valore.
Se ha un profilo più di business che tecnico, Google Cloud mette a disposizione anche GenAI Navigator, che propone una serie di domande in tre categorie (Strategia, Infrastruttura e Competenze) e restituisce raccomandazioni su come iniziare con la GenAI su Google Cloud.
Prompt design degli LLM
Una volta chiara l'idea da perseguire, il passo successivo è sperimentare con i prompt in Vertex AI Studio: può anche ottenere 300$ in crediti gratuiti, e ulteriori crediti tramite iniziative come l'AI Startup program di Google Cloud.
Tuttavia, sperimentare tanto per sperimentare non porta lontano. Serve un obiettivo chiaro e occorre seguire i passaggi chiave indicati da Eduardo nel processo di prompt design:
Definire l'output desiderato: espliciti con chiarezza ciò che vuole che il modello produca. Si va dai risultati di classificazione alle raccomandazioni personalizzate, fino ad analisi complesse.
Adottare misure di sicurezza: predisponga delle protezioni contro rischi potenziali come la prompt injection e gli output errati degli LLM. Abbiamo approfondito i rischi da tenere d'occhio in un precedente episodio del podcast Cloud Masters dedicato ai rischi di sicurezza degli LLM e alle strategie di mitigazione:
Individuare il contesto necessario all'output desiderato: si chieda di quali informazioni ha bisogno il modello — dati, informazioni di background, istruzioni specifiche — per generare l'output che Lei si aspetta.
Creare 2-3 prompt con tecniche diverse: provi tecniche come few-shot learning, chain-of-thought reasoning o approcci multi-prompt. Ogni tecnica può dare risultati diversi, quindi vale la pena confrontare più metodi.
Valutare i prompt con modelli diversi: in Vertex AI Studio ha accesso a un'ampia gamma di modelli. Ne metta alla prova alcuni! Capirà come ciascuno reagisce ai Suoi prompt e potrà ottimizzare prestazioni e accuratezza.
Proof-of-concept (PoC) GenAI
Dopo aver sperimentato con il prompt design, il passo successivo è sviluppare un proof of concept. Eduardo ha individuato alcuni requisiti chiave per un PoC di successo:
- Definire criteri di successo chiari
- Costituire un gruppo di test di almeno 10 utenti
- Sfruttare i servizi gestiti di Google come text-bison, Gemini, Cloud Functions, ecc.
- Raccogliere il feedback degli utenti
- Stabilire metriche di performance
- Definire benchmark di performance
Come Eduardo ha spiegato a Data Science Central, il feedback del primo gruppo di test è fondamentale. "Bisogna raccogliere il feedback degli utenti, anche quando l'esperienza non è stata positiva. È importante aver definito benchmark standard e poi monitorare ogni input e output prodotto dalla propria GenAI. Già solo valutando questi elementi si capisce quali aggiustamenti sui workloads servono per fare un salto di qualità." L'obiettivo è iterare velocemente sulla base del feedback per colmare eventuali lacune nel customer journey.
In un precedente episodio del podcast Cloud Masters, Sascha ed Eduardo hanno illustrato anche perché è importante avere osservabilità su metriche come input, output e richieste degli LLM.
Se vuole mettere subito le mani in pasta con la GenAI, ma non è ancora pronto per sviluppare un PoC con i propri dati, Google Cloud offre le soluzioni Jump Start.
Si tratta di deployment open-source attivabili con un clic che:
- Forniscono un'infrastructure as code pronta all'uso in un repository GitHub
- Consentono un deployment semplice nel proprio progetto
- Offrono un'architettura end-to-end completa che può essere esplorata e modificata
Il diagramma qui sotto mostra, ad esempio, l'architettura dell'infrastruttura applicativa per una soluzione GenAI Knowledge Base, tratta dal corrispondente Jump Start di Google Cloud:

Generare output JSON con Vertex AI
Domanda originale: Come posso ottenere risposte degli LLM in JSON con un formato chiaramente definito?
Gli output degli LLM sono spesso non strutturati. Se questa flessibilità può essere utile per attività creative o conversazionali, diventa un problema quando si costruiscono applicazioni in produzione che devono elaborare e agire su quegli output in modo programmatico.
Pensi a un sistema di raccomandazione prodotti per un e-commerce, in cui ogni suggerimento richiede attributi specifici come prezzo, categoria e disponibilità, ma con dati non strutturati. Oppure a un sistema di customer support che deve estrarre dettagli del ticket, livelli di priorità e azioni suggerite in un formato coerente.
In questi scenari ottenere risposte in formato JSON strutturato è essenziale. Senza output strutturati servirebbe una logica di parsing complessa, che può rompersi anche con minime variazioni nel formato di risposta dell'LLM.
Al momento della domanda, Google Cloud aveva appena rilasciato in private preview Controlled generation, che consente agli sviluppatori di specificare il formato esatto delle risposte degli LLM. Dal 5 settembre 2024, Gemini 1.5 Pro e Flash supportano pienamente Controlled generation.
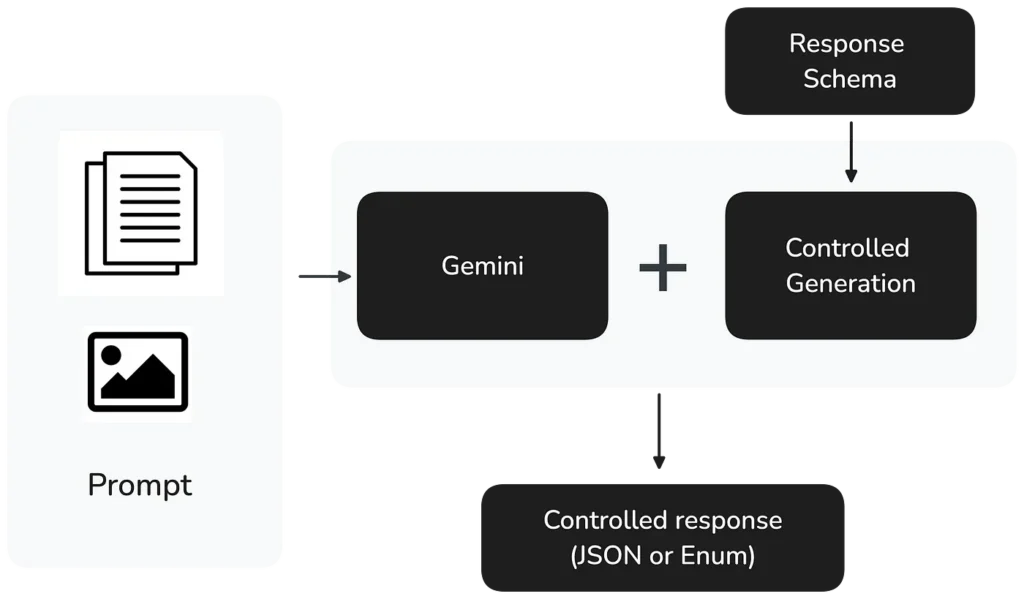
L'implementazione è semplice: gli sviluppatori possono specificare
- un response MIME type per garantire un output JSON o Enum valido;
- uno schema di risposta che definisce la struttura esatta richiesta.
Sascha approfondisce Controlled generation nel suo blog post: se vuole tuffarsi in un notebook Google Colab e iniziare a sperimentare con il codice, dia un'occhiata al suo articolo.
Implementare il RAG con i dati di Google Workspace
Domanda originale: Esiste un modo per addestrare gli LLM di Google Cloud su sottoinsiemi dei nostri dati Google Workspace? Ad esempio, come posso addestrare un LLM su My Drive, su un Drive condiviso o su una cartella e poi interrogarlo per ottenere informazioni contenute nel dataset? Vorrei evitare di copiare tutti i dati su GCS solo per l'addestramento.
La Retrieval Augmented Generation (RAG) è una tecnica che permette di arricchire le risposte degli LLM integrando informazioni esterne ai dati di addestramento del modello. Invece di affidarsi unicamente a tali dati, la RAG recupera informazioni pertinenti dai documenti e dai dati che Lei fornisce e li utilizza per generare risposte più accurate e contestualizzate.
Un'applicazione utile della RAG per le aziende è l'integrazione con i propri dati Google Workspace (Docs, Sheets, Drive, ecc.). Può essere usata in scenari come:
- creare una knowledge base basata sull'AI a partire dalla documentazione interna;
- costruire sistemi di customer support che attingono dalla documentazione di prodotto archiviata su Drive;
- sviluppare strumenti di ricerca interna in grado di comprendere e riassumere contenuti distribuiti su più documenti Workspace.
Ad esempio, un team commerciale potrebbe usare la RAG per trovare e riassumere rapidamente i case study più rilevanti dal proprio Drive, oppure HR potrebbe costruire un sistema che risponde alle domande dei dipendenti basandosi sui documenti di policy interni.
Come ha spiegato Jared nella clip qui sotto, Google Cloud offre diverse opzioni per implementare la RAG all'interno di Vertex AI:
- Vertex AI Search: genera e archivia gli embedding per il recupero dei documenti
- Custom retriever: costruire il proprio sistema di retrieval
- LlamaIndex: uno strumento open-source adottato da Google come soluzione RAG gestita
Jared ha poi mostrato passo passo l'implementazione della RAG con i dati di Google Drive usando LlamaIndex. In particolare ha:
- creato un RAG corpus per archiviare i dati dei documenti;
- importato i file da una cartella Google Drive contenente, tra gli altri, il bilancio Q1 2024 di Alphabet;
- verificato l'importazione controllando il numero di file caricati;
- testato il funzionamento del retriever con la domanda: "Qual è stato il fatturato di Alphabet nel Q1 2024?";
- generato una risposta con Gemini 1.0, che ha riportato accuratamente il fatturato di Alphabet nel Q1 2024 — un'informazione estratta direttamente dal bilancio caricato.
Mockare le risposte API per testare gli LLM
Domanda originale : in Vertex AI Agent Builder , è possibile mockare una tool call a scopo di test? Ad esempio, se l'API che useremo non è ancora stata sviluppata.
Il testing è importante in generale nello sviluppo software e nelle API, ma diventa particolarmente critico nelle applicazioni basate su LLM, vista la loro natura probabilistica. Lo stesso prompt può generare risposte diverse ogni volta: per questo è essenziale disporre di ambienti di test controllati, in grado di validare un comportamento coerente dell'agente.
Allo stesso tempo, sviluppare applicazioni con custom agent basati su LLM non rende il testing semplice. Questi agenti hanno spesso bisogno di interagire con API esterne, ma affidarsi a chiamate API live durante i test introduce costi, latenza e potenziali problemi di affidabilità dovuti a rate limit e interruzioni di servizio. Inoltre, le API esterne possono restituire risposte variabili in base ai dati in tempo reale, rendendo difficile testare in modo coerente scenari specifici o casi limite.
Implementare risposte API mock consente a Lei o ai Suoi sviluppatori di testare il comportamento degli agenti in un ambiente controllato, garantendo cicli di test affidabili ed efficienti.
Eduardo ha illustrato un approccio semplice per mockare le risposte API con Google Cloud Functions, presentando due opzioni di implementazione:
Mock Function separata
- Creare una Cloud Function dedicata che funga da API mock
- Configurare l'agente affinché chiami questa funzione mock durante i test
Mocking inline
- Implementare la risposta mock direttamente all'interno della Cloud Function esistente
- Restituire risposte predefinite invece di effettuare chiamate API reali
Avendo pieno controllo sull'implementazione della funzione, può definire risposte mock personalizzate che rispecchino la struttura dell'API reale, decidere quando restituire risposte mock o reali e mantenere formati di risposta coerenti per l'elaborazione da parte dell'agente.
L'aspetto su cui prestare attenzione è che le risposte mock conservino la stessa struttura e lo stesso formato che l'agente si aspetta dall'API reale.
Con un mocking ben fatto delle API, può sviluppare e testare i Suoi agenti basati su LLM in modo più efficiente, mantenendo il pieno controllo sull'ambiente di test.
Passare parametri tra agenti con Vertex AI Agent Builder
Domanda originale: Usando Agent Builder, come posso passare parametri tra agenti in modo affidabile?
Immagini di costruire un sistema AI in cui agenti specializzati diversi devono collaborare. Magari un agente gestisce le richieste dei clienti, un altro le informazioni di magazzino e un terzo elabora gli ordini. Questi agenti devono scambiarsi informazioni in modo fluido e affidabile. Ed è qui che entra in gioco il passaggio dei parametri.
Ad esempio, quando un cliente chiede di ordinare un prodotto, l'agente di customer service potrebbe dover passare l'ID prodotto all'agente di magazzino per verificarne la disponibilità, e poi passare sia l'ID prodotto sia la quantità all'agente di order processing. Curare bene questo flusso di informazioni è cruciale per costruire sistemi AI efficaci.
Tuttavia, anche se gli agenti AI sono in genere bravi a comprendere e condividere informazioni, la loro natura probabilistica fa sì che possano occasionalmente gestire male questi handoff. In un contesto di business in cui l'accuratezza è fondamentale, servono modi per garantire che questi passaggi siano affidabili al 100%.
Eduardo ha mostrato come passare parametri tra agenti con Vertex AI Agent Builder e ha discusso la validazione tramite codice lungo tutto il flusso, per assicurarsi che vengano passati i parametri corretti.
Agent Builder di Vertex AI rende semplice creare agenti AI in grado di collaborare, ma una corretta validazione dei parametri è ciò che garantisce affidabilità in condizioni reali. Implementando un orchestratore per gestire il passaggio dei parametri e arricchendo gli agenti con buoni esempi, può costruire sistemi AI robusti e in grado di scambiarsi informazioni in modo affidabile.
Si ricordi di implementare una logica di validazione completa e di mantenere log dettagliati delle operazioni di passaggio dei parametri. Questo investimento iniziale in una gestione affidabile dei parametri farà risparmiare molto tempo e fatica man mano che le Sue applicazioni AI cresceranno e diventeranno più complesse.
Conclusioni
Abbiamo affrontato poco più della metà delle domande emerse durante il nostro Q&A live sull'implementazione degli LLM su Google Cloud. Sia che stia muovendo i primi passi con la GenAI, sia che voglia ottimizzare un'implementazione già esistente, questi spunti Le offrono basi solide.
Per il quadro completo — comprese tematiche come l'elaborazione documentale, le best practice LLM per app iOS native e la strutturazione delle trascrizioni — dia un'occhiata alla nostra playlist YouTube completa della sessione di Q&A.
Implementare gli LLM su Google Cloud richiede un mix di tecnologia e competenze umane. Trattandosi di una tecnologia ancora relativamente nuova, una guida esperta aiuta a evitare gli errori più comuni e ad accelerare il percorso verso la produzione.
Se desidera supporto per la Sua implementazione GenAI su Google Cloud, ci contatti: il nostro team di esperti AI/ML potrà illustrarLe il nostro GenAI Accelerator for Google Cloud, con cui La aiutiamo a costruire e a far crescere in modo efficiente le Sue applicazioni basate su LLM.