Aprende a implementar LLMs en Google Cloud con los expertos en IA de DoiT. Consejos prácticos sobre selección de modelos, gestión de costos, implementación de RAG con Google Workspace, estrategias de testing de APIs y una guía paso a paso para tu camino con GenAI.

A medida que más empresas buscan incorporar Large Language Models (LLMs) en sus productos y servicios, nos han llegado muchas preguntas sobre:
- Cómo elegir el Foundational Model adecuado para tu caso de uso,
- Cómo mantener estables los costos unitarios de tu despliegue de GenAI, y
- Observabilidad de los LLMs después del despliegue
...o incluso por dónde empezar un proyecto con LLMs.
Por eso organizamos un Q&A en vivo para clientes de Google Cloud con distintos niveles de madurez en GenAI. Se sumaron empresas que van desde las que están en fase experimental con IA hasta las que ya tienen un despliegue en producción, para hacerle a tres de los expertos en AI/ML de DoiT (Eduardo Mota, Jared Burns, Sascha Heyer) cualquier pregunta sobre la implementación de LLMs en Google Cloud.
A continuación resumimos las ideas clave, desde cómo dar los primeros pasos con GenAI en Google Cloud hasta temas más avanzados, como aprovechar los datos de Google Workspace de tu empresa para Retrieval-Augmented Generation (RAG).
Primeros pasos con GenAI en Google Cloud
Pregunta original: ¿Cómo debería empezar con GenAI como empresa en Google Cloud?
Para responder, Eduardo resumió el GenAI Implementation Journey con el que acompañamos a las empresas cuando las ayudamos a construir soluciones personalizadas de GenAI a través de nuestros GenAI Accelerators.
Este recorrido cubre los pasos desde la ideación hasta escalar tu despliegue en producción (con observabilidad en todo el proceso).
En concreto, nos enfocamos en las etapas de ideación, diseño de prompts y PoC.
Ideación de casos de uso de GenAI
Al hacer brainstorming de implementaciones basadas en LLMs, es importante alinear lo que quieres construir con los objetivos del negocio.
Algunas preguntas que puedes hacerte para que fluyan las ideas:
- Clasificación: "Si pudiera identificar ______ en ________, podría ________"
- Ej. "Si pudiera reconocer rayones en un auto a partir de imágenes de una cámara de vigilancia, podría mejorar el proceso de check-in y check-out de nuestros autos de alquiler"
- Personalización: "Si supiera qué ________ tienen más probabilidades de _________, podría _______"
- Ej. "Si supiera qué servicios tienen más probabilidades de retener a un cliente, podría ofrecer ofertas de retención personalizadas."
- Sistemas expertos: "Si pudiera identificar ________ con _________, podría ___________"
- Ej. "Si pudiera identificar el perfil del cliente con sus datos históricos individuales, podría brindarle orientación a la medida"
En general, al hacer brainstorming de posibles implementaciones de GenAI, le sugerimos a las empresas pensar en experiencias personalizadas en lugar de procesos genéricos.
Por ejemplo:
- Genérico: Queremos que los clientes puedan pedir comida online con recompra de pedidos anteriores y crear up-sells basados en personas de marketing.
- Personalizado: Si pudiéramos aprovechar los datos individuales del cliente y la información del restaurante, podemos crear una experiencia de pedido de alta calidad que reduce el tiempo de orden y suma up-sells de alto valor.
Si tu perfil es más de negocio que técnico, Google Cloud también ofrece GenAI Navigator, que te hace una serie de preguntas en tres categorías (Estrategia, Infraestructura y Habilidades) para darte recomendaciones sobre cómo dar tus primeros pasos con GenAI en Google Cloud.
Diseño de prompts para LLM
Una vez que tienes claro qué quieres lograr, el siguiente paso es experimentar con prompts en Vertex AI Studio; incluso puedes obtener $300 en créditos gratuitos y aún más a través de iniciativas como el programa AI Startup de Google Cloud.
Sin embargo, no se trata de experimentar por experimentar. Conviene tener un objetivo en mente y seguir los pasos clave que destacó Eduardo en el proceso de diseño de prompts:
Define el resultado deseado: Articula con claridad qué quieres que produzca tu modelo. Esto va desde resultados de clasificación hasta recomendaciones personalizadas o análisis complejos.
Implementa medidas de seguridad: Pon protecciones ante riesgos potenciales como prompt injection y outputs incorrectos del LLM. Cubrimos los riesgos a tener en cuenta con más detalle en un episodio anterior del podcast Cloud Masters sobre riesgos de seguridad en LLMs y estrategias de mitigación:
Identifica el contexto necesario para el resultado deseado: Pregúntate qué información necesita el modelo —datos, información de contexto, instrucciones específicas— para generar el resultado esperado.
Crea 2-3 prompts con diferentes técnicas: Prueba enfoques como few-shot learning, chain-of-thought reasoning o multi-prompt. Cada técnica puede arrojar resultados distintos, así que vale la pena experimentar con varios métodos.
Evalúa los prompts con diferentes modelos: Tienes acceso a una amplia variedad de modelos en Vertex AI Studio. ¡Prueba algunos! Esto te ayudará a entender cómo responde cada modelo a tus prompts y a optimizar el desempeño y la precisión.
Prueba de concepto (PoC) de GenAI
Una vez que has experimentado con el diseño de prompts, el siguiente paso es desarrollar una prueba de concepto. Eduardo describió varios requisitos clave para un PoC exitoso:
- Define criterios claros de éxito
- Conforma un grupo de prueba de al menos 10 usuarios
- Aprovecha los servicios administrados de Google como text-bison, Gemini, Cloud Functions, etc.
- Recoge feedback de los usuarios
- Define métricas de desempeño
- Establece benchmarks de desempeño
Como Eduardo le comentó a Data Science Central, el feedback de tu grupo inicial de prueba es clave. "Quieres recibir feedback de los usuarios, incluso si la experiencia no fue positiva. Asegúrate de haber definido benchmarks estándar y luego monitorea cada input y output que produzca tu GenAI. Con solo evaluar estos elementos puedes obtener pistas sobre los ajustes en los workloads necesarios para llevar las cosas a otro nivel." El propósito es iterar rápido a partir del feedback para cerrar cualquier brecha en la experiencia del cliente.
En un episodio anterior del podcast Cloud Masters, Sascha y Eduardo también explicaron por qué es importante contar con observabilidad sobre métricas como inputs, outputs y requests de LLM.
Si quieres meterte rápido con GenAI, pero todavía no llegas al punto de desarrollar un PoC con tus propios datos, Google Cloud ofrece soluciones Jump Start.
Son despliegues open-source de un solo clic que:
- Proveen una infraestructura como código lista para usar en un repositorio de GitHub
- Permiten un despliegue sencillo en tu propio proyecto
- Ofrecen una arquitectura end-to-end completa que puedes explorar y modificar
Por ejemplo, el siguiente diagrama muestra la arquitectura de la infraestructura de la aplicación para una solución de GenAI Knowledge Base del Jump Start correspondiente de Google Cloud:

Generación de outputs en JSON con Vertex AI
Pregunta original: ¿Cómo obtengo respuestas del LLM en JSON con un formato claramente definido?
Los outputs de los LLMs suelen ser no estructurados, y aunque esa flexibilidad puede ser útil para tareas creativas o conversacionales, se vuelve un problema al construir aplicaciones en producción que necesitan procesar y actuar sobre esos outputs de forma programática.
Imagina construir un sistema de recomendación de productos para e-commerce donde cada sugerencia necesita atributos específicos como precio, categoría y disponibilidad, pero con datos no estructurados. O crear un sistema de soporte al cliente que tenga que extraer detalles del ticket, niveles de prioridad y acciones sugeridas en un formato consistente.
En estos escenarios, recibir respuestas en un formato JSON estructurado es esencial. Sin outputs estructurados, necesitarías una lógica de parsing compleja que podría romperse en cuanto el formato de la respuesta del LLM varíe aunque sea un poco.
Cuando se hizo esta pregunta, Google Cloud acababa de lanzar Controlled generation en private preview, que permite a los desarrolladores especificar formatos de output exactos para sus respuestas de LLM. Desde el 5 de septiembre de 2024, Gemini 1.5 Pro y Flash soportan completamente Controlled generation.
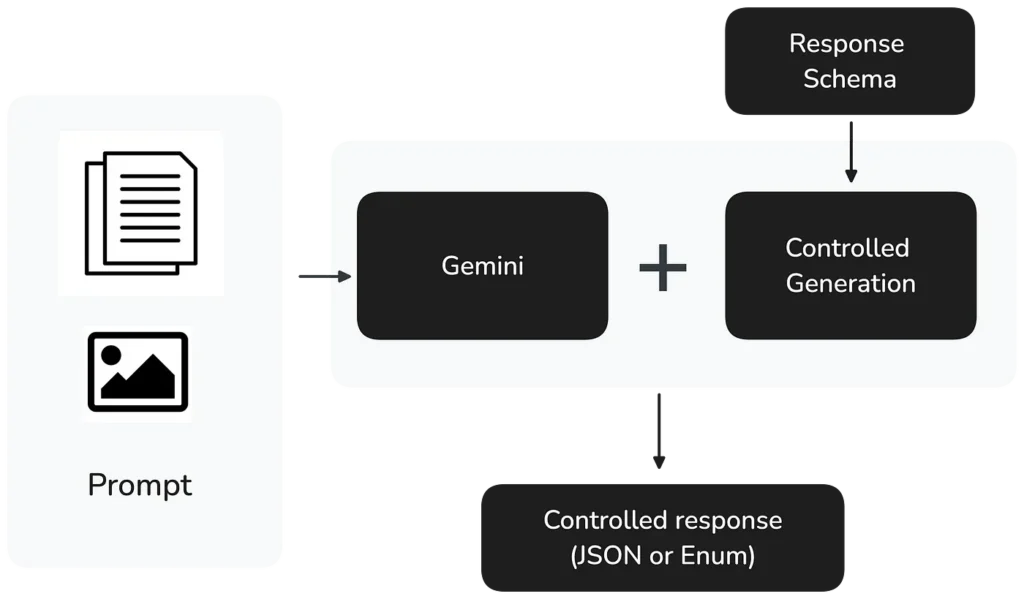
La implementación es sencilla: los desarrolladores pueden especificar:
- Un tipo MIME de respuesta para garantizar un output válido en JSON o Enum
- Un esquema de respuesta para definir la estructura exacta requerida
Sascha explica Controlled generation con más detalle en su blog post, así que si quieres meterte de lleno en un notebook de Google Colab y empezar a experimentar con código, échale un vistazo a su artículo.
Implementando RAG con datos de Google Workspace
Pregunta original: ¿Hay alguna forma de entrenar LLMs de Google Cloud con subconjuntos de nuestros datos de Google Workspace? Por ejemplo, ¿cómo puedo entrenar un LLM a partir de My Drive o un Shared Drive o Folder, y luego consultar la información contenida en ese conjunto de datos? Quiero evitar copiar todos los datos a GCS para el entrenamiento.
Retrieval Augmented Generation (RAG) es una técnica que te permite enriquecer las respuestas del LLM al incorporar información que está fuera de los datos de entrenamiento del modelo. En lugar de depender únicamente de esos datos, RAG recupera información relevante de los documentos y datos que tú proporcionas y la usa para generar respuestas más precisas y contextuales.
Una aplicación útil de RAG para las empresas es integrarlo con sus datos de Google Workspace (Docs, Sheets, Drive, etc.). Esto sirve en situaciones como:
- Crear una base de conocimiento con IA a partir de la documentación interna
- Construir sistemas de soporte al cliente que se nutran de la documentación de producto almacenada en Drive
- Desarrollar herramientas de búsqueda interna que entiendan y resuman contenido a través de varios documentos de Workspace
Por ejemplo, un equipo de ventas podría usar RAG para encontrar y resumir rápidamente casos de éxito relevantes desde su Drive, o RR.HH. podría construir un sistema que responda preguntas de los empleados a partir de sus documentos de políticas internas.
Como contó Jared en el clip de abajo, Google Cloud ofrece varias opciones para implementar RAG dentro de Vertex AI:
- Vertex AI Search: Genera y almacena embeddings para la recuperación de documentos
- Custom retrievers: Construye tu propio sistema de recuperación
- LlamaIndex: Una herramienta open-source adoptada por Google como su solución administrada de RAG
Luego Jared mostró cómo implementar RAG con datos de Google Drive usando LlamaIndex. En concreto:
- Creó un corpus de RAG para almacenar los datos de los documentos
- Importó archivos desde una carpeta de Google Drive que contenía el reporte de ganancias del Q1 2024 de Alphabet, entre otros archivos.
- Verificó la importación revisando el conteo de archivos importados
- Probó la funcionalidad del retriever preguntando: "¿Cuáles fueron los ingresos de Alphabet en el Q1 2024?"
- Generó una respuesta con Gemini 1.0, que reportó con precisión los ingresos de Alphabet en el Q1 2024, información extraída directamente del reporte cargado.
Mockear respuestas de API para testing de LLMs
Pregunta original : En Vertex AI Agent Builder , ¿es posible mockear una llamada a una herramienta con fines de testing? Por ejemplo, si la API que vamos a usar todavía no está desarrollada.
Si bien el testing es importante en general en el desarrollo de software y APIs, resulta especialmente crítico al trabajar con aplicaciones basadas en LLMs por su naturaleza probabilística. El mismo prompt puede generar respuestas distintas cada vez, por lo que conviene tener entornos de testing controlados que permitan validar un comportamiento consistente del agente.
Al mismo tiempo, cuando se desarrollan aplicaciones con agentes personalizados basados en LLMs, el testing no es algo trivial. Aunque estos agentes suelen necesitar interactuar con APIs externas, depender de llamadas a APIs en vivo durante el testing introduce costos, latencia y posibles problemas de confiabilidad por límites de tasa e interrupciones del servicio. Además, las APIs externas pueden devolver respuestas distintas según los datos en tiempo real, lo que dificulta probar de forma consistente escenarios específicos o casos extremos.
Implementar respuestas mock de API te permite a ti o a tus desarrolladores probar el comportamiento del agente en un entorno controlado, garantizando ciclos de testing confiables y eficientes.
Eduardo describió un enfoque sencillo para mockear respuestas de API con Google Cloud Functions, comentando dos opciones de implementación:
Función Mock Separada
- Crea una Cloud Function dedicada que sirva como la API mock
- Configura el agente para que llame a esta función mock durante el testing
Mockeo Inline
- Implementa la respuesta mock directamente dentro de la Cloud Function existente
- Devuelve respuestas predefinidas en lugar de hacer llamadas reales a la API
Como tienes control total sobre la implementación de la función, puedes definir respuestas mock personalizadas que coincidan con la estructura real de la API, controlar cuándo devolver respuestas mock vs. reales y mantener formatos de respuesta consistentes para el procesamiento del agente.
Lo principal a tener en cuenta es que tus respuestas mock conserven la misma estructura y formato que tu agente espera de la API real.
Con un mockeo adecuado de APIs, puedes desarrollar y probar tus agentes basados en LLMs de forma más eficiente, manteniendo el control sobre su entorno de testing.
Pasar parámetros entre agentes con Vertex AI Agent Builder
Pregunta original: Con Agent Builder, ¿cómo puedo pasar parámetros entre agentes de manera confiable?
Imagina que estás construyendo un sistema de IA donde diferentes agentes especializados necesitan trabajar juntos. Tal vez un agente atiende las consultas de los clientes, otro gestiona la información del inventario y un tercero procesa los pedidos. Estos agentes necesitan compartir información entre sí de forma fluida y confiable. Ahí es donde entra el paso de parámetros.
Por ejemplo, cuando un cliente pregunta por la compra de un producto, el agente de servicio al cliente podría necesitar pasarle el ID del producto al agente de inventario para verificar disponibilidad y, luego, pasarle tanto el ID del producto como la cantidad al agente de procesamiento de pedidos. Lograr que ese flujo de información funcione correctamente es clave para construir sistemas de IA efectivos.
Sin embargo, aunque los agentes de IA suelen ser buenos para entender y compartir información, su naturaleza probabilística hace que ocasionalmente puedan manejar mal estos traspasos. En un contexto empresarial donde la precisión es crucial, hacen falta mecanismos para garantizar que esos traspasos sean 100% confiables.
Eduardo mostró cómo pasar parámetros entre agentes con Vertex AI Agent Builder y comentó la validación por código a lo largo de tu flujo para asegurar que se estén pasando los parámetros correctos.
Si bien Agent Builder de Vertex AI facilita crear agentes de IA que trabajen juntos, una validación adecuada de parámetros garantiza que tu sistema funcione de manera confiable en condiciones reales. Al implementar un orquestador que gestione el paso de parámetros y enriquecer a tus agentes con buenos ejemplos, puedes construir sistemas de IA robustos que manejen el intercambio de información de forma confiable.
Recuerda implementar una lógica de validación integral y mantener logs detallados de las operaciones de paso de parámetros. Esa inversión inicial en un manejo confiable de parámetros te ahorrará tiempo y esfuerzo considerables a medida que tus aplicaciones de IA crezcan y se vuelvan más complejas.
Conclusión
Cubrimos poco más de la mitad de las preguntas que recibimos durante nuestro Q&A en vivo sobre la implementación de LLMs en Google Cloud. Ya sea que estés empezando con GenAI o que quieras optimizar tu implementación actual, esto debería darte una base sólida.
Para acceder al conjunto completo de insights, incluyendo temas como el procesamiento de documentos, las mejores prácticas de LLM para apps nativas de iOS y la estructuración de transcripciones, mira nuestra playlist completa de YouTube de la sesión de Q&A.
Implementar LLMs en Google Cloud combina tecnología y experiencia humana. Al ser GenAI una tecnología relativamente nueva, contar con orientación experimentada ayuda a evitar errores comunes y a acelerar tu camino a producción.
Si quieres apoyo con tu implementación de GenAI en Google Cloud, ponte en contacto con nuestro equipo de expertos en AI/ML para conocer nuestro GenAI Accelerator para Google Cloud, donde te ayudamos a construir y escalar tus aplicaciones basadas en LLMs de forma eficiente.