Saiba como implementar LLMs no Google Cloud com os especialistas em IA da DoiT. Insights práticos sobre escolha de modelos, gestão de custos, RAG com Google Workspace, estratégias de teste de API e um passo a passo para sua jornada em GenAI.

Com cada vez mais empresas querendo incorporar Large Language Models (LLMs) aos seus produtos e serviços, recebemos muitas perguntas sobre:
- Como escolher o Foundational Model certo para seu caso de uso;
- Como manter estáveis os custos unitários do seu deployment de GenAI; e
- Observabilidade de LLMs após o deployment.
...ou até mesmo por onde começar em um projeto com LLMs.
Foi por isso que organizamos um Q&A ao vivo para clientes do Google Cloud em diferentes estágios de maturidade em GenAI. De empresas em fase experimental com IA a outras já com deployment em produção, todas participaram para tirar dúvidas sobre a implementação de LLMs no Google Cloud com três especialistas em AI/ML da DoiT (Eduardo Mota, Jared Burns e Sascha Heyer).
Reunimos abaixo os principais insights, que vão desde como dar os primeiros passos com GenAI no Google Cloud até tópicos mais avançados, como usar os dados do Google Workspace da sua empresa em Retrieval-Augmented Generation (RAG).
Primeiros passos com GenAI no Google Cloud
Pergunta original: Como minha empresa deve começar com GenAI no Google Cloud?
Para responder, Eduardo resumiu a Jornada de Implementação de GenAI que conduzimos com as empresas quando ajudamos a construir soluções customizadas de GenAI por meio dos nossos GenAI Accelerators.
Essa jornada cobre as etapas desde a ideação até o scaling do deployment em produção (com observabilidade do início ao fim).
Aqui, focamos especificamente nas etapas de ideação, design de prompts e PoC.
Ideação de casos de uso de GenAI
Ao fazer brainstorming de implementações com LLMs, é fundamental alinhar o que você quer construir aos objetivos do negócio.
Algumas perguntas que ajudam a destravar as ideias:
- Classificação: "Se eu pudesse identificar ______ em ________, eu poderia ________"
- Ex.: "Se eu pudesse reconhecer arranhões em carros nas imagens de uma câmera de segurança, eu poderia melhorar o processo de check-in e check-out dos nossos carros de aluguel."
- Personalização: "Se eu soubesse quais ________ têm mais chance de _________, eu poderia _______"
- Ex.: "Se eu soubesse quais serviços têm maior chance de reter um cliente, eu poderia oferecer ofertas de retenção personalizadas."
- Sistemas especialistas: "Se eu pudesse identificar ________ com _________, eu poderia ___________"
- Ex.: "Se eu pudesse identificar a persona do cliente a partir do seu histórico individual, eu poderia oferecer uma orientação sob medida para cada um."
De modo geral, ao pensar em possíveis implementações de GenAI, recomendamos às empresas focarem em experiências personalizadas, e não em processos genéricos.
Por exemplo:
- Genérico: queremos permitir que clientes peçam comida online, recompondo pedidos anteriores e gerando up-sells com base em personas de marketing.
- Personalizado: aproveitando os dados individuais do cliente e as informações dos restaurantes, podemos criar uma experiência de pedido de alta qualidade que reduz o tempo de compra e adiciona up-sells de alto valor.
Se você é mais um líder de negócio do que técnico, o Google Cloud também oferece o GenAI Navigator, que faz uma série de perguntas em três categorias (Estratégia, Infraestrutura e Habilidades) e gera recomendações sobre como começar com GenAI no Google Cloud.
Design de prompts para LLMs
Com uma ideia clara do que vai construir, o próximo passo é experimentar prompts no Vertex AI Studio — você pode até começar com US$ 300 em créditos gratuitos, e ainda mais por meio de iniciativas como o AI Startup program do Google Cloud.
Mas não experimente só por experimentar. Tenha um objetivo em mente e siga os passos que o Eduardo destacou no processo de design de prompts:
Defina o output desejado: deixe claro o que você quer que o modelo produza, seja um resultado de classificação, recomendações personalizadas ou análises complexas.
Implemente medidas de segurança: configure proteções contra riscos como prompt injection e outputs incorretos do LLM. Falamos sobre esses riscos em mais detalhes em um episódio anterior do podcast Cloud Masters sobre riscos de segurança em LLMs e estratégias de mitigação.
Identifique o contexto necessário para o output desejado: pergunte-se quais informações o modelo precisa — dados, contexto, instruções específicas — para gerar a saída desejada.
Crie 2 ou 3 prompts com técnicas diferentes: teste abordagens como few-shot learning, chain-of-thought reasoning ou multi-prompt. Cada técnica pode trazer resultados diferentes, então vale a pena testar.
Avalie os prompts em modelos diferentes: você tem acesso a uma ampla variedade de modelos no Vertex AI Studio. Teste vários! Isso ajuda a entender como cada modelo responde aos seus prompts e a otimizar performance e precisão.
Prova de conceito (PoC) de GenAI
Depois de explorar o design de prompts, o próximo passo é desenvolver uma prova de conceito. Eduardo elencou alguns requisitos para uma PoC bem-sucedida:
- Definir critérios claros de sucesso
- Montar um grupo de teste com pelo menos 10 usuários
- Aproveitar serviços gerenciados do Google, como text-bison, Gemini, Cloud Functions etc.
- Coletar feedback dos usuários
- Estabelecer métricas de performance
- Definir benchmarks de performance
Como Eduardo contou ao Data Science Central, o feedback do grupo de teste inicial é fundamental. "Você quer ouvir os usuários, mesmo quando a experiência não foi positiva. Defina benchmarks padrão e monitore cada input e output gerado pelo seu GenAI. Avaliando só esses itens, dá para entender quais ajustes nos workloads são necessários para subir o nível." O objetivo é iterar rápido com base no feedback e fechar as lacunas na jornada do cliente.
Em um episódio anterior do podcast Cloud Masters, Sascha e Eduardo também explicaram por que é importante ter observabilidade para métricas como inputs, outputs e requests dos LLMs.
Se você quer botar a mão na massa rapidamente com GenAI, mas ainda não está pronto para desenvolver uma PoC com seus próprios dados, o Google Cloud oferece as soluções Jump Start.
São deployments open source de um clique que:
- Disponibilizam uma infraestrutura como código pronta para usar em um repositório no GitHub
- Permitem deployment fácil no seu próprio projeto
- Oferecem uma arquitetura end-to-end completa para você explorar e modificar
Por exemplo, o diagrama abaixo mostra a arquitetura da aplicação de uma solução de GenAI Knowledge Base do Jump Start correspondente do Google Cloud:

Gerando outputs em JSON com o Vertex AI
Pergunta original: Como obter respostas dos LLMs em JSON com o formato bem definido?
Os outputs dos LLMs costumam ser não estruturados. Essa flexibilidade é ótima para tarefas criativas ou de conversação, mas vira um problema quando você precisa construir aplicações em produção que processem e ajam sobre essas saídas de forma programática.
Imagine montar um sistema de recomendação de produtos para e-commerce em que cada sugestão precisa de atributos específicos como preço, categoria e disponibilidade — tudo isso a partir de dados não estruturados. Ou criar um sistema de suporte ao cliente que precisa extrair detalhes do ticket, níveis de prioridade e ações sugeridas em um formato consistente.
Nesses cenários, ter respostas em JSON estruturado é essencial. Sem outputs estruturados, você precisaria de uma lógica de parsing complexa, que pode quebrar à menor variação no formato da resposta do LLM.
Quando essa pergunta foi feita, o Google Cloud tinha acabado de lançar o Controlled generation em private preview, recurso que permite aos desenvolvedores definir o formato exato das respostas dos LLMs. Desde 05/09/2024, o Gemini 1.5 Pro e o Flash dão suporte total ao Controlled generation.
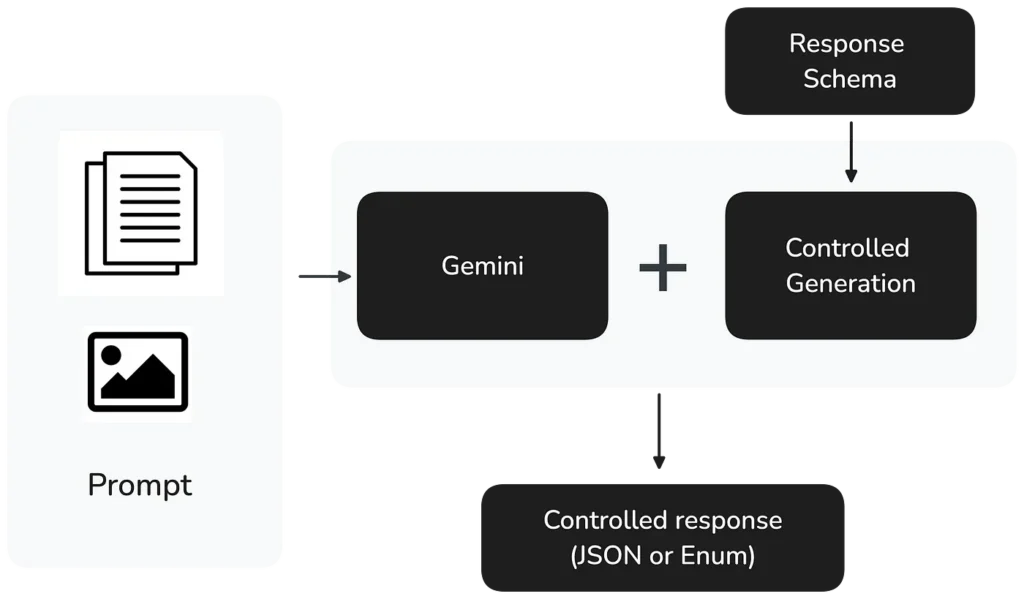
A implementação é direta — os desenvolvedores podem especificar:
- Um response MIME type para garantir um output JSON ou Enum válido
- Um response schema para definir a estrutura exata desejada
Sascha aborda o Controlled generation em mais detalhes no blog post dele. Se você quer abrir um notebook do Google Colab e começar a experimentar com código, vale conferir o artigo.
Implementando RAG com dados do Google Workspace
Pergunta original: Existe alguma forma de treinar LLMs do Google Cloud em subconjuntos dos nossos dados do Google Workspace? Por exemplo, como treinar um LLM com base no Meu Drive, em um Drive Compartilhado ou em uma pasta e, depois, consultar as informações desse dataset? Quero evitar copiar todos os dados para o GCS para o treinamento.
Retrieval Augmented Generation (RAG) é uma técnica que enriquece as respostas dos LLMs incorporando informações externas aos dados de treinamento do modelo. Em vez de depender só do que o modelo aprendeu, o RAG busca informações relevantes em documentos e dados que você fornece e usa esse contexto para gerar respostas mais precisas e contextualizadas.
Uma aplicação útil de RAG para empresas é integrá-lo aos dados do Google Workspace (Docs, Sheets, Drive etc.). Alguns cenários:
- Criar uma base de conhecimento com IA a partir da documentação interna
- Construir sistemas de suporte ao cliente que se baseiam na documentação de produto armazenada no Drive
- Desenvolver ferramentas internas de busca capazes de entender e resumir conteúdo de vários documentos do Workspace
Por exemplo, um time de vendas pode usar RAG para encontrar e resumir rapidamente case studies relevantes no Drive, ou o RH pode montar um sistema que responde dúvidas dos colaboradores com base nas políticas internas.
Como Jared mostrou no clipe abaixo, o Google Cloud oferece várias opções para implementar RAG dentro do Vertex AI:
- Vertex AI Search: gera e armazena embeddings para recuperação de documentos
- Custom retrievers: construa seu próprio sistema de retrieval
- LlamaIndex: ferramenta open source adotada pelo Google como sua solução gerenciada de RAG
Em seguida, Jared mostrou como implementar RAG com dados do Google Drive usando o LlamaIndex. Especificamente, ele:
- Criou um RAG corpus para armazenar os dados dos documentos
- Importou arquivos de uma pasta do Google Drive contendo o earnings statement do Q1 2024 da Alphabet, entre outros
- Verificou a importação conferindo a contagem de arquivos importados
- Testou o retriever perguntando: "Qual foi a receita da Alphabet no Q1 2024?"
- Gerou uma resposta usando o Gemini 1.0, que reportou com precisão a receita da Alphabet no Q1 2024 — informação extraída diretamente do statement carregado.
Mockando respostas de API para testes de LLM
Pergunta original : no Vertex AI Agent Builder , é possível mockar uma chamada de tool para fins de teste? Por exemplo, se a API que vamos usar ainda não foi desenvolvida.
Testes são importantes em qualquer desenvolvimento de software ou API, mas se tornam ainda mais críticos em aplicações baseadas em LLMs por causa da sua natureza probabilística. O mesmo prompt pode gerar respostas diferentes a cada execução, e por isso é essencial ter ambientes de teste controlados que validem um comportamento consistente do agente.
Ao mesmo tempo, testar aplicações com agentes customizados baseados em LLMs não é trivial. Esses agentes costumam interagir com APIs externas, e depender de chamadas reais durante os testes traz custos, latência e potenciais problemas de confiabilidade por conta de rate limits e indisponibilidades. Além disso, APIs externas podem retornar respostas variadas com base em dados em tempo real, dificultando o teste consistente de cenários específicos ou edge cases.
Implementar respostas de API mockadas permite que você ou os desenvolvedores testem o comportamento do agente em um ambiente controlado, garantindo ciclos de teste confiáveis e eficientes.
Eduardo apresentou uma abordagem direta para mockar respostas de API com Google Cloud Functions, com duas opções de implementação:
Função de mock separada
- Crie uma Cloud Function dedicada que sirva como API mockada
- Configure o agente para chamar essa função mock durante os testes
Mocking inline
- Implemente a resposta mockada diretamente dentro da Cloud Function existente
- Retorne respostas predefinidas em vez de fazer chamadas reais à API
Como você tem controle total sobre a função, dá para definir respostas mockadas personalizadas que correspondem à estrutura real da API, decidir quando retornar mocks ou respostas reais e manter formatos consistentes para o agente processar.
O principal cuidado é garantir que suas respostas mockadas mantenham a mesma estrutura e formato que o agente espera da API real.
Com um mocking de API bem feito, você desenvolve e testa agentes baseados em LLMs com mais eficiência, mantendo o controle do ambiente de testes.
Passando parâmetros entre agentes com o Vertex AI Agent Builder
Pergunta original: Usando o Agent Builder, como posso passar parâmetros entre agentes de forma confiável?
Imagine que você está construindo um sistema de IA em que diferentes agentes especializados precisam trabalhar juntos. Talvez um cuide das dúvidas dos clientes, outro gerencie informações de estoque e um terceiro processe pedidos. Esses agentes precisam compartilhar informações entre si de forma fluida e confiável. É aí que entra a passagem de parâmetros.
Por exemplo, quando um cliente pergunta sobre um produto, o agente de atendimento pode precisar passar o ID do produto para o agente de estoque para verificar a disponibilidade e, em seguida, repassar o ID e a quantidade para o agente de processamento de pedidos. Acertar esse fluxo de informações é fundamental para construir sistemas de IA eficazes.
Mas, embora os agentes de IA costumem ser bons em entender e compartilhar informações, sua natureza probabilística faz com que ocasionalmente possam errar nesses repasses. Em um contexto de negócio em que precisão é crucial, precisamos garantir que esses repasses sejam 100% confiáveis.
Eduardo demonstrou como passar parâmetros entre agentes com o Vertex AI Agent Builder e fala sobre validação por código ao longo do fluxo para garantir que os parâmetros corretos estão sendo passados.
O Agent Builder do Vertex AI facilita a criação de agentes de IA que trabalham juntos, mas adicionar uma validação de parâmetros adequada é o que garante que seu sistema rode de forma confiável em condições reais. Implementando um orquestrador para gerenciar a passagem de parâmetros e enriquecendo seus agentes com bons exemplos, você constrói sistemas de IA robustos que lidam com o compartilhamento de informações com confiança.
Lembre-se de implementar uma lógica de validação abrangente e manter logs detalhados das operações de passagem de parâmetros. Esse investimento inicial em um tratamento confiável de parâmetros vai economizar bastante tempo e esforço conforme suas aplicações de IA crescem e ficam mais complexas.
Conclusão
Cobrimos pouco mais da metade das perguntas feitas no nosso Q&A ao vivo sobre implementação de LLMs no Google Cloud. Esteja você dando os primeiros passos com GenAI ou buscando otimizar uma implementação que já existe, este conteúdo serve como uma boa base.
Para o conjunto completo de insights, com tópicos como processamento de documentos, melhores práticas de LLMs em apps iOS-native e estruturação de transcrições, confira nossa playlist completa no YouTube da sessão de Q&A.
Implementar LLMs no Google Cloud envolve uma combinação de tecnologia e expertise humana. Como GenAI ainda é uma tecnologia relativamente nova, contar com orientação experiente ajuda a evitar armadilhas comuns e acelera o caminho até a produção.
Se você quiser apoio na sua implementação de GenAI no Google Cloud, fale com a gente. Nosso time de especialistas em AI/ML pode te apresentar nosso GenAI Accelerator for Google Cloud, com o qual ajudamos você a construir e escalar suas aplicações baseadas em LLMs com eficiência.