Die KI-Experten von DoiT zeigen, wie Sie LLMs auf Google Cloud umsetzen. Mit Praxistipps zu Modellauswahl, Kostenkontrolle, RAG mit Google Workspace, API-Teststrategien und konkreten Schritten für Ihren GenAI-Einstieg.

Immer mehr Unternehmen wollen Large Language Models (LLMs) in ihre Produkte und Services integrieren. Entsprechend häufig erreichen uns Fragen zu folgenden Themen:
- Das passende Foundational Model für den jeweiligen Use Case auswählen,
- Wie sich die Stückkosten eines GenAI-Deployments stabil halten lassen und
- Observability von LLMs nach dem Deployment
...oder schlicht die Frage, wo man bei einem LLM-Projekt überhaupt anfangen soll.
Genau deshalb haben wir ein Live-Q&A für Google-Cloud-Kunden organisiert – quer durch alle Reifegrade in Sachen GenAI. Vom experimentellen Frühstadium bis hin zum produktiven Deployment war alles dabei. Drei AI/ML-Experten von DoiT (Eduardo Mota, Jared Burns, Sascha Heyer) standen für alle Fragen rund um die Umsetzung von LLMs auf Google Cloud bereit.
Die wichtigsten Erkenntnisse haben wir hier für Sie zusammengefasst – von den ersten Schritten mit GenAI auf Google Cloud bis hin zu fortgeschrittenen Themen wie der Nutzung Ihrer Google-Workspace-Daten für Retrieval-Augmented Generation (RAG).
Einstieg in GenAI auf Google Cloud
Ursprüngliche Frage: Wie sollte ich als Unternehmen mit GenAI auf Google Cloud starten?
Eduardo hat dazu unsere GenAI Implementation Journey skizziert – den Weg, den wir mit Unternehmen im Rahmen unserer GenAI Accelerators gehen, wenn wir maßgeschneiderte GenAI-Lösungen aufbauen.
Diese Journey reicht von der Ideenfindung bis zur Skalierung des Deployments in Produktion – inklusive Observability über den gesamten Verlauf.
Im Q&A haben wir uns auf die Phasen Ideenfindung, Prompt Design und PoC konzentriert.
Ideenfindung für GenAI-Use-Cases
Beim Brainstorming für LLM-basierte Implementierungen ist es entscheidend, dass das Vorhaben Hand in Hand mit den Geschäftszielen geht.
Diese Leitfragen bringen die Ideen ins Rollen:
- Klassifikation: "Wenn ich ______ in ________ erkennen könnte, könnte ich ________"
- Beispiel: "Wenn ich Kratzer an einem Auto auf Bildern einer Überwachungskamera erkennen könnte, ließe sich der Check-in- und Check-out-Prozess unserer Mietwagen verbessern."
- Personalisierung: "Wenn ich wüsste, welche ________ am ehesten _________, könnte ich _______"
- Beispiel: "Wenn ich wüsste, welche Services Kunden am ehesten halten, könnte ich personalisierte Retention-Angebote machen."
- Expertensysteme: "Wenn ich ________ anhand von _________ identifizieren könnte, könnte ich ___________"
- Beispiel: "Wenn ich die Customer Persona anhand individueller historischer Daten identifizieren könnte, könnte ich passgenaue Empfehlungen geben."
Generell raten wir Unternehmen, beim Brainstorming für GenAI-Implementierungen eher in personalisierten Erlebnissen zu denken als in generischen Prozessen.
Ein Beispiel:
- Generisch: Wir wollen Kunden ermöglichen, online Essen zu bestellen, mit Wiederbestellung früherer Orders und Up-Sells nach Marketing-Personas.
- Personalisiert: Wenn wir die individuellen Daten eines Kunden mit Restaurantinformationen kombinieren, schaffen wir ein hochwertiges Bestellerlebnis, das die Bestellzeit verkürzt und Up-Sells mit hohem Mehrwert ermöglicht.
Wer eher aus dem Business als aus der Technik kommt, kann auch den GenAI Navigator von Google Cloud nutzen. Er stellt Fragen zu drei Bereichen (Strategy, Infrastructure, Skills) und gibt darauf basierend Empfehlungen, wie Sie mit GenAI auf Google Cloud starten können.
LLM Prompt Design
Sobald klar ist, was Sie umsetzen wollen, geht es ans Experimentieren mit Prompts in Vertex AI Studio – dafür gibt es 300 USD an kostenlosen Credits und über Initiativen wie das AI Startup Program von Google Cloud sogar noch mehr.
Aber: Experimentieren um des Experimentierens willen bringt nichts. Sie sollten ein klares Ziel vor Augen haben und den Schritten folgen, die Eduardo für den Prompt-Design-Prozess hervorgehoben hat:
Definieren Sie den gewünschten Output: Halten Sie klar fest, was Ihr Modell liefern soll – von Klassifikationsergebnissen über personalisierte Empfehlungen bis hin zu komplexen Analysen.
Setzen Sie Sicherheitsmaßnahmen um: Bauen Sie Schutzmechanismen ein gegen Risiken wie Prompt Injection und fehlerhafte LLM-Outputs. Welche Risiken Sie kennen sollten, haben wir in einer früheren Folge des Cloud-Masters-Podcasts zu LLM-Sicherheitsrisiken und Mitigation-Strategien ausführlich behandelt.
Identifizieren Sie den nötigen Kontext für den gewünschten Output: Fragen Sie sich, welche Informationen das Modell braucht – Daten, Hintergrundwissen, konkrete Anweisungen –, um das gewünschte Ergebnis zu liefern.
Erstellen Sie 2–3 Prompts mit unterschiedlichen Techniken: Probieren Sie Ansätze wie Few-Shot Learning, Chain-of-Thought-Reasoning oder Multi-Prompt-Ansätze aus. Jede Technik kann andere Ergebnisse liefern – es lohnt sich, verschiedene Methoden zu testen.
Bewerten Sie die Prompts mit verschiedenen Modellen: In Vertex AI Studio steht Ihnen eine breite Auswahl an Modellen zur Verfügung. Testen Sie mehrere davon! So sehen Sie, wie unterschiedliche Modelle auf Ihre Prompts reagieren, und können auf Performance und Genauigkeit hin optimieren.
GenAI Proof of Concept (PoC)
Nach den ersten Experimenten mit Prompt Design folgt der Proof of Concept. Eduardo hat mehrere Schlüsselanforderungen für einen erfolgreichen PoC herausgearbeitet:
- Klare Erfolgskriterien definieren
- Eine Testgruppe von mindestens 10 Nutzern aufbauen
- Managed Services von Google nutzen, etwa text-bison, Gemini, Cloud Functions usw.
- Nutzerfeedback einholen
- Performance-Metriken festlegen
- Performance-Benchmarks definieren
Wie Eduardo gegenüber Data Science Central erklärt hat, ist das Feedback der ersten Testgruppe extrem wichtig. "Sie wollen Feedback von Nutzern bekommen, auch wenn die Erfahrung nicht positiv war. Stellen Sie sicher, dass Sie Standard-Benchmarks definiert haben, und überwachen Sie jeden Input und Output Ihrer GenAI. Allein durch die Auswertung dieser Punkte gewinnen Sie Erkenntnisse darüber, welche Anpassungen an Ihren workloads nötig sind, um die Qualität auf das nächste Level zu heben." Ziel ist es, durch Feedback schnell zu iterieren und Lücken in der Customer Experience zu schließen.
In einer früheren Folge des Cloud-Masters-Podcasts haben Sascha und Eduardo zudem erläutert, warum Observability für Metriken wie LLM-Inputs, -Outputs und -Requests so wichtig ist.
Wenn Sie schnell mit GenAI loslegen wollen, aber noch nicht so weit sind, einen PoC mit eigenen Daten zu entwickeln, bietet Google Cloud Jump-Start-Lösungen.
Das sind One-Click-Open-Source-Deployments, die:
- eine einsatzbereite Infrastructure as Code in einem GitHub-Repository bereitstellen,
- ein einfaches Deployment im eigenen Projekt ermöglichen und
- eine vollständige End-to-End-Architektur bieten, die Sie erkunden und anpassen können.
Das Diagramm unten zeigt zum Beispiel die Architektur der Anwendungsinfrastruktur für eine GenAI-Knowledge-Base-Lösung aus dem entsprechenden Jump Start von Google Cloud:

JSON-Outputs mit Vertex AI generieren
Ursprüngliche Frage: Wie bekomme ich LLM-Antworten in JSON mit klar definiertem Format?
LLM-Outputs sind häufig unstrukturiert. Diese Flexibilität ist bei kreativen oder dialogorientierten Aufgaben nützlich, wird aber zum Problem, sobald produktive Anwendungen die Antworten programmatisch verarbeiten und darauf reagieren müssen.
Stellen Sie sich vor, Sie bauen ein Produktempfehlungssystem für E-Commerce, bei dem jede Empfehlung definierte Attribute wie Preis, Kategorie und Verfügbarkeit braucht – mit unstrukturierten Daten kaum machbar. Oder ein Customer-Support-System, das Ticketdetails, Prioritätsstufen und vorgeschlagene Maßnahmen in einem konsistenten Format extrahieren muss.
In solchen Szenarien sind Antworten in einem strukturierten JSON-Format unverzichtbar. Ohne strukturierte Outputs bräuchten Sie komplexe Parsing-Logik, die schon bei kleinsten Abweichungen im Antwortformat des LLM bricht.
Zum Zeitpunkt der Frage hatte Google Cloud gerade Controlled Generation in Private Preview veröffentlicht. Damit können Entwickler exakte Output-Formate für ihre LLM-Antworten festlegen. Seit dem 5. September 2024 unterstützen Gemini 1.5 Pro und Flash Controlled Generation vollständig.
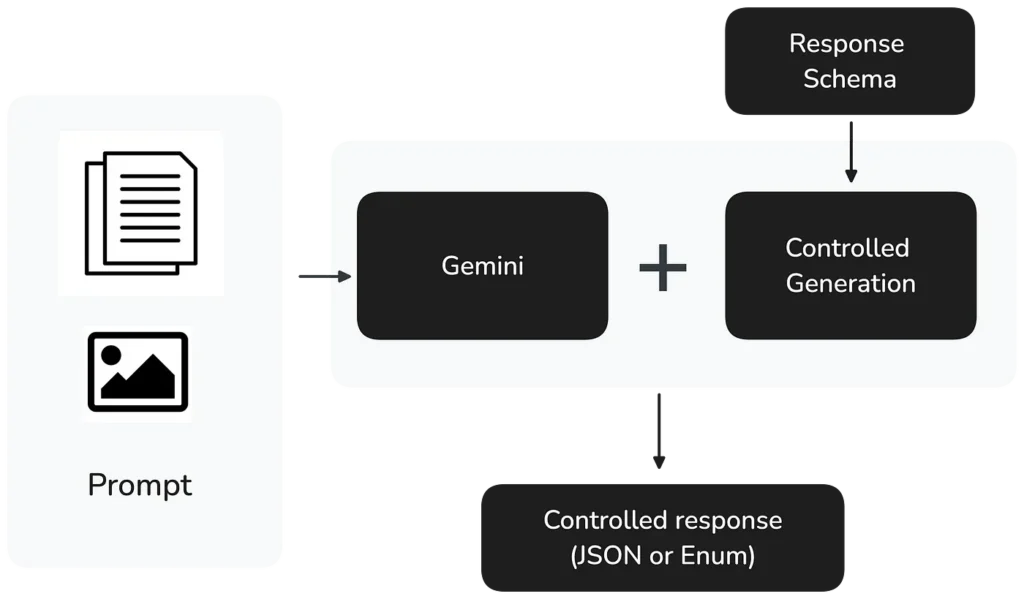
Die Umsetzung ist unkompliziert – Entwickler können Folgendes festlegen:
- Einen Response-MIME-Type, der gültige JSON- oder Enum-Outputs sicherstellt
- Ein Response-Schema, das die exakt benötigte Struktur definiert
Sascha geht in seinem Blogpost ausführlicher auf Controlled Generation ein. Wenn Sie direkt in ein Google-Colab-Notebook eintauchen und mit Code experimentieren wollen, lohnt sich der Artikel.
RAG mit Google-Workspace-Daten umsetzen
Ursprüngliche Frage: Gibt es eine Möglichkeit, Google-Cloud-LLMs auf Teilmengen unserer Google-Workspace-Daten zu trainieren? Zum Beispiel: Wie kann ich ein LLM auf Basis von My Drive oder einem Shared Drive bzw. Ordner trainieren und anschließend Informationen aus diesem Datensatz abfragen? Ich möchte vermeiden, alle Daten für das Training nach GCS zu kopieren.
Retrieval Augmented Generation (RAG) ist eine Technik, mit der Sie LLM-Antworten anreichern können, indem Sie Informationen einbeziehen, die nicht in den Trainingsdaten des Modells stecken. Statt sich allein auf die Trainingsdaten zu verlassen, ruft RAG relevante Informationen aus den von Ihnen bereitgestellten Dokumenten und Daten ab und nutzt sie, um genauere, kontextbezogene Antworten zu erzeugen.
Eine sinnvolle Anwendung für Unternehmen ist die Integration von RAG mit ihren Google-Workspace-Daten (Docs, Sheets, Drive usw.). Das eignet sich zum Beispiel für:
- den Aufbau einer KI-gestützten Wissensdatenbank aus interner Dokumentation
- Customer-Support-Systeme, die auf in Drive abgelegter Produktdokumentation basieren
- interne Suchwerkzeuge, die Inhalte über mehrere Workspace-Dokumente hinweg verstehen und zusammenfassen
Ein Vertriebsteam könnte RAG zum Beispiel nutzen, um relevante Case Studies aus dem Drive schnell zu finden und zusammenzufassen. Die HR-Abteilung könnte ein System aufbauen, das Mitarbeiterfragen anhand interner Richtlinien beantwortet.
Wie Jared im folgenden Clip zeigt, bietet Google Cloud mehrere Optionen, um RAG innerhalb von Vertex AI umzusetzen:
- Vertex AI Search: erzeugt und speichert Embeddings für die Dokumentensuche
- Custom Retrievers: bauen Sie Ihr eigenes Retrieval-System
- LlamaIndex: ein Open-Source-Tool, das Google als Managed-RAG-Lösung übernommen hat
Anschließend hat Jared exemplarisch RAG mit Google-Drive-Daten via LlamaIndex umgesetzt. Konkret hat er:
- einen RAG Corpus angelegt, um die Dokumentdaten zu speichern,
- Dateien importiert aus einem Google-Drive-Ordner mit dem Q1-2024-Earnings-Statement von Alphabet und weiteren Dateien,
- den Import durch Prüfen der Anzahl importierter Dateien verifiziert,
- die Retriever-Funktion mit der Frage getestet: "What was Alphabet's revenue for Q1 2024?",
- eine Antwort mit Gemini 1.0 erzeugt, die den Q1-2024-Umsatz von Alphabet korrekt wiedergegeben hat – die Information wurde direkt aus dem hochgeladenen Statement gezogen.
API-Antworten für LLM-Tests mocken
Ursprüngliche Frage: Ist es im Vertex AI Agent Builder möglich, einen Tool-Call für Testzwecke zu mocken? Zum Beispiel, wenn die API, die wir später nutzen wollen, noch nicht entwickelt ist.
Tests sind in der Softwareentwicklung und bei APIs grundsätzlich wichtig, bei LLM-basierten Anwendungen aber besonders kritisch – wegen ihrer probabilistischen Natur. Derselbe Prompt kann jedes Mal andere Antworten liefern. Umso wichtiger sind kontrollierte Testumgebungen, die ein konsistentes Agent-Verhalten validieren.
Gleichzeitig ist das Testen bei LLM-basierten Custom Agents nicht trivial. Diese Agents müssen häufig mit externen APIs interagieren. Echte API-Calls im Test verursachen jedoch Kosten, Latenz und potenzielle Zuverlässigkeitsprobleme durch Rate Limits und Service-Ausfälle. Hinzu kommt: Externe APIs liefern je nach Echtzeitdaten unterschiedliche Antworten, was es erschwert, bestimmte Szenarien oder Edge Cases konsistent zu testen.
Mit gemockten API-Antworten können Sie bzw. Ihre Entwickler das Verhalten der Agents in einer kontrollierten Umgebung testen und so zuverlässige, effiziente Testzyklen sicherstellen.
Eduardo hat einen pragmatischen Ansatz für das Mocken von API-Antworten mit Google Cloud Functions skizziert und zwei Varianten vorgestellt:
Separate Mock-Funktion
- Erstellen Sie eine eigene Cloud Function, die als Mock-API dient
- Konfigurieren Sie den Agent so, dass er diese Mock-Funktion während der Tests aufruft
Inline-Mocking
- Implementieren Sie die Mock-Antwort direkt in der bestehenden Cloud Function
- Geben Sie vordefinierte Antworten zurück, statt echte API-Calls auszuführen
Da Sie die Implementierung der Funktion vollständig im Griff haben, können Sie eigene Mock-Antworten definieren, die zur echten API-Struktur passen, festlegen, wann Mock- und wann echte Antworten zurückgegeben werden, und konsistente Antwortformate für die Verarbeitung durch den Agent sicherstellen.
Wichtig ist vor allem: Ihre Mock-Antworten müssen dieselbe Struktur und dasselbe Format haben, wie der Agent sie von der echten API erwartet.
Mit sauberem API-Mocking entwickeln und testen Sie Ihre LLM-basierten Agents effizienter und behalten gleichzeitig die volle Kontrolle über Ihre Testumgebung.
Parameter zwischen Agents im Vertex AI Agent Builder weitergeben
Ursprüngliche Frage: Wie kann ich mit dem Agent Builder zuverlässig Parameter zwischen Agents weitergeben?
Stellen Sie sich vor, Sie bauen ein KI-System, in dem verschiedene spezialisierte Agents zusammenarbeiten. Ein Agent kümmert sich um Kundenanfragen, ein zweiter um Bestandsinformationen, ein dritter um die Bestellabwicklung. Diese Agents müssen Informationen reibungslos und zuverlässig austauschen – genau dafür ist die Parameterübergabe da.
Wenn ein Kunde zum Beispiel ein Produkt bestellen möchte, muss der Customer-Service-Agent womöglich die Produkt-ID an den Inventory-Agent übergeben, um die Verfügbarkeit zu prüfen, und anschließend Produkt-ID und Menge an den Order-Processing-Agent weiterreichen. Dass dieser Informationsfluss sauber funktioniert, ist entscheidend für effektive KI-Systeme.
Zwar sind KI-Agents grundsätzlich gut darin, Informationen zu verstehen und weiterzugeben – aufgrund ihrer probabilistischen Natur kann es aber vorkommen, dass sie Übergaben fehlerhaft handhaben. In einem geschäftlichen Kontext, in dem Genauigkeit zählt, brauchen wir Wege, diese Übergaben zu 100 % zuverlässig zu machen.
Eduardo hat live gezeigt, wie sich Parameter im Vertex AI Agent Builder zwischen Agents übergeben lassen, und erläutert, wie man Validierungen in den Code des gesamten Flows einbaut, damit garantiert die richtigen Parameter weitergegeben werden.
Der Agent Builder von Vertex AI macht es zwar leicht, KI-Agents zu erstellen, die zusammenarbeiten – mit einer sauberen Parameter-Validierung läuft Ihr System aber auch unter realen Bedingungen zuverlässig. Mit einem Orchestrator für die Parameterübergabe und gut gewählten Beispielen für Ihre Agents bauen Sie robuste KI-Systeme, die Informationen verlässlich teilen.
Setzen Sie auf umfassende Validierungslogik und führen Sie detaillierte Logs der Parameterübergaben. Diese anfängliche Investition in zuverlässiges Parameter-Handling spart erheblich Zeit und Aufwand, wenn Ihre KI-Anwendungen wachsen und komplexer werden.
Fazit
Wir haben hier knapp die Hälfte der Fragen aus unserem Live-Q&A zur Implementierung von LLMs auf Google Cloud abgedeckt. Egal, ob Sie gerade erst mit GenAI starten oder Ihr bestehendes Setup optimieren wollen – das hier sollte Ihnen ein solides Fundament liefern.
Die vollständigen Insights – inklusive Themen wie Dokumentenverarbeitung, LLM-Best-Practices für iOS-native Apps und Transkript-Strukturierung – finden Sie in unserer vollständigen YouTube-Playlist zur Q&A-Session.
Die Implementierung von LLMs auf Google Cloud ist immer ein Zusammenspiel aus Technologie und menschlicher Expertise. Da GenAI noch eine recht junge Technologie ist, hilft erfahrene Begleitung, typische Stolperfallen zu vermeiden und schneller in die Produktion zu kommen.
Wenn Sie Unterstützung bei Ihrer GenAI-Implementierung auf Google Cloud möchten, sprechen Sie unser Team aus AI/ML-Experten an – im Rahmen unseres GenAI Accelerator for Google Cloud helfen wir Ihnen, Ihre LLM-basierten Anwendungen effizient zu bauen und zu skalieren.