Du simple à la grande échelle
Cet article s'adresse aux débutants en ML qui ont appris à utiliser les Jupyter Notebooks et se demandent désormais comment passer à un système prêt pour la production en s'appuyant sur les services AWS.
Vous avez démarré en local, avec une configuration légère, mais il est temps de passer aux systèmes distribués capables d'absorber les charges importantes, comme :
- Glue pour la transformation et le catalogue de métadonnées
- Athena pour interroger directement les buckets S3
- QuickSight pour la visualisation analytique
- Sagemaker Instances pour l'entraînement parallélisé
- Sagemaker Endpoints pour des serveurs d'inférence versionnés et auto-scalés
Partir des Notebooks
Les Jupyter Notebooks sont une merveille pour le Machine Learning : un IDE en ligne qui conserve l'état des variables locales en mémoire, ce qui permet de travailler avec ce type de processus de longue durée propre au ML. Les Sagemaker Notebooks ( Console ; Docs) offrent un environnement managé pour les lancer rapidement. Vous pouvez tout y faire : charger les données, les explorer, les prétraiter, les visualiser, entraîner, évaluer et déployer — le tout dans un même espace mémoire, gage de simplicité et de rapidité.
Services AWS distribués
Au-delà du Notebook, les choses se compliquent : il faut coordonner toute une série de services distribués, intégrer chaque composant et s'assurer qu'ils s'authentifient mutuellement.
Difficile dès lors de garder une vision claire de ce qui se passe tout au long du processus ML. D'abord parce que l'état du processus est distribué (principalement dans des buckets S3), ensuite à cause des longues attentes lors du déclenchement des services AWS et du traitement de gros volumes de données.
Dans cet article, j'explique comment opérer cette transition, étape par étape.
Franchir le pas
Un environnement interactif unique ne convient pas pour faire tourner des systèmes en production. À un moment donné, il faut passer du Notebook au système distribué.
Voici un exemple pour montrer comment isoler chaque composant à mesure que vous progressez vers un système de production. Nous prendrons comme support ce Notebook open source. Dans cet article, vous verrez comment l'exécuter pas à pas dans une instance Sagemaker Notebook — ou plus simplement encore, dans le nouveau Sagemaker Studio ( Console ; Docs). Pour chaque type de fonctionnalité, j'extrais un ou deux extraits de code du Notebook, puis je les compare au système distribué qui assure la même fonction au sein d'AWS. Dans certains cas, ce Notebook utilise déjà AWS, en invoquant Sagemaker pour l'entraînement et le déploiement ; je montre alors comment passer d'une simple exécution locale aux APIs Sagemaker, puis à un système orchestré en dehors du Notebook.
Ingestion
La première étape consiste à faire entrer les données dans votre système.
Dans un Notebook
Dans un Notebook, vous chargez simplement un fichier CSV (ou un autre format) directement sur votre disque, pour le traiter en mémoire.
# Extrait du Notebook d'exemple
with zipfile.ZipFile('bank-additional.zip', 'r') as zip_ref:
zip_ref.extractall('.')
Avec les services AWS
Sur des projets à grande échelle, les ressources locales de votre petite instance Notebook seraient vite saturées.
Prenez plutôt le CSV (ou vos autres données) et placez-le dans un bucket S3 ( Console ; Docs) qui représente la source de vos données. Pour des sources statiques, déposez-les directement dans S3 ; pour une ingestion continue par streaming, utilisez Kinesis ( Console ; Docs) qui écrira dans S3.
S3 est l'emplacement habituel pour stocker les données ML
Schémas
Vient ensuite l'identification du schéma : vous disposez d'un gros bloc de données (qui semble non structuré vu de l'extérieur) et vous voulez pouvoir l'interroger et le manipuler selon sa structure interne (généralement un format tabulaire en lignes et colonnes).
Dans un Notebook
Dans le Notebook, le schéma est identifié automatiquement à partir de la ligne d'en-tête du CSV lors du chargement dans un Dataframe.
# Extrait du Notebook d'exemple
data = pd.read_csv(‘./bank-additional/bank-additional-full.csv’)
Avec les services AWS
Dans AWS, créez un Glue Crawler ( Console ; Docs) pour identifier le schéma du CSV à partir des en-têtes de colonnes.
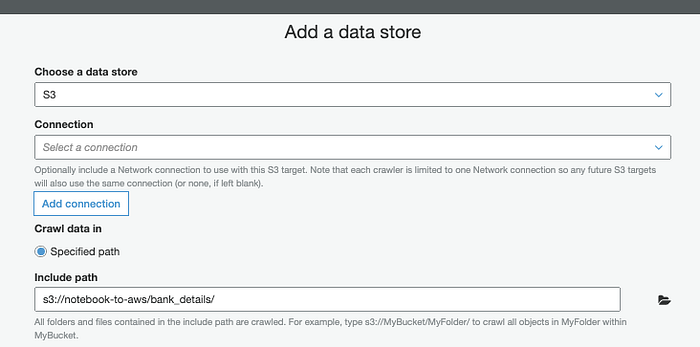
Identifier la structure avec Glue Crawler
Glue Crawler insère le schéma dans le Glue Data Catalog ( Console ; Docs). Lors des étapes suivantes (voir ci-dessous), Athena, Databrew, Quicksight et d'autres services pourront traiter ces objets S3 comme des données structurées.
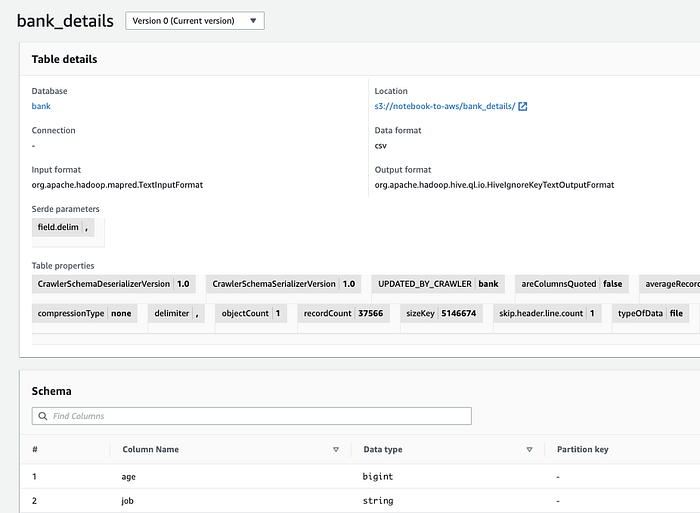
Le schéma de nos données d'exemple dans le Data Catalog
Lake Formation ( Console ; Docs) contrôle ensuite l'accès à ces tables du Data Catalog.
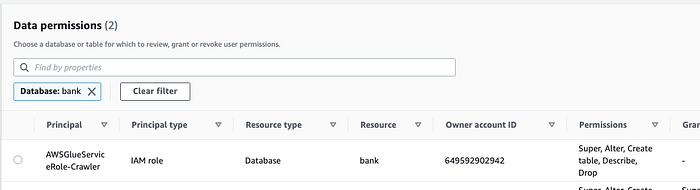
Ici, nous avons donné l'accès à Glue afin qu'il puisse parcourir les schémas. Nous pouvons aussi l'accorder à des utilisateurs humains.
Analyse exploratoire des données
Vient ensuite l'étape où l'on identifie des motifs dans les données et où on les transforme pour en faire une entrée ML utile.
Dans un Notebook
Même en production, on peut accomplir beaucoup avec un sous-ensemble échantillonné aléatoirement et de taille raisonnable, exploré dans un Notebook.
Avec Pandas, par exemple, vous pouvez analyser les distributions de fréquence.
# Extrait du Notebook d'exemple
for column in data.select_dtypes(include=[‘object’]).columns:
display(...)
La visualisation tire parti des centres de traitement visuel du cerveau humain pour faire ressortir les motifs. Vous pouvez visualiser les données dans un Notebook : histogrammes, cartes de chaleur, matrices de dispersion, etc., grâce à Seaborn et à d'autres bibliothèques.
# Extrait du Notebook d'exemple
for column in data.select_dtypes(exclude=['object']).columns:
...
hist = data[[column, 'y']].hist(by='y', bins=30)
plt.show()# Extrait du Notebook d'exemple
pd.plotting.scatter_matrix(data, figsize=(12, 12))
Avec les services AWS
Dans AWS, Athena ( Console ; Docs) vous permet d'explorer directement l'ensemble des données avec du bon vieux SQL. Athena s'appuie sur le schéma enregistré dans le Glue Data Catalog pour interroger la structure des objets S3.
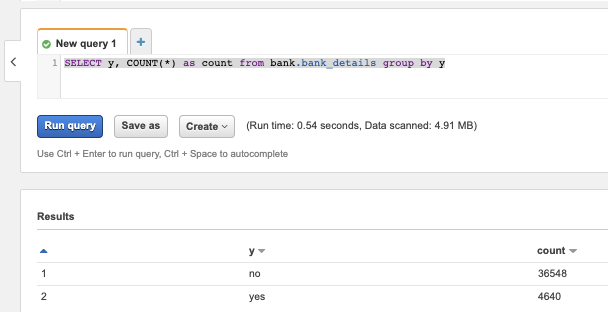
Cette simple requête nous montre que les classes du jeu de données sont déséquilibrées, ce qui nous amènera à régler le paramètre weight de XGBoost en conséquence.
Pour la visualisation, utilisez Quicksight ( Console ; Docs), directement par-dessus vos requêtes Athena. Ces visualisations ont l'avantage d'être facilement partageables avec d'autres personnes — par exemple des analystes métier, qui peuvent apporter leur expertise.
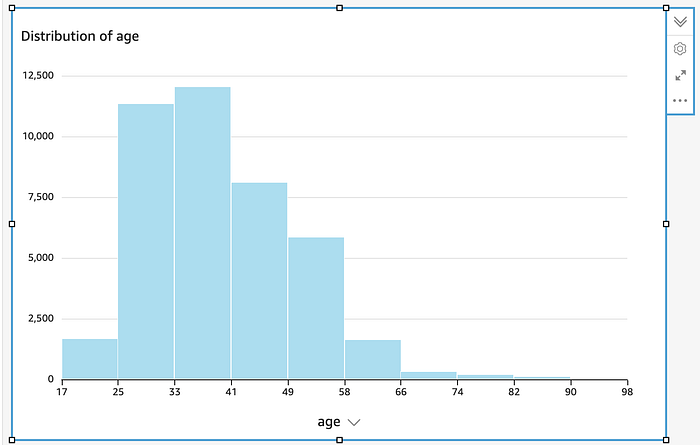
Dans QuickSight, choisissez l'option histogram et pointez-la sur la colonne age
QuickSight a généré cet histogramme automatiquement une fois pointé sur la colonne age
Transformation
Dans un Notebook
Dans votre Notebook, vous exploitez les enseignements de l'EDA pour transformer les données en une forme exploitable comme entrée pour votre algorithme d'entraînement, à l'aide d'APIs qui fonctionnent avec les Dataframes Pandas :
- normalisation des données numériques
- encodage one-hot des données catégorielles
# Extrait du Notebook d'exemple
# Convertir les variables catégorielles en ensembles d'indicateurs
# (One-hot)
model_data = pd.get_dummies(data)
- fonctions arithmétiques comme la multiplication et le modulo
- suppression de colonnes
# Extrait du Notebook d'exemple
model_data = model_data.drop([‘duration’, ...], axis=1)
- suppression des valeurs aberrantes
- manipulation de chaînes de caractères
- et bien plus
Vous convertissez ensuite les données dans un format qui accélère le ML, comme Parquet ou libsvm.
Avec les services AWS
Pour passer à l'échelle, AWS met à disposition plusieurs outils de transformation :
DataBrew ( Console ; Docs) est un constructeur graphique de transformations — l'un des rares qui, d'après mon expérience, fonctionne réellement bien. Il lit vos données S3 telles que définies dans le Glue Data Catalog. Vous choisissez parmi un éventail de transformations comme le one-hot, la normalisation et d'autres déjà mentionnées plus haut dans le contexte des Notebooks.
DataBrew génère des transformations qui s'exécutent dans le framework Glue. En dernière étape, les données peuvent être converties dans le format ML souhaité : Parquet, Avro, CSV ou JSON.
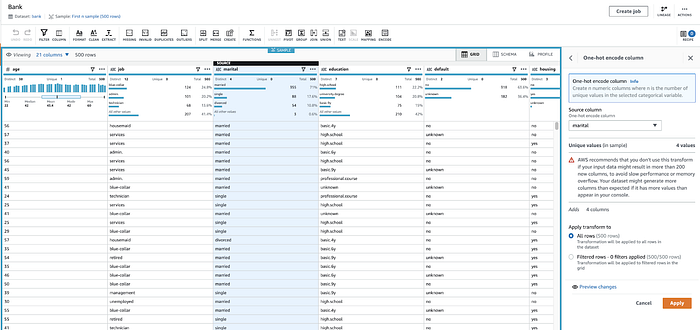
Ici, DataBrew applique l'encodage one-hot au champ marital (pour créer des champs binaires 1/0 distincts pour single, divorced, etc.)
Autre option : Glue Studio ( Console ; Docs) propose un outil graphique de transformation — sans toutefois les transformations orientées ML de DataBrew comme le one-hot — et vous permet d'écrire votre propre code de transformation en Python ou Scala, exécuté sur Apache Spark.

Un constructeur de transformations dans Glue Studio, qui s'articule avec votre propre code Spark.
Entraînement
Sans Sagemaker
Vous exécutez peut-être des algorithmes comme XGBoost directement dans la mémoire de votre Notebook. C'est très pratique pour un développement interactif et rapide.
Voyez par exemple cette invocation locale de XGBoost sans Sagemaker.
# Extrait d'un Notebook sans Sagemaker
from xgboost import XGBClassifier # Package non Sagemaker
...
model = XGBClassifier(… )
...
model.fit(...)
Avec Sagemaker
Justement, notre Notebook d'exemple est déjà configuré pour invoquer le SDK Sagemaker ( Docs), et si ce n'est pas votre cas, c'est l'étape suivante la plus simple. L'API est ici la même que pour d'autres bibliothèques open source qui exécutent le même algorithme — il suffit d'importer une bibliothèque différente.
# Avec Sagemaker (extrait du Notebook d'exemple)
from sagemaker.estimator import Estimator # Package différent
...
xgb = Estimator...
...
xgb.fit(...) # Même API
Le SDK Sagemaker permet à la fois l'entraînement local et distant : vous pouvez entraîner en mode local pour itérer rapidement pendant le développement (ce que vous faisiez peut-être déjà), puis, à mesure que vous montez en charge, utiliser le SDK pour déclencher l'entraînement sur des Sagemaker instances ( Console ; Docs) spécialisées, avec des fonctionnalités puissantes comme l'entraînement distribué sur plusieurs instances.
Avec ce même SDK, vous pouvez aussi appeler les algorithmes avec le tuning des hyperparamètres ( Docs) : le même algorithme est exécuté plusieurs fois, chaque fois avec un jeu de paramètres différent, à la recherche de ceux qui donnent les meilleurs résultats.
Déploiement et évaluation
Sans Sagemaker
Si vous entraînez en local, sans Sagemaker, aucun déploiement n'est nécessaire : vous exécutez l'inférence directement dans votre espace mémoire. Vous pouvez par exemple évaluer les performances en lançant l'inférence (predict()) sur un jeu de validation.
# Extrait d'un Notebook sans Sagemaker
y_pred = model.predict(X_test) # Modèle XGBClassifier créé plus haut
...
pd.crosstab(…) # Évaluer la matrice de confusion avec Pandas
Avec Sagemaker
Avec Sagemaker, vous voudrez déployer sur un Endpoint, un ensemble d'instances qui répond aux requêtes d'inférence ( Console), comme dans notre Notebook d'exemple.
# Avec Sagemaker (extrait du Notebook d'exemple)
xgb_predictor = xgb.deploy(…) # Estimator créé plus haut
Pour la mise à l'échelle, vous pouvez ajouter d'autres instances d'inférence ou les configurer en autoscale, et solliciter davantage de puissance de calcul à la demande grâce à Elastic Inference.
Lorsque vous redéployez une nouvelle version du modèle, vous comparez ses performances sur un nouvel endpoint, grâce à la prise en charge de l'A/B testing par Sagemaker.
Lancez l'inférence sur l'endpoint avec predict(), exactement comme dans le code sans Sagemaker. Vous pouvez évaluer les résultats en exécutant l'inférence sur un jeu de validation, puis en calculant les métriques avec Pandas et d'autres APIs en mémoire.
# Avec Sagemaker (extrait du Notebook d'exemple)
xgb_predictor.predict(…)
pd.crosstab(…) # Évaluer la matrice de confusion avec Pandas
Mais c'est encore dans un Notebook !
Notre objectif était de quitter le Notebook pour gagner les systèmes scalables d'AWS ; vous vous demandez peut-être pourquoi les dernières étapes étaient encore dans un Notebook.
D'un côté, ces étapes clés invoquaient bel et bien des APIs distribuées Sagemaker, plutôt que de s'exécuter en local : elles sont donc pleinement scalables. Dans un workflow basique, où vous réentraînez et redéployez le modèle à la main de temps à autre, elles pourraient même convenir à un système manuel et non automatisé.
De l'autre, dans un processus ML de production typique, les nouvelles versions du modèle doivent être réentraînées et redéployées en continu, à l'image de la compilation et des tests logiciels via un pipeline d'intégration continue / déploiement continu. Pour cela, vous définissez en JSON votre graphe orienté acyclique d'étapes de traitement ML, incluant par exemple le nettoyage des données, le prétraitement, l'entraînement, le déploiement et les APIs d'évaluation. ( Voici un exemple utile pour mettre en place un Pipeline.) Vous pouvez réutiliser votre code existant, car le code des Notebooks n'est que du Python et peut s'exécuter n'importe où, y compris dans un pipeline.
Le Notebook est un outil puissant pour le développement, mais à mesure que vous passez en production, il vous faudra une infrastructure plus solide. Cet article vous montre comment isoler les composants un à un, tout en vous permettant de continuer à travailler avec le Notebook pendant que le système principal tourne de manière autonome.
J'espère que cet article vous aura aidé à monter en puissance vers de grands systèmes de production.
— — —
P.S. Cet article s'appuie sur mon expérience AWS AI/ML Black Belt, une certification avancée qui va plus loin que la certification AWS Certified ML Specialty basée sur un examen. Le Black Belt comprend un cours avancé et un projet Capstone final qui sert de base à la certification. C'est une excellente façon de développer puis de démontrer vos compétences dans les domaines évoqués ci-dessus. Voir un article plus détaillé à ce sujet ici.
Merci de votre lecture ! Pour rester en contact, suivez-nous sur le DoiT Engineering Blog , la page LinkedIn DoiT et le compte Twitter DoiT . Pour découvrir les opportunités de carrière, rendez-vous sur https://careers.doit-intl.com .