Vom Kleinen zum Großen
Dieser Beitrag richtet sich an ML-Einsteiger, die bereits mit Jupyter Notebooks vertraut sind und nun wissen möchten: Wie komme ich von dort zu einem produktionsreifen System auf AWS?
Sie haben schlank und lokal angefangen – jetzt brauchen Sie verteilte Systeme, die auch große Lasten stemmen, etwa:
- Glue für Transformation und Metadatenkatalog
- Athena für direkte Abfragen auf S3-Buckets
- QuickSight zur Visualisierung von Analysen
- Sagemaker Instances für parallelisiertes Training
- Sagemaker Endpoints für versionierte, autoskalierende Inferenz-Server
Im Notebook beginnen
Jupyter Notebooks sind ein Glücksfall für Machine Learning: eine Online-IDE, die den Zustand lokaler Variablen im Speicher hält – ideal für die langlaufenden Prozesse, die für ML typisch sind. Sagemaker Notebooks ( Console; Docs) liefern Ihnen eine verwaltete Umgebung, die sich im Handumdrehen hochfährt. Dort erledigen Sie alles in einem einzigen Speicherbereich – komfortabel und schnell: Daten laden, erkunden, vorverarbeiten, visualisieren, trainieren, evaluieren und deployen.
Verteilte AWS-Dienste
Außerhalb des Notebooks wird es anspruchsvoller: Sie müssen eine Reihe schwergewichtiger verteilter Dienste koordinieren, jeden Baustein integrieren und dafür sorgen, dass sie sich gegenseitig authentifizieren.
Den Überblick über den ML-Prozess zu behalten, ist nicht leicht. Erstens, weil der Zustand des Prozesses verteilt liegt (meist in S3-Buckets), und zweitens wegen der langen Wartezeiten, während AWS-Dienste angestoßen werden und große Datenmengen verarbeitet werden.
In diesem Beitrag zeige ich, wie Sie diesen Übergang Schritt für Schritt meistern.
Der Übergang
Eine einzelne interaktive Umgebung taugt nicht für den Produktionsbetrieb. Irgendwann müssen Sie vom Notebook zu einem verteilten System wechseln.
Ich möchte an einem Beispiel zeigen, wie Sie Stück für Stück einzelne Komponenten herauslösen, während Sie sich in Richtung Produktionssystem bewegen. Wir veranschaulichen das anhand dieses Open-Source-Notebooks. In diesem Artikel sehen Sie, wie Sie es Schritt für Schritt in einer Sagemaker-Notebook-Instanz durchspielen – oder noch einfacher im neuen Sagemaker Studio ( Console; Docs). Für jede Funktionalität greife ich ein bis zwei Code-Snippets aus dem Notebook heraus und stelle ihnen das verteilte System gegenüber, das in AWS dieselbe Funktion bereitstellt. In manchen Fällen nutzt das Notebook bereits AWS, indem es Sagemaker für Training und Deployment aufruft; dann erkläre ich, wie Sie von der einfachen lokalen Ausführung zu den Sagemaker-APIs hochskalieren – und darüber hinaus zu einem System, das außerhalb des Notebooks orchestriert wird.
Ingestion
Der erste Schritt: die Daten ins System bringen.
Im Notebook
Im Notebook laden Sie eine CSV- oder andere Datei einfach direkt auf die Festplatte und verarbeiten sie im Speicher.
# From the example Notebook
with zipfile.ZipFile('bank-additional.zip', 'r') as zip_ref:
zip_ref.extractall('.')
Mit AWS-Diensten
Bei großen Projekten wären die lokalen Ressourcen Ihrer kleinen Notebook-Instanz schnell am Limit.
Legen Sie die CSV oder andere Daten stattdessen in einen S3-Bucket ( Console; Docs), der den Ursprung Ihrer Daten abbildet. Bei statischen Datenquellen geht das direkt nach S3; für die laufende Aufnahme per Streaming nutzen Sie Kinesis ( Console; Docs), das die Ausgabe nach S3 schreibt.
S3 ist der typische Speicherort für ML-Daten
Schemas
Als Nächstes folgt die Schemaerkennung: Sie haben einen großen Datenklumpen, der von außen unstrukturiert wirkt, und möchten ihn anhand seiner inneren Struktur (in der Regel ein tabellarisches Zeilen-/Spalten-Format) abfragen und bearbeiten.
Im Notebook
Im Notebook wird das Schema beim Laden in einen Dataframe automatisch aus der CSV-Header-Zeile erkannt.
# From the example Notebook
data = pd.read_csv(‘./bank-additional/bank-additional-full.csv’)
Mit AWS-Diensten
In AWS richten Sie einen Glue Crawler ein ( Console; Docs), der das Schema dieser CSV anhand der Spaltenüberschriften erkennt.
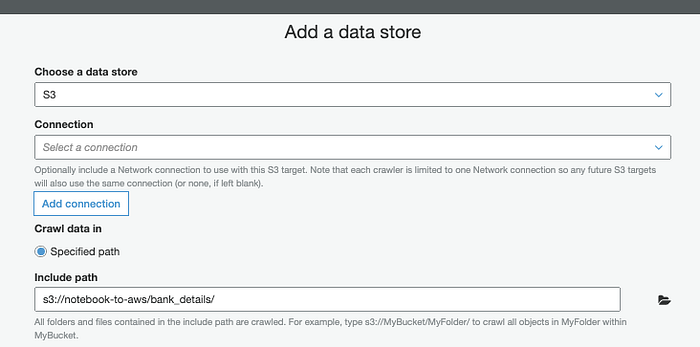
Struktur erkennen mit dem Glue Crawler
Der Glue Crawler trägt das Schema in den Glue Data Catalog ein ( Console; Docs). In den folgenden Schritten (siehe unten) können Athena, DataBrew, QuickSight und weitere Dienste diese S3-Objekte als strukturierte Daten verarbeiten.
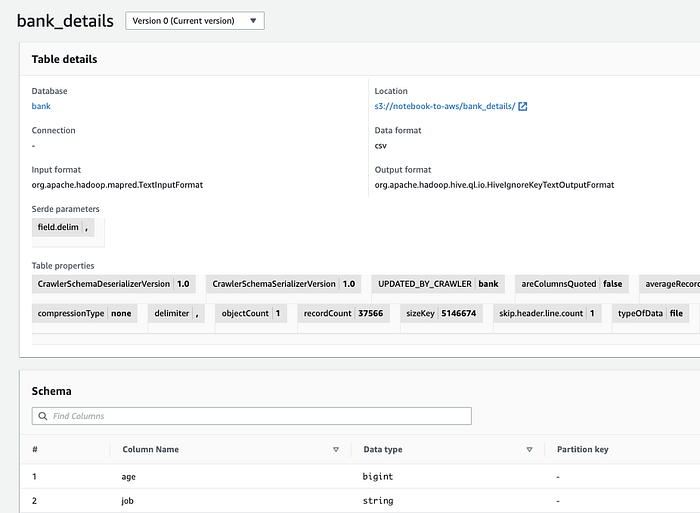
Das Schema unserer Beispieldaten im Data Catalog
Lake Formation ( Console; Docs) regelt anschließend den Zugriff auf diese Data-Catalog-Tabellen.
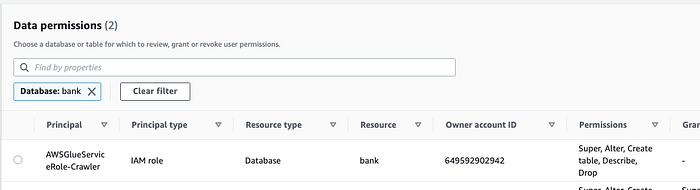
Hier haben wir Glue den Zugriff erteilt, damit der Dienst die Schemas crawlen kann. Genauso lässt sich der Zugriff auch für menschliche Nutzer freigeben.
Exploratory Data Analysis
Im nächsten Schritt erkennen Sie Muster in den Daten und transformieren sie in einen sinnvollen ML-Input.
Im Notebook
Selbst in Produktionsszenarien lässt sich vieles erreichen, indem Sie eine handhabbar große, zufällig gezogene Teilmenge in einem Notebook erkunden.
Mit Pandas verschaffen Sie sich zum Beispiel einen Überblick über die Häufigkeitsverteilungen.
# From the example Notebook
for column in data.select_dtypes(include=[‘object’]).columns:
display(...)
Visualisierungen spielen die visuellen Verarbeitungszentren des menschlichen Gehirns aus, um Muster sichtbar zu machen. Im Notebook lassen sich Daten unmittelbar visualisieren – Histogramme, Heatmaps, Scatter-Matrizen und mehr – mit Seaborn und anderen Bibliotheken.
# From the example Notebook
for column in data.select_dtypes(exclude=['object']).columns:
...
hist = data[[column, 'y']].hist(by='y', bins=30)
plt.show()# From the example Notebook
pd.plotting.scatter_matrix(data, figsize=(12, 12))
Mit AWS-Diensten
In AWS lässt Sie Athena ( Console; Docs) den vollständigen Datenbestand direkt mit gutem alten SQL erkunden. Athena nutzt das im Glue Data Catalog hinterlegte Schema, um die Struktur in den S3-Objekten abzufragen.
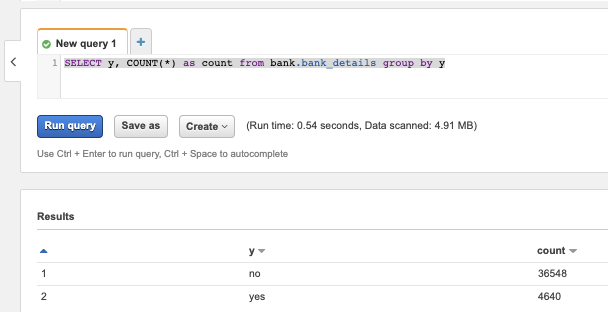
Diese einfache Abfrage zeigt, dass die Klassen im Datensatz unausgewogen sind – ein Hinweis darauf, den Gewichtungsparameter von XGBoost entsprechend zu setzen.
Für die Visualisierung der Daten setzen Sie QuickSight ( Console; Docs) direkt auf Ihren Athena-Abfragen auf. Diese Visualisierungen lassen sich mühelos mit anderen teilen – etwa mit Business Analysts, die ihre eigenen Erkenntnisse beisteuern.
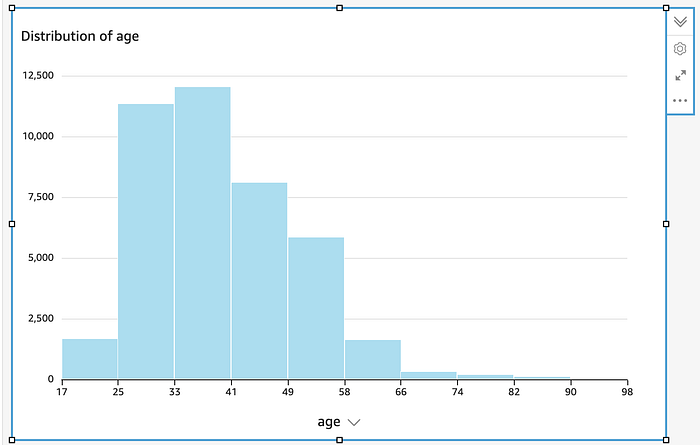
Wählen Sie in QuickSight "Histogramm" und richten Sie es auf die Spalte "age"
QuickSight hat dieses Histogramm automatisch erzeugt, sobald wir es auf die Spalte "age" gerichtet haben
Transformation
Im Notebook
Im Notebook nutzen Sie die Erkenntnisse aus der EDA, um die Daten in eine Form zu bringen, die als Input für Ihren Trainingsalgorithmus taugt – mit APIs, die direkt auf Pandas Dataframes arbeiten:
- Normalisierung für numerische Daten
- One-Hot-Encoding für kategorische Daten
# From the example Notebook
# Convert categorical variables to sets of indicators
# (One-hot)
model_data = pd.get_dummies(data)
- arithmetische Funktionen wie Multiplikation und Modulo
- Spalten entfernen
# From the example Notebook
model_data = model_data.drop([‘duration’, ...], axis=1)
- Ausreißer entfernen
- String-Manipulation
- und vieles mehr
Anschließend konvertieren Sie die Daten in ein Format, das schnelleres ML ermöglicht, etwa Parquet oder libsvm.
Mit AWS-Diensten
Wenn Sie skalieren, bietet AWS gleich mehrere Werkzeuge für die Transformation:
DataBrew ( Console; Docs) ist ein grafischer Transformations-Builder – einer der wenigen, die meiner Erfahrung nach wirklich gut funktionieren. Er liest Ihre S3-Daten so ein, wie sie im Glue Data Catalog definiert sind. Sie wählen aus einem Katalog von Transformationen wie One-Hot, Normalisierung und weiteren, die ich oben im Notebook-Kontext aufgezählt habe.
DataBrew erzeugt Transformationen, die im Glue-Framework laufen. Im letzten Schritt der Transformation lassen sich die Daten in das gewünschte ML-Format wie Parquet, Avro, CSV oder JSON konvertieren.
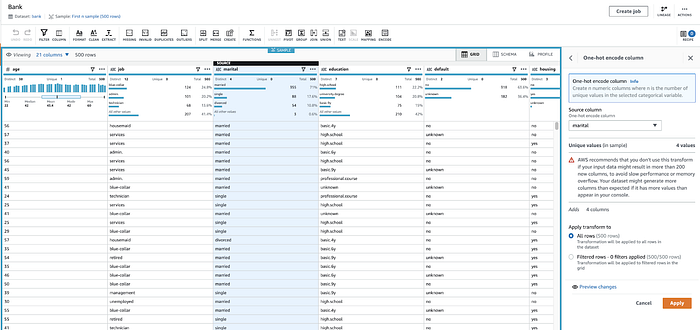
Hier wendet DataBrew One-Hot-Encoding auf das Feld marital an (für single, divorced usw. entstehen separate binäre 1/0-Felder)
Alternativ bietet Ihnen Glue Studio ( Console; Docs) ein grafisches Transformationswerkzeug – allerdings ohne die ML-orientierten Transformationen von DataBrew wie One-Hot. Dafür können Sie eigenen Python- oder Scala-Code schreiben, der in Apache Spark ausgeführt wird.

Ein Transformations-Builder in Glue Studio, der Hand in Hand mit Ihrem eigenen Spark-Code arbeitet.
Training
Ohne Sagemaker
Womöglich lassen Sie Algorithmen wie XGBoost direkt im Speicher Ihres Notebooks laufen. Für interaktive, schnelle Entwicklung ist das ideal.
Sehen Sie sich beispielsweise diesen lokalen XGBoost-Aufruf ohne Sagemaker an.
# From a Notebook that does not use Sagemaker
from xgboost import XGBClassifier # Non-Sagemaker package
...
model = XGBClassifier(… )
...
model.fit(...)
Mit Sagemaker
Wie es der Zufall will, ist unser Beispiel-Notebook bereits darauf vorbereitet, das Sagemaker SDK ( Docs) aufzurufen – und falls Sie das noch nicht tun, ist genau das Ihr nächster, einfacher Schritt. Die API entspricht der anderer Open-Source-Bibliotheken, die denselben Algorithmus ausführen – Sie importieren lediglich eine andere Bibliothek.
# Using Sagemaker (from the example Notebook)
from sagemaker.estimator import Estimator # Different package
...
xgb = Estimator...
...
xgb.fit(...) # Same API
Das Sagemaker SDK erlaubt sowohl lokales als auch entferntes Training: Während der Entwicklung trainieren Sie im Local Mode, um schnell zu iterieren (was Sie womöglich bereits getan haben). Beim Skalieren stoßen Sie über das SDK Trainings auf spezialisierten Sagemaker Instances ( Console; Docs) an – inklusive leistungsstarker Funktionen wie verteiltem Training auf mehreren Instanzen.
Mit demselben SDK rufen Sie die Algorithmen auch mit Hyperparameter-Tuning ( Docs) auf: Derselbe Algorithmus läuft mehrfach mit jeweils unterschiedlichen Parametersätzen – auf der Suche nach den Parametern mit den besten Ergebnissen.
Deployment und Evaluation
Ohne Sagemaker
Wenn Sie lokal ohne Sagemaker trainieren, entfällt das Deployment ganz: Sie führen die Inferenz direkt in Ihrem Speicherbereich aus. Die Performance bewerten Sie zum Beispiel, indem Sie Ihre Inferenz (predict()) auf einem Hold-out-Set laufen lassen.
# From a Notebook that does not use Sagemaker
y_pred = model.predict(X_test) # XGBClassifier model created above
...
pd.crosstab(…) # Evaluate confusion matrix using Pandas
Mit Sagemaker
In Sagemaker werden Sie auf einen Endpoint deployen wollen – eine Gruppe von Instanzen, die Inferenz-Anfragen beantwortet ( Console), so wie es in unserem Beispiel-Notebook geschieht.
# Using Sagemaker (from the example Notebook)
xgb_predictor = xgb.deploy(…) # Using Estimator created above
Zum Skalieren fügen Sie weitere Inferenz-Instanzen hinzu oder konfigurieren sie für Autoscaling. Mit Elastic Inference holen Sie sich zusätzliche Rechenleistung as a Service dazu.
Wenn Sie eine neue Modellversion ausrollen, vergleichen Sie deren Performance auf einem neuen Endpoint – mithilfe der A/B-Testing-Funktion von Sagemaker.
Die Inferenz auf dem Endpoint rufen Sie mit predict() auf – genau wie im Code ohne Sagemaker. Ergebnisse werten Sie aus, indem Sie auf einem Hold-out-Set Inferenz durchführen und anschließend Metriken mit Pandas und anderen In-Memory-APIs berechnen.
# Using Sagemaker (from the example Notebook)
xgb_predictor.predict(…)
pd.crosstab(…) # Evaluate confusion matrix using Pandas
Aber das läuft doch noch im Notebook!
Unser Ziel war es, das Notebook hinter uns zu lassen und in die skalierbaren AWS-Systeme zu wechseln – Sie fragen sich daher vielleicht, warum die letzten Schritte weiterhin im Notebook stattfanden.
Auf der einen Seite haben diese zentralen Schritte tatsächlich verteilte Sagemaker-APIs aufgerufen, statt im Prozess zu laufen, und sind damit voll skalierbar. In einem einfachen Workflow, in dem Sie das Modell nur gelegentlich von Hand neu trainieren und neu ausrollen, könnten sie sogar für ein manuelles, nicht automatisiertes System ausreichen.
Auf der anderen Seite müssen in einem typischen ML-Produktionsprozess neue Modellversionen kontinuierlich neu trainiert und ausgerollt werden – genau wie Sie Software über eine Continuous-Integration-/Continuous-Deployment-Pipeline bauen und testen. Dafür definieren Sie Ihren gerichteten azyklischen Graphen der ML-Verarbeitungsschritte in JSON, etwa mit APIs für Daten-Cleaning, Vorverarbeitung, Training, Deployment und Evaluation. ( Hier ein nützliches Beispiel für das Aufsetzen einer Pipeline.) Bestehenden Code können Sie dabei wiederverwenden – schließlich ist der Code in den Notebooks reines Python und läuft überall, auch in einer Pipeline.
Ein Notebook ist ein mächtiges Entwicklungswerkzeug. Sobald es Richtung Produktion geht, brauchen Sie jedoch leistungsfähigere Infrastruktur. Dieser Artikel zeigt, wie Sie Stück für Stück einzelne Komponenten herauslösen – und dabei sogar weiter mit dem Notebook arbeiten, während das eigentliche System autonom läuft.
Ich hoffe, dieser Beitrag hilft Ihnen dabei, den Sprung zu großen Produktionssystemen zu schaffen.
— — —
P.S. Dieser Beitrag basiert auf meiner Erfahrung mit dem AWS AI/ML Black Belt, einer fortgeschrittenen Zertifizierung, die über die testbasierte AWS Certified ML Specialty hinausgeht. Der Black Belt umfasst einen Aufbaukurs sowie ein abschließendes Capstone-Projekt, das die Grundlage Ihrer Zertifizierung bildet. Eine ausgezeichnete Möglichkeit, Ihre Kompetenzen in den oben genannten Bereichen aufzubauen und nachzuweisen. Einen ausführlicheren Beitrag dazu finden Sie hier.
Vielen Dank fürs Lesen! Bleiben Sie mit uns in Kontakt – im DoiT Engineering Blog , auf dem DoiT LinkedIn-Kanal und auf dem DoiT Twitter-Kanal . Karrieremöglichkeiten finden Sie unter https://careers.doit-intl.com .