De lo simple a lo grande
Este artículo es para quienes recién arrancan en ML, ya aprendieron a trabajar con Jupyter Notebooks y ahora se preguntan: ¿cómo doy el siguiente paso hacia un sistema listo para producción usando los servicios de AWS?
Empezaste con algo ligero y local, pero ahora necesitas llegar a sistemas distribuidos capaces de manejar workloads pesados, como:
- Glue para la transformación y el catálogo de metadatos
- Athena para consultas directas a buckets de S3
- QuickSight para la visualización de analítica
- Sagemaker Instances para entrenamiento paralelizado
- Sagemaker Endpoints como servidores de inferencia versionados y con autoescalado
Comienza desde los Notebooks
Los Jupyter Notebooks son una maravilla para el Machine Learning: un IDE en línea que mantiene en memoria el estado de las variables locales, lo que te permite trabajar con procesos de larga duración como los de ML. Los Sagemaker Notebooks ( Console; Docs) te dan un entorno gestionado para levantarlos rápido. Ahí puedes hacerlo todo: cargar datos, explorar, preprocesar, visualizar, entrenar, evaluar y desplegar, todo en un mismo espacio de memoria, con la comodidad y la rapidez que eso implica.
Servicios distribuidos de AWS
Más allá del Notebook, la cosa se complica: hay que coordinar una serie de servicios distribuidos pesados, integrar cada parte y asegurarse de que se autentiquen entre sí.
Es difícil mantener una visión clara de lo que ocurre a lo largo del proceso de ML. Primero, porque el estado del proceso está distribuido (en su mayoría en buckets de S3) y, segundo, por las largas esperas mientras se activan los servicios de AWS y se procesan grandes volúmenes de datos.
En este artículo te explico cómo dar ese paso de forma gradual.
Dar el salto
Un único entorno interactivo no es la forma de operar sistemas en producción. En algún momento hay que pasar del Notebook a ese sistema distribuido.
Quiero mostrarte un ejemplo de cómo separar cada pieza a medida que avanzas hacia un sistema de producción. Lo ilustraremos con este Notebook open source. En este artículo puedes ver cómo recorrerlo paso a paso en una instancia de Sagemaker Notebook o, de manera aún más sencilla, en el nuevo Sagemaker Studio ( Console; Docs). Para cada tipo de funcionalidad tomo uno o dos fragmentos de código del Notebook y los comparo con el sistema distribuido que ofrece la misma funcionalidad dentro de AWS. En algunos casos, ese Notebook ya usa AWS al invocar Sagemaker para entrenamiento y despliegue; para esos casos te explico cómo pasar de la simple ejecución local a las APIs de Sagemaker y, más allá, a un sistema orquestado fuera del Notebook.
Ingesta
Llevar los datos a tu sistema es el primer paso.
En un Notebook
En un Notebook simplemente cargas un CSV u otro archivo directo al disco para procesarlo en memoria.
# From the example Notebook
with zipfile.ZipFile('bank-additional.zip', 'r') as zip_ref:
zip_ref.extractall('.')
Con servicios de AWS
En proyectos a gran escala, los recursos locales de tu pequeña instancia de Notebook quedarían rebasados.
En su lugar, toma el CSV u otros datos y colócalos en un bucket de S3 ( Console; Docs) que represente el origen de tus datos. Para fuentes estáticas, súbelos directo a S3; para una ingesta continua por streaming, usa Kinesis ( Console; Docs) para volcar la salida en S3.
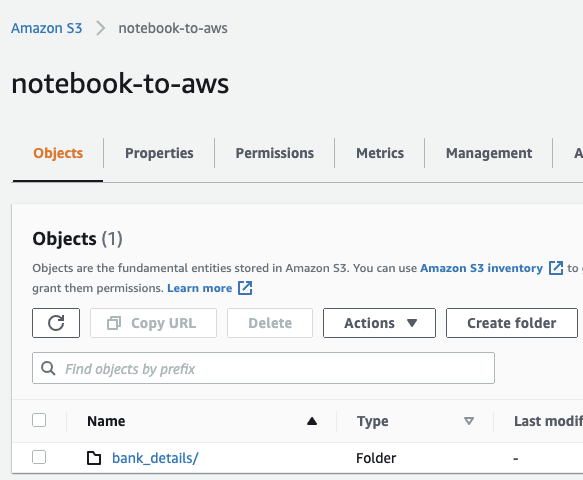
S3 es el lugar habitual para almacenar datos de ML
Esquemas
Lo siguiente es identificar el esquema: tienes un gran bloque de datos (que desde fuera parecen no estructurados) y quieres poder consultarlos y manipularlos según su estructura interna (por lo general, un formato tabular de filas y columnas).
En un Notebook
En el Notebook, el esquema se identifica automáticamente a partir de la fila de encabezado del CSV cuando se carga en un Dataframe.
# From the example Notebook
data = pd.read_csv(‘./bank-additional/bank-additional-full.csv’)
Con servicios de AWS
En AWS, crea un Glue Crawler ( Console; Docs) para identificar el esquema de este CSV a partir de los encabezados de sus columnas.
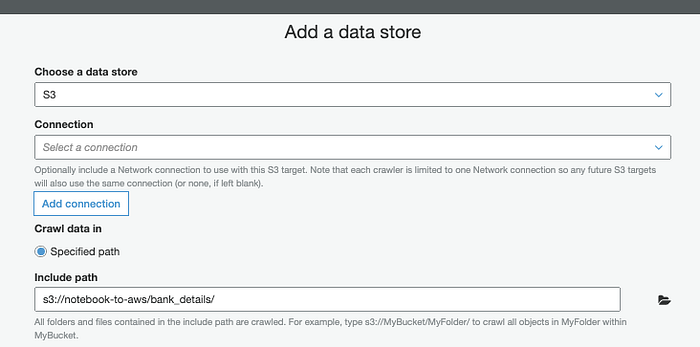
Identifica la estructura con Glue Crawler
Glue Crawler inserta el esquema en el Glue Data Catalog ( Console; Docs). En los siguientes pasos (ver más abajo), Athena, Databrew, Quicksight y otros servicios podrán tratar estos objetos de S3 como datos estructurados.
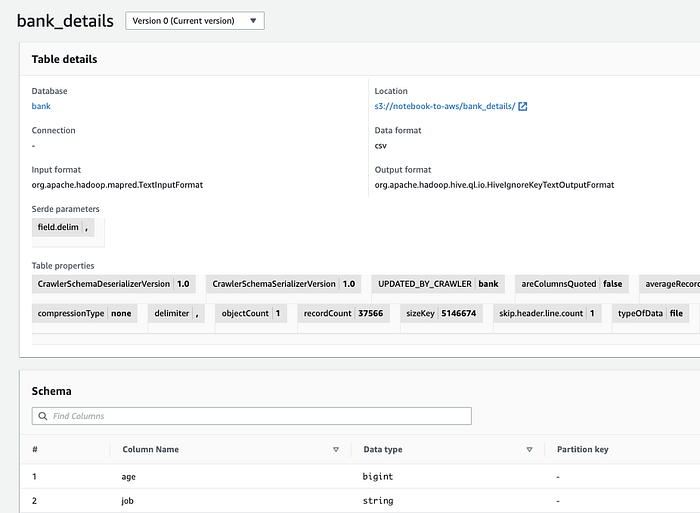
El esquema de nuestros datos de ejemplo en el Data Catalog
Lake Formation ( Console; Docs) controla luego el acceso a estas tablas del Data Catalog.
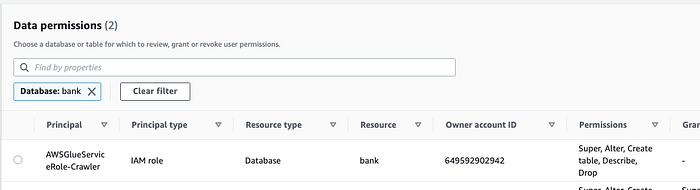
Aquí le dimos acceso a Glue para que pueda rastrear los esquemas. También se puede dar acceso a usuarios humanos.
Análisis exploratorio de datos
A continuación, descubres patrones en los datos y los transformas para convertirlos en una entrada útil para ML.
En un Notebook
Incluso en escenarios de producción, se logra mucho usando un subconjunto manejable y muestreado al azar, y explorándolo en un Notebook.
Con Pandas, por ejemplo, puedes entender las distribuciones de frecuencia.
# From the example Notebook
for column in data.select_dtypes(include=[‘object’]).columns:
display(...)
La visualización aprovecha los centros de procesamiento visual del cerebro humano para resaltar patrones. Puedes visualizar los datos en un Notebook creando histogramas, mapas de calor, matrices de dispersión, etc., con Seaborn y otras librerías.
# From the example Notebook
for column in data.select_dtypes(exclude=['object']).columns:
...
hist = data[[column, 'y']].hist(by='y', bins=30)
plt.show()# From the example Notebook
pd.plotting.scatter_matrix(data, figsize=(12, 12))
Con servicios de AWS
En AWS, Athena ( Console; Docs) te permite explorar directamente todo el conjunto de datos con el clásico SQL de toda la vida. Athena utiliza el esquema guardado en el Glue Data Catalog para consultar la estructura de los objetos en S3.
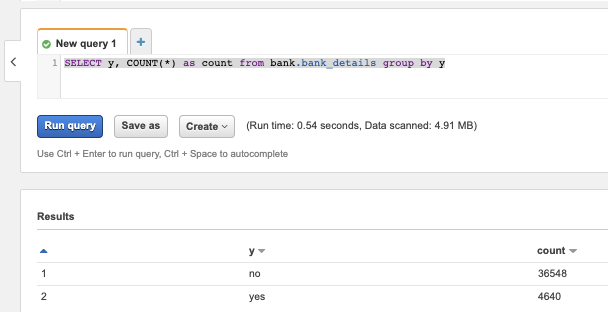
Esta consulta sencilla nos muestra que las clases del dataset están desbalanceadas, lo que nos llevará a ajustar el parámetro de peso de XGBoost en consecuencia.
Para visualizar los datos, usa Quicksight ( Console; Docs) directamente sobre tus consultas de Athena. Estas visualizaciones tienen la ventaja de poder compartirse fácilmente con otras personas, por ejemplo, analistas de negocio que pueden aportar insights.
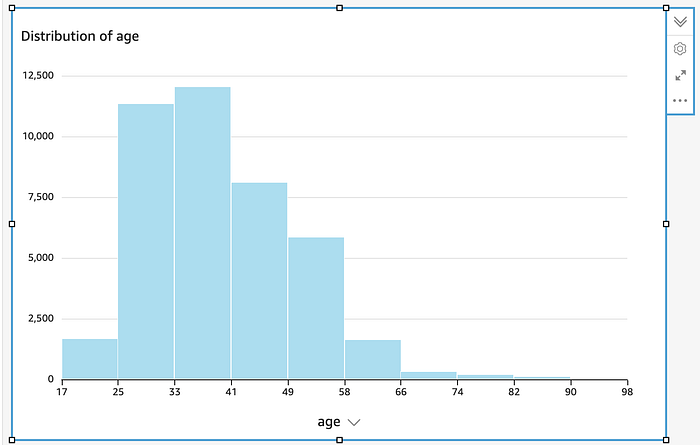
En QuickSight, elige "histograma" y apúntalo a la columna de edad
QuickSight creó este histograma automáticamente al apuntarlo a la columna de edad
Transformación
En un Notebook
En tu Notebook, usas los hallazgos del EDA para transformar los datos en un formato apto como entrada para tu algoritmo de entrenamiento, mediante APIs que trabajan con Dataframes de Pandas:
- normalización para datos numéricos
- one-hot encoding para datos categóricos
# From the example Notebook
# Convert categorical variables to sets of indicators
# (One-hot)
model_data = pd.get_dummies(data)
- funciones aritméticas como multiplicación y módulo
- eliminación de columnas
# From the example Notebook
model_data = model_data.drop([‘duration’, ...], axis=1)
- eliminación de outliers
- manipulación de cadenas
- y más
Después conviertes los datos a un formato que permita un ML más rápido, como Parquet o libsvm.
Con servicios de AWS
Al escalar, AWS te ofrece varias herramientas distintas para la transformación:
DataBrew ( Console; Docs) es un constructor gráfico de transformaciones, una de las pocas herramientas de su tipo que, según mi experiencia, funciona bien. Lee tus datos en S3 tal como están definidos en el Glue Data Catalog. Eliges entre una variedad de transformaciones como one-hot, normalización y otras que ya mencioné en el contexto de los Notebooks.
DataBrew genera transformaciones que se ejecutan en el framework de Glue. Como paso final de la transformación, los datos pueden convertirse al formato de ML deseado, como Parquet, Avro, CSV o JSON.
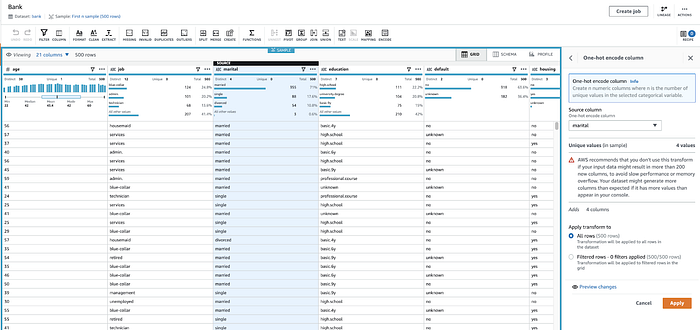
Aquí DataBrew aplica one-hot encoding al campo marital (para crear campos binarios 1/0 separados para single, divorced, etc.)
Como alternativa, Glue Studio ( Console; Docs) te ofrece una herramienta gráfica de transformación —aunque sin las transformaciones orientadas a ML de DataBrew, como one-hot— y puedes escribir tu propio código de transformación en Python o Scala para ejecutarlo en Apache Spark.

Un constructor de transformaciones en Glue Studio, que funciona junto con tu propio código de Spark.
Entrenamiento
Sin Sagemaker
Es posible que estés ejecutando algoritmos como XGBoost directamente en la memoria de tu Notebook. Esto es ideal para un desarrollo interactivo y rápido.
Mira, por ejemplo, esta invocación local de XGBoost sin Sagemaker.
# From a Notebook that does not use Sagemaker
from xgboost import XGBClassifier # Non-Sagemaker package
...
model = XGBClassifier(… )
...
model.fit(...)
Con Sagemaker
Da la casualidad de que nuestro Notebook de ejemplo ya está configurado para invocar el SDK de Sagemaker ( Docs) y, si todavía no lo haces, este es tu siguiente paso natural. La API es la misma que la de otras librerías open source que ejecutan el mismo algoritmo: solo tienes que importar una librería distinta.
# Using Sagemaker (from the example Notebook)
from sagemaker.estimator import Estimator # Different package
...
xgb = Estimator...
...
xgb.fit(...) # Same API
El SDK de Sagemaker permite tanto el entrenamiento local como el remoto: puedes entrenar en modo local para iterar rápido durante el desarrollo (probablemente ya lo venías haciendo) y luego, al escalar, usar el SDK para activar el entrenamiento en Sagemaker instances especializadas ( Console; Docs), incluyendo funciones potentes como el entrenamiento distribuido en múltiples instancias.
Con el mismo SDK también puedes invocar los algoritmos con hyperparameter tuning ( Docs): el mismo algoritmo se ejecuta varias veces, cada una con un conjunto distinto de parámetros, en busca de los que arrojen los mismos resultados.
Despliegue y evaluación
Sin Sagemaker
Si entrenas localmente, sin Sagemaker, no necesitas desplegar nada: ejecutas la inferencia dentro de tu propio espacio de memoria. Por ejemplo, podrías evaluar el desempeño ejecutando tu inferencia (predict()) sobre un conjunto de prueba (hold-out).
# From a Notebook that does not use Sagemaker
y_pred = model.predict(X_test) # XGBClassifier model created above
...
pd.crosstab(…) # Evaluate confusion matrix using Pandas
Con Sagemaker
En Sagemaker, vas a querer desplegar a un Endpoint, un conjunto de instancias que responde a las solicitudes de inferencia ( Console), tal como se hace en nuestro Notebook de ejemplo.
# Using Sagemaker (from the example Notebook)
xgb_predictor = xgb.deploy(…) # Using Estimator created above
Para escalar, puedes agregar más instancias de inferencia o configurarlas con autoescalado, y echar mano de más capacidad de cómputo como servicio con Elastic Inference.
Cuando despliegas una nueva versión del modelo, comparas su desempeño en un nuevo endpoint usando el soporte de Sagemaker para A/B testing.
Invoca la inferencia en el endpoint con predict(), igual que en el código sin Sagemaker. Puedes evaluar resultados ejecutando inferencia sobre un conjunto hold-out y luego calcular métricas con Pandas y otras APIs en memoria.
# Using Sagemaker (from the example Notebook)
xgb_predictor.predict(…)
pd.crosstab(…) # Evaluate confusion matrix using Pandas
¡Pero esto sigue siendo un Notebook!
Nuestro objetivo era salir del Notebook y movernos a los sistemas escalables de AWS, así que tal vez te preguntes por qué las últimas etapas seguían dentro de un Notebook.
Por un lado, esos pasos clave sí invocaban APIs distribuidas de Sagemaker, en lugar de ejecutarse en proceso, así que son totalmente escalables. En un flujo básico, donde de vez en cuando reentrenas y vuelves a desplegar el modelo a mano, hasta podrían servir para un sistema manual y no automatizado.
Por otro lado, en un proceso típico de ML en producción, las nuevas versiones del modelo deben reentrenarse y volver a desplegarse de forma continua, igual que cuando construyes y pruebas tu software con un pipeline de Integración Continua/Despliegue Continuo. Para esto, defines tu grafo acíclico dirigido de pasos de procesamiento de ML en JSON, incluyendo, por ejemplo, APIs de limpieza de datos, preprocesamiento, entrenamiento, despliegue y evaluación. ( Aquí tienes un ejemplo útil para configurar un Pipeline.) Puedes reutilizar tu código existente, ya que el código de los Notebooks es solo Python y puede ejecutarse en cualquier lugar, incluso dentro de un pipeline.
Un Notebook es una herramienta poderosa para el desarrollo, pero al pasar a producción vas a querer una infraestructura más robusta. Este artículo te muestra cómo ir separando piezas, una a una, lo que te permite seguir trabajando con el Notebook mientras el sistema principal corre de forma autónoma.
Espero que este artículo te haya ayudado a dar el salto hacia sistemas grandes en producción.
— — —
P.D. Este artículo se basa en mi experiencia con el AWS AI/ML Black Belt, una certificación avanzada que va más allá del examen AWS Certified ML Specialty. El Black Belt incluye un curso avanzado y un proyecto final (Capstone) que es la base de tu certificación. Es una excelente manera de desarrollar y luego demostrar tus habilidades en las áreas mencionadas. Puedes ver un artículo más detallado al respecto aquí.
¡Gracias por leer! Para mantenerte conectado, síguenos en el DoiT Engineering Blog , el canal de DoiT en LinkedIn y el canal de DoiT en Twitter . Para explorar oportunidades laborales, visita https://careers.doit-intl.com .