Do simples ao grande
Este post é para quem está começando em ML, já aprendeu a trabalhar com Jupyter Notebooks e agora quer saber: como evoluir para um sistema pronto para produção usando os serviços da AWS?
Você começou de forma leve e local, mas agora precisa partir para sistemas distribuídos capazes de lidar com cargas pesadas, como:
- Glue para transformação e catálogo de metadados
- Athena para consultas diretas em buckets do S3
- QuickSight para visualização de analytics
- Sagemaker Instances para treinamento paralelizado
- Sagemaker Endpoints para servidores de inferência versionados e com autoscaling
Começando pelos Notebooks
Os Jupyter Notebooks são uma mão na roda para Machine Learning: uma IDE online que mantém o estado das variáveis locais em memória, o que permite trabalhar com aquele tipo de processo demorado tão típico de ML. Os Sagemaker Notebooks ( Console; Docs) oferecem um ambiente gerenciado para subir esses notebooks rapidinho. Você faz tudo ali: carregar dados, explorar, pré-processar, visualizar, treinar, avaliar e implantar — tudo num único espaço de memória, com praticidade e velocidade.
Serviços distribuídos da AWS
Para além do Notebook, a coisa complica: você precisa coordenar uma série de serviços distribuídos pesados, integrar cada parte e garantir que se autentiquem entre si.
Fica difícil ter uma visão clara do que está acontecendo ao longo do processo de ML. Primeiro, porque o estado do processo está distribuído (principalmente em buckets do S3) e, segundo, por causa das longas esperas enquanto serviços da AWS são acionados e grandes volumes de dados são processados.
Neste post, vou explicar como fazer essa transição aos poucos.
Fazendo a transição
Um único ambiente interativo não é jeito de rodar sistemas em produção. Em algum momento, você precisa sair do Notebook e migrar para esse sistema distribuído.
Quero mostrar um exemplo de como ir separando cada peça à medida que você avança rumo a um sistema de produção. Vamos ilustrar com este Notebook open-source. Neste artigo, você vê como percorrê-lo numa instância de Sagemaker Notebook — ou, mais fácil ainda, no novo Sagemaker Studio ( Console; Docs). Para cada tipo de funcionalidade, eu pego um trecho ou outro de código do Notebook e comparo com o sistema distribuído que entrega a mesma funcionalidade dentro da AWS. Em alguns casos, o Notebook já usa AWS, invocando o Sagemaker para treinamento e implantação; nesses casos, explico como evoluir da execução local simples para as APIs do Sagemaker e, depois, para um sistema orquestrado fora do Notebook.
Ingestão
Levar os dados para o seu sistema é o primeiro passo.
Em um Notebook
Em um Notebook, você simplesmente carrega um CSV ou outro arquivo direto no disco, para processar em memória.
# Do Notebook de exemplo
with zipfile.ZipFile('bank-additional.zip', 'r') as zip_ref:
zip_ref.extractall('.')
Com serviços da AWS
Em projetos de larga escala, os recursos locais da sua pequena instância de Notebook não dariam conta.
Em vez disso, pegue o CSV (ou outros dados) e coloque em um bucket do S3 ( Console; Docs) que represente a origem dos seus dados. Para fontes de dados estáticas, jogue direto no S3; para ingestão contínua via streaming, use o Kinesis ( Console; Docs) para gravar no S3.
O S3 é o lugar de praxe para guardar dados de ML
Schemas
O próximo passo é a identificação do schema: você tem um grande blob de dados (que, por fora, parece não estruturado) e quer poder consultá-lo e manipulá-lo de acordo com sua estrutura interna (em geral, um formato tabular de linhas e colunas).
Em um Notebook
No Notebook, o schema é identificado automaticamente a partir da linha de cabeçalho do CSV quando ele é carregado em um Dataframe.
# Do Notebook de exemplo
data = pd.read_csv(‘./bank-additional/bank-additional-full.csv’)
Com serviços da AWS
Na AWS, crie um Glue Crawler ( Console; Docs) para identificar o schema desse CSV a partir dos cabeçalhos das colunas.
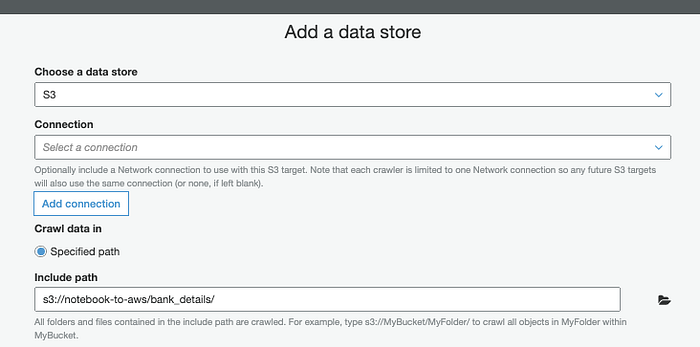
Identifique a estrutura com o Glue Crawler
O Glue Crawler insere o schema no Glue Data Catalog ( Console; Docs). Nas próximas etapas (veja abaixo), Athena, DataBrew, QuickSight e outros serviços vão conseguir tratar esses objetos do S3 como dados estruturados.
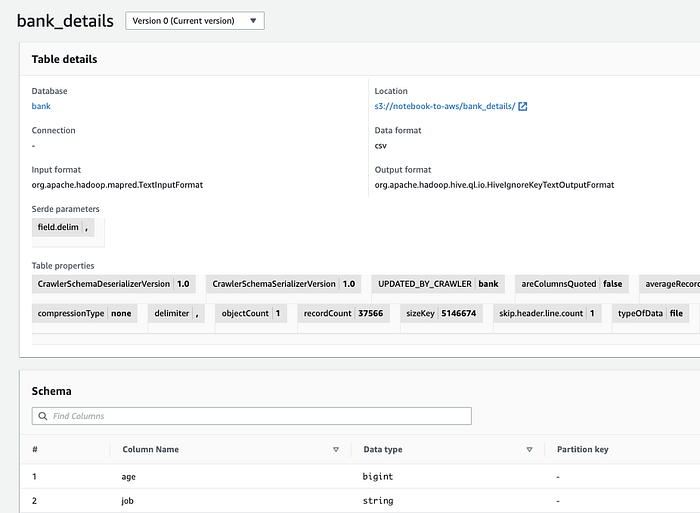
O schema dos nossos dados de exemplo no Data Catalog
O Lake Formation ( Console; Docs) controla, então, o acesso a essas tabelas do Data Catalog.
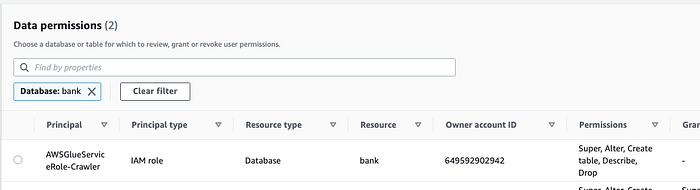
Aqui, demos acesso ao Glue para que ele possa rastrear os schemas. Também dá para liberar acesso para usuários humanos.
Análise Exploratória de Dados
Em seguida, você descobre padrões nos dados e os transforma para gerar uma entrada útil para ML.
Em um Notebook
Mesmo em cenários de produção, dá para fazer muita coisa usando um subconjunto amostrado aleatoriamente, de tamanho gerenciável, e explorando-o em um Notebook.
Com Pandas, por exemplo, você consegue entender as distribuições de frequência.
# Do Notebook de exemplo
for column in data.select_dtypes(include=[‘object’]).columns:
display(...)
A visualização aproveita bem os centros de processamento visual do cérebro humano para destacar padrões. Você pode visualizar os dados em um Notebook, criando histogramas, mapas de calor, matrizes de dispersão etc., usando Seaborn e outras bibliotecas.
# Do Notebook de exemplo
for column in data.select_dtypes(exclude=['object']).columns:
...
hist = data[[column, 'y']].hist(by='y', bins=30)
plt.show()# Do Notebook de exemplo
pd.plotting.scatter_matrix(data, figsize=(12, 12))
Com serviços da AWS
Na AWS, o Athena ( Console; Docs) permite explorar diretamente todos os dados com o bom e velho SQL. O Athena usa o schema salvo no Glue Data Catalog para consultar a estrutura dos objetos no S3.
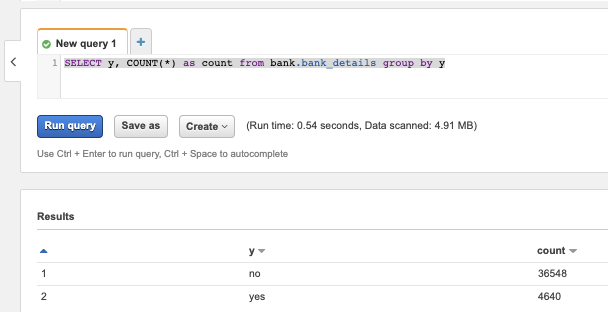
Esta consulta simples mostra que as classes do dataset estão desbalanceadas, o que vai nos levar a ajustar o parâmetro de peso do XGBoost de acordo.
Para visualização de dados, use o QuickSight ( Console; Docs), direto em cima das suas consultas no Athena. Essas visualizações têm a vantagem de serem fáceis de compartilhar com outras pessoas, por exemplo, analistas de negócio, que podem agregar insights.
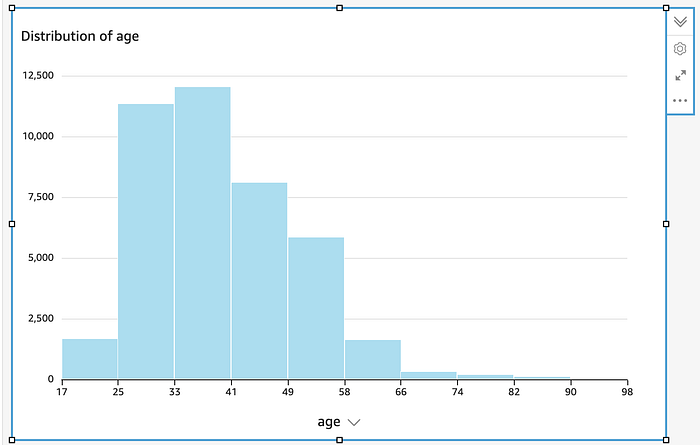
No QuickSight, escolha "histograma" e aponte para a coluna age
O QuickSight criou este histograma automaticamente quando apontamos para a coluna age
Transformação
Em um Notebook
No seu Notebook, você usa os insights da EDA para transformar os dados em um formato utilizável como entrada para o seu algoritmo de treinamento, com APIs que funcionam com Dataframes do Pandas:
- normalização para dados numéricos
- one-hot encoding para dados categóricos
# Do Notebook de exemplo
# Converte variáveis categóricas em conjuntos de indicadores
# (One-hot)
model_data = pd.get_dummies(data)
- funções aritméticas, como multiplicação e módulo
- remoção de colunas
# Do Notebook de exemplo
model_data = model_data.drop([‘duration’, ...], axis=1)
- remoção de outliers
- manipulação de strings
- e por aí vai
Depois, você converte os dados em um formato que permite ML mais rápido, como Parquet ou libsvm.
Com serviços da AWS
Subindo de escala, a AWS oferece várias ferramentas diferentes para transformação:
O DataBrew ( Console; Docs) é um construtor gráfico de transformações — um dos poucos, na minha experiência, que funciona bem. Ele lê seus dados do S3, conforme definido no Glue Data Catalog. Você escolhe entre uma seleção de transformações como one-hot, normalização e outras que listei acima no contexto dos Notebooks.
O DataBrew gera transformações que rodam no framework do Glue. Como última etapa da transformação, os dados podem ser convertidos para o formato de ML desejado, como Parquet, Avro, CSV ou JSON.
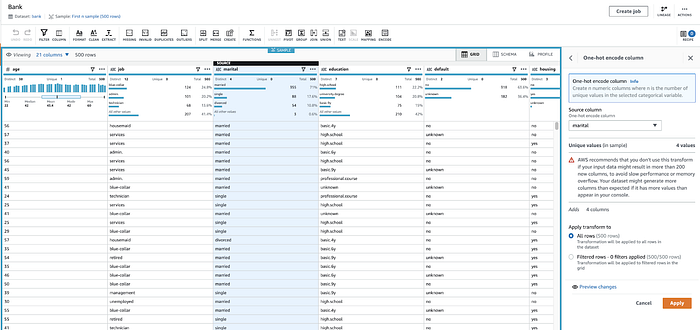
Aqui, o DataBrew aplica one-hot encoding ao campo marital (criando campos binários 1/0 separados para cada valor: solteiro, divorciado etc.)
Como alternativa, o Glue Studio ( Console; Docs) oferece uma ferramenta gráfica de transformação — embora sem as transformações orientadas a ML do DataBrew, como one-hot — e você pode escrever seu próprio código de transformação em Python ou Scala para rodar no Apache Spark.

Um construtor de transformações no Glue Studio, que funciona em conjunto com o seu próprio código Spark.
Treinamento
Sem o Sagemaker
Você pode estar rodando algoritmos como o XGBoost direto na memória do seu Notebook. É bom para desenvolvimento rápido e interativo.
Veja, por exemplo, esta invocação local do XGBoost, sem Sagemaker.
# De um Notebook que não usa Sagemaker
from xgboost import XGBClassifier # Pacote sem Sagemaker
...
model = XGBClassifier(… )
...
model.fit(...)
Com o Sagemaker
Por sorte, o nosso Notebook de exemplo já está configurado para invocar o SDK do Sagemaker ( Docs) e, se você ainda não está fazendo isso, esse é o seu próximo passo fácil. A API aqui é a mesma de outras bibliotecas open-source que executam o mesmo algoritmo — você só precisa importar uma biblioteca diferente.
# Usando o Sagemaker (do Notebook de exemplo)
from sagemaker.estimator import Estimator # Pacote diferente
...
xgb = Estimator...
...
xgb.fit(...) # Mesma API
O SDK do Sagemaker permite tanto treinamento local quanto remoto: você pode treinar em modo local para iterações rápidas durante o desenvolvimento (talvez já estivesse fazendo isso) e, ao escalar, usar o SDK para disparar o treinamento em Sagemaker instances especializadas ( Console; Docs), com recursos poderosos como treinamento distribuído em múltiplas instâncias.
Com o mesmo SDK, você também pode chamar os algoritmos com tuning de hiperparâmetros ( Docs): o mesmo algoritmo é executado várias vezes, cada uma com um conjunto diferente de parâmetros, em busca daqueles que entregam os melhores resultados.
Implantação e Avaliação
Sem o Sagemaker
Se você está treinando localmente, sem o Sagemaker, não precisa fazer deploy: a inferência roda dentro do seu próprio espaço de memória. Por exemplo, você pode avaliar o desempenho rodando sua inferência (predict()) em um conjunto de hold-out.
# De um Notebook que não usa Sagemaker
y_pred = model.predict(X_test) # Modelo XGBClassifier criado acima
...
pd.crosstab(…) # Avalia a matriz de confusão usando Pandas
Com o Sagemaker
No Sagemaker, você vai querer fazer deploy em um Endpoint, um conjunto de instâncias que responde a requisições de inferência ( Console), como acontece no nosso Notebook de exemplo.
# Usando o Sagemaker (do Notebook de exemplo)
xgb_predictor = xgb.deploy(…) # Usando o Estimator criado acima
Para escalar, você pode adicionar mais instâncias de inferência ou configurá-las para autoscaling, e ainda contar com mais poder computacional como serviço usando o Elastic Inference.
Quando você reimplanta uma nova versão do modelo, compara o desempenho dela em um novo endpoint, usando o suporte do Sagemaker para teste A/B.
Invoque a inferência no endpoint com predict(), igualzinho no código sem Sagemaker. Você pode avaliar os resultados rodando inferência em um conjunto de hold-out e calculando métricas com Pandas e outras APIs em memória.
# Usando o Sagemaker (do Notebook de exemplo)
xgb_predictor.predict(…)
pd.crosstab(…) # Avalia a matriz de confusão usando Pandas
Mas isso ainda é em um Notebook!
Nosso objetivo era sair do Notebook e ir para os sistemas escaláveis da AWS, então você pode estar se perguntando por que as últimas etapas ainda estavam em um Notebook.
Por um lado, esses passos-chave de fato invocaram APIs distribuídas do Sagemaker, em vez de rodar in-process, então são totalmente escaláveis. Em um workflow básico, em que você ocasionalmente retreina e reimplanta o modelo na mão, eles podem até ser viáveis para um sistema manual e não automatizado.
Por outro lado, em um processo típico de ML em produção, novas versões do modelo precisam ser retreinadas e reimplantadas continuamente, do mesmo jeito que você compila e testa seu software com um pipeline de Continuous Integration/Continuous Deployment. Para isso, você define seu grafo acíclico dirigido de etapas de processamento de ML em JSON, incluindo, por exemplo, APIs de limpeza de dados, pré-processamento, treinamento, deploy e avaliação. ( Aqui está um exemplo útil de como configurar um Pipeline.) Você pode reaproveitar seu código existente, já que o código nos Notebooks é apenas Python e roda em qualquer lugar, inclusive em um pipeline.
Um Notebook é uma ferramenta poderosa para desenvolvimento, mas, ao entrar em produção, você vai querer uma infraestrutura mais robusta. Este artigo mostra como ir separando as peças, uma a uma, permitindo até que você continue trabalhando no Notebook enquanto o sistema principal roda de forma autônoma.
Espero que este post tenha ajudado você a dar o salto para grandes sistemas de produção.
— — —
P.S. Este post é baseado na minha experiência no AWS AI/ML Black Belt, uma certificação avançada que vai além da AWS Certified ML Specialty, baseada em prova. O Black Belt inclui um curso avançado e um projeto final de Capstone, que é a base da sua certificação. É uma ótima maneira de desenvolver e demonstrar suas habilidades nas áreas mencionadas acima. Veja um post mais detalhado sobre isso aqui.
Obrigado pela leitura! Para ficar por dentro, siga a gente no DoiT Engineering Blog , no DoiT Linkedin Channel e no DoiT Twitter Channel . Para conferir oportunidades de carreira, acesse https://careers.doit-intl.com .