Dal piccolo al grande
Questo articolo è dedicato a chi si avvicina al ML, ha imparato a usare i Jupyter Notebook e ora si chiede: come passo a un sistema production-ready con i servizi AWS?
Ha iniziato in modo leggero e in locale, ma ora deve passare a sistemi distribuiti capaci di gestire carichi pesanti come:
- Glue per la trasformazione e il catalogo dei metadati
- Athena per query dirette sui bucket S3
- QuickSight per la visualizzazione delle analisi
- Sagemaker Instances per il training parallelizzato
- Sagemaker Endpoints per server di inferenza versionati e con autoscaling
Si parte dai Notebook
I Jupyter Notebook sono una meraviglia per il Machine Learning: un IDE online che mantiene in memoria lo stato delle variabili locali, così può lavorare con quei processi a lunga esecuzione tipici del ML. I Sagemaker Notebook ( Console; Docs) offrono un ambiente gestito per crearli in pochi istanti. Lì può fare tutto: caricare i dati, esplorarli, fare il preprocessing, visualizzarli, addestrare, valutare e fare il deployment, il tutto in un unico spazio di memoria, con tutti i vantaggi in termini di comodità e velocità.
Servizi AWS distribuiti
Fuori dal Notebook le cose si complicano: bisogna coordinare una serie di servizi distribuiti pesanti, integrare ogni componente e fare in modo che si autentichino tra loro.
Diventa difficile mantenere una visione chiara di ciò che accade nel processo ML. Da un lato, perché lo stato del processo è distribuito (per lo più nei bucket S3); dall'altro, per via delle lunghe attese mentre i servizi AWS si attivano e grandi quantità di dati vengono elaborate.
In questo articolo le spiegherò come affrontare il passaggio in modo graduale.
Come fare il salto
Un singolo ambiente interattivo non è la sede giusta per gestire sistemi di produzione. Prima o poi bisogna passare dal Notebook a un sistema distribuito.
Vorrei mostrarle un esempio di come scomporre ogni pezzo lungo il percorso che porta verso un sistema di produzione. Useremo come riferimento questo Notebook open-source. In questo articolo trova come eseguirlo passo passo in un'istanza Sagemaker Notebook — o, ancora più facilmente, nel nuovo Sagemaker Studio ( Console; Docs). Per ogni tipo di funzionalità prendo uno o due frammenti di codice dal Notebook e li metto a confronto con il sistema distribuito che fornisce la stessa funzionalità all'interno di AWS. In alcuni casi quel Notebook usa già AWS, richiamando Sagemaker per il training e il deployment; per questi casi spiego come passare dalla semplice esecuzione locale alle API di Sagemaker e oltre, fino a un sistema orchestrato al di fuori del Notebook.
Ingestion
Far entrare i dati nel sistema è il primo passo.
In un Notebook
In un Notebook basta caricare un CSV o un altro file direttamente sul disco, per elaborarlo in memoria.
# From the example Notebook
with zipfile.ZipFile('bank-additional.zip', 'r') as zip_ref:
zip_ref.extractall('.')
Con i servizi AWS
Nei progetti su larga scala le risorse locali della sua piccola istanza Notebook verrebbero subito saturate.
L'alternativa è prendere il CSV, o altri dati, e collocarli in un bucket S3 ( Console; Docs) che rappresenti l'origine dei dati. Per le fonti statiche, caricarli direttamente su S3; per l'ingestion continua tramite streaming, usare Kinesis ( Console; Docs) per scrivere l'output su S3.
S3 è il luogo abituale in cui archiviare i dati ML
Schemi
Il passo successivo è l'identificazione dello schema: ha un grande blob di dati (che dall'esterno sembrano destrutturati) e vuole poterli interrogare e manipolare in base alla loro struttura interna (in genere un formato tabellare a righe e colonne).
In un Notebook
Nel Notebook lo schema viene identificato automaticamente dalla riga di intestazione del CSV nel momento in cui viene caricato in un Dataframe.
# From the example Notebook
data = pd.read_csv(‘./bank-additional/bank-additional-full.csv’)
Con i servizi AWS
In AWS crei un Glue Crawler ( Console; Docs) per ricavare lo schema di questo CSV dalle intestazioni di colonna.
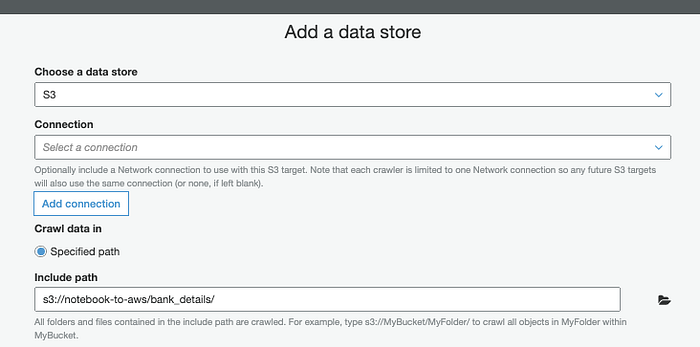
Identificare la struttura con Glue Crawler
Glue Crawler inserisce lo schema nel Glue Data Catalog ( Console; Docs). Nei passaggi successivi (vedi sotto), Athena, Databrew, Quicksight e altri servizi potranno trattare questi oggetti S3 come dati strutturati.
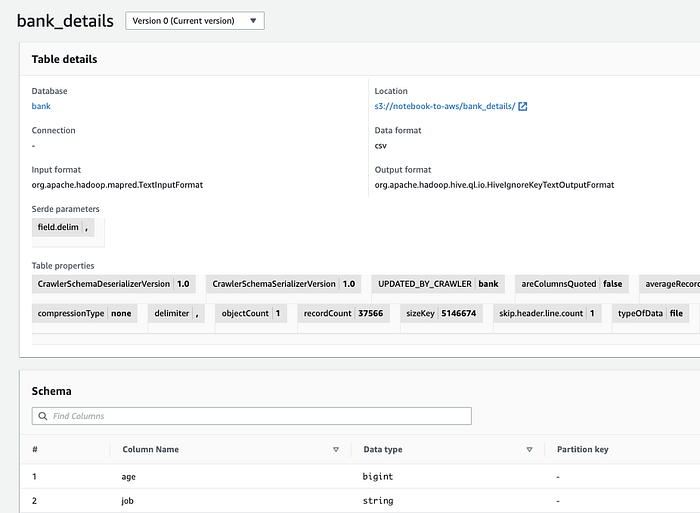
Lo schema dei nostri dati di esempio nel Data Catalog
Lake Formation ( Console; Docs) gestisce poi gli accessi a queste tabelle del Data Catalog.
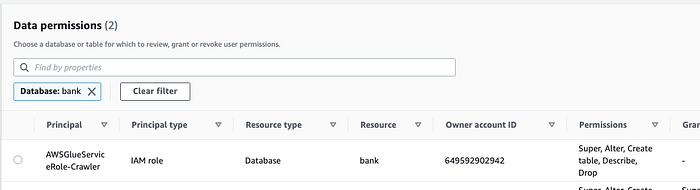
Qui abbiamo concesso l'accesso a Glue affinché possa fare il crawling degli schemi. Possiamo anche concedere l'accesso a utenti reali.
Exploratory Data Analysis
Il passo successivo è scoprire pattern nei dati e trasformarli in input utili per il ML.
In un Notebook
Anche in scenari di produzione si ottengono ottimi risultati lavorando su un sottoinsieme di dati di dimensioni gestibili, campionato casualmente, ed esplorandolo in un Notebook.
Con Pandas, ad esempio, può analizzare le distribuzioni di frequenza.
# From the example Notebook
for column in data.select_dtypes(include=[‘object’]).columns:
display(...)
La visualizzazione sfrutta al meglio le aree di elaborazione visiva del cervello umano per mettere in evidenza i pattern. Nel Notebook può visualizzare i dati creando istogrammi, heat map, scatter matrix, ecc. con Seaborn e altre librerie.
# From the example Notebook
for column in data.select_dtypes(exclude=['object']).columns:
...
hist = data[[column, 'y']].hist(by='y', bins=30)
plt.show()# From the example Notebook
pd.plotting.scatter_matrix(data, figsize=(12, 12))
Con i servizi AWS
In AWS, Athena ( Console; Docs) le permette di esplorare direttamente l'intero set di dati con il caro vecchio SQL. Athena utilizza lo schema salvato nel Glue Data Catalog per interrogare la struttura presente negli oggetti S3.
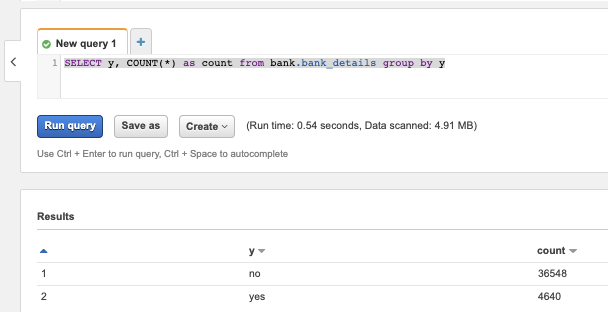
Questa semplice query mostra che le classi nel dataset sono sbilanciate, motivo per cui imposteremo di conseguenza il parametro weight di XGBoost.
Per la visualizzazione dei dati usi Quicksight ( Console; Docs), direttamente sopra le query Athena. Queste visualizzazioni hanno il vantaggio di essere facilmente condivisibili con altre persone, ad esempio analisti di business, che possono apportare i propri insight.
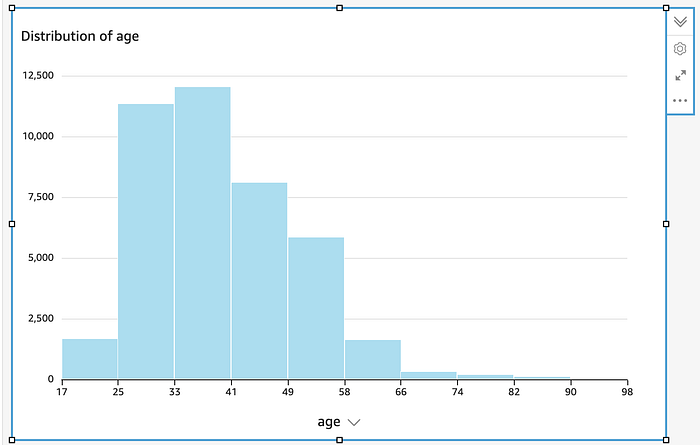
In QuickSight, scelga "histogram" e lo punti sulla colonna age
QuickSight ha generato automaticamente questo istogramma una volta puntato sulla colonna age
Trasformazione
In un Notebook
Nel Notebook usa le indicazioni emerse dall'EDA per trasformare i dati in una forma utilizzabile come input per l'algoritmo di training, sfruttando API che lavorano con i Pandas Dataframe:
- normalizzazione per i dati numerici
- one-hot encoding per i dati categorici
# From the example Notebook
# Convert categorical variables to sets of indicators
# (One-hot)
model_data = pd.get_dummies(data)
- funzioni aritmetiche come moltiplicazione e modulo
- eliminazione di colonne
# From the example Notebook
model_data = model_data.drop([‘duration’, ...], axis=1)
- rimozione degli outlier
- manipolazione delle stringhe
- e altro ancora
Quindi convertirà i dati in un formato che permetta un ML più rapido, come Parquet o libsvm.
Con i servizi AWS
Quando si scala, AWS mette a disposizione diversi strumenti per la trasformazione:
DataBrew ( Console; Docs) è un costruttore grafico di trasformazioni — uno dei pochi che, per mia esperienza, funziona davvero bene. Legge i dati S3 così come definiti nel Glue Data Catalog. Si sceglie tra una serie di trasformazioni come one-hot, normalizzazione e altre che ho elencato sopra nel contesto dei Notebook.
DataBrew genera trasformazioni che girano nel framework Glue. Come ultimo passaggio, i dati possono essere convertiti nel formato ML desiderato, come Parquet, Avro, CSV o JSON.
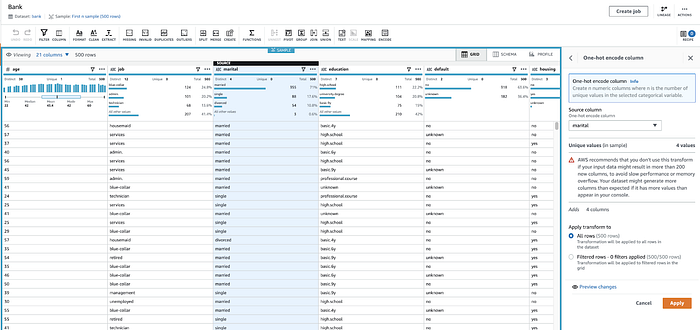
Qui DataBrew applica il one-hot encoding al campo marital (per creare campi binari 1/0 separati per single, divorced, ecc.)
In alternativa, Glue Studio ( Console; Docs) offre uno strumento grafico di trasformazione — pur senza le trasformazioni orientate al ML di DataBrew, come il one-hot — e le consente di scrivere il proprio codice di trasformazione in Python o Scala da eseguire in Apache Spark.

Un costruttore di trasformazioni in Glue Studio, che si integra con il suo codice Spark.
Training
Senza Sagemaker
Potrebbe eseguire algoritmi come XGBoost direttamente nella memoria del Notebook. È una scelta valida per uno sviluppo interattivo e rapido.
Veda, ad esempio, questa invocazione locale di XGBoost senza Sagemaker.
# From a Notebook that does not use Sagemaker
from xgboost import XGBClassifier # Non-Sagemaker package
...
model = XGBClassifier(… )
...
model.fit(...)
Con Sagemaker
Per inciso, il nostro Notebook di esempio è già configurato per richiamare il Sagemaker SDK ( Docs) e, se non lo sta già facendo, è il passo successivo più semplice. L'API qui è la stessa di altre librerie open-source che eseguono lo stesso algoritmo: basta importare una libreria diversa.
# Using Sagemaker (from the example Notebook)
from sagemaker.estimator import Estimator # Different package
...
xgb = Estimator...
...
xgb.fit(...) # Same API
Il Sagemaker SDK consente sia il training locale sia quello remoto: può addestrare in modalità locale per iterare velocemente durante lo sviluppo (cosa che probabilmente faceva già), ma poi, quando si scala, usa l'SDK per avviare il training su istanze Sagemaker specializzate ( Console; Docs), incluse funzionalità potenti come il training distribuito su più istanze.
Con lo stesso SDK può anche richiamare gli algoritmi con il tuning degli iperparametri ( Docs): lo stesso algoritmo viene eseguito più volte, ognuna con un set diverso di parametri, alla ricerca della combinazione che dà i risultati migliori.
Deployment e valutazione
Senza Sagemaker
Se sta facendo training in locale, senza Sagemaker, non serve fare alcun deployment: l'inferenza viene eseguita direttamente nel suo spazio di memoria. Ad esempio, può valutare le prestazioni eseguendo l'inferenza (predict()) su un hold-out set.
# From a Notebook that does not use Sagemaker
y_pred = model.predict(X_test) # XGBClassifier model created above
...
pd.crosstab(…) # Evaluate confusion matrix using Pandas
Con Sagemaker
In Sagemaker il deployment va fatto su un Endpoint, un insieme di istanze che risponde alle richieste di inferenza ( Console), come avviene nel nostro Notebook di esempio.
# Using Sagemaker (from the example Notebook)
xgb_predictor = xgb.deploy(…) # Using Estimator created above
Per scalare, può aggiungere altre istanze di inferenza o configurarle in autoscaling, e può attingere a ulteriore potenza di calcolo as-a-service con Elastic Inference.
Quando rilascia una nuova versione del modello, ne confronta le prestazioni su un nuovo endpoint, sfruttando il supporto di Sagemaker per l'A/B testing.
Per richiamare l'inferenza sull'endpoint usa predict(), esattamente come nel codice non-Sagemaker. Può valutare i risultati eseguendo l'inferenza su un hold-out set e poi calcolando le metriche con Pandas e altre API in-memory.
# Using Sagemaker (from the example Notebook)
xgb_predictor.predict(…)
pd.crosstab(…) # Evaluate confusion matrix using Pandas
Ma è ancora un Notebook!
Il nostro obiettivo era uscire dal Notebook e approdare ai sistemi scalabili di AWS, quindi forse si starà chiedendo perché le ultime fasi siano ancora nel Notebook.
Da un lato, questi passaggi chiave hanno effettivamente richiamato le API distribuite di Sagemaker, anziché girare in-process, e sono quindi pienamente scalabili. In un workflow di base, in cui si riaddestra e si rilascia il modello manualmente di tanto in tanto, potrebbero anche bastare per un sistema gestito a mano e non automatizzato.
Dall'altro lato, in un tipico processo ML di produzione le nuove versioni del modello vanno riaddestrate e rilasciate in continuazione, proprio come si fa il build e il test del software con una pipeline di Continuous Integration/Continuous Deployment. Per questo si definisce in JSON il proprio grafo aciclico diretto di passaggi di elaborazione ML, includendo, ad esempio, le API di pulizia dei dati, preprocessing, training, deployment e valutazione. ( Qui trova un esempio utile per configurare una Pipeline.) Può riutilizzare il codice esistente, perché quello presente nei Notebook è semplicemente Python e può girare ovunque, anche in una pipeline.
Il Notebook è uno strumento potente per lo sviluppo, ma quando passa alla produzione le servirà un'infrastruttura più robusta. Questo articolo le mostra come scorporare i pezzi, uno alla volta, permettendole anche di continuare a lavorare con il Notebook mentre il sistema principale gira in autonomia.
Spero che questo articolo l'abbia aiutata a fare il salto verso grandi sistemi di produzione.
— — —
P.S. Questo articolo si basa sulla mia esperienza con l'AWS AI/ML Black Belt, una certificazione avanzata che va oltre l'AWS Certified ML Specialty basato su test. La Black Belt comprende un corso avanzato e un Capstone project finale, su cui si fonda la certificazione stessa. È un ottimo modo per costruire e poi dimostrare le proprie competenze nelle aree menzionate sopra. Trova un articolo più dettagliato a riguardo qui.
Grazie per la lettura! Per restare in contatto, ci segua sul DoiT Engineering Blog , sul canale LinkedIn di DoiT e sul canale Twitter di DoiT . Per scoprire le opportunità di carriera, visiti https://careers.doit-intl.com .