小さく始めて、大きく育てる
本記事は、Jupyter Notebookでの作業に慣れたML初心者の方に向けて、「AWSサービスを活用した本番運用レベルのシステムへどう移行すればよいか」を解説するガイドです。
軽量なローカル環境からスタートしたものの、次のような重い処理に対応できる分散システムへとステップアップしたい方のための内容です。
- 変換処理とメタデータカタログを担うGlue
- S3バケットへ直接クエリを実行できるAthena
- 分析データを可視化するQuickSight
- 並列学習を可能にするSagemaker Instances
- バージョン管理とオートスケールに対応した推論サーバーであるSagemaker Endpoints
Notebookから始める
分散型のAWSサービス
Notebookの先に踏み出すと、難易度は一段と上がります。複数の重量級分散サービスを連携させ、それぞれを統合し、相互に認証させる必要があるためです。
MLプロセス全体で何が起きているのかを把握し続けるのは簡単ではありません。ひとつにはプロセスの状態が分散しているため(主にS3バケット内)、もうひとつにはAWSサービスの起動や大量データ処理に伴う待ち時間が長いためです。
本記事では、この移行を段階的に進める方法を解説します。
移行の進め方
本番システムを単一の対話型環境で動かし続けるのは現実的ではありません。どこかのタイミングで、Notebookから分散システムへ移行する必要があります。
本番システムへ向かう過程で各要素をどのように切り出していくか、具体例で示してみましょう。題材にはこのオープンソースのNotebookを使います。こちらの記事では、Sagemaker Notebookインスタンスでこれを順に動かす方法、あるいはさらに手軽な新しいSagemaker Studio( Console; Docs)で動かす方法が紹介されています。機能ごとにNotebookから1〜2片のコードを抜き出し、AWS内で同等の機能を提供する分散システムと比較していきます。なかには、すでにSagemakerを呼び出して学習やデプロイを行っているNotebookもあります。そうしたケースでは、シンプルなローカル実行からSagemaker APIへ、さらにNotebookの外側でオーケストレーションされるシステムへとステップアップする方法を解説します。
データ取り込み
まずはシステムへのデータ取り込みからです。
Notebookの場合
Notebookでは、CSVなどのファイルをそのままディスクに読み込み、メモリ上で処理します。
# From the example Notebook
with zipfile.ZipFile('bank-additional.zip', 'r') as zip_ref:
zip_ref.extractall('.')
AWSサービスの場合
大規模プロジェクトでは、小さなNotebookインスタンスのローカルリソースではすぐに限界を迎えます。
そこで、CSVなどのデータを、データの起点となるS3バケット( Console; Docs)に格納します。静的なデータソースであれば直接S3に置き、ストリーミングによる継続的な取り込みであれば、Kinesis( Console; Docs)を経由してS3へ出力します。
S3はMLデータの定番の保管場所
スキーマ
次はスキーマの特定です。外見上は非構造化データに見える大きな塊から、その内部構造(一般には行と列のテーブル形式)に基づいてクエリや操作ができるようにする工程です。
Notebookの場合
Notebookでは、CSVをDataframeに読み込んだ時点で、ヘッダー行から自動的にスキーマが特定されます。
# From the example Notebook
data = pd.read_csv(‘./bank-additional/bank-additional-full.csv’)
AWSサービスの場合
AWSでは、Glue Crawler( Console; Docs)を作成し、CSVのカラムヘッダーからスキーマを特定します。
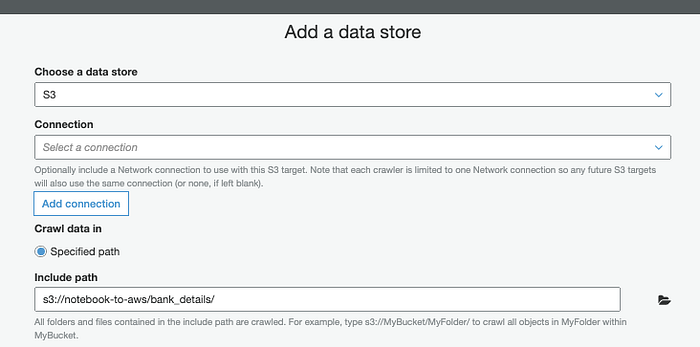
Glue Crawlerで構造を特定する
Glue Crawlerは、特定したスキーマをGlue Data Catalog( Console; Docs)に登録します。これ以降のステップ(後述)では、Athena、Databrew、Quicksightなどのサービスが、これらのS3オブジェクトを構造化データとして扱えるようになります。
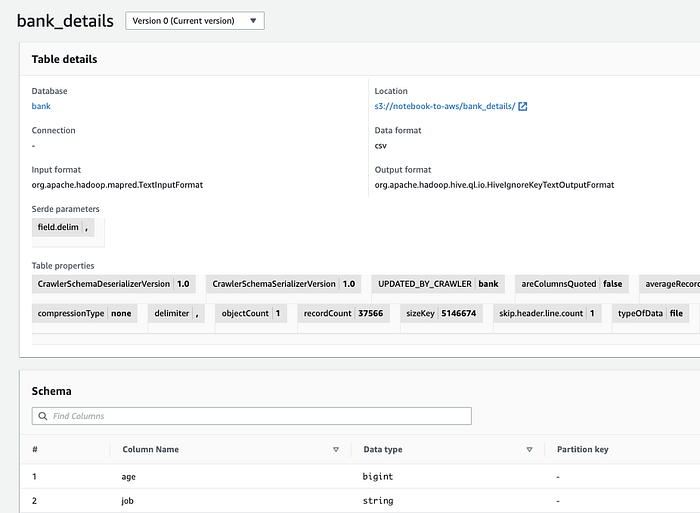
Data Catalogに登録されたサンプルデータのスキーマ
そしてLake Formation( Console; Docs)が、Data Catalogテーブルへのアクセス制御を担います。
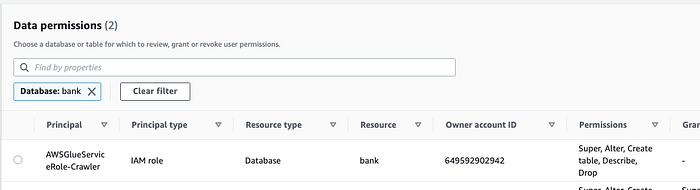
ここではGlueにアクセス権を付与し、スキーマをクロールできるようにしています。同様に、人間のユーザーにもアクセス権を付与できます。
探索的データ分析(EDA)
続いて、データからパターンを発見し、MLに有用な入力となるよう変換していきます。
Notebookの場合
本番シナリオであっても、扱いやすいサイズにランダムサンプリングしたサブセットをNotebookで探索するだけで、多くのことが見えてきます。
たとえばPandasを使えば、頻度分布を把握できます。
# From the example Notebook
for column in data.select_dtypes(include=[‘object’]).columns:
display(...)
可視化は、人間の脳の視覚処理機能をうまく活用してパターンを浮かび上がらせる手段です。NotebookではSeabornなどのライブラリを使い、ヒストグラム、ヒートマップ、散布図行列などを作成してデータを可視化できます。
# From the example Notebook
for column in data.select_dtypes(exclude=['object']).columns:
...
hist = data[[column, 'y']].hist(by='y', bins=30)
plt.show()# From the example Notebook
pd.plotting.scatter_matrix(data, figsize=(12, 12))
AWSサービスの場合
AWSでは、Athena( Console; Docs)を使えば、使い慣れたSQLでデータ全体を直接探索できます。AthenaはGlue Data Catalogに保存されたスキーマを利用し、S3オブジェクト内の構造に対してクエリを実行します。
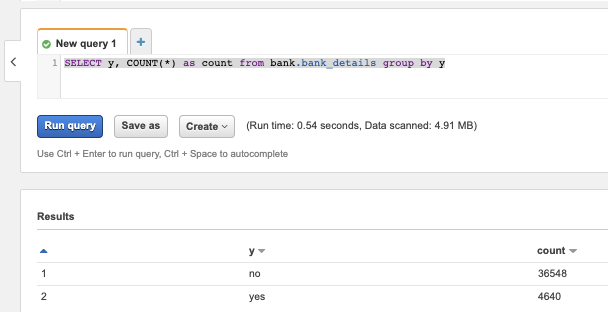
このシンプルなクエリから、データセットのクラス分布が偏っていることがわかります。これを踏まえて、XGBoostのweightパラメータを調整することになります。
データの可視化には、Quicksight( Console; Docs)をAthenaクエリに直接重ねて使います。これらの可視化は、たとえばビジネスアナリストなど他のメンバーと簡単に共有でき、彼らからのインサイトも取り込めるという利点があります。
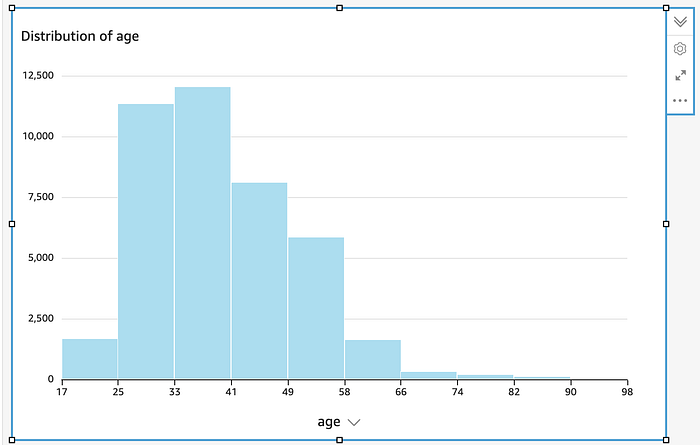
QuickSightで「histogram」を選び、ageカラムを指定します
ageカラムを指定するだけで、QuickSightがこのヒストグラムを自動生成してくれました
変換
Notebookの場合
Notebookでは、EDAから得られたインサイトをもとに、Pandas Dataframeで動作するAPIを使って、データを学習アルゴリズムへの入力として使える形に変換します。
- 数値データの正規化
- カテゴリカルデータのone-hotエンコーディング
# From the example Notebook
# Convert categorical variables to sets of indicators
# (One-hot)
model_data = pd.get_dummies(data)
- 乗算や剰余などの算術関数
- 列の削除
# From the example Notebook
model_data = model_data.drop([‘duration’, ...], axis=1)
- 外れ値の除去
- 文字列操作
- その他
最後に、Parquetやlibsvmなど、MLをより高速に行える形式へとデータを変換します。
AWSサービスの場合
スケールアップに際して、AWSは複数の変換ツールを用意しています。
DataBrew( Console; Docs)はグラフィカルな変換ビルダーで、私の経験上、まともに使える数少ないツールのひとつです。Glue Data Catalogで定義されたS3データを読み込み、先ほどNotebookの文脈で挙げたone-hotや正規化などの変換を選択肢から選べます。
DataBrewが生成する変換処理はGlueフレームワーク上で実行されます。変換の最終ステップでは、データをParquet、Avro、CSV、JSONなど目的のML形式に変換できます。
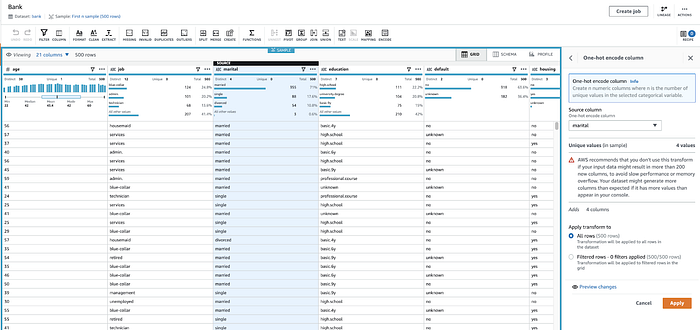
ここではDataBrewがmaritalフィールドにone-hotエンコーディングを適用しています(single、divorcedなどの値ごとに、個別の二値1/0フィールドを作成)
もうひとつの選択肢として、Glue Studio( Console; Docs)もグラフィカルな変換ツールを提供しています。DataBrewのようなone-hotといったML向け変換は備えていませんが、独自のPythonコードやScalaコードを書いてApache Spark上で実行できます。

Glue Studioの変換ビルダー。独自のSparkコードと組み合わせて動作します。
学習
Sagemakerを使わない場合
XGBoostのようなアルゴリズムは、Notebookのメモリ上で直接実行することもできます。これは対話的でスピード重視の開発に向いています。
たとえば、Sagemakerを使わずローカルでXGBoostを呼び出す例は次のとおりです。
# From a Notebook that does not use Sagemaker
from xgboost import XGBClassifier # Non-Sagemaker package
...
model = XGBClassifier(… )
...
model.fit(...)
Sagemakerを使う場合
実は、サンプルNotebookはすでにSagemaker SDK( Docs)を呼び出すように設定されています。まだ使っていないなら、これが手軽な次の一歩です。ここでのAPIは、同じアルゴリズムを動かす他のオープンソースライブラリと同じで、インポートするライブラリを差し替えるだけです。
# Using Sagemaker (from the example Notebook)
from sagemaker.estimator import Estimator # Different package
...
xgb = Estimator...
...
xgb.fit(...) # Same API
Sagemaker SDKはローカル学習とリモート学習の両方に対応しています。開発中の高速イテレーションにはローカルモードで学習し(これまでもそうしてきたかもしれません)、スケールアップする際にはSDKから専用のSagemaker instances( Console; Docs)上での学習をトリガーします。複数インスタンスでの分散学習といった強力な機能も利用できます。
同じSDKで、ハイパーパラメータチューニング( Docs)も呼び出せます。これは、同じアルゴリズムを異なるパラメータの組み合わせで複数回実行し、望ましい結果が得られるパラメータを探す仕組みです。
デプロイと評価
Sagemakerを使わない場合
Sagemakerなしでローカル学習を行っているなら、デプロイそのものが不要です。推論はメモリ空間内で直接実行できます。たとえば、ホールドアウトセットに対して推論(predict())を実行することで、性能を評価できます。
# From a Notebook that does not use Sagemaker
y_pred = model.predict(X_test) # XGBClassifier model created above
...
pd.crosstab(…) # Evaluate confusion matrix using Pandas
Sagemakerを使う場合
Sagemakerでは、推論リクエストに応答するインスタンス群であるEndpoint( Console)へデプロイします。サンプルNotebookでも同様の手順がとられています。
# Using Sagemaker (from the example Notebook)
xgb_predictor = xgb.deploy(…) # Using Estimator created above
スケーリング時には、推論インスタンスを追加したり、オートスケーリングを設定したりできます。さらにElastic Inferenceを使えば、コンピューティングパワーをサービスとして追加で利用することもできます。
新しいバージョンのモデルを再デプロイする際には、SagemakerのA/Bテスト機能を使って、新しいエンドポイント上で性能を比較できます。
エンドポイントでの推論呼び出しは、Sagemakerを使わないコードと同様にpredict()で行います。ホールドアウトセットでの推論結果から、Pandasなどのインメモリ APIを使ってメトリクスを算出し、評価できます。
# Using Sagemaker (from the example Notebook)
xgb_predictor.predict(…)
pd.crosstab(…) # Evaluate confusion matrix using Pandas
でもこれ、結局Notebookの中の話では?
本記事の目標はNotebookから抜け出してAWSのスケーラブルなシステムへ移行することのはずなのに、なぜ最後の数ステップは依然としてNotebook上だったのか――そう感じた方もいるかもしれません。
一方で、これらの重要なステップは確かにSagemakerの分散APIを呼び出しており、インプロセスで実行しているわけではないため、十分にスケーラブルです。手作業で時々モデルを再学習・再デプロイするような基本的なワークフローであれば、手動・非自動のシステムとしてもこのまま運用できる場合すらあります。
他方で、典型的なML本番プロセスでは、ソフトウェアをCI/CD(継続的インテグレーション/継続的デプロイ)パイプラインでビルド・テストするのと同じように、新しいバージョンのモデルを継続的に再学習・再デプロイする必要があります。そのためには、データクレンジング、前処理、学習、デプロイ、評価といったAPIを含むMLの処理ステップ群を、有向非巡回グラフ(DAG)としてJSONで定義します(Pipelineを構築するための参考例はこちら)。Notebook内のコードは単なるPythonコードなので、パイプラインを含めどこでも実行でき、既存のコードをそのまま再利用できます。
Notebookは開発において強力なツールですが、本番運用に進むにつれて、より強力なインフラが必要になります。本記事では、要素を1つずつ切り出していく方法を紹介しました。これにより、メインシステムを自律的に稼働させながら、Notebookでの作業も並行して続けられます。
本記事が、大規模な本番システムへのステップアップの一助となれば幸いです。
— — —
P.S. 本記事は、私のAWS AI/ML Black Beltでの経験に基づいています。これは、テストベースのAWS Certified ML Specialtyを超える上級認定資格です。Black Beltには上級コースと、認定の基礎となる最終Capstoneプロジェクトが含まれます。本記事で取り上げた領域でスキルを磨き、それを示すうえでうってつけの方法です。詳細はこちらの記事をご覧ください。
お読みいただきありがとうございました! 最新情報はDoiT Engineering Blog、DoiT LinkedInチャンネル、DoiT Twitterチャンネルでフォローいただけます。キャリアの機会についてはhttps://careers.doit-intl.comをご覧ください。