Les pipelines de Machine Learning soulèvent des défis spécifiques pour les équipes qui les construisent et les maintiennent. L'évolution des données dans le temps peut produire des résultats inattendus, et donc des bugs là où on n'en rencontre pas dans d'autres logiciels.
Même lorsque le code n'a pas bougé, le comportement du système, lui, peut changer : ce sont les données utilisées pour entraîner les modèles qui déterminent les prédictions. Si les données sur lesquelles on prédit aujourd'hui diffèrent de celles ayant servi à l'entraînement, plus rien n'est garanti.
Bien comprendre ses données et la façon dont elles évoluent dans le temps facilite grandement le raisonnement sur les pipelines de machine learning. Les équipes ML ont besoin d'outils complémentaires pour garder leurs modèles à jour et leurs prédictions pertinentes : TFX en fait partie.
Passons en revue quelques défis classiques de la mise en production du ML et la façon dont TFX y répond, avec l'aide de Dorothée, Toto et du Magicien d'Oz !
Quand les données ne collent plus à la réalité
Des lions ? Des tigres ? Et des ours ? Oh là là !
Dorothée suit la route de briques jaunes à travers une forêt dense, avec un objectif : rallier la Cité d'Émeraude. Les lions ne l'inquiètent guère, ils sont plutôt poltrons. En revanche, mieux vaut éviter les tigres et les ours.
Avec une bonne connexion 5G, elle récupère un volume confortable de données et entraîne un classifieur capable de distinguer les lions des tigres et des ours. Nous partons du corpus ci-dessous, en espérant enrichir le jeu de données au fil du temps.
Photo de Mika Brandt sur Unsplash
Dorothée envoie Toto en éclaireur, équipé d'une caméra : à mesure qu'il croise de nouveaux animaux, le modèle effectue ses prédictions. La nuit, pendant que l'Épouvantail et l'Homme de Fer-Blanc dorment, elle réentraîne le modèle en y intégrant les nouvelles données collectées. Le classifieur s'améliore ainsi en mêlant le corpus initial aux nouvelles données. Les performances du modèle (précision, perte, etc.) doivent être estimées à partir de données représentatives de ce que l'on s'attend à observer demain ; Dorothée se sert donc des images de Toto pour évaluer le modèle.
Mais Dorothée repère un problème : les images de son corpus sont soigneusement sélectionnées, en haute résolution et au format paysage. Celles de Toto sont nettement moins professionnelles et, comme leur ratio diffère, il va falloir ajuster le modèle.

Les images de Toto sont au format portrait et moins bien cadrées que celles d'entraînement.
Qu'est-ce qu'un pipeline de machine learning ?
Je t'aurai, ma jolie, et ton petit chien aussi !
Dans la vraie vie ;), repérer ce genre de problème de données peut s'avérer délicat. Les données sont souvent collectées sur la durée, et de subtils changements (ou dérives) dans la distribution des features peuvent créer des soucis bien plus loin sur la route de briques jaunes.
Pour détecter une éventuelle anomalie, Dorothée peut surveiller la distribution des features de son corpus (utilisé pour l'entraînement) et la comparer à celle des données collectées par Toto (utilisées pour l'inférence). En suivant le ratio d'aspect des images, elle peut repérer un biais (ou skew) dans son pipeline. Le cas de Dorothée illustre un Distribution Skew : la distribution des valeurs de features dans les données d'entraînement diffère de celle des données d'inférence (ou de service), ce qui peut dégrader la qualité des prédictions (il existe d'autres types de skew).
Un pipeline de machine learning ne se limite pas à l'entraînement : il couvre tout le parcours des données, du stockage à l'inférence, et permet de suivre des métriques utiles sur l'évolution des données et du modèle dans le temps.
Comment Dorothée peut-elle savoir que son modèle pose problème ? Comment juger du bon moment pour le mettre à jour en production ? Et à quelles performances s'attendre par la suite ?
Comment TensorFlow Extended peut aider
Le Magicien d'Oz est unique grâce aux merveilles qu'il accomplit !
TFX simplifie le raisonnement sur votre pipeline de machine learning en production. Il vous aide à comprendre, valider et superviser vos données à grande échelle. Il intègre des mécanismes pour détecter le skew entre données d'entraînement et d'évaluation, mais aussi entre entraînement et inférence. L'architecture est scalable et garantit un processus répétable et reproductible. Dorothée adorerait TFX !
Les pipelines TFX se construisent à partir de composants, des étapes distinctes qui assument chacune une seule responsabilité. Les composants se combinent via les artefacts qu'ils échangent en entrée et en sortie. L'ensemble forme un Directed Acyclic Graph (DAG) qui décrit les dépendances du pipeline ; ils peuvent être planifiés et exécutés efficacement sur un orchestrateur (nous y reviendrons).
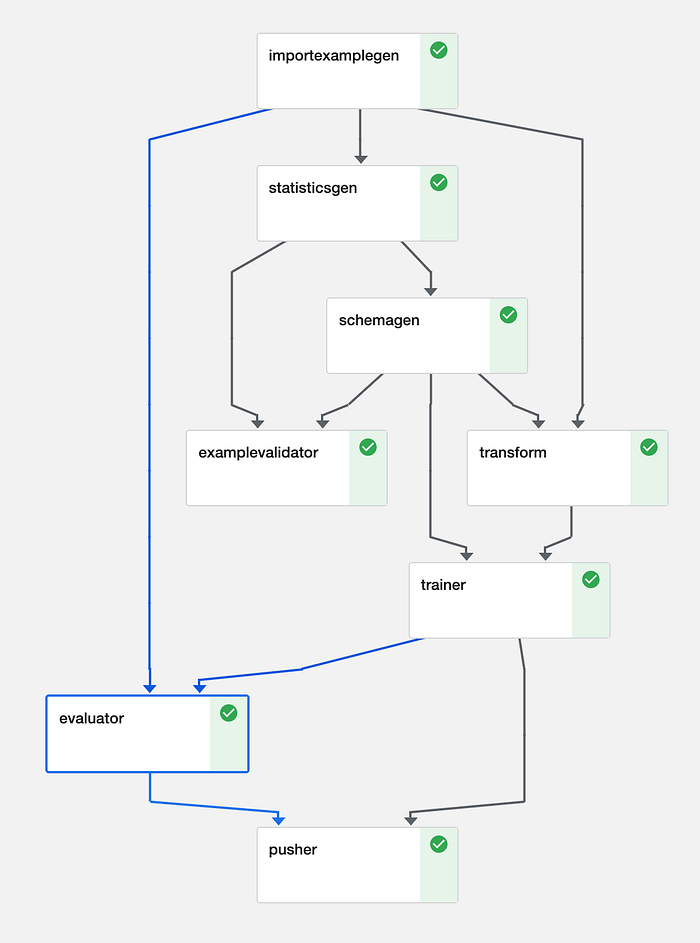
Exemple de DAG pour un pipeline de traitement d'images (Kubeflow)
C'est un pipeline classique, mais comme les composants sont composables, les développeurs peuvent n'en utiliser qu'une partie.
- Les pipelines débutent par un ExampleGen : ces composants récupèrent les données dans leur format brut depuis le stockage (disque/base de données). Les ExampleGens sont liés à votre format de données — CSV, JSON ou TFRecords — et produisent des jeux d'entraînement et d'évaluation. Les composants suivants exploiteront ces données brutes. ImportExampleGen peut par exemple lire des TFRecords depuis un stockage cloud. Si aucun des composants existants ne convient, il suffit d'implémenter le vôtre.
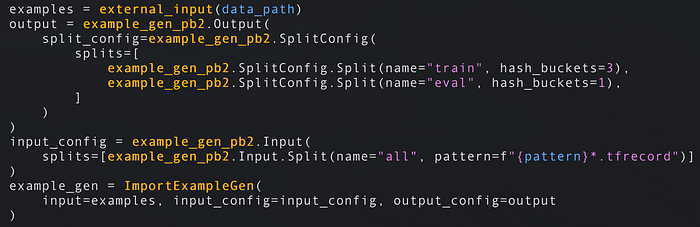
Lecture de TFRecords depuis le disque ou un stockage cloud, avec un découpage 75 %/25 % entraînement/évaluation
- Les composants StatisticsGen, SchemaGen et Example Validator fonctionnent de concert pour vous aider à raisonner sur vos données d'entrée. StatisticsGen calcule des statistiques sur les features de l'ensemble des données. SchemaGen précise les types et les plages de valeurs admissibles ; cela peut être inféré automatiquement, mais une spécification manuelle facilite la détection des erreurs. ExampleValidator détecte les données anormales en s'appuyant sur les sorties de SchemaGen et StatisticsGen (voir le DAG ci-dessus).

Anomalies détectées sur des données tabulaires
- Le composant Transform réalise le feature engineering nécessaire pour mettre les données dans le format attendu par le modèle, à l'entraînement comme à l'inférence. En spécifiant la transformation au sein du pipeline, on s'assure qu'aucune régression ne peut survenir entre les codes d'entraînement, d'évaluation et de service. On évite ainsi d'entraîner par mégarde un modèle sur des features indisponibles au moment de l'inférence : c'est le Schema Skew.
- Trainer reprend les données transformées, puis entraîne et évalue un modèle. Les Estimators et, plus récemment, les modèles basés sur Keras sont pris en charge. Les modèles peuvent être initialisés depuis un stockage pour permettre le warm start ou le transfer learning. La recherche d'hyperparamètres est désormais disponible via un composant Tuner.
- Evaluator et ResolverNode travaillent en tandem pour évaluer le modèle. Le composant Evaluator mesure les métriques sur lesquelles vous souhaitez suivre votre modèle. ResolverNode fournit le meilleur modèle précédent pour exécuter le jeu d'évaluation, ce qui permet de comparer l'ancien et le nouveau dans des conditions identiques. Si le modèle nouvellement entraîné surpasse l'existant, on le " valide ". Des seuils de performance absolus peuvent aussi être définis : par exemple, une précision supérieure à 80 %. Ces composants empêchent les modèles de mauvaise qualité d'arriver en production. On peut également évaluer les métriques par tranche de données — la ROC par heure de la journée, par exemple — pour identifier les zones où le modèle est moins performant et pourrait être amélioré.
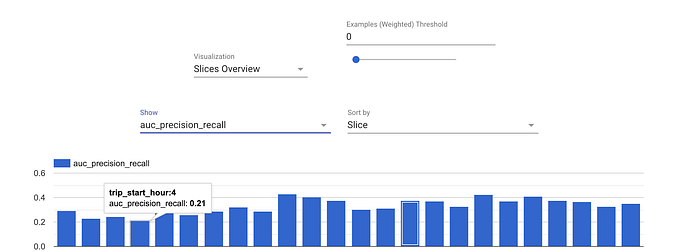
Métriques d'évaluation calculées par heure de la journée
- Pusher persiste le modèle dans le stockage. Avec TensorFlowServing, cette étape peut publier le modèle en production. Pour cibler le mobile ou le navigateur, Pusher prend également en charge TFLite et TF.js.
Quel orchestrateur choisir ?
Ne prêtez pas attention à l'homme derrière le rideau !
TFX apporte un niveau d'abstraction plus élevé pour construire des pipelines ML. Il a été pensé pour être portable : vous n'êtes donc verrouillé ni sur un environnement ni sur un framework d'orchestration. Vous pouvez l'exécuter on-premise ou sur des plateformes cloud, et il est même envisageable qu'un même pipeline tourne sur plusieurs environnements cloud. Cette flexibilité vous permet de choisir la plateforme qui correspond le mieux à vos besoins.
Un DAG TFX s'exécute sur un orchestrateur. TFX en prend actuellement en charge plusieurs.
- Kubeflow (AI Platform Pipelines sur GCP) tourne sur Kubernetes, omniprésent dans les équipes tech et en production. Kubeflow est conçu pour exécuter des pipelines de Machine Learning ; il est moins mature que les autres options et vient tout juste d'atteindre le statut stable. Si vous gérez plusieurs modèles et souhaitez pouvoir scaler votre cluster en fonction de vos besoins d'entraînement, il peut être un bon choix. Servir votre modèle sur Kubernetes est en outre un jeu d'enfant !
- Apache Beam (Cloud Dataflow sur GCP) est idéal pour traiter des jeux de données en parallèle. TFX utilise Beam pour le traitement distribué, et d'autres orchestrateurs s'appuient eux aussi sur Beam (y compris Beam lui-même lorsqu'il sert d'orchestrateur !). Il peut également s'exécuter en local, ce qui est utile pour déboguer un pipeline avec le Direct Runner.
- Airflow (Cloud Composer sur GCP) est populaire dans les équipes Data Engineering ; si vous avez déjà une instance opérationnelle, y exécuter votre pipeline sera familier et demandera peu d'infrastructure supplémentaire à gérer.
Les composants Trainer et Pusher disposent d'exécuteurs leur permettant de fonctionner sur GCP AI Platform pour entraîner et servir votre modèle dans un environnement serverless.
Pour conclure
Toto, j'ai l'impression que nous ne sommes plus au Kansas.

Photo par Akshay Nanavati sur Unsplash
De plus en plus d'équipes prennent aujourd'hui en charge des pipelines de Machine Learning en production. TFX aide à relever certains des défis spécifiques que rencontrent les équipes ML lors du passage en production. Il s'exécute sur une liste croissante d'orchestrateurs : vous disposez peut-être déjà de l'essentiel de l'infrastructure nécessaire pour vous lancer dès aujourd'hui ! Choisir le bon orchestrateur permettra à votre plateforme d'évoluer avec vos données et de soutenir l'expérimentation indispensable à la création de modèles utiles.