機械学習パイプラインは、構築・運用するチームに特有の課題をもたらします。データは時間とともに変化し、その結果として予期せぬ挙動が生じるため、通常のソフトウェアでは見られないような場所にバグが潜むことになります。
コードに変更がなくても、システムの挙動は変わり得ます。なぜなら、モデルの学習に使うデータが予測結果を左右するからです。今日予測対象としているデータが学習時のデータと違っていれば、結果は保証できません。
データそのものと、それが時間とともにどう変化し得るかを理解することで、機械学習パイプラインの挙動を整理しやすくなります。MLチームには、モデルを最新の状態に保ち、予測の有効性を維持するためのツールが欠かせません。TFXはまさにそうしたツールの一つです。
本番環境にMLを導入する際によく直面する課題と、それをTFXがどう解決するのかを、ドロシー、トト、そしてオズの魔法使いの力を借りながら見ていきましょう。
データが現実とずれてしまうとき
「ライオン?トラ?それにクマも?大変だわ!」
ドロシーは黄色いレンガの道をたどって深い森を進み、エメラルドシティを目指しています。ライオンはかなり臆病なのでさほど心配していませんが、トラとクマは何としても避けたい相手です。
5G回線さえつながれば、十分な量のデータを集めて、ライオンとトラ・クマを見分ける分類器を学習させることができます。まずは以下のようなコーパスから始めて、時間をかけてデータセットを充実させていきます。
Photo by Mika Brandt on Unsplash
ドロシーはトトにカメラを持たせて先に行かせ、道中で新しい動物に出会うたびにモデルが予測を行います。夜、案山子とブリキの木こりが眠っている間に、ドロシーは新たに集まったデータを加えてモデルを再学習させます。こうして元のコーパスと新しいデータを組み合わせ、分類器を改善していきます。モデルの性能(精度や損失など)は、明日目にするであろうデータを代表するもので評価すべきなので、ドロシーはトトが撮った画像で評価を行います。
そこでドロシーはある問題に気づきます。コーパス画像は丁寧に整えられた高解像度の横向き写真ばかり。一方、トトの撮る写真はそれほど整っておらず、アスペクト比も異なります。そのため、モデルにいくつか手を加える必要が出てきます。

トトの画像は縦向きで、学習用画像ほどフレーミングが整っていません。
機械学習パイプラインとは
「捕まえてやるよ、お嬢ちゃん。それにその小さな犬もね」
実際の運用環境では、こうしたデータの問題を見つけ出すのは容易ではありません。データは時間をかけて収集することが多く、特徴量分布のわずかな変化(ドリフト)が、黄色いレンガの道のさらに先で問題を引き起こすことがあります。
ドロシーが異変に気づくための一つの方法は、コーパスデータ(学習用)とトトが収集したデータ(推論用)の特徴量分布を比較してモニタリングすることです。画像のアスペクト比を継続的にチェックすれば、パイプライン内のバイアス(スキュー)を監視できます。ドロシーが直面しているのは分布スキューの一例で、学習データと推論(サービング)データの特徴量分布が異なり、予測品質の低下につながる恐れがあります(他の種類のスキューもあります)。
機械学習パイプラインは学習工程だけにとどまらず、ストレージから推論までのデータの流れ全体を網羅し、データやモデルの変化に関する有用なメトリクスを継続的に追跡できるようにするものです。
では、ドロシーは自分の機械学習モデルに問題があることをどう見抜けばよいのでしょうか。本番のモデルをいつ更新すべきか、どう判断すればよいのでしょうか。そして、将来モデルがどの程度の性能を発揮するか、どう見積もればよいのでしょうか。
TensorFlow Extendedの活用方法
「オズの魔法使いが魔法使いと呼ばれるのは、素晴らしいことをやってのけるからだ!」
TFXを使えば、本番運用中の機械学習パイプラインを把握しやすくなり、大規模なデータの理解、検証、モニタリングを支援してくれます。学習データと評価データ、そして学習データと推論データの間のスキューを検出する仕組みも備えています。アーキテクチャはスケーラブルで、プロセスの再現性と再実行性を担保します。きっとドロシーもTFXを気に入るはずです。
TFXのパイプラインはコンポーネントから構成されます。各コンポーネントは一つの役割だけを担う独立したステップで、入出力としてやり取りするアーティファクトを介して連結されます。コンポーネントの集まりは有向非巡回グラフ(DAG)を形成し、これがパイプラインの依存関係を表現します。DAGはオーケストレーター上で効率的にスケジューリング・実行されます(オーケストレーターについては後述)。
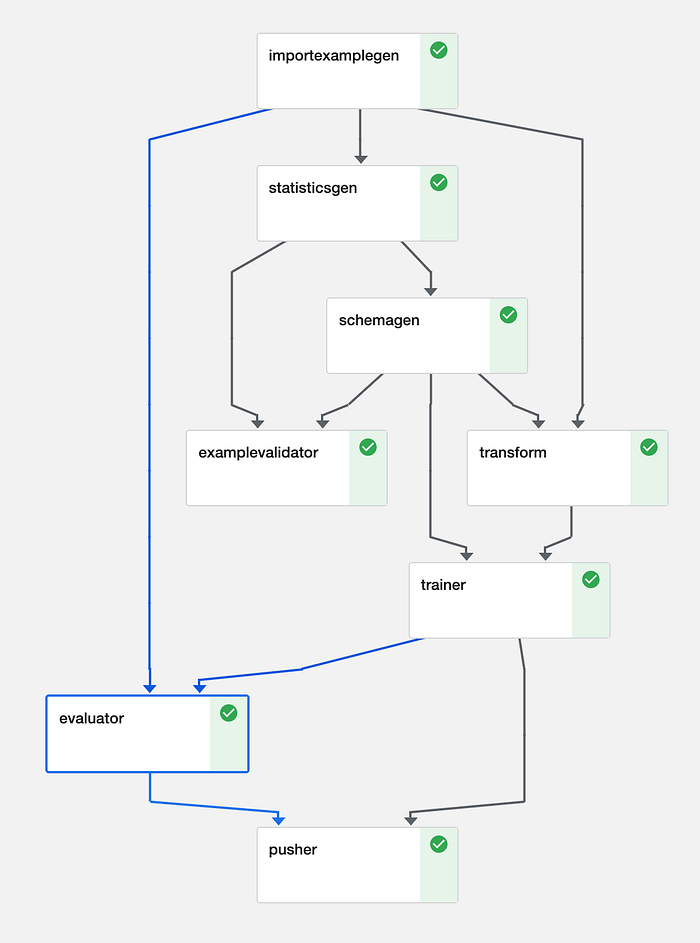
画像処理パイプラインのDAG例(Kubeflow)
これは典型的なパイプラインですが、コンポーネントは組み合わせ自由なので、開発者は以下のうち必要なものだけを選んで使うこともできます。
- パイプラインはExampleGenから始まります。これは、ストレージ(ディスクやデータベース)から生のフォーマットでデータを取得するコンポーネントです。ExampleGenはCSV、JSON、TFRecordsといったデータ形式に対応しており、学習用と評価用のセットを出力します。後続のコンポーネントはこの生データを使って処理を進めます。例えばImportExampleGenはクラウドストレージからTFRecordsを読み込めます。既存のExampleGenでは要件を満たせない場合は、独自に実装することもできます。
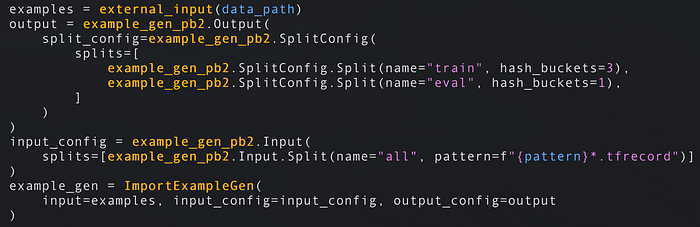
ディスクやクラウドストレージからTFRecordsを読み込み、学習データを75%/25%で学習用と評価用に分割
- StatisticsGen、SchemaGen、Example Validatorの各コンポーネントは連携し、入力データの把握をサポートします。StatisticsGenはデータ全体の特徴量統計を算出します。SchemaGenはデータが取り得る型や範囲を定義します。これは自動推定も可能ですが、範囲を手動で指定すれば異常検出が容易になります。ExampleValidatorはSchemaGenとStatisticsGenの出力をもとに、異常データを検出します(上記DAG参照)。

表形式データで検出された異常
- Transformコンポーネントは、学習・推論時にモデルが扱える形式にデータを整えるための特徴量エンジニアリングを行います。変換処理をパイプラインに組み込むことで、学習・評価・サービング用コードの間にリグレッションが入り込む余地をなくします。これにより、推論時には利用できない特徴量を誤って学習に使ってしまうSchema Skewを防げます。
- Trainerは変換済みのデータを受け取り、モデルの学習と評価を行います。Estimatorsに加えて、より新しいKerasベースのモデルもサポートされています。モデルはストレージから初期化することができ、ウォームスタートや転移学習にも対応します。ハイパーパラメータ探索のサポートも最近リリースされ、Tunerコンポーネントとして実装されています。
- EvaluatorとResolverNodeは連携してモデルを評価します。Evaluatorコンポーネントは、追跡したいメトリクスに照らしてモデルを評価します。ResolverNodeは、評価セットに対する比較対象として過去のベストモデルを提供し、新旧モデルを公平な条件で比較できるようにします。新たに学習したモデルが既存モデルを上回れば、その新モデルを「bless(承認)」します。「精度は80%を超えること」といった絶対的な性能基準を指定することも可能です。これらのコンポーネントによって、品質の低いモデルが本番環境に流れ込むのを防げます。さらに、データのスライス単位でメトリクスを評価することもでき、例えば時間帯別のROCを見ることで、モデルが弱い箇所や改善の余地を見つけ出せます。
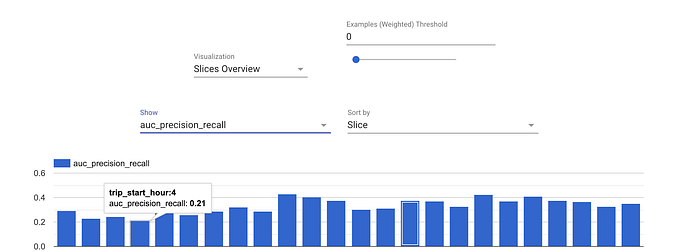
時間帯別に算出された評価メトリクス
- Pusherはモデルをストレージに永続化します。TensorFlowServingを使っている場合、このステップでモデルを本番環境にリリースできます。モバイルやブラウザを対象とする場合、PusherはTFLiteやTF.jsにも対応しています。
どのオーケストレーターを選ぶべきか
カーテンの後ろの男には目を向けるな!
TFXはMLパイプライン構築のための高レベルな抽象化を提供します。ポータビリティを重視した設計のため、特定の環境やオーケストレーションフレームワークに縛られることはありません。さらに、オンプレミスでもクラウド上でも実行でき、複数のクラウド環境にまたがってパイプラインを動かすことも十分可能です。この柔軟性のおかげで、自分たちのニーズに最適なプラットフォームを選択できます。
TFXのDAGはオーケストレーター上で実行されます。現時点でTFXがサポートするオーケストレーターは以下の通りです。
- Kubeflow(GCPではAI Platform Pipelines)はKubernetes上で動作します。Kubernetesは技術チームや本番環境で広く使われています。Kubeflowは機械学習パイプラインの実行を目的に設計されており、他の選択肢と比べると成熟度はやや低く、ようやく安定版に到達したばかりです。複数のモデルを管理し、学習ニーズに合わせてクラスターをスケールしたい場合には有力な選択肢になるでしょう。Kubernetes上でのモデルのサービングも非常にスムーズです。
- Apache Beam(GCPではCloud Dataflow)は、データセットの並列処理に優れています。TFXは分散データ処理にBeamを利用しており、他のオーケストレーターもBeamを使用しています(Beam自体をオーケストレーターとして使う場合も含みます)。ローカル実行にも対応しているため、Direct Runnerを使ったパイプラインのデバッグにも便利です。
- Airflow(GCPではCloud Composer)はデータエンジニアリングチームに人気があります。すでに稼働中のインスタンスがあるなら、追加で管理するインフラもほとんどなく、使い慣れた環境でパイプラインを実行できます。
TrainerとPusherの各コンポーネントには、GCP AI Platform上で実行できるエグゼキューターが用意されており、サーバーレス環境でモデルの学習とサービングが行えます。
まとめ
トト、私たちはもうカンザスにはいないみたいね。

Photo by Akshay Nanavati on Unsplash
本番環境で機械学習パイプラインの運用を担うチームは、かつてないほど増えています。TFXは、MLチームがソフトウェアを本番に届けるうえで直面する固有の課題のいくつかを解決してくれます。対応するオーケストレーターも増え続けており、今日からTFXを使い始めるのに必要なインフラの大部分は、すでに手元に揃っているかもしれません。適切なオーケストレーターを選べば、データの拡大に合わせてプラットフォームを成長させ、有用なモデルを生み出すために欠かせない実験も支えられます。