Los pipelines de Machine Learning suponen un reto para los equipos que los construyen y mantienen. Los cambios en los datos a lo largo del tiempo pueden derivar en resultados inesperados, lo que se traduce en bugs en lugares donde no aparecen en otro tipo de software.
Aunque el código no haya cambiado, el comportamiento del sistema sí puede hacerlo, porque los datos con los que entrenamos nuestros modelos determinan las predicciones que hacemos. Si los datos sobre los que predecimos hoy son distintos de los que usamos para entrenar, ¡nada está garantizado!
Entender tus datos y cómo pueden cambiar con el tiempo facilita razonar sobre los pipelines de machine learning. Los equipos de ML necesitan herramientas adicionales para mantener sus modelos al día y sus predicciones relevantes; TFX es una de ellas.
Veamos algunos retos comunes al llevar ML a producción y cómo los resuelve TFX, ¡con un poco de ayuda de Dorothy, Toto y el Mago de Oz!
Cuando los datos no coinciden con la realidad
"¿Leones? ¿Tigres? ¿Y osos? ¡Ay, no!"
Dorothy avanza por el camino de baldosas amarillas a través de un bosque denso, ¡quiere llegar hasta la Ciudad Esmeralda! No le preocupan demasiado los leones: son bastante cobardes. A los tigres y a los osos sí conviene evitarlos.
Con una buena conexión 5G consigue una cantidad considerable de datos y entrena un clasificador para distinguir leones de tigres y osos. Empezamos con un corpus como el siguiente y esperamos ir ampliando el dataset con el tiempo.
Foto de Mika Brandt en Unsplash
Dorothy envía a Toto por delante con una cámara y, a medida que se topa con animales nuevos, el modelo hace predicciones. Por la noche, mientras el Espantapájaros y el Hombre de Hojalata duermen, ella reentrena el modelo añadiendo los datos recién recopilados. Así, el clasificador irá mejorando, combinando el corpus original con datos nuevos. El desempeño del modelo (accuracy, loss, etc.) debería estimarse a partir de datos representativos de lo que esperamos ver al día siguiente, así que Dorothy usa las fotos de Toto para evaluarlo.
Dorothy detecta un problema: las imágenes de su corpus están bien curadas, son de alta resolución y tienen orientación horizontal. Las fotos de Toto no son tan profesionales y, como la relación de aspecto es distinta, tendrá que hacer ajustes en el modelo.

Las fotos de Toto son verticales y no están tan bien encuadradas como las de entrenamiento.
¿Qué es un pipeline de machine learning?
"¡Te atraparé, preciosa, y a tu perrito también!"
En la vida real ;), detectar este tipo de problemas en los datos puede ser complicado. Muchas veces los datos se recopilan a lo largo del tiempo, y cambios sutiles (o drifts) en la distribución de las features pueden hacer que los problemas se cuelen más adelante en el camino de baldosas amarillas.
Una forma en que Dorothy puede notar que algo no anda bien es monitorear la distribución de las features en los datos de su corpus (usados para entrenar) frente a los datos que recopila Toto (usados para inferencia). Al llevar un control de la relación de aspecto de las imágenes, Dorothy puede vigilar el sesgo (o skew) en su pipeline. El problema de Dorothy es un ejemplo de Distribution Skew: la distribución de los valores de las features en los datos de entrenamiento difiere de la de los datos de inferencia (o serving), lo que puede llevar a predicciones de mala calidad ( existen otros tipos de skew).
Un pipeline de machine learning abarca mucho más que el entrenamiento: cubre todo el recorrido de los datos, desde el almacenamiento hasta la inferencia, y te ayuda a hacer seguimiento de métricas útiles sobre los cambios en los datos y en el modelo a lo largo del tiempo.
¿Cómo puede saber Dorothy si su modelo de machine learning tiene un problema? ¿Cómo decide cuándo actualizar su modelo en producción? ¿Qué tan bien debería esperar que rinda en el futuro?
Cómo puede ayudar TensorFlow Extended
"¡El Mago de Oz lo es por las cosas maravillosas que hace!"
TFX facilita razonar sobre tu pipeline de machine learning en producción. Te ayuda a entender, validar y monitorear tus datos a escala. Cuenta con mecanismos para detectar skew entre tus datos de entrenamiento y evaluación, así como entre los de entrenamiento e inferencia. Su arquitectura es escalable y garantiza que el proceso sea repetible y reproducible. ¡A Dorothy le encantaría TFX!
Los pipelines en TFX se construyen a partir de componentes: pasos diferenciados, cada uno responsable de una sola cosa. Los componentes se conectan a través de los artefactos que intercambian como entradas y salidas. El conjunto de componentes forma un Directed Acyclic Graph (DAG) que describe las dependencias del pipeline, y se pueden agendar y ejecutar de forma eficiente en un orchestrator (más sobre esto en breve).
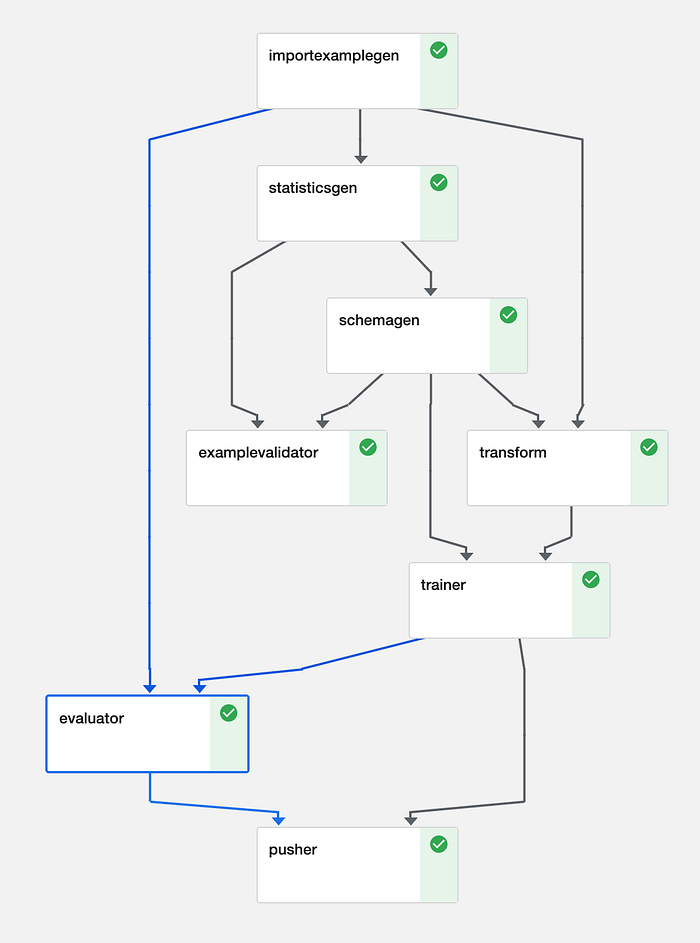
Ejemplo de DAG para un pipeline de procesamiento de imágenes (Kubeflow)
Este es un pipeline clásico, pero los desarrolladores pueden optar por usar solo algunos de los siguientes componentes, ya que son combinables.
- Los pipelines arrancan con un ExampleGen: estos componentes obtienen los datos en formato crudo desde el almacenamiento (disco/base de datos). Los ExampleGens están acoplados al formato de tus datos —CSV, JSON o TFRecords— y producen los conjuntos de entrenamiento y evaluación. Los componentes posteriores usarán estos datos crudos. ImportExampleGen, por ejemplo, puede leer TFRecords desde almacenamiento en la nube. Si ninguno de los componentes de ejemplo te resulta suficiente, simplemente implementa el tuyo propio.
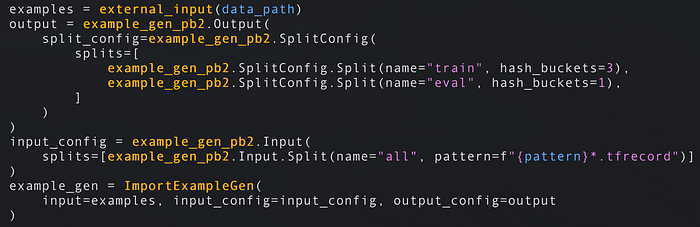
Lee TFRecords desde disco/almacenamiento en la nube y divide los datos de entrenamiento 75 %/25 % entre train/eval
- Los componentes StatisticsGen, SchemaGen y Example Validator trabajan en conjunto y te ayudan a razonar sobre los datos de entrada. StatisticsGen calcula estadísticas de las features sobre los datos. SchemaGen especifica los tipos y rangos que pueden tomar los datos; esto puede inferirse automáticamente, pero definir los rangos a mano facilita detectar errores. ExampleValidator detecta datos anómalos a partir de las salidas de SchemaGen y StatisticsGen (ver el DAG anterior).

Anomalías detectadas en datos tabulares
- El componente Transform realiza el feature engineering necesario para llevar los datos al formato correcto que usará el modelo durante el entrenamiento y la inferencia. Al especificar la transformación dentro del pipeline, nos aseguramos de que no haya regresiones en el código de entrenamiento, evaluación o serving. Esto evita entrenar accidentalmente con features que no estarán disponibles en el momento de la inferencia, lo que se conoce como Schema Skew.
- Trainer toma los datos transformados, entrena y evalúa un modelo. Se admiten tanto Estimators como, más recientemente, modelos basados en Keras. Los modelos pueden inicializarse desde almacenamiento, lo que habilita escenarios de warm start o transfer learning. El soporte para búsqueda de hiperparámetros se liberó hace poco y se implementa mediante un componente Tuner.
- Evaluator y ResolverNode trabajan en conjunto para evaluar el modelo. El componente Evaluator mide las métricas que nos interesa monitorear. ResolverNode aporta el mejor modelo previo contra el cual ejecutar el set de evaluación, asegurando que comparemos lo viejo con lo nuevo en igualdad de condiciones. Si el modelo recién entrenado supera al existente, "bendecimos" al nuevo modelo. También se pueden definir métricas de desempeño absolutas; por ejemplo, que la accuracy supere el 80 %. Estos componentes evitan que modelos de mala calidad lleguen a producción. Además, podemos evaluar métricas por segmentos de los datos —por ejemplo, ROC por hora del día—, lo que nos da visibilidad sobre dónde podría estar fallando nuestro modelo y dónde tiene margen de mejora.
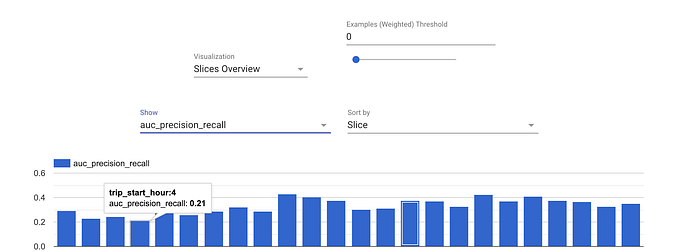
Métricas de evaluación calculadas por hora del día
- Pusher persiste el modelo en almacenamiento. Si usamos TensorFlowServing, este paso puede liberar el modelo a producción. Si tu objetivo es mobile o el navegador, Pusher también soporta TFLite y TF.js.
¿Qué orchestrator debería usar?
¡No prestes atención al hombre detrás de la cortina!
TFX ofrece un mayor nivel de abstracción a la hora de construir pipelines de ML. Está diseñado para ser portable, lo que significa que no quedas atado a un único entorno o framework de orquestación. Además, puedes ejecutarlo on-premise o en plataformas de nube; incluso es viable que un pipeline corra en varios entornos cloud. Esta flexibilidad te permite elegir la plataforma que mejor se adapte a tus necesidades.
Un DAG de TFX se ejecuta sobre un Orchestrator; actualmente, TFX soporta varios.
- Kubeflow (AI Platform Pipelines en GCP) corre sobre Kubernetes, también omnipresente en equipos técnicos y entornos productivos. Kubeflow está pensado para ejecutar pipelines de Machine Learning; es menos maduro que las otras opciones y recién alcanzó el estado stable. Si gestionas múltiples modelos y quieres poder escalar tu clúster para cubrir tus necesidades de entrenamiento, puede ser una buena alternativa. ¡Servir tu modelo en Kubernetes también es muy sencillo!
- Apache Beam (Cloud Dataflow en GCP) es excelente para procesar datasets en paralelo. TFX usa Beam para el procesamiento distribuido de datos, y por eso otros orchestrators también lo usan (¡incluido el propio Beam cuando lo utilizas como orchestrator!). También se puede ejecutar localmente, así que resulta útil para depurar un pipeline mediante Direct Runner.
- Airflow (Cloud Composer en GCP) es popular en los equipos de Data Engineering; si ya tienes una instancia funcionando, ejecutar tu pipeline allí te resultará familiar y requerirá poca infraestructura adicional.
Los componentes Trainer y Pusher cuentan con executors que permiten ejecutarlos en la GCP AI platform para entrenar y servir tu modelo en un entorno serverless.
Reflexiones finales
Toto, tengo el presentimiento de que ya no estamos en Kansas.

Foto de Akshay Nanavati en Unsplash
Cada vez más equipos son responsables de gestionar pipelines de Machine Learning en producción. TFX ayuda a manejar algunos de los retos únicos que enfrentan los equipos de ML al llevar su software al entorno productivo. TFX corre sobre una lista creciente de orchestrators, ¡así que es probable que ya cuentes con buena parte de la infraestructura necesaria para empezar a usarlo hoy mismo! Elegir el orchestrator adecuado permitirá que tu plataforma crezca a la par de tus datos y soporte la experimentación necesaria para construir modelos verdaderamente útiles.