Machine-Learning-Pipelines stellen die Teams, die sie aufbauen und betreiben, vor besondere Herausforderungen. Verändern sich die Daten im Lauf der Zeit, kann das zu unerwartetem Verhalten führen – und damit zu Bugs an Stellen, an denen man sie aus anderer Software nicht kennt.
Selbst wenn der Code unverändert bleibt, kann sich das Systemverhalten ändern. Denn die Daten, mit denen wir unsere Modelle trainieren, bestimmen, welche Vorhersagen sie treffen. Unterscheiden sich die Daten, auf die wir heute Vorhersagen anwenden, von denen, mit denen wir trainiert haben, ist alles offen.
Wer seine Daten und ihre Veränderungen im Zeitverlauf versteht, tut sich beim Arbeiten mit Machine-Learning-Pipelines deutlich leichter. ML-Teams brauchen zusätzliche Werkzeuge, um Modelle aktuell und Vorhersagen relevant zu halten – TFX ist genau so ein Werkzeug.
Werfen wir einen Blick auf typische Stolpersteine beim produktiven Einsatz von ML – und darauf, wie TFX sie aus dem Weg räumt. Mit etwas Hilfe von Dorothy, Toto und dem Zauberer von Oz!
Wenn die Daten nicht zur Realität passen
"Löwen? Tiger? Und Bären? Oh nein!"
Dorothy folgt der gelben Ziegelsteinstraße durch dichten Wald, denn sie will unbedingt zur Smaragdstadt. Vor Löwen hat sie wenig Angst – die sind eher feige. Tiger und Bären sind dagegen besser zu meiden.
Mit einer stabilen 5G-Verbindung kommt sie an reichlich Daten und trainiert einen Klassifikator, der Löwen von Tigern und Bären unterscheidet. Wir starten mit dem unten gezeigten Korpus und wollen den Datensatz im Lauf der Zeit ausbauen.
Foto von Mika Brandt auf Unsplash
Dorothy schickt Toto mit einer Kamera voraus, und sobald er unterwegs neuen Tieren begegnet, trifft das Modell Vorhersagen. Über Nacht, während Scarecrow und der Tin Man schlafen, trainiert sie das Modell mit den frisch gesammelten Daten neu. So wird der Klassifikator Schritt für Schritt besser, weil er den ursprünglichen Korpus mit neuen Daten kombiniert. Die Modellgüte (Accuracy, Loss usw.) sollte anhand von Daten geschätzt werden, die repräsentativ für das sind, was uns morgen erwartet – darum nutzt Dorothy Totos Bilder zur Evaluierung.
Dann fällt Dorothy ein Problem auf: Ihre Korpusbilder sind sorgfältig kuratiert, hochauflösend und im Querformat. Totos Aufnahmen sind weit weniger professionell, und weil das Seitenverhältnis abweicht, muss sie ihr Modell anpassen.

Totos Bilder sind im Hochformat und nicht so gut komponiert wie unsere Trainingsbilder.
Was ist eine Machine-Learning-Pipeline?
"Ich krieg dich, meine Süße – und deinen kleinen Hund auch!"
In freier Wildbahn ;) sind solche Datenprobleme nur schwer aufzuspüren. Häufig sammelt man Daten über lange Zeiträume hinweg, und subtile Verschiebungen (Drifts) in der Verteilung der Features können Probleme verursachen, die erst weit später auf der gelben Ziegelsteinstraße auftauchen.
Eine Möglichkeit für Dorothy, Unstimmigkeiten zu erkennen: Sie vergleicht die Feature-Verteilungen ihres Korpus (für das Training) mit den Daten, die Toto sammelt (für die Inferenz). Behält sie das Seitenverhältnis der Bilder im Auge, kann sie einen Bias (oder Skew) in ihrer Pipeline überwachen. Dorothys Problem ist ein Beispiel für Distribution Skew: Die Verteilung der Feature-Werte in den Trainingsdaten unterscheidet sich von den Inferenz- bzw. Serving-Daten – mit der Folge, dass die Vorhersagequalität leiden kann (es gibt noch weitere Arten von Skew).
Eine Machine-Learning-Pipeline umfasst mehr als nur das Training: Sie deckt den gesamten Datenweg von der Speicherung bis zur Inferenz ab und hilft dabei, aussagekräftige Metriken zu Veränderungen von Daten und Modell im Zeitverlauf zu verfolgen.
Wie merkt Dorothy, dass mit ihrem Machine-Learning-Modell etwas nicht stimmt? Wann sollte sie ihr Modell in der Produktion aktualisieren? Und wie gut darf sie erwarten, dass es künftig abschneidet?
Wie TensorFlow Extended hilft
"Der Zauberer von Oz ist einer – wegen der wunderbaren Dinge, die er tut!"
TFX vereinfacht die Arbeit mit Ihrer produktiven Machine-Learning-Pipeline. Es unterstützt Sie dabei, Ihre Daten skalierbar zu verstehen, zu validieren und zu überwachen. Außerdem bietet es Mechanismen, um Skew sowohl zwischen Trainings- und Evaluierungsdaten als auch zwischen Trainings- und Inferenzdaten zu erkennen. Die Architektur ist skalierbar und sorgt dafür, dass Ihr Prozess wiederholbar und reproduzierbar bleibt. Dorothy hätte ihre Freude an TFX!
Pipelines in TFX werden aus Komponenten aufgebaut – einzelnen Schritten, die jeweils für genau eine Aufgabe zuständig sind. Verknüpft werden sie über die Artefakte, die sie als Inputs und Outputs austauschen. Mehrere Komponenten zusammen bilden einen Directed Acyclic Graph (DAG), der die Abhängigkeiten der Pipeline beschreibt. Sie lassen sich effizient auf einem Orchestrator einplanen und ausführen (dazu später mehr).
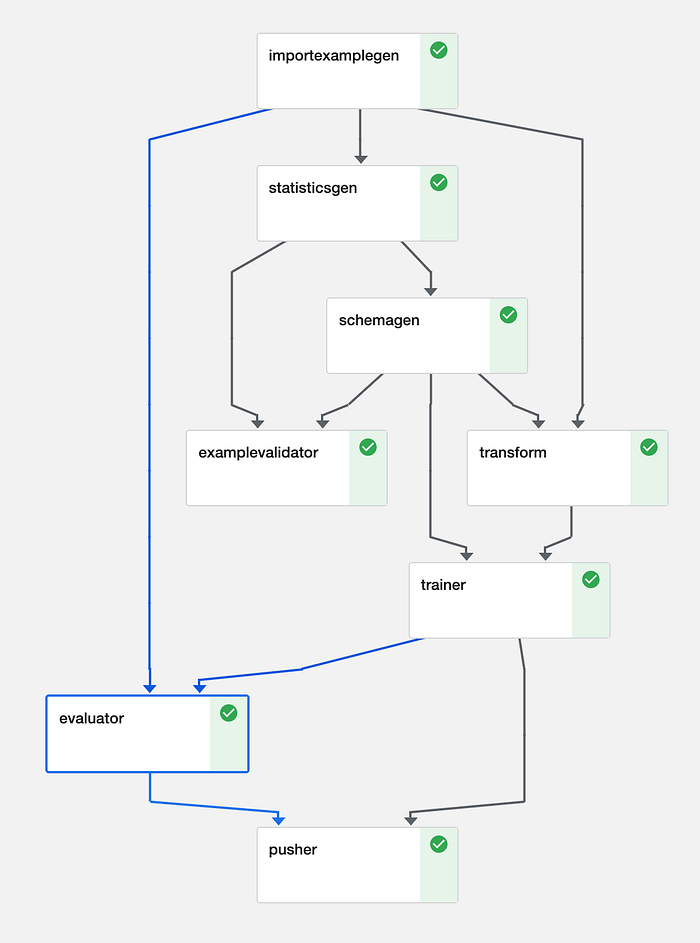
Beispielhafter DAG für eine Bildverarbeitungs-Pipeline (Kubeflow)
Das ist eine klassische Pipeline. Da die Komponenten kombinierbar sind, lässt sich aber auch nur ein Teil der folgenden Bausteine nutzen.
- Pipelines beginnen mit einem ExampleGen; diese Komponenten beziehen die Rohdaten aus dem Speicher (Disk/Datenbank). ExampleGens sind an Ihr Datenformat gekoppelt – CSV, JSON oder TFRecords – und erzeugen Trainings- und Evaluierungssets. Die nachfolgenden Komponenten arbeiten mit diesen Rohdaten weiter. ImportExampleGen kann zum Beispiel TFRecords aus Cloud-Speicher lesen. Wenn keine der mitgelieferten Komponenten passt, schreiben Sie einfach Ihre eigene.
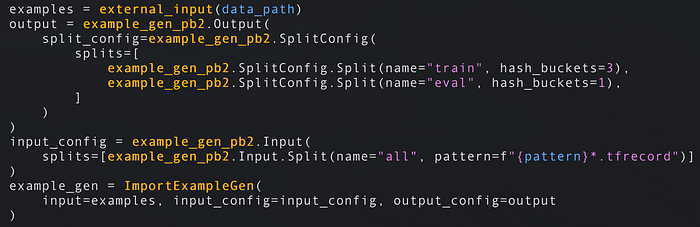
TFRecords aus Disk-/Cloud-Speicher lesen und die Trainingsdaten 75 % / 25 % auf Train/Eval aufteilen
- Die Komponenten StatisticsGen, SchemaGen und Example Validator arbeiten zusammen und helfen dabei, die Eingangsdaten zu durchdringen. StatisticsGen berechnet Feature-Statistiken über die Daten hinweg. SchemaGen legt die Typen und Wertebereiche fest, die die Daten annehmen können – das lässt sich automatisch ableiten, doch eine manuelle Vorgabe der Wertebereiche erleichtert die Fehlersuche. ExampleValidator erkennt anomale Daten anhand der Outputs von SchemaGen und StatisticsGen (siehe DAG oben).

In tabellarischen Daten erkannte Anomalien
- Die Komponente Transform übernimmt das Feature Engineering und bringt die Daten in das Format, das das Modell beim Training und bei der Inferenz benötigt. Indem wir die Transformation in der Pipeline definieren, schließen wir aus, dass Trainings-, Evaluierungs- oder Serving-Code Regressionen aufweisen. So vermeiden wir, dass wir versehentlich mit Features trainieren, die zur Inferenzzeit gar nicht verfügbar sind – also Schema Skew.
- Trainer nimmt unsere transformierten Daten und trainiert sowie evaluiert ein Modell. Unterstützt werden sowohl Estimators als auch – seit Kurzem – Keras-basierte Modelle. Modelle lassen sich aus dem Speicher initialisieren, was Warm-Start- oder Transfer-Learning-Szenarien ermöglicht. Auch eine Hyperparameter-Suche ist seit Kurzem verfügbar und wird über eine Tuner-Komponente umgesetzt.
- Evaluator und ResolverNode arbeiten bei der Modellbewertung Hand in Hand. Die Evaluator-Komponente berechnet die Metriken, anhand derer wir unser Modell bewerten wollen. ResolverNode liefert das bisher beste Modell, gegen das die Evaluierung läuft – so vergleichen wir Alt und Neu zu fairen Bedingungen. Schlägt das neu trainierte Modell das bestehende, wird das neue Modell "gesegnet". Auch absolute Performance-Schwellen lassen sich angeben, etwa eine Accuracy von mindestens 80 %. Diese Komponenten verhindern, dass Modelle minderer Qualität in die Produktion gelangen. Metriken können wir außerdem über Slices der Daten hinweg auswerten, etwa ROC nach Tagesstunde – das zeigt, wo unser Modell schwächelt und sich verbessern ließe.
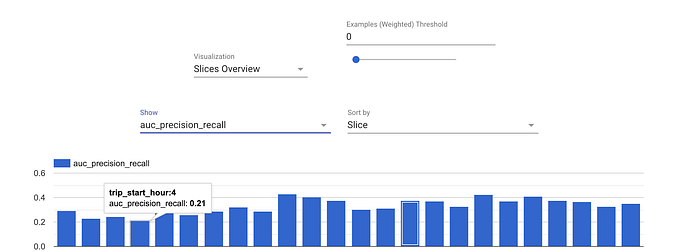
Nach Tagesstunde berechnete Evaluierungsmetriken
- Pusher persistiert unser Modell im Speicher. Setzen wir TensorFlow Serving ein, kann dieser Schritt das Modell in die Produktion ausrollen. Wer mobile Endgeräte oder den Browser anvisiert: Pusher unterstützt auch TFLite und TF.js.
Welchen Orchestrator soll ich nutzen?
Schenken Sie dem Mann hinter dem Vorhang keine Beachtung!
TFX bietet beim Aufbau von ML-Pipelines eine höhere Abstraktionsebene. Es ist auf Portabilität ausgelegt – Sie sind also nicht an eine einzelne Umgebung oder ein Orchestrierungs-Framework gebunden. Sie können es on-premise oder auf Cloud-Plattformen betreiben, und es ist sogar denkbar, eine Pipeline über mehrere Cloud-Umgebungen hinweg auszuführen. Diese Flexibilität bedeutet: Sie wählen die Plattform, die am besten zu Ihren Anforderungen passt.
Ein TFX-DAG wird auf einem Orchestrator ausgeführt – aktuell unterstützt TFX mehrere Optionen.
- Kubeflow (AI Platform Pipelines auf GCP) läuft auf Kubernetes, das in Tech-Teams und in der Produktion ohnehin allgegenwärtig ist. Kubeflow ist speziell für Machine-Learning-Pipelines konzipiert; es ist weniger ausgereift als die anderen Optionen und hat erst kürzlich Stable-Status erreicht. Wenn Sie mehrere Modelle verwalten und Ihren Cluster passend zu Ihren Trainingsanforderungen skalieren wollen, kann es eine gute Wahl sein. Auch das Serving Ihres Modells auf Kubernetes ist ein Kinderspiel.
- Apache Beam (Cloud Dataflow auf GCP) eignet sich hervorragend für die parallele Verarbeitung von Datensätzen. TFX nutzt Beam für die verteilte Datenverarbeitung, und auch andere Orchestratoren setzen auf Beam (einschließlich Beam selbst, wenn Sie es als Orchestrator verwenden!). Da es sich auch lokal ausführen lässt, eignet es sich gut zum Debuggen einer Pipeline mit dem Direct Runner.
- Airflow (Cloud Composer auf GCP) ist in Data-Engineering-Teams beliebt; wenn Sie bereits eine laufende Instanz haben, fühlt sich der Pipeline-Betrieb dort vertraut an, und Sie müssen kaum zusätzliche Infrastruktur verwalten.
Die Komponenten Trainer und Pusher verfügen über Executors, mit denen sich die Ausführung auf der GCP AI Platform nutzen lässt, um Ihr Modell in einer Serverless-Umgebung zu trainieren und auszuliefern.
Abschließende Gedanken
Toto, ich habe das Gefühl, wir sind nicht mehr in Kansas.

Foto von Akshay Nanavati auf Unsplash
Mehr Teams als je zuvor sind dafür verantwortlich, Machine-Learning-Pipelines im Produktivbetrieb zu managen. TFX hilft, einige der besonderen Hürden zu nehmen, vor denen ML-Teams stehen, wenn sie ihre Software in die Produktivumgebung bringen. TFX läuft auf einer wachsenden Liste von Orchestratoren – möglicherweise haben Sie schon den Großteil der nötigen Infrastruktur, um heute mit TFX loszulegen. Mit dem richtigen Orchestrator wächst Ihre Plattform mit Ihren Daten mit und unterstützt das Experimentieren, das es für wirklich nützliche Modelle braucht.