Le pipeline di Machine Learning pongono sfide non banali ai team che le costruiscono e le mantengono. Le variazioni dei dati nel tempo possono produrre risultati inattesi, generando bug in punti dove non li troveresti in altri tipi di software.
Anche quando il codice non cambia, il comportamento del sistema può cambiare lo stesso: i dati con cui addestriamo i modelli determinano le previsioni che otteniamo. Se i dati su cui facciamo previsioni oggi sono diversi da quelli usati in addestramento, ogni previsione diventa un terno al lotto.
Capire i propri dati e come possono evolvere nel tempo aiuta a ragionare meglio sulle pipeline di machine learning. I team ML hanno bisogno di strumenti aggiuntivi per mantenere i modelli aggiornati e le previsioni rilevanti: TFX è uno di questi.
Vediamo alcune sfide ricorrenti nel portare il ML in produzione e come TFX le affronta, con un piccolo aiuto da Dorothy, Toto e il Mago di Oz!
Quando i dati non rispecchiano la realtà
"Leoni? Tigri? E Orsi? Oh cielo!"
Dorothy percorre la strada di mattoni gialli attraverso una fitta foresta: vuole arrivare fino alla Città di Smeraldo! I Leoni non la preoccupano più di tanto, sono piuttosto codardi. Tigri e Orsi, invece, sono da evitare.
Con una buona connessione 5G, Dorothy riesce a procurarsi una discreta quantità di dati e ad addestrare un classificatore per distinguere i Leoni da Tigri e Orsi. Si parte da un corpus come quello qui sotto, con l'idea di ampliare il dataset nel tempo.
Foto di Mika Brandt su Unsplash
Dorothy manda Toto in avanscoperta con una macchina fotografica e, man mano che incontra nuovi animali lungo il cammino, il modello fa le sue previsioni. Di notte, mentre lo Spaventapasseri e l'Uomo di Latta dormono, Dorothy riaddestra il modello aggiungendo i dati appena raccolti. Così facendo il classificatore migliora, fondendo il corpus originale con i nuovi dati. Le prestazioni del modello (accuratezza, loss, ecc.) andrebbero stimate su dati rappresentativi di ciò che ci aspettiamo di vedere domani: per questo Dorothy usa le foto di Toto per valutare il modello.
Ma Dorothy si accorge di un problema: le immagini del suo corpus sono ben curate, ad alta risoluzione e in orizzontale. Quelle di Toto non sono altrettanto professionali e, dato che il rapporto d'aspetto è diverso, Dorothy dovrà apportare qualche modifica al modello.

Le immagini di Toto sono in verticale e non sono inquadrate bene come quelle di addestramento.
Cos'è una pipeline di machine learning?
"Ti prenderò, mia cara, e anche il tuo cagnolino!"
Nella realtà ;) individuare questo tipo di problemi nei dati può essere insidioso. Spesso raccogliamo dati nel tempo e variazioni sottili (o drift) nella distribuzione delle feature possono far emergere problemi più a valle, lungo la strada di mattoni gialli.
Un modo per accorgersene è monitorare la distribuzione delle feature nei dati del corpus (usati per il training) rispetto a quelli raccolti da Toto (usati per l'inferenza). Tenendo d'occhio il rapporto d'aspetto delle immagini, Dorothy può individuare bias (o skew) nella sua pipeline. Quello di Dorothy è un esempio di Distribution Skew: la distribuzione dei valori delle feature nei dati di training è diversa da quella nei dati di inferenza (o serving), con il rischio di previsioni di scarsa qualità (esistono altri tipi di skew).
Una pipeline di machine learning non si limita al training: copre l'intero percorso dei dati, dallo storage fino all'inferenza, e aiuta a tracciare metriche utili sull'evoluzione di dati e modello nel tempo.
Come può Dorothy capire se il suo modello ha un problema? Quando conviene aggiornare il modello in produzione? Quanto bene possiamo aspettarci che il modello si comporti in futuro?
Come può aiutare TensorFlow Extended
"Il Mago di Oz è uno solo, per le cose meravigliose che fa!"
TFX semplifica il ragionamento sulla propria pipeline di machine learning in produzione, aiutando a comprendere, validare e monitorare i dati su larga scala. Mette a disposizione meccanismi per rilevare lo skew tra dati di training ed evaluation e tra dati di training e di inferenza. L'architettura è scalabile e garantisce un processo ripetibile e riproducibile. A Dorothy piacerebbe TFX!
Le pipeline in TFX sono costruite a partire da componenti, ovvero passaggi distinti, ciascuno responsabile di un singolo compito. I componenti si compongono attraverso gli artefatti che si scambiano come input e output. Insieme formano un Directed Acyclic Graph (DAG) che descrive le dipendenze della pipeline e che può essere schedulato ed eseguito in modo efficiente da un orchestratore (ne parliamo più avanti).
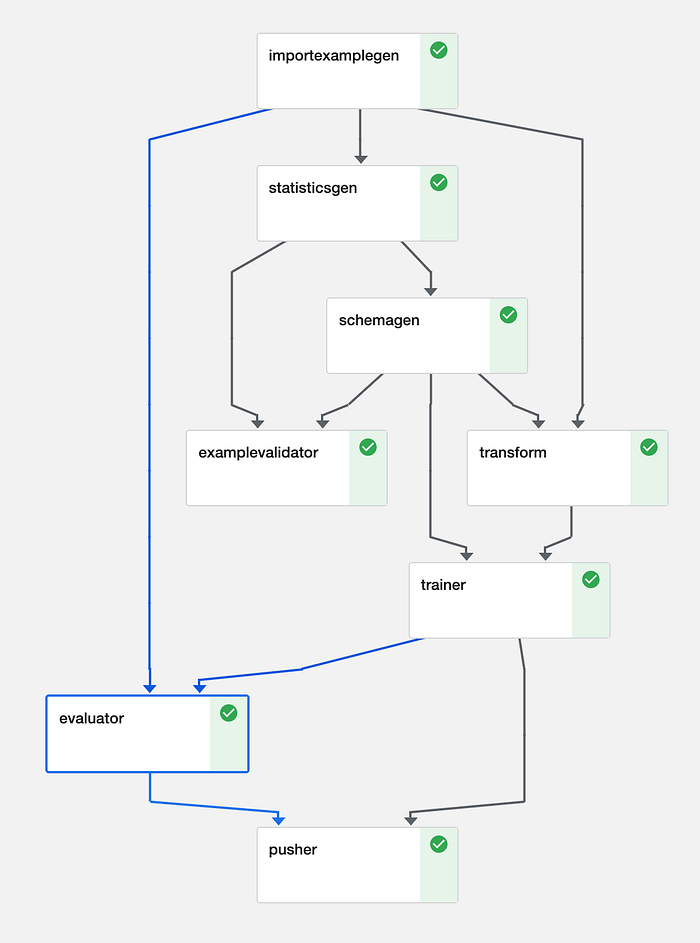
Esempio di DAG per una pipeline di elaborazione immagini (Kubeflow)
Questa è una pipeline classica, ma gli sviluppatori possono usarne anche solo una parte dei componenti, dato che sono componibili.
- Le pipeline iniziano con un ExampleGen: questi componenti recuperano i dati nel loro formato grezzo dallo storage (disco/database). Gli ExampleGen sono legati al formato dei dati (CSV, JSON o TFRecords) e producono i set di training ed evaluation. I componenti successivi useranno questi dati grezzi. ImportExampleGen, ad esempio, può leggere TFRecords dal cloud storage. Se nessuno dei componenti predefiniti soddisfa le tue esigenze, basta implementarne uno personalizzato.
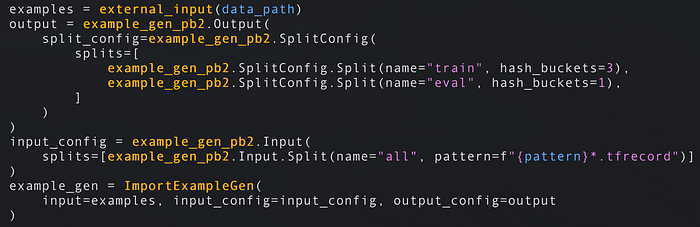
Lettura dei TFRecords da disco/cloud storage e suddivisione dei dati di training 75%/25% tra train ed eval
- I componenti StatisticsGen, SchemaGen ed Example Validator lavorano in sinergia e aiutano a ragionare sui dati di input. StatisticsGen calcola le statistiche delle feature sui dati. SchemaGen specifica i tipi e gli intervalli che i dati possono assumere; può essere generato in automatico, ma definire gli intervalli manualmente rende più semplice individuare gli errori. ExampleValidator rileva dati anomali sfruttando l'output di SchemaGen e StatisticsGen (vedi DAG sopra).

Anomalie rilevate su alcuni dati tabellari
- Il componente Transform esegue la feature engineering necessaria a portare i dati nel formato corretto da utilizzare nel modello, sia in training sia in inferenza. Definendo la trasformazione direttamente nella pipeline si elimina il rischio di regressioni nel codice di training, evaluation o serving. In questo modo si evita di addestrare per errore con feature non disponibili al momento dell'inferenza, ovvero lo Schema Skew.
- Trainer prende i dati trasformati e si occupa di addestrare e valutare un modello. Sono supportati sia gli Estimators, sia, più recentemente, i modelli basati su Keras. I modelli possono essere inizializzati a partire dallo storage, abilitando scenari di warm start o transfer learning. Il supporto alla ricerca degli iperparametri è stato rilasciato di recente ed è implementato tramite il componente Tuner.
- Evaluator e ResolverNode lavorano in tandem per valutare il modello. Evaluator misura le metriche che ci interessa monitorare. ResolverNode fornisce il miglior modello precedente con cui eseguire il set di evaluation: in questo modo confrontiamo vecchio e nuovo ad armi pari. Se il modello appena addestrato supera quello esistente, lo "benediciamo". È possibile specificare anche metriche di performance assolute, ad esempio un'accuratezza minima dell'80%. Questi componenti impediscono che modelli scadenti finiscano in produzione. Possiamo inoltre valutare le metriche su slice dei dati, ad esempio la ROC per fascia oraria, ottenendo indicazioni su dove il modello rende meno e potrebbe essere migliorato.
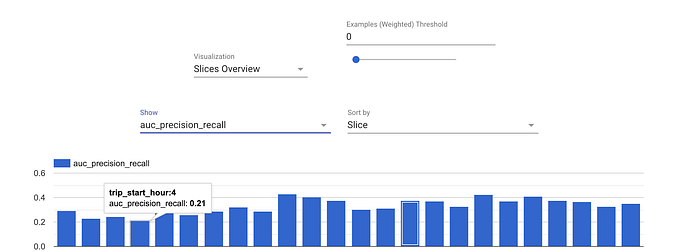
Metriche di evaluation calcolate per fascia oraria
- Pusher salva il modello sullo storage. Se utilizziamo TensorFlowServing, questo passaggio può rilasciare il modello in produzione. Se invece il target è il mobile o il browser, Pusher supporta anche TFLite e TF.js.
Quale orchestratore scegliere?
Non fate caso a quell'uomo dietro la tenda!
TFX offre un livello di astrazione più alto nella costruzione delle pipeline ML. È progettato per essere portabile, quindi non si è vincolati a un singolo ambiente o framework di orchestrazione. Inoltre può girare on-premise o su piattaforme cloud, e nulla vieta che una pipeline venga eseguita su più ambienti cloud diversi. Questa flessibilità permette di scegliere la piattaforma più adatta alle proprie esigenze.
Un DAG TFX viene eseguito su un Orchestratore: al momento TFX ne supporta diversi.
- Kubeflow (AI Platform Pipelines su GCP) gira su Kubernetes, anch'esso ormai onnipresente nei team tech e in produzione. Kubeflow è pensato proprio per eseguire pipeline di Machine Learning; è meno maturo delle altre opzioni e ha appena raggiunto lo stato stabile. Se gestisci più modelli e vuoi poter scalare il cluster in base alle esigenze di training, può essere una buona scelta. E servire il modello su Kubernetes è davvero semplice!
- Apache Beam (Cloud Dataflow su GCP) è ottimo per elaborare dataset in parallelo. TFX usa Beam per l'elaborazione distribuita dei dati e di conseguenza anche altri orchestratori si appoggiano a Beam (incluso Beam stesso, quando lo si usa come orchestratore!). Può essere eseguito anche in locale ed è quindi utile per il debug di una pipeline tramite il Direct Runner.
- Airflow (Cloud Composer su GCP) è molto diffuso nei team di Data Engineering: se hai già un'istanza attiva, eseguire qui la pipeline sarà familiare e richiederà poca infrastruttura aggiuntiva da gestire.
I componenti Trainer e Pusher dispongono di executor che ne permettono l'esecuzione sulla GCP AI Platform, per addestrare e servire il modello in un ambiente serverless.
Considerazioni finali
Toto, ho la sensazione che non siamo più in Kansas.

Foto di Akshay Nanavati su Unsplash
Sono sempre più i team che si trovano a gestire pipeline di Machine Learning in produzione. TFX aiuta ad affrontare alcune delle sfide tipiche che i team ML incontrano nel portare il proprio software in ambiente di produzione. TFX gira su un elenco crescente di orchestratori: con ogni probabilità hai già gran parte dell'infrastruttura necessaria per iniziare a usarlo oggi stesso! Scegliere l'orchestratore giusto permetterà alla tua piattaforma di crescere insieme ai dati e di sostenere la sperimentazione necessaria per costruire modelli davvero utili.