Pipelines de Machine Learning trazem desafios para os times que os constroem e mantêm. Mudanças nos dados ao longo do tempo podem gerar resultados inesperados e bugs em lugares onde você não costuma encontrá-los em outros tipos de software.
Mesmo que o código não tenha mudado, o comportamento do sistema pode mudar — afinal, são os dados usados no treinamento que determinam as previsões do modelo. Se os dados sobre os quais estamos prevendo hoje são diferentes daqueles em que treinamos, aí já não dá para garantir nada!
Entender seus dados e como eles podem mudar ao longo do tempo facilita raciocinar sobre pipelines de machine learning. Times de ML precisam de ferramentas adicionais para manter os modelos atualizados e as previsões relevantes — e o TFX é uma delas.
Vamos passar por alguns desafios comuns na hora de levar ML para produção e ver como o TFX lida com eles, com uma ajudinha de Dorothy, Totó e do Mágico de Oz!
Quando os dados não correspondem à realidade
"Leões? Tigres? E ursos? Ai, meu Deus!"
Dorothy está percorrendo a estrada de tijolos amarelos por uma floresta densa e quer chegar até a Cidade Esmeralda! Ela não está muito preocupada com os leões — são bem covardes. Já tigres e ursos é melhor evitar.
Com uma boa conexão 5G, ela consegue acesso a uma quantidade considerável de dados e treina um classificador para distinguir leões de tigres e ursos. Começamos com um corpus como o de baixo e a ideia é ampliar o dataset com o tempo.
Foto de Mika Brandt no Unsplash
Dorothy manda Totó na frente com uma câmera; conforme ele encontra novos animais pelo caminho, o modelo faz previsões. Durante a noite, enquanto o Espantalho e o Homem de Lata dormem, ela retreina o modelo incluindo os dados recém-coletados. Assim, o classificador vai melhorando, combinando o corpus original com os novos dados. O desempenho do modelo (acurácia, perda etc.) precisa ser estimado a partir de dados representativos do que esperamos ver amanhã, então Dorothy usa as fotos do Totó para avaliar o modelo.
Aí Dorothy nota um problema: as imagens do corpus dela são bem selecionadas, em alta resolução e em orientação paisagem. As imagens do Totó não são tão profissionais e, como a proporção é diferente, ela vai precisar fazer alguns ajustes no modelo.

As imagens do Totó estão em retrato e não têm o mesmo enquadramento das imagens de treino.
O que é um pipeline de machine learning?
"Vou pegar você, minha querida, e seu cachorrinho também!"
No mundo real ;), identificar esse tipo de problema nos dados pode ser complicado. Em geral, coletamos dados ao longo do tempo, e mudanças sutis (ou drifts) na distribuição das features podem fazer com que problemas passem despercebidos e sigam estrada de tijolos amarelos abaixo.
Uma forma de Dorothy perceber que algo pode estar errado é monitorar a distribuição das features no corpus (usado para treino) em comparação com os dados que o Totó coleta (usados para inferência). Acompanhando a proporção das imagens, Dorothy consegue monitorar viés (ou skew) no pipeline. O problema dela é um exemplo de Distribution Skew: a distribuição dos valores das features nos dados de treino é diferente da dos dados de inferência (ou serving), o que pode levar a previsões de baixa qualidade (existem outros tipos de skew).
Um pipeline de machine learning vai além do treinamento: ele cobre toda a jornada dos dados, do armazenamento até a inferência, e ajuda você a acompanhar métricas úteis sobre as mudanças nos dados e no modelo ao longo do tempo.
Como Dorothy pode saber se o modelo de machine learning dela tem algum problema? Como decidir o momento certo de atualizar o modelo em produção? E qual desempenho esperar dele no futuro?
Como o TensorFlow Extended pode ajudar
"O Mágico de Oz é único pelas coisas maravilhosas que faz!"
O TFX facilita raciocinar sobre o seu pipeline de machine learning em produção, ajudando você a entender, validar e monitorar os dados em escala. Ele tem mecanismos para detectar skew entre dados de treino e avaliação, bem como entre dados de treino e inferência. A arquitetura é escalável e garante que o processo seja repetível e reproduzível. A Dorothy ia adorar o TFX!
No TFX, os pipelines são montados a partir de components: etapas distintas, cada uma com uma responsabilidade única. Os components se conectam por meio dos artefatos que trocam como entradas e saídas. Conjuntos de components formam um Directed Acyclic Graph (DAG) que descreve as dependências do pipeline e podem ser agendados e executados de forma eficiente em um orchestrator (mais sobre isso adiante).
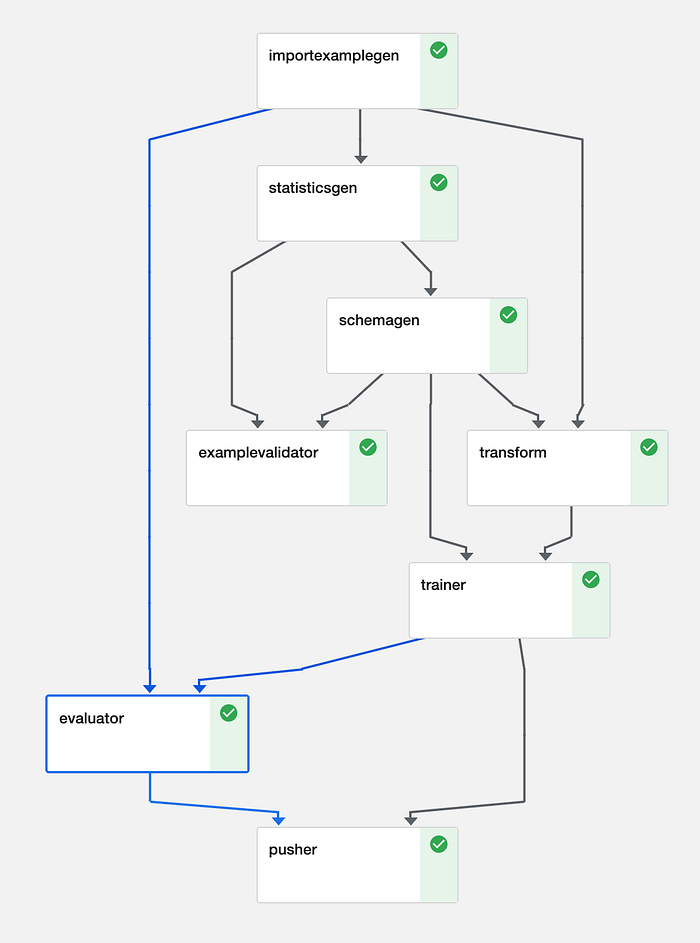
Exemplo de DAG para um pipeline de processamento de imagens (Kubeflow)
Esse é um pipeline clássico, mas, como os components são combináveis, os desenvolvedores podem optar por usar apenas alguns deles.
- Os pipelines começam com um ExampleGen: esses components buscam os dados em formato bruto no armazenamento (disco/banco de dados). Os ExampleGens são acoplados ao formato dos seus dados — CSV, JSON ou TFRecords — e geram os conjuntos de treino e avaliação. Os components seguintes vão usar esses dados brutos. O ImportExampleGen, por exemplo, consegue ler TFRecords do cloud storage. Se nenhum dos components prontos atender às suas necessidades, basta implementar o seu próprio.
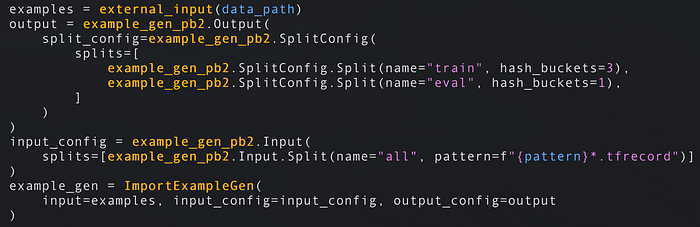
Lê TFRecords do disco/cloud storage e divide os dados de treino em 75%/25% entre treino e avaliação
- Os components StatisticsGen, SchemaGen e Example Validator trabalham juntos para te ajudar a entender os dados de entrada. O StatisticsGen calcula estatísticas das features. O SchemaGen especifica os tipos e os intervalos que os dados podem assumir; isso pode ser inferido automaticamente, mas definir os intervalos manualmente costuma facilitar a detecção de erros. Já o ExampleValidator detecta dados anômalos a partir das saídas do SchemaGen e do StatisticsGen (veja o DAG acima).

Anomalias detectadas em dados tabulares
- O component Transform faz a engenharia de features necessária para deixar os dados no formato correto para o modelo usar durante o treinamento e a inferência. Ao especificar a transformação no pipeline, garantimos que não haja regressões no código de treino, avaliação ou serving. Isso evita que você acabe treinando, sem querer, com features que não estão disponíveis no momento da inferência — o famoso Schema Skew.
- O Trainer pega os dados transformados, treina e avalia um modelo. Ele suporta tanto Estimators quanto, mais recentemente, modelos baseados em Keras. Os modelos podem ser inicializados a partir do armazenamento, possibilitando cenários de warm start ou transfer learning. O suporte a busca de hiperparâmetros foi lançado recentemente e é implementado por meio de um component Tuner.
- O Evaluator e o ResolverNode trabalham em conjunto para avaliar o modelo. O Evaluator analisa as métricas que queremos acompanhar. O ResolverNode disponibiliza o melhor modelo anterior para rodar contra o conjunto de avaliação, garantindo que a comparação entre o antigo e o novo seja feita em condições iguais. Se o modelo recém-treinado superar o atual, "abençoamos" o novo modelo. Também é possível especificar métricas absolutas de desempenho — por exemplo, a acurácia precisa ultrapassar 80%. Esses components evitam que modelos de baixa qualidade cheguem à produção. Também dá para avaliar métricas em fatias dos dados, como ROC por hora do dia, o que traz insights sobre onde o modelo pode estar deixando a desejar e onde há espaço para melhorias.
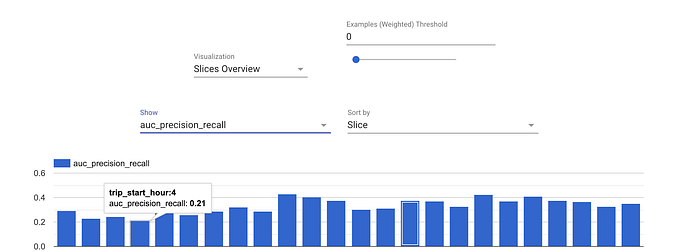
Métricas de avaliação calculadas por hora do dia
- O Pusher persiste o modelo no armazenamento. Se você estiver usando o TensorFlowServing, essa etapa pode liberar o modelo para produção. Caso o alvo seja mobile ou o navegador, o Pusher também suporta TFLite e TF.js.
Qual orchestrator devo usar?
Não dê atenção àquele homem atrás da cortina!
O TFX oferece um nível mais alto de abstração na construção de pipelines de ML. Ele foi projetado para ser portátil, ou seja, você não fica preso a um único ambiente ou framework de orquestração. Além disso, dá para rodá-lo on-premise ou em plataformas de nuvem — é até possível um pipeline rodar em múltiplos ambientes de nuvem. Essa flexibilidade permite escolher a plataforma que melhor se encaixa nas suas necessidades.
Um DAG do TFX é executado em um Orchestrator e, atualmente, o TFX suporta alguns deles.
- Kubeflow (AI Platform Pipelines no GCP) roda em Kubernetes, que também é onipresente em times de tecnologia e em produção. O Kubeflow foi projetado para executar pipelines de Machine Learning; é menos maduro que as outras opções e acabou de chegar ao status estável. Se você gerencia múltiplos modelos e quer poder escalar o cluster para atender às demandas de treino, pode ser uma boa pedida. E servir seu modelo no Kubernetes é moleza!
- Apache Beam (Cloud Dataflow no GCP) é ótimo para processar datasets em paralelo. O TFX usa o Beam para processamento distribuído de dados, e por isso outros orchestrators também usam o Beam (incluindo o próprio Beam, quando você o usa como orchestrator!). Ele também roda localmente, o que é útil para depurar um pipeline com o Direct Runner.
- Airflow (Cloud Composer no GCP) é popular em times de Data Engineering. Se você já tem uma instância em pleno funcionamento, rodar seu pipeline ali vai parecer familiar e exigir pouca infraestrutura adicional para gerenciar.
Os components Trainer e Pusher têm executors que permitem executá-los na GCP AI platform, possibilitando treinar e servir o seu modelo em um ambiente serverless.
Considerações finais
Totó, tenho a impressão de que não estamos mais no Kansas.

Foto de Akshay Nanavati no Unsplash
Cada vez mais times são responsáveis por gerenciar pipelines de Machine Learning em produção. O TFX ajuda a lidar com alguns dos desafios bem específicos que esses times enfrentam ao levar seu software para o ambiente de produção. Ele roda em uma lista crescente de orchestrators, e é bem provável que você já tenha boa parte da infraestrutura necessária para começar a usá-lo hoje mesmo! Escolher o orchestrator certo vai permitir que sua plataforma cresça junto com seus dados e sustente a experimentação necessária para construir modelos realmente úteis.