Assembler les pièces de votre propre pipeline ML
La plupart des tutoriels que je consulte ne couvrent qu'une partie d'une solution complète et fonctionnelle. Certains présentent un Notebook (nous y reviendrons) avec l'entraînement, la prédiction et l'analyse d'un modèle. D'autres montrent comment créer une API pour exposer un modèle. J'ai voulu adopter une approche différente et montrer comment concevoir une application de bout en bout, avec l'application web, l'API et le ré-entraînement automatique du modèle déclenché par les interactions utilisateur.
Prérequis : vidéo de démonstration
Lisez la partie 1 de cette série pour visionner la démo de quatre minutes de l'application en fonctionnement, ainsi que le contexte sur les concepts et la terminologie du machine learning. Nous allons à présent passer en revue les étapes suivies pour concevoir et créer la démo du pipeline ML, et les choix faits en chemin.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Conception générale de la solution
Je suis parti d'exigences non fonctionnelles précises portant sur l'efficacité des ressources, la scalabilité et des temps de réponse inférieurs à la seconde. Beaucoup de modèles de prédiction peuvent très bien être servis par un simple programme API. Ici, en revanche, je vais montrer comment concevoir une architecture serverless distribuée à partir de services de cloud public, et pourquoi opter pour ce type de design.
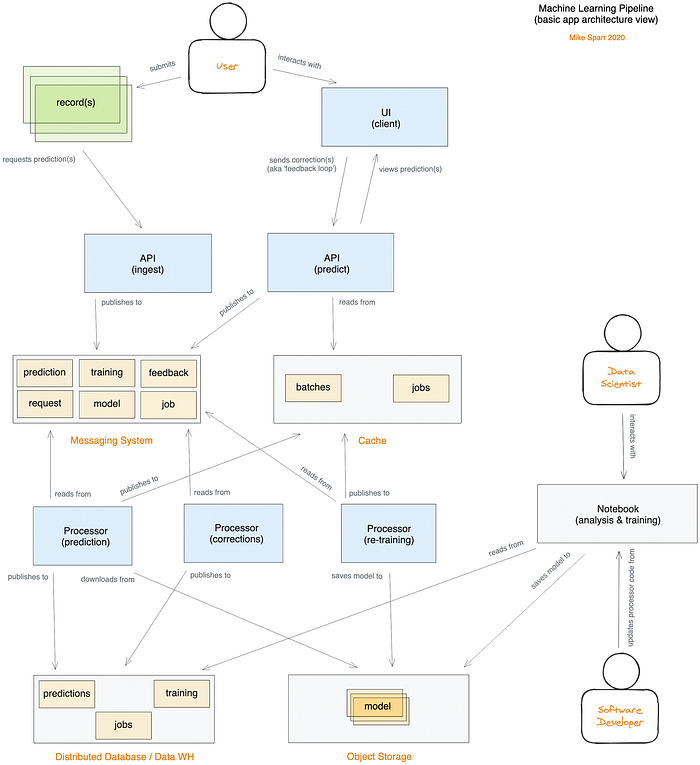
Architecture sur mesure d'un pipeline ML (application serverless distribuée hébergée sur cloud public)
Si vous êtes data scientist avec un peu de bagage logiciel, certains aspects vous sembleront sans doute inhabituels — petite revanche ! En parcourant les dépôts de code source et en confrontant le code au Notebook, j'espère que les pièces du puzzle s'emboîteront et que tout cela vous sera utile.
Commencer par un plan
Sans plan, on perd vite beaucoup de temps. Comme assembler des planches au hasard en espérant obtenir un bâtiment : il est bien plus efficace de dessiner les plans, d'acheter les matériaux, puis de monter l'ensemble. La conception logicielle ne fonctionne pas autrement, mais selon le niveau d'expérience, le type de planification varie.
Architecture, UI et conception de l'API
Pour prouver que je n'ai pas sauté cette étape, voici une photo de quelques-uns de mes croquis réalisés pendant les vacances de Thanksgiving, qui ont donné le schéma d'architecture présenté plus haut. J'ai ensuite construit l'application de démo sur mon temps libre durant le mois de décembre 2020.
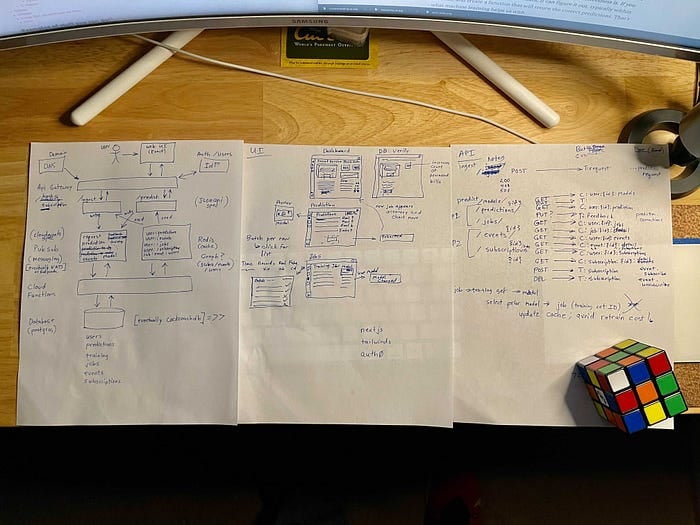
Maquettes initiales de l'architecture, de l'UI et des interfaces API pour l'application de démo IA
Choisir le bon algorithme de machine learning
Avec l'aide d'un collègue de DoiT International (notre équipe compte de nombreux experts IA et Kaggle competition masters), j'ai opté pour un classifieur binaire reposant sur un algorithme linéaire SVM (Support Vector Machine) pour entraîner mon modèle. La vidéo ci-dessous explique de quoi il s'agit ; pas d'inquiétude si cela vous dépasse pour l'instant — comprendre le fonctionnement précis des algorithmes n'est pas, à mon sens, le plus important au départ.
Si vos données tombent d'un côté de la ligne, c'est mauvais ; de l'autre, c'est bon. Voilà l'idée de base.
Plutôt que de partir de mon vrai projet, j'ai déniché un jeu de données public pour bâtir l'ensemble de la démo. Je pourrai par la suite remplacer les features par celles de mon projet, ajouter la sécurité et les autres briques nécessaires à une véritable startup.
Stack technologique retenue
Ayant occupé des postes seniors dans plusieurs entreprises, je n'avais pas codé activement de nouveaux produits depuis un moment. J'ai d'abord passé deux jours pendant les vacances de Thanksgiving à me remettre à niveau sur les outils et frameworks actuels avant d'arrêter ma stack. Pour rester simple, nous laissons de côté l'automatisation DevOps, mais j'y reviendrai peut-être dans un prochain article.
- Couche UI — conteneurs NextJS/React + Chakra UI servis par Cloud Run
- Couche API — conteneurs Golang + Go-Chi servis par Cloud Run
- Couche messaging — Cloud Pub/Sub
- Couche cache — Cloud Memorystore (Redis)
- Couche traitement — Cloud Functions Python avec déclencheur Pub/Sub
- Couche base de données — Cloud SQL (Postgres)
- Couche stockage — Cloud Storage Buckets
Pour protéger les secrets — mots de passe de base de données utilisés par les fonctions, par exemple —, l'application de démo s'appuie sur Cloud Secret Manager. D'ordinaire, je conçois mes solutions de manière agnostique vis-à-vis des fournisseurs, mais la plupart des solutions managées de Google Cloud Platform reposent sur des produits open source, ce qui en facilite le remplacement ultérieur par de l'OSS. Multiplier les interfaces dans mon code aide aussi à la substitution de services.
" Montrez-moi le code "

Il a vraiment dit show me the code et I love data science
Code source et documentation
Les dépôts GitHub suivants contiennent le code fonctionnel de l'application de démo présentée dans la partie 1 de cette série. Chaque dépôt comprend une démo et une documentation expliquant la place du composant dans l'architecture globale, ainsi que la marche à suivre pour l'installer et l'exécuter.
- Web UI — interface conviviale pour visualiser le fonctionnement du système
- Ingest API — c'est ici que l'on soumet les lots d'enregistrements à prédire
- Predict API — sert les prédictions par lots et reçoit les corrections des utilisateurs
- Processors — fonctions cloud asynchrones qui assurent les tâches de prédiction, d'entraînement et de persistance des données (inclut également le Jupyter Notebook d'origine, le modèle entraîné, le jeu de données et les fichiers de schéma de base de données)
L'étape suivante (passer de la démo à une vraie application) consisterait à durcir le code, ajouter des tests automatisés et la pagination. Je provisionnerais ensuite l'infrastructure avec Terraform, j'affinerais le pipeline CI/CD et je placerais une API Gateway en frontal pour centraliser l'authentification, la journalisation, le tracing et le rate-limiting. Si je décide de publier ces étapes en open source, j'ajouterai une partie 3 à cette série. ;-)
Comparaison avec les solutions commerciales
En parcourant cette série d'articles et les dépôts GitHub ci-dessus, j'espère que vous reconnaîtrez peu à peu les éléments et termes qui semblaient au départ insurmontables. Bon test : examinez ce schéma de Google qui décrit leur solution managée AI Platform. En regardant les blocs, combien de termes vous parlent désormais ?
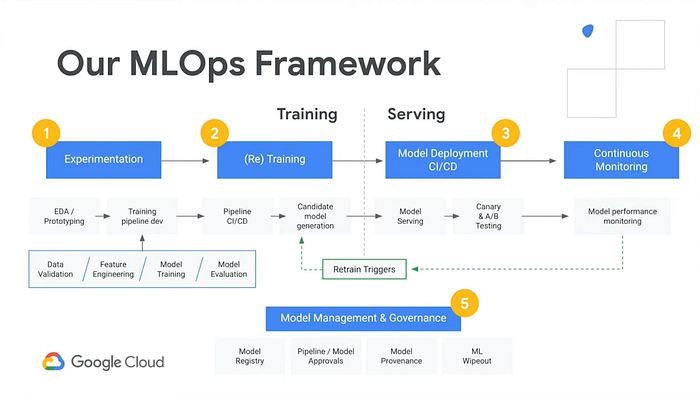
Dans le dépôt ai-demo-functions de l'application de démo, vous retrouverez des fonctionnalités similaires :
- Experimentation — voir notebook.ipynb
- (Re) Training — voir /training/main.py
- Model Deployment et Model Serving — voir /training/main.py , /prediction/main.py et /prediction-to-cache/main.py
- Continuous Monitoring et Retrain Triggers — voir /feedback-to-db/main.py et /feedback-to-training/main.py
- Model Management & Governance — voir /training-to-cache/main.py et training-to-db/main.py
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Performance
La performance est souvent un facteur clé de différenciation entre les solutions du marché. De nombreux choix de conception ont été dictés par des objectifs de performance.
Python ou pas ?
Dans le Jupyter Notebook qui m'a servi aux premières expérimentations, j'ai mesuré la durée de chaque opération afin de m'assurer que le langage Python et les bibliothèques retenues répondraient à mes besoins.
L'une de ces expériences portait sur le service de prédiction lui-même. J'ai chargé les données saisies par l'utilisateur dans une structure Pandas DataFrame, lancé ma prédiction, et celle-ci a pris environ 6 millisecondes. Heureusement, un collègue m'a soufflé qu'utiliser un tableau Numpy pourrait être plus rapide — et de fait, le temps de prédiction est tombé à 2 millisecondes. Un beau gain.
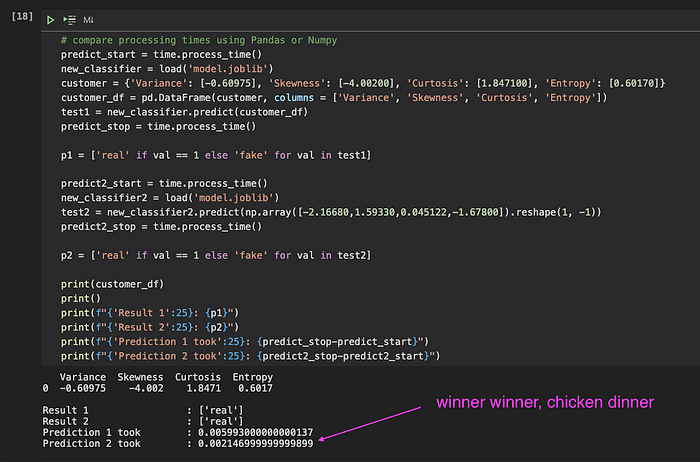
Comparaison des temps de traitement (et de la consommation mémoire) entre structures de données
Fonctions serverless ou pas ?
Autre point d'attention : les temps de démarrage à froid des fonctions serverless et leur vitesse de traitement. Après quelques fonctions de test, j'ai trouvé un moyen de précharger les bibliothèques et de réduire drastiquement le temps d'exécution de la fonction de prédiction, à environ 8 millisecondes. Tous les tests indiquaient que Python et Google Cloud Functions répondraient à mes besoins.
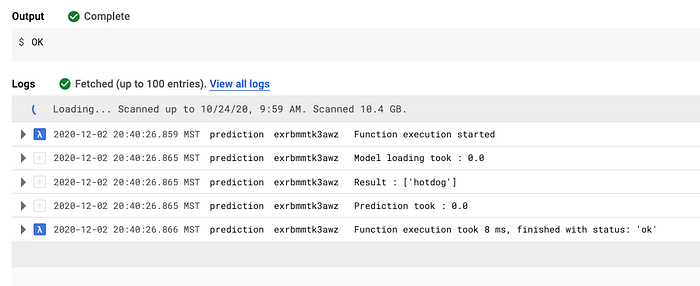
Premiers tests sur le temps d'exécution des prédictions Cloud Function (8 millisecondes)
Avec des durées d'entraînement ou un jeu de données différents, j'aurais pu faire d'autres choix, compte tenu des limites fixes de timeout et de mémoire.
- Cloud Functions — 4 Go de mémoire max ; temps d'exécution max de 9 min
- Cloud Run — 8 Go de mémoire max ; exécution max de 15 min (60 min en bêta)
- Cloud Run (Anthos) — davantage de mémoire ; exécution max de 24 h (gke 16+)
- pour les jobs plus longs, envisagez GKE ou l'exécution de conteneurs sur VM
Astuces de pro
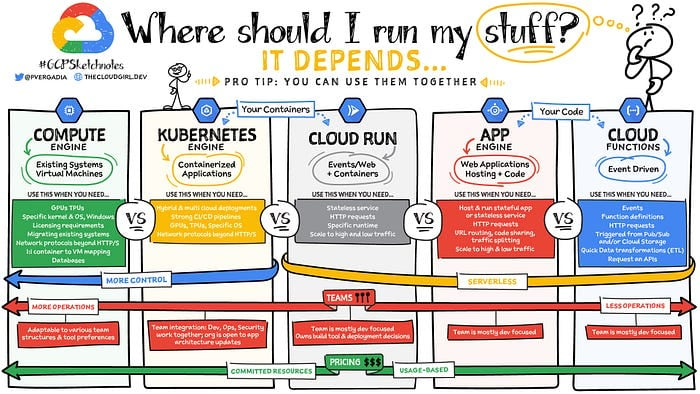
Source : Google (Priyanka Avergadia)
Conteneurs pour l'API ou pas ?
J'ai retenu Golang et Google Cloud Run pour la couche API. Je voulais construire quelque chose en Golang : c'est très rapide, hautement concurrent et peu gourmand en ressources, à l'image de NodeJS. Autre atout : la taille réduite des images Docker, qui permet un autoscaling rapide sous charge. Enfin, un langage fortement typé limite les entrées indésirables et offre une couche de défense avant de transmettre les données aux processeurs Python typés dynamiquement.
Avec Apache Bench et en jouant sur la compression gzip, j'ai pu réduire le transfert réseau de 82 % et atteindre une moyenne de 5,295 millisecondes par requête depuis mon réseau domestique au Montana, aux États-Unis, vers les serveurs us-central1 de Google. Un autre collègue m'a recommandé Snappy, qui peut réduire les coûts CPU tout en offrant une optimisation réseau substantielle (à tester pour trouver la meilleure combinaison).
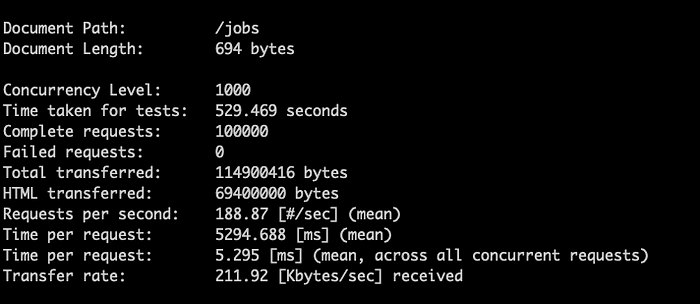
Benchmark des performances de l'API avec et sans compression
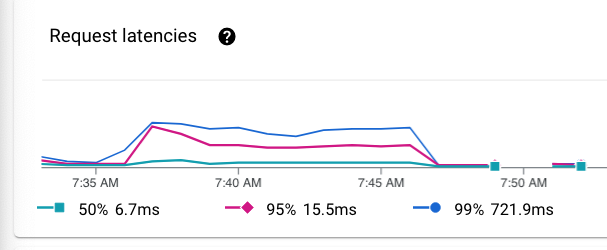
Analyse de la surcharge de l'infrastructure cloud et des latences de requêtes
React ou pas ? Dans plusieurs entreprises, nous avons utilisé React pour la couche UI web ; ailleurs, c'était Angular. Je suis VueJS et d'autres frameworks de près, mais j'ai retenu React parce que j'ai plus d'expérience avec et que c'est ce que nous utilisons dans mon entreprise actuelle. Par le passé, je bootstrappais mes applications React avec create-react-app, mais j'ai vu d'excellents retours sur l'amélioration des performances SSR et la simplicité du routing avec NextJS.
Material UI ou pas ?
J'ai consacré quelques jours à tester des frameworks CSS comme Material UI, Tailwinds, et finalement Chakra UI. J'avais déjà utilisé Semantic UI, mais je voulais quelque chose de plus moderne en matière de stylisation. Chakra l'a emporté (pour l'instant) — c'est donc avec lui que cette démo est construite.
Efficacité et coût maîtrisé
Autre avantage concurrentiel possible : l'efficacité côté coûts. Elle permet à une entreprise d'être plus compétitive que ses pairs tout en préservant des marges plus élevées. Comme je conseille souvent d'autres acteurs sur l'optimisation de leur infrastructure cloud public, j'ai voulu me prêter à l'exercice et voir avec quelle efficacité je pouvais faire tourner une stack applicative IA complète, en équilibrant les besoins humains et techniques.
Après un mois de construction et d'exploitation de cette stack, j'ai le plaisir d'annoncer que cet environnement unique, sous charge minimale, a coûté moins de 80 $. Bien sûr, multiplier les environnements et augmenter l'usage feront grimper les coûts dans le temps. L'architecture serverless et d'autres choix — données compressées, conception sérialisée des données (tableaux plutôt que hashs pour éliminer la redondance) — devraient maintenir des coûts opérationnels très bas.
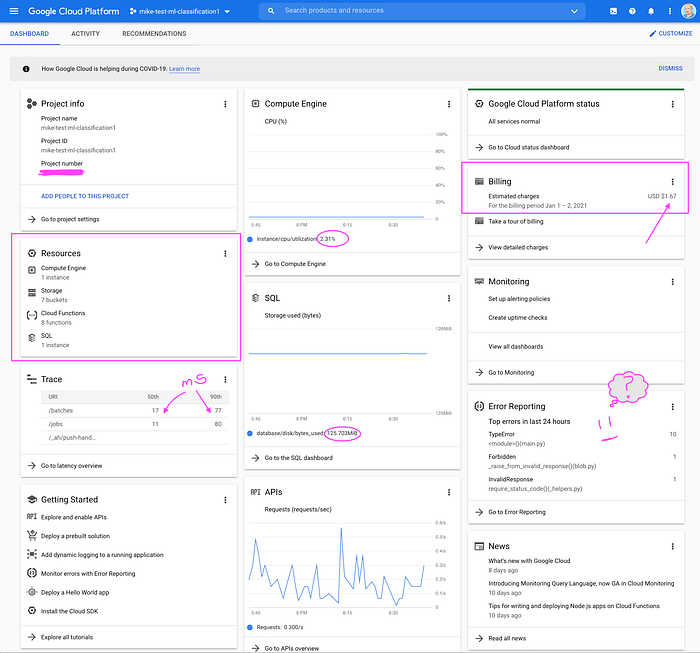
Un environnement unique faisant tourner une démo à très faible coût (jusqu'ici)
Prochaines étapes
Comme je l'évoquais dans le premier article, nous avons laissé de côté beaucoup de contenus habituellement abordés dans les tutoriels ML. Cette démo s'appuie sur de l'apprentissage supervisé et crée un classifieur binaire, mais nous avons tous entendu parler des réseaux de neurones et autres formes d'apprentissage différentes.
J'ai sciemment écarté ce bruit pour permettre, dans un premier temps, de se concentrer sur la compréhension d'ensemble. Pour poursuivre votre parcours en IA et ML, voici quelques ressources utiles afin de mieux cerner l'éventail de problèmes et de solutions que ces disciplines peuvent traiter :
- Elements of AI (cours en ligne gratuit de l'Université d'Helsinki)
- Schéma général des algorithmes (différents types d'outils et de problèmes)
- Choisir le bon algorithme (bons schémas illustrant les différents types)
- Comparatif des plateformes
Il existe des solutions commerciales telles que Databricks, AI Platform, Sagemaker, ou des solutions open source comme ML Flow et Kubeflow. Chacune a ses avantages et ses inconvénients, plus des coûts supplémentaires, des points de défaillance et une courbe d'apprentissage propre.
Pour réellement comprendre comment construire un pipeline ML capable de servir et de ré-entraîner des prédictions, j'ai estimé qu'il valait mieux bâtir les composants soi-même (un peu comme apprendre les maths à la main avant de s'appuyer sur une calculatrice). J'espère que ces enseignements vous seront utiles — ils ne représentent qu'une petite portion de votre parcours global en IA.
J'ai la chance de travailler avec une équipe de data scientists experts ; à mesure que j'apprends, je continuerai à transmettre via d'autres articles comme celui-ci. Si vous souhaitez rejoindre notre équipe chez DoiT, consultez notre page carrières ou contactez-moi par message sur Twitter ou LinkedIn.