Encaixando as peças do seu próprio pipeline de ML
A maioria dos tutoriais que encontro cobre só uma parte da solução completa. Alguns mostram um Notebook (já chegamos lá) com treinamento, predição e análise do modelo. Outros ensinam a criar uma API para servir um modelo. Resolvi seguir um caminho diferente e mostrar como projetar uma aplicação ponta a ponta, com web app, API e re-treinamento automático do modelo a partir das interações dos usuários.
Pré-requisito: vídeo de demonstração
Leia a parte 1 desta série para assistir à demo de quatro minutos da aplicação rodando e ver o contexto sobre conceitos e terminologia de machine learning. Na sequência, vamos explorar os passos que segui para projetar e construir o pipeline de ML da demo, além das decisões tomadas no caminho.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Visão geral da arquitetura da solução
Comecei com requisitos não funcionais bem definidos: eficiência de recursos, escalabilidade e desempenho abaixo de um segundo. Muitos modelos de predição podem ser servidos por um simples programa de API e funcionar muito bem. Aqui, porém, vou mostrar como projetar uma arquitetura serverless distribuída usando serviços de nuvem pública — e por que alguém escolheria esse caminho.
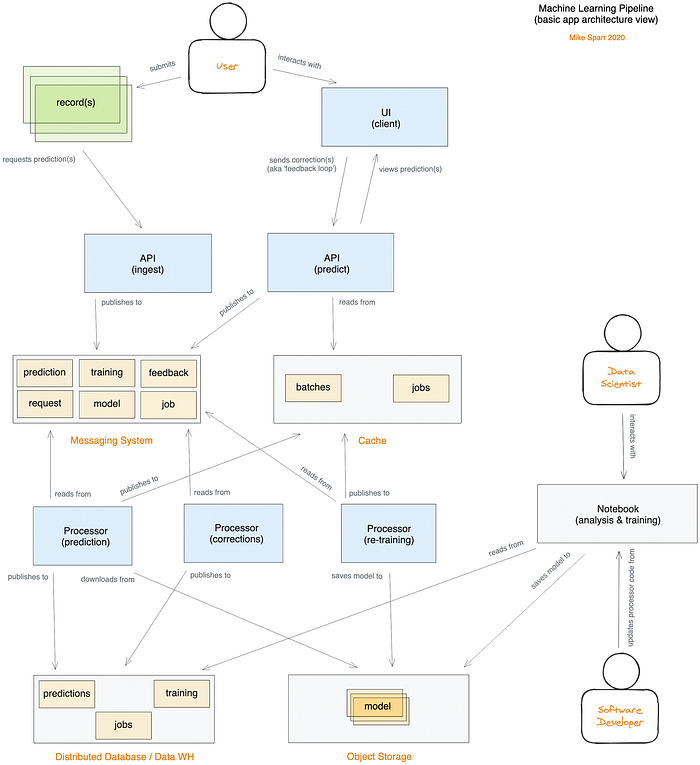
Arquitetura customizada de pipeline de ML (aplicação serverless distribuída hospedada em nuvem pública)
Se você é cientista de dados com pouca bagagem em software, parte disso pode soar estranho — pequenas vinganças, hehe! Conforme explorar os repositórios de código-fonte e ver o código real conectado ao Notebook, espero que as peças do quebra-cabeça se encaixem e o material seja útil.
Comece com um plano
Sem um plano, dá para perder muito tempo. É como pregar tábuas torcendo para que, no fim, surja um prédio: muito mais eficiente é desenhar a planta, comprar o material e só depois montar. Projetar software não é diferente, mas níveis de experiência distintos exigem tipos de planejamento distintos.
Design de arquitetura, UI e API
Só para provar que não pulei essa etapa, abaixo está uma foto de alguns rascunhos que fiz durante o feriado de Ação de Graças e que deram origem ao diagrama de arquitetura mostrado acima. Depois, construí a aplicação demo no tempo livre ao longo de dezembro de 2020.
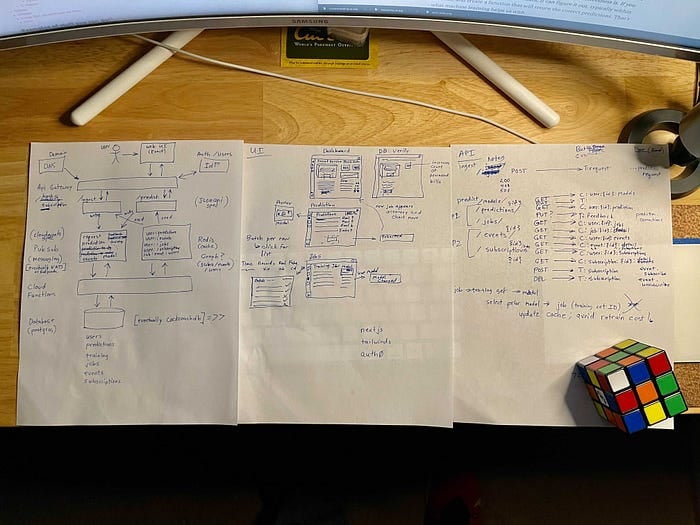
Mockups iniciais de arquitetura, UI e interfaces de API para a aplicação demo de IA
Escolhendo o algoritmo de machine learning certo
Com a ajuda de um colega da DoiT International (nosso time tem vários gurus de IA e mestres de competições do Kaggle), optei por um classificador binário usando o algoritmo linear Support Vector Machine (SVM) para treinar o modelo. O vídeo abaixo explica o que é, mas não se preocupe se parecer complicado agora — entender como os algoritmos funcionam não é o mais importante no início, na minha opinião.
Se seus dados caem de um lado da linha, são "ruins"; do outro lado, são "bons". Esse é o básico.
Em vez de usar meu projeto real, por enquanto encontrei um dataset público para construir tudo nesta demo. Mais adiante, posso trocar as features pelas do meu projeto, adicionar segurança e outros componentes necessários para uma startup de verdade.
Stack tecnológica escolhida
Como ocupei cargos seniores em várias empresas, fazia tempo que eu não codificava ativamente novos produtos. Passei alguns dias durante o feriado de Ação de Graças me reciclando nas ferramentas e frameworks atuais até definir minha "stack". Para simplificar, deixamos de fora a automação de DevOps, mas posso abordar isso em um post futuro.
- Camada de UI — containers NextJS/React + Chakra UI servidos pelo Cloud Run
- Camada de API — containers Golang + Go-Chi servidos pelo Cloud Run
- Camada de mensageria — Cloud Pub/Sub
- Camada de cache — Cloud Memorystore (Redis)
- Camada de processamento — Python Cloud Functions com gatilho via Pub/Sub
- Camada de banco de dados — Cloud SQL (Postgres)
- Camada de armazenamento — Cloud Storage Buckets
Para proteger segredos como senhas de banco de dados das functions, a aplicação demo usa o Cloud Secret Manager. Costumo projetar as coisas para serem agnósticas em relação ao fornecedor, mas a maioria das soluções gerenciadas do Google Cloud Platform é baseada em produtos open-source, o que facilita "trocá-las" por OSS depois. Adicionar mais interfaces no código também simplifica a substituição de serviços.
"Me mostra o código"

Ele realmente disse "me mostra o código" e "adoro ciência de dados"
Código-fonte e documentação
Os repositórios do GitHub a seguir trazem o código funcional da aplicação demo que você viu na parte 1 desta série. Cada repositório inclui uma demo e a documentação sobre onde aquele componente se encaixa na arquitetura geral, além de explicar como instalar e executar tudo por conta própria.
- Web UI — interface amigável para visualizar como o sistema funciona
- Ingest API — onde enviamos lotes de registros para os quais queremos predições
- Predict API — entrega predições em lote e recebe correções dos usuários
- Processors — cloud functions assíncronas que executam tarefas de predição, treinamento e persistência de dados (também inclui o Jupyter Notebook original, o modelo treinado, o dataset e os arquivos de schema do banco)
Meu próximo passo (sair da aplicação demo para uma de verdade) seria refinar o código (deixá-lo mais defensivo), adicionar testes automatizados e paginação. Depois, provisionaria a infraestrutura com Terraform, refinaria o pipeline de CI/CD e colocaria tudo atrás de um API Gateway para centralizar autenticação, logging, tracing e rate-limiting. Se eu decidir abrir o código dessas etapas, atualizo a série com uma "parte 3". ;-)
Comparação com soluções comerciais
Conforme você avança nesta série e nos repositórios do GitHub acima, espero que comece a reconhecer as peças e os termos que pareciam complicados no começo. Um ótimo teste é olhar este diagrama do Google que descreve a solução gerenciada AI Platform. Olhando as caixas, quantos termos agora fazem sentido para você?
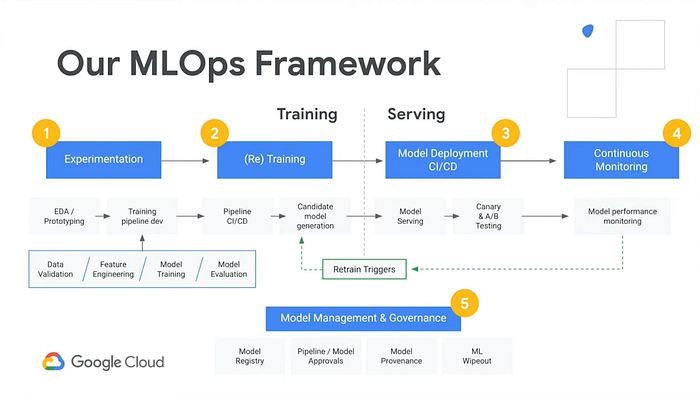
Ao explorar o repositório da aplicação demo ai-demo-functions, você vai encontrar funcionalidades semelhantes:
- "Experimentation" — veja notebook.ipynb
- "(Re) Training" — veja /training/main.py
- "Model Deployment" e "Model Serving" — veja /training/main.py , /prediction/main.py e /prediction-to-cache/main.py
- "Continuous Monitoring" e "Retrain Triggers" — veja /feedback-to-db/main.py e /feedback-to-training/main.py
- "Model Management & Governance" — veja /training-to-cache/main.py e training-to-db/main.py
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Performance
Um dos principais diferenciais entre as soluções do mercado costuma ser a performance. Várias decisões de design foram guiadas por objetivos de desempenho.
Python ou não?
No Jupyter Notebook em que rodei os experimentos iniciais, medi o tempo de cada operação para garantir que o Python e as bibliotecas escolhidas atenderiam às minhas necessidades.
Um desses experimentos foi o serviço de predição em si. Carreguei os dados de entrada do usuário em um Pandas DataFrame e rodei a predição, que levou cerca de 6 milissegundos. Por sorte, um colega me deu a dica de usar um array Numpy: pode ser mais rápido — e, de fato, derrubou o tempo de predição para 2 milissegundos. Vitória!
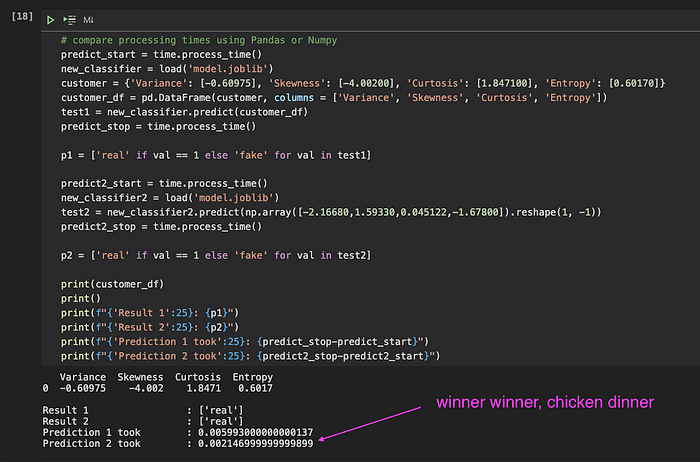
Comparativo de tempo de processamento (e consumo de memória) entre estruturas de dados
Funções serverless ou não?
Outra preocupação minha era o tempo de cold start de funções serverless e a velocidade de processamento. Depois de testar algumas funções, descobri uma forma de pré-carregar bibliotecas e reduzir drasticamente o tempo de execução da função de predição para cerca de 8 milissegundos. Todos os testes mostraram que Python e Google Cloud Functions atenderiam às minhas necessidades.
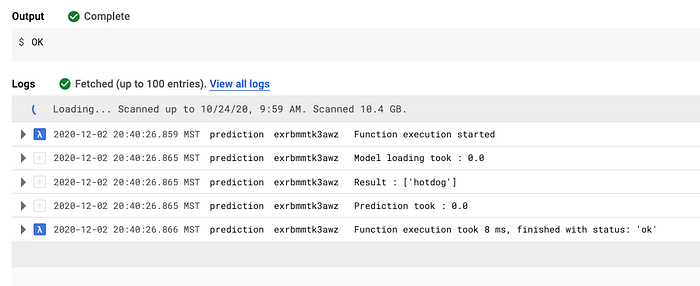
Testes iniciais do tempo de execução de predição em Cloud Function (8 milissegundos)
Se os tempos de treinamento ou o dataset fossem diferentes, eu poderia tomar outras decisões, dados os timeouts fixos e os limites de memória.
- Cloud Functions — máx. 4Gb de memória; máx. 9m de execução
- Cloud Run — máx. 8Gb de memória; máx. 15m de execução (60m em beta)
- Cloud Run (Anthos) — mais memória; máx. 24h de execução (gke 16+)
- para jobs mais longos, considere GKE ou rodar containers em VMs
Dicas de quem é da área
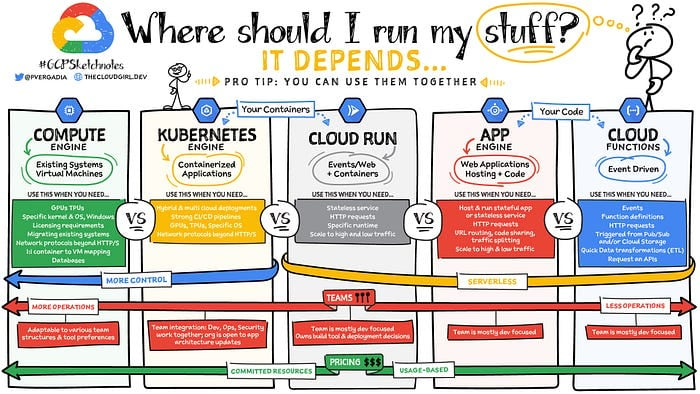
Fonte: Google (Priyanka Avergadia)
Containers para a API ou não?
Optei por Golang e Google Cloud Run para a camada de API. Eu queria construir algo em Golang, que é muito rápido e oferece alta concorrência usando recursos mínimos, parecido com o NodeJS. Além disso, o tamanho da imagem Docker é pequeno, então sob carga ela faz autoscale rapidamente. Por fim, uma linguagem fortemente tipada ajuda a barrar o "lixo na entrada", criando uma camada de defesa antes de passar os dados para os processadores Python, de tipagem dinâmica.
Usando o Apache Bench e brincando com compressão gzip, consegui reduzir a transferência de rede em 82% e ter uma média de 5,295 milissegundos por requisição saindo da minha rede doméstica em Montana, EUA, até os servidores us-central1 do Google. Outro colega recomendou o Snappy, que pode reduzir o custo de CPU mantendo uma boa otimização de rede (vale o tentativa e erro para achar a melhor combinação).
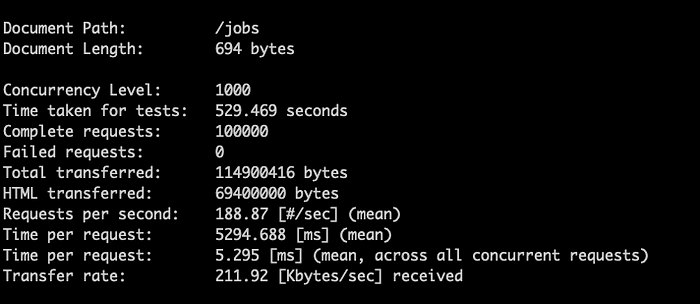
Benchmark de performance da API com e sem compressão
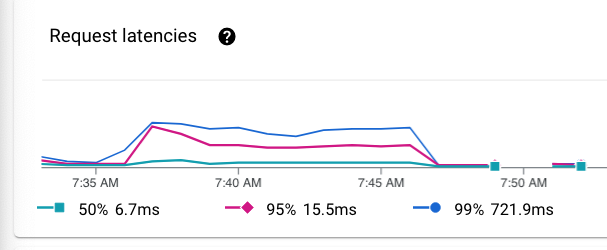
Análise do overhead da infraestrutura de nuvem e das latências de requisição
React ou não? Em algumas empresas usamos a biblioteca React para a camada de UI web; em outras, Angular. Acompanho VueJS e outros, mas escolhi React porque tenho mais experiência pessoal com ele e é o que usamos na minha empresa atual. No passado, eu inicializava apps em React com o create-react-app, mas vi relatos impressionantes de melhorias de performance em SSR e simplicidade de roteamento usando NextJS.
Material UI ou não?
Passei alguns dias testando frameworks de CSS como Material UI, Tailwinds e, por fim, Chakra UI. No passado, usei Semantic UI, mas queria algo com técnicas de estilização mais novas. O Chakra me conquistou (por enquanto), e é com ele que esta demo foi construída.
Eficiência e custo acessível
Outro diferencial competitivo que uma empresa pode ter é a eficiência de custos. Isso permite ser mais competitiva e, ao mesmo tempo, ter margens de lucro maiores. Como costumo orientar outras pessoas sobre como otimizar a infraestrutura de nuvem pública, achei que valia pôr isso à prova e ver o quão eficiente eu conseguiria rodar uma stack completa de aplicação de IA, equilibrando necessidades humanas e tecnológicas.
Depois de construir e rodar essa stack por um mês, fico feliz em compartilhar que esse ambiente único, com carga mínima, custou menos de US$ 80. É claro que vários ambientes e maior uso vão aumentar o custo ao longo do tempo. A arquitetura serverless e outras decisões — como dados comprimidos e até o design de dados serializados (arrays em vez de hashes para eliminar redundância) — devem manter os custos operacionais bem baixos.
Ambiente único rodando uma demo a um custo bem baixo (até agora)
Próximos passos
Como mencionei no primeiro artigo, pulamos vários assuntos que costumam aparecer em tutoriais de ML. Esta demo usa "aprendizado supervisionado" e cria um "classificador binário", mas todo mundo já ouviu falar de redes neurais etc., que são tipos diferentes de aprendizado.
Eliminei esse "ruído" de propósito para permitir um foco inicial na compreensão geral. Conforme você continua sua jornada em IA e ML, aqui vão alguns recursos úteis para explorar e entender melhor a gama mais ampla de problemas e soluções que IA e ML podem resolver:
- Elements of AI (curso online gratuito da Universidade de Helsinki)
- Diagrama geral de algoritmos (diferentes tipos de ferramentas e problemas)
- Como escolher o algoritmo certo (bons diagramas dos diferentes tipos)
- Comparação de plataformas
Existem soluções comerciais como Databricks, AI Platform e Sagemaker, ou alternativas open-source como ML Flow e Kubeflow. Cada uma tem prós e contras, além de custo adicional, pontos de falha e curvas de aprendizado.
Cheguei à conclusão de que, para entender de verdade como construir um pipeline de ML que serve e re-treina predições, o melhor é construir os componentes você mesmo (como aprender matemática na mão antes de depender da calculadora). Espero que você curta esses insights — e que isso seja só uma fatia pequena da sua jornada em IA.
Sou grato por trabalhar com um time de cientistas de dados especialistas, e, à medida que aprendo mais, vou "passar adiante" com mais artigos como este. Se você quiser fazer parte do nosso time na DoiT, visite nossa página de carreiras ou me chame no Twitter ou LinkedIn.