Come mettere insieme i pezzi per la propria pipeline ML
Molti tutorial che mi capita di trovare coprono solo una parte di una soluzione completa e funzionante. Alcuni mostrano un Notebook (ci arriveremo) con addestramento del modello, predizione e analisi. Altri spiegano come creare un'API per esporre un modello. Ho voluto adottare un approccio diverso e mostrare come progettare un'applicazione end-to-end con web app, API e riaddestramento automatico del modello in base alle interazioni degli utenti.
Prerequisito: video demo
Leggi la parte 1 di questa serie per vedere la demo di quattro minuti dell'applicazione funzionante e per un'introduzione ai concetti e alla terminologia del machine learning. In seguito esploreremo i passaggi che ho seguito per progettare e realizzare la demo della pipeline ML, con le decisioni prese lungo il percorso.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Progettazione della soluzione ad alto livello
Sono partito da requisiti non funzionali ben precisi: efficienza delle risorse, scalabilità e prestazioni inferiori al secondo. Molti modelli di predizione potrebbero essere esposti semplicemente da un programma API senza alcun problema. Qui, invece, mostrerò come si potrebbe progettare un'architettura serverless distribuita basata su servizi di public cloud e perché si potrebbe scegliere proprio questo approccio.
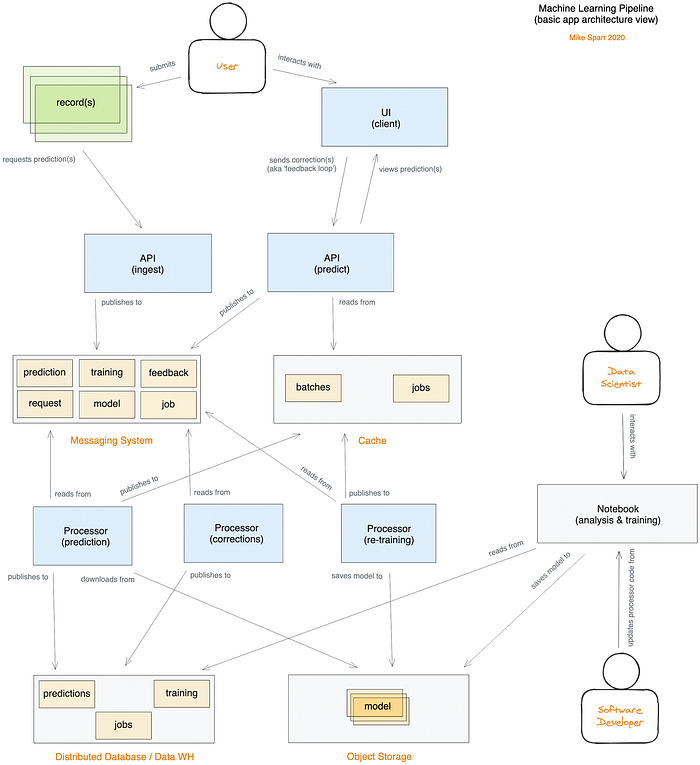
Architettura personalizzata della pipeline ML (app serverless distribuita ospitata su public cloud)
Se sei un data scientist con qualche base di sviluppo software, alcune cose potrebbero sembrarti poco familiari — vendetta, ah! Esplorando i repository del codice sorgente e leggendo il codice reale che si ricollega al Notebook, spero che i pezzi del puzzle vadano al loro posto e che il tutto ti risulti utile.
Parti da un piano
Senza un piano si rischia di sprecare un sacco di tempo. È un po' come inchiodare assi sperando prima o poi di tirare su un edificio: è molto più efficiente disegnare i progetti, comprare i materiali e poi assemblare. Progettare soluzioni software non è poi così diverso, ma a livelli di esperienza diversi corrispondono tipi di pianificazione diversi.
Architettura, UI e progettazione delle API
Giusto per dimostrare di non aver saltato questa fase, ecco una foto di alcuni dei miei schizzi grezzi realizzati durante la pausa del Ringraziamento, da cui è poi nato il diagramma di architettura mostrato sopra. Ho quindi sviluppato la demo nel mio tempo libero a dicembre 2020.
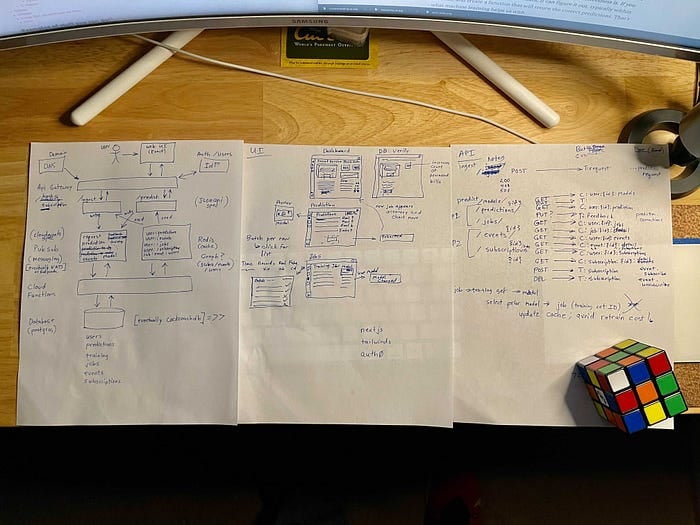
Mockup iniziali di architettura, UI e interfacce API per la demo dell'app AI
Scegliere l'algoritmo di machine learning giusto
Con l'aiuto di un collega di DoiT International (il nostro team include molti guru dell'AI e master di competizioni Kaggle), ho deciso di progettare un classificatore binario utilizzando un algoritmo lineare Support Vector Machine (SVM) per addestrare il modello. Il video qui sotto spiega di cosa si tratta, ma non preoccuparti se a questo punto ti sembra troppo complesso: a mio parere, capire come funzionano nel dettaglio gli algoritmi non è la cosa più importante all'inizio.
Se i dati cadono da un lato della linea sono "cattivi", se cadono dall'altro sono "buoni". Le basi sono queste.
Invece di usare il mio progetto reale, per ora, ho trovato un dataset pubblico con cui costruire tutta la demo. In seguito potrò sostituire le features con quelle del mio progetto, aggiungere la sicurezza e gli altri elementi necessari per una vera startup.
Stack tecnologico scelto
Avendo ricoperto ruoli senior in diverse aziende, è da un po' che non sviluppo attivamente nuovi prodotti software. Ho quindi dedicato un paio di giorni della pausa del Ringraziamento a riprendere confidenza con strumenti e framework attuali, fino a definire il mio "stack". Per semplicità tralasciamo l'automazione DevOps, ma potrei trattarla in un futuro post.
- Livello UI — container NextJS/React + Chakra UI serviti da Cloud Run
- Livello API — container Golang + Go-Chi serviti da Cloud Run
- Livello messaggistica — Cloud Pub/Sub
- Livello caching — Cloud Memorystore (Redis)
- Livello processor — Python Cloud Functions con trigger Pub/Sub
- Livello database — Cloud SQL (Postgres)
- Livello storage — Cloud Storage Buckets
Per proteggere i secret come le password del database utilizzate dalle funzioni, la demo si appoggia a Cloud Secret Manager. Di norma progetto soluzioni vendor agnostic, ma la maggior parte dei servizi gestiti di Google Cloud Platform si basa su prodotti open-source, quindi è più semplice "sostituirli" con OSS in un secondo momento. Anche aggiungere più interfacce nel codice può semplificare la sostituzione dei servizi.
"Mostrami il codice"

Ha davvero detto "mostrami il codice" e "adoro la data science"
Codice sorgente e documentazione
I seguenti repository GitHub contengono il codice funzionante della demo che hai visto nella parte 1 di questa serie. Ogni repository include una demo e la documentazione su come quel componente si inserisce nell'architettura complessiva, oltre alle istruzioni per installarli ed eseguirli in autonomia.
- Web UI — interfaccia user-friendly per visualizzare il funzionamento del sistema
- Ingest API — il punto in cui inviamo i batch di record per cui vogliamo ottenere predizioni
- Predict API — fornisce predizioni in batch e riceve le correzioni dell'utente
- Processors — cloud function asincrone che eseguono predizione, addestramento e persistenza dei dati (include anche il Jupyter Notebook originale, il modello addestrato, il dataset e i file dello schema del database)
Il passo successivo (per passare dalla demo a un'app vera e propria) sarebbe rifinire il codice (renderlo più difensivo), aggiungere test automatizzati e paginazione. Poi proviciionerei l'infrastruttura con Terraform, perfezionerei la pipeline CI/CD e metterei davanti a tutto un API Gateway per centralizzare autenticazione, logging, tracing e rate-limiting. Se deciderò di rendere open-source quei passaggi, aggiornerò questa serie con una "parte 3". ;-)
Confronto con le soluzioni commerciali
Mentre approfondisci questa serie di articoli e i repository GitHub indicati sopra, spero che inizierai a riconoscere i pezzi e i termini che all'inizio sembravano scoraggianti. Una buona prova è osservare questo diagramma di Google che descrive la sua soluzione gestita AI Platform. Guardando i blocchi, quanti termini ti risultano ora chiari?
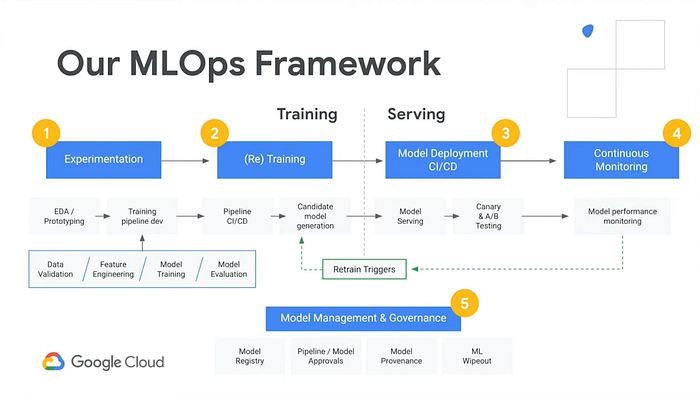
Esplorando il repository ai-demo-functions della demo troverai funzionalità analoghe:
- "Experimentation" — vedi notebook.ipynb
- "(Re) Training" — vedi /training/main.py
- "Model Deployment" e "Model Serving" — vedi /training/main.py , /prediction/main.py e /prediction-to-cache/main.py
- "Continuous Monitoring" e "Retrain Triggers" — vedi /feedback-to-db/main.py e /feedback-to-training/main.py
- "Model Management & Governance" — vedi /training-to-cache/main.py e training-to-db/main.py
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Prestazioni
Spesso uno dei principali fattori di differenziazione tra le soluzioni sul mercato sono le prestazioni. Molte scelte progettuali sono state guidate proprio da obiettivi di performance.
Python o no?
Nel Jupyter Notebook in cui ho condotto i primi esperimenti ho misurato il tempo richiesto da ciascuna operazione, per assicurarmi che Python e le librerie scelte fossero all'altezza delle mie esigenze.
Uno di questi esperimenti riguardava il serving della predizione vero e proprio. Ho caricato i dati di input dell'utente in una struttura Pandas DataFrame ed eseguito la predizione, impiegando circa 6 millisecondi. Per fortuna un collega mi ha suggerito che con un array Numpy avrei potuto guadagnare tempo, e in effetti il tempo di predizione è sceso a 2 millisecondi: per me un bel risultato.
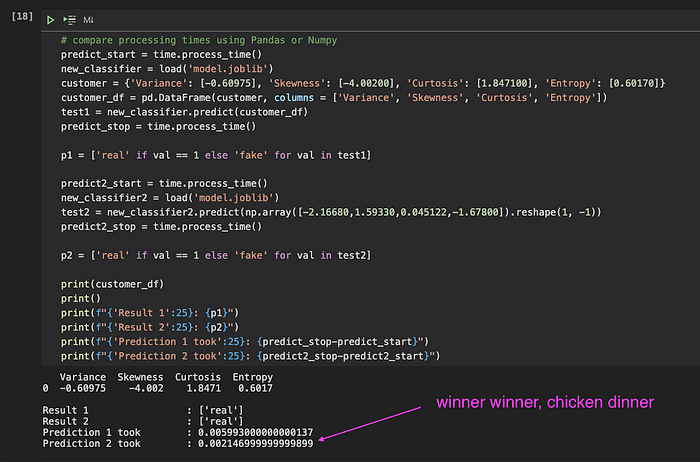
Confronto tra tempi di elaborazione (e consumo di memoria) di diverse strutture dati
Funzioni serverless o no?
Un altro aspetto che mi preoccupava erano i tempi di cold start delle funzioni serverless e la velocità di esecuzione. Dopo aver sperimentato con qualche funzione di test, ho trovato il modo di precaricare le librerie e ridurre drasticamente il tempo di esecuzione della funzione di predizione a circa 8 millisecondi. Tutti i test hanno confermato che Python e Google Cloud Functions sarebbero stati all'altezza delle mie esigenze.
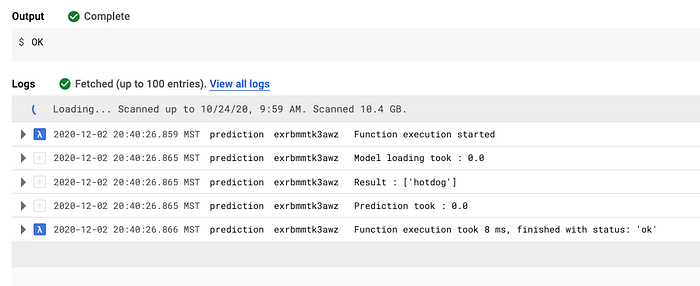
Test iniziali sul tempo di esecuzione della predizione di Cloud Function (8 millisecondi)
Con tempi di addestramento del modello o dataset diversi avrei però potuto prendere decisioni differenti, dati i timeout fissi e i limiti di memoria.
- Cloud Functions — max 4Gb di memoria; tempo di esecuzione max 9m
- Cloud Run — max 8Gb di memoria; esecuzione max 15m (60m in beta)
- Cloud Run (Anthos) — più memoria; esecuzione max 24h (gke 16+)
- per job a esecuzione più lunga, valuta GKE o l'esecuzione di container su VM
Pro tip
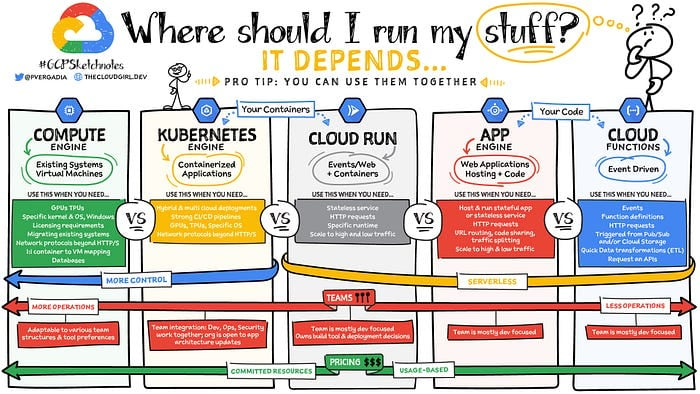
Fonte: Google (Priyanka Avergadia)
Container per le API o no?
Per il livello API ho scelto Golang e Google Cloud Run. Volevo costruire qualcosa in Golang, che è molto veloce e gestisce un'elevata concorrenza con risorse minime, come NodeJS. Inoltre l'immagine Docker è di dimensioni ridotte, quindi sotto carico può scalare automaticamente molto in fretta. Infine, un linguaggio fortemente tipizzato aiuta a ridurre la "spazzatura in ingresso", offrendo un livello di difesa prima di passare i dati ai processor Python a tipizzazione dinamica.
Usando Apache Bench e sperimentando con la compressione gzip sono riuscito a ridurre il trasferimento di rete dell'82%, con una media di 5,295 millisecondi per richiesta dalla mia rete domestica in Montana, USA, ai server us-central1 di Google. Un altro collega mi ha consigliato Snappy, che potrebbe ridurre il consumo di CPU mantenendo comunque un'ottima ottimizzazione di rete (occorre sperimentare per trovare la combinazione migliore).
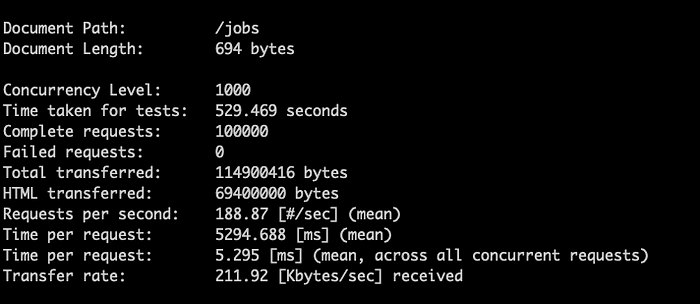
Benchmark delle prestazioni API con e senza compressione
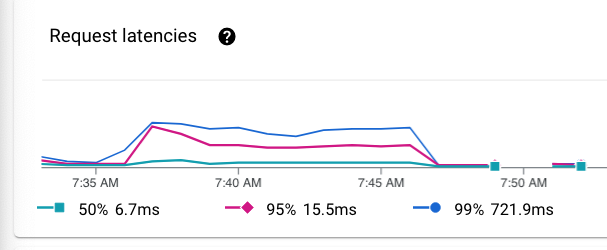
Analisi dell'overhead dell'infrastruttura cloud e delle latenze delle richieste
React o no? In diverse aziende abbiamo usato la libreria React per il livello web UI, in altre Angular. Tengo d'occhio VueJS e altri framework, ma ho scelto React perché ho più esperienza personale con esso ed è quello che usiamo nella mia azienda attuale. In passato ho avviato app React con create-react-app, ma ho letto report molto positivi sulle prestazioni SSR migliorate e sulla semplicità di routing offerte da NextJS.
Material UI o no?
Ho passato un paio di giorni a provare framework CSS come Material UI, Tailwinds e infine Chakra UI. In passato avevo usato Semantic UI, ma volevo qualcosa che adottasse tecniche di styling più moderne. Chakra mi ha conquistato (per ora) ed è ciò con cui è costruita questa demo.
Efficienza e sostenibilità economica
Un altro vantaggio competitivo per un'azienda è l'efficienza dei costi: le permette di essere più competitiva godendo al tempo stesso di margini di profitto più alti. Visto che spesso consiglio agli altri come ottimizzare la propria infrastruttura public cloud, ho voluto mettermi alla prova in prima persona e vedere quanto efficientemente potessi far girare un intero stack di un'app AI, bilanciando esigenze umane e tecnologiche.
Dopo aver costruito ed eseguito questo stack per un mese, sono lieto di poter dire che questo singolo ambiente, con carico minimo, è costato meno di 80 dollari. È chiaro che ambienti multipli e un utilizzo crescente faranno aumentare il costo nel tempo. L'architettura serverless e altre scelte, come la compressione dei dati e persino il design dei dati serializzati (array al posto di hash per eliminare le ridondanze), dovrebbero mantenere i costi operativi piuttosto bassi.
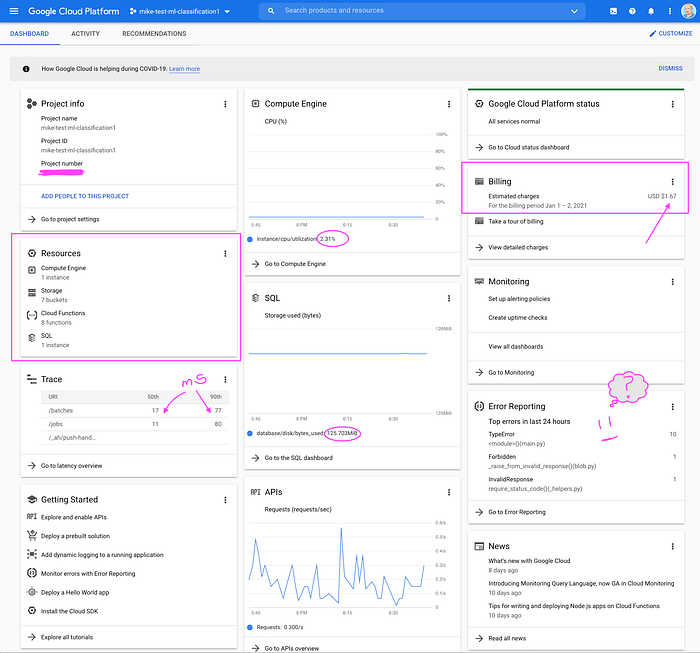
Singolo ambiente che esegue una demo a costi molto contenuti (finora)
Prossimi passi
Come accennato nel primo articolo, abbiamo tralasciato molti contenuti che di solito si trovano nei tutorial di ML. Questa demo utilizza il "supervised learning" e crea un "binary classifier", ma tutti abbiamo sentito parlare di reti neurali e via dicendo, che sono tipi di apprendimento differenti.
Ho volutamente eliminato questo "rumore" per mettere a fuoco fin da subito una comprensione d'insieme. Mentre prosegui il tuo percorso nell'AI e nel ML, ecco alcune risorse utili da esplorare per capire meglio l'ampia gamma di problemi e di soluzioni che AI e ML possono affrontare:
- Elements of AI (corso online gratuito dell'Università di Helsinki)
- Diagramma panoramico degli algoritmi (diversi tipi di strumenti e di problemi)
- Scegliere l'algoritmo giusto (ottimi diagrammi delle varie tipologie)
- Confronto tra piattaforme
Esistono soluzioni commerciali come Databricks, AI Platform, Sagemaker, oppure soluzioni open-source come ML Flow e Kubeflow. Ognuna ha i suoi pro e contro, oltre a costi aggiuntivi, punti di guasto e curve di apprendimento.
Ho concluso che, per capire davvero come costruire una pipeline ML in grado di servire e riaddestrare predizioni, è meglio costruire i componenti da soli (un po' come imparare la matematica a mano prima di affidarsi alla calcolatrice). Spero che questi spunti ti siano utili e che rappresentino una piccola tappa del tuo percorso complessivo nell'AI.
Sono fortunato a poter lavorare con un team di data scientist esperti, quindi man mano che imparerò "restituirò il favore" con altri articoli come questi. Se vuoi unirti al team di DoiT, visita la nostra pagina careers oppure contattami con un messaggio su Twitter o LinkedIn.