So fügen Sie die Bausteine Ihrer eigenen ML-Pipeline zusammen
Viele Tutorials, die mir begegnen, behandeln nur einen Ausschnitt einer funktionierenden Gesamtlösung. Manche zeigen ein Notebook (dazu gleich mehr) mit Modelltraining, Vorhersage und Analyse. Andere erklären, wie man eine API baut, um ein Modell bereitzustellen. Ich wollte einen anderen Weg gehen und zeigen, wie sich eine durchgängige Anwendung mit Web-App, API und automatischem Modell-Retraining auf Basis von Nutzerinteraktionen entwerfen lässt.
Voraussetzung: Demo-Video
In Teil 1 dieser Serie finden Sie die vierminütige Demo der lauffähigen Anwendung sowie Hintergründe zu Konzepten und Begriffen rund um Machine Learning. Im Folgenden gehen wir die Schritte durch, mit denen ich die ML-Pipeline-Demo entworfen und umgesetzt habe – samt der Entscheidungen, die dabei gefallen sind.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Lösungsdesign im Überblick
Ausgangspunkt waren konkrete nicht-funktionale Anforderungen: Ressourceneffizienz, Skalierbarkeit und Performance im Sub-Sekunden-Bereich. Viele Vorhersagemodelle ließen sich problemlos einfach über ein API-Programm ausliefern. Hier möchte ich aber zeigen, wie sich mit Public-Cloud-Diensten eine verteilte serverlose Architektur entwerfen lässt – und warum man sich für ein solches Design entscheiden könnte.
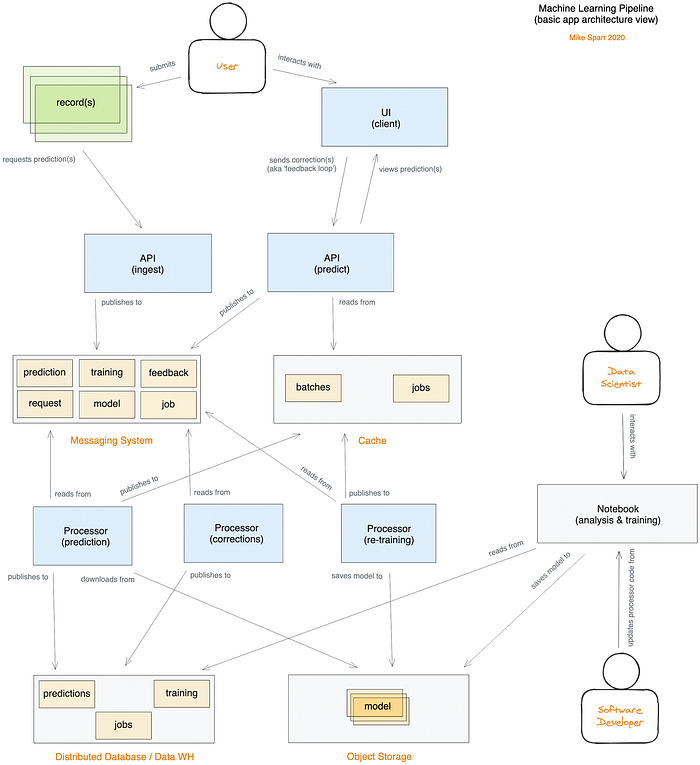
Maßgeschneiderte ML-Pipeline-Architektur (verteilte serverlose App, gehostet in der Public Cloud)
Wenn Sie Data Scientist mit etwas Software-Hintergrund sind, mag Ihnen einiges davon fremd vorkommen – kleine Retourkutsche, ha! Beim Erkunden der Quellcode-Repos und beim Blick auf den tatsächlichen Code, der zum Notebook zurückführt, fügen sich die Puzzleteile hoffentlich zusammen und das Ganze hilft Ihnen weiter.
Mit einem Plan starten
Ohne Plan vergeuden Sie schnell viel Zeit. Bretter zusammenzunageln und zu hoffen, dass am Ende ein Gebäude entsteht, ist deutlich ineffizienter, als zuerst Pläne zu zeichnen, Material zu beschaffen und dann zu montieren. Beim Entwurf von Softwarelösungen ist es nicht anders – allerdings erfordern unterschiedliche Erfahrungsstufen unterschiedliche Arten der Planung.
Architektur-, UI- und API-Design
Damit Sie sehen, dass ich diesen Schritt nicht übersprungen habe: Unten finden Sie ein Foto einiger meiner groben Skizzen aus der Thanksgiving-Pause, aus denen das oben gezeigte Architekturdiagramm entstanden ist. Anschließend habe ich die Demo-App im Dezember 2020 in meiner Freizeit umgesetzt.
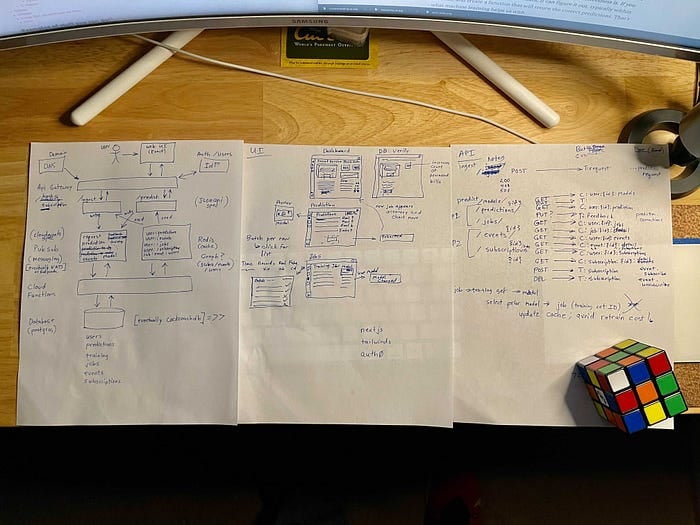
Erste Mockups für Architektur, UI und API-Schnittstellen der KI-Demo-App
Den passenden Machine-Learning-Algorithmus wählen
Mit Unterstützung eines Kollegen von DoiT International (in unserem Team gibt es viele KI-Profis und Kaggle Competition Master) habe ich mich für einen binären Klassifikator entschieden, der mit einem linearen Support-Vector-Machine-Algorithmus (SVM) trainiert wird. Das folgende Video erklärt, was sich dahinter verbirgt – aber keine Sorge, falls das im Moment zu hoch ist: Wie die Algorithmen im Detail funktionieren, ist meiner Meinung nach am Anfang gar nicht so entscheidend.
Liegen Ihre Daten auf der einen Seite der Linie, sind sie "schlecht", auf der anderen Seite "gut". Das ist die Grundidee.
Statt mein eigenes Projekt zu nutzen, habe ich für diese Demo zunächst einen öffentlichen Datensatz gefunden, mit dem ich alles aufbauen kann. Später lassen sich die Features auf mein Projekt umstellen, Sicherheit ergänzen und weitere Bestandteile hinzufügen, die ein echtes Startup braucht.
Der gewählte Technologie-Stack
Da ich in verschiedenen Unternehmen Senior-Rollen innehatte, habe ich eine Weile keine neuen Softwareprodukte aktiv programmiert. In der Thanksgiving-Pause habe ich daher zunächst ein paar Tage damit verbracht, mich wieder in aktuelle Tools und Frameworks einzuarbeiten und meinen "Stack" festzulegen. Der Einfachheit halber lassen wir DevOps-Automatisierung außen vor – die ergänze ich vielleicht in einem späteren Beitrag.
- UI-Layer – NextJS/React + Chakra-UI-Container, ausgeliefert über Cloud Run
- API-Layer – Golang + Go-Chi-Container, ausgeliefert über Cloud Run
- Messaging-Layer – Cloud Pub/Sub
- Caching-Layer – Cloud Memorystore (Redis)
- Processor-Layer – Python Cloud Functions mit Pub/Sub-Trigger
- Datenbank-Layer – Cloud SQL (Postgres)
- Storage-Layer – Cloud Storage Buckets
Zum Schutz sensibler Daten wie Datenbankpasswörter für die Functions setzt die Demo-App den Cloud Secret Manager ein. Üblicherweise designe ich anbieterunabhängig – die meisten Managed Services der Google Cloud Platform basieren jedoch auf Open-Source-Produkten, sodass sich später leichter auf OSS-Alternativen umsteigen lässt. Zusätzliche Schnittstellen im Code erleichtern den Austausch von Diensten zusätzlich.
"Show me the code"

Er hat tatsächlich gesagt: "Show me the code" und "I love data science"
Quellcode und Dokumentation
Die folgenden GitHub-Repositories enthalten den lauffähigen Code für die Demo-App, die Sie in Teil 1 dieser Serie gesehen haben. Jedes Repo enthält eine Demo und Dokumentation dazu, wo die jeweilige Komponente in die Gesamtarchitektur passt und wie Sie sie selbst installieren und ausführen.
- Web-UI – benutzerfreundliche Oberfläche zur Visualisierung der Funktionsweise
- Ingest-API – hier reichen wir Datensatz-Batches ein, für die wir Vorhersagen wollen
- Predict-API – liefert Batch-Vorhersagen aus und nimmt Korrekturen der Nutzer entgegen
- Processors – asynchrone Cloud Functions für Vorhersage, Training und Datenpersistenz (enthält auch das ursprüngliche Jupyter Notebook, das trainierte Modell, den Datensatz sowie Datenbankschema-Dateien)
Mein nächster Schritt (vom Demo zum echten Produkt) wäre, den Code zu härten (robuster zu machen) und automatisierte Tests sowie Pagination zu ergänzen. Anschließend würde ich die Infrastruktur per Terraform bereitstellen, die CI/CD-Pipeline verfeinern und alles über ein API-Gateway absichern, um Authentifizierung, Logging, Tracing und Rate-Limiting zentral zu bündeln. Falls ich diese Schritte als Open Source veröffentliche, ergänze ich diese Serie um einen "Teil 3". ;-)
Vergleich mit kommerziellen Lösungen
Beim Durcharbeiten dieser Artikelserie und der oben verlinkten GitHub-Repos werden Sie hoffentlich beginnen, jene Bausteine und Begriffe wiederzuerkennen, die anfangs überwältigend wirkten. Ein guter Test ist ein Blick auf das folgende Diagramm von Google, das deren Managed Service AI Platform beschreibt. Wie viele Begriffe in den Boxen ergeben für Sie inzwischen Sinn?
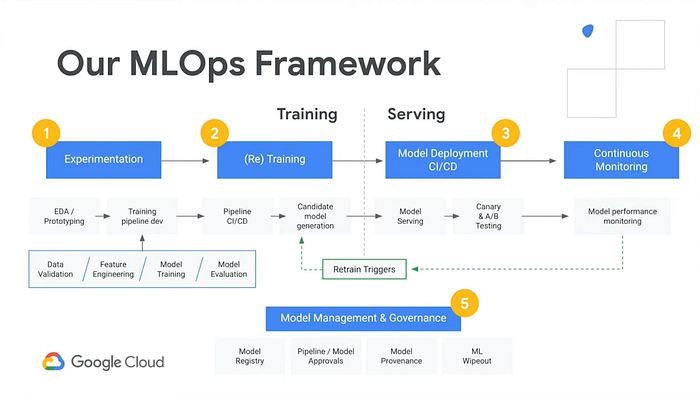
Im Repo der Demo-App ai-demo-functions finden Sie ähnliche Funktionalität:
- "Experimentation" – siehe notebook.ipynb
- "(Re) Training" – siehe /training/main.py
- "Model Deployment" und "Model Serving" – siehe /training/main.py, /prediction/main.py und /prediction-to-cache/main.py
- "Continuous Monitoring" und "Retrain Triggers" – siehe /feedback-to-db/main.py und /feedback-to-training/main.py
- "Model Management & Governance" – siehe /training-to-cache/main.py und training-to-db/main.py
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Performance
Performance ist häufig ein zentrales Unterscheidungsmerkmal zwischen Marktlösungen. Viele Designentscheidungen wurden hier von Performance-Zielen geleitet.
Python oder nicht?
Im Jupyter Notebook, in dem ich erste Experimente durchgeführt habe, habe ich gemessen, wie lange jede Operation dauert, um sicherzugehen, dass Python und die gewählten Bibliotheken meine Anforderungen erfüllen.
Eines dieser Experimente betraf die Vorhersage selbst. Ich habe die Eingabedaten der Nutzer in eine Pandas-DataFrame-Struktur geladen und die Vorhersage ausgeführt – das dauerte rund 6 Millisekunden. Glücklicherweise gab mir ein Kollege den Tipp, ein Numpy-Array zu nutzen: Damit reduzierte sich die Vorhersagezeit tatsächlich auf 2 Millisekunden – ein klarer Gewinn.
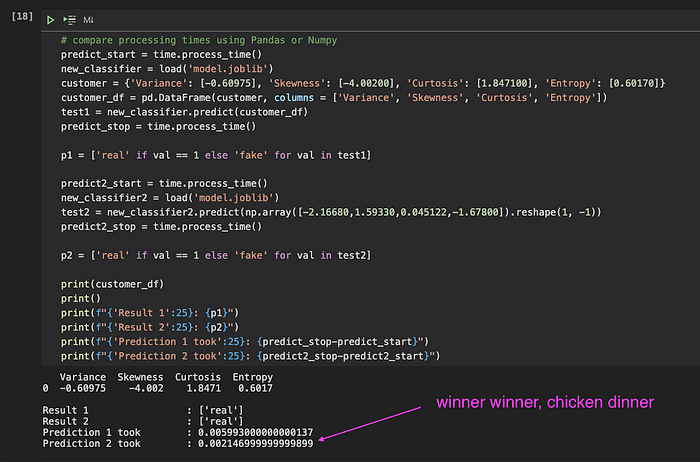
Vergleich von Verarbeitungszeit (und Speicherverbrauch) verschiedener Datenstrukturen
Serverless Functions oder nicht?
Ein weiteres Thema waren die Cold-Start-Zeiten serverloser Funktionen und ihr Verarbeitungstempo. Nach Tests mit einigen Funktionen habe ich einen Weg gefunden, Bibliotheken vorzuladen und die Ausführungszeit der Predict-Funktion drastisch auf rund 8 Millisekunden zu drücken. Alle Tests zeigten, dass Python und Google Cloud Functions meine Anforderungen erfüllen können.
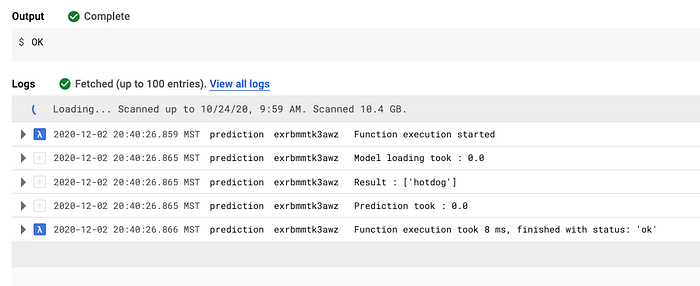
Erste Tests zur Ausführungszeit der Predict-Cloud-Function (8 Millisekunden)
Bei abweichenden Trainingszeiten oder einem anderen Datensatz könnten angesichts fester Timeouts und Speichergrenzen jedoch andere Entscheidungen sinnvoll sein.
- Cloud Functions – max. 4 GB Speicher; max. 9 Min. Ausführungszeit
- Cloud Run – max. 8 GB Speicher; max. 15 Min. Ausführungszeit (60 Min. in Beta)
- Cloud Run (Anthos) – mehr Speicher; max. 24 Std. Ausführungszeit (GKE 16+)
- Für länger laufende Jobs sollten Sie GKE oder den Container-Betrieb auf VMs in Betracht ziehen.
Profi-Tipps
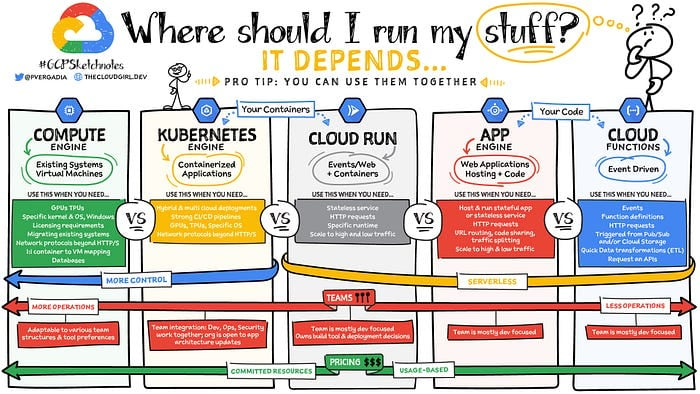
Quelle: Google (Priyanka Avergadia)
Container für die API oder nicht?
Für den API-Layer habe ich mich für Golang und Google Cloud Run entschieden. Ich wollte etwas in Golang bauen, und die Sprache ist sehr schnell und bietet hohe Nebenläufigkeit bei minimalem Ressourcenbedarf – ähnlich wie NodeJS. Außerdem ist das Docker-Image klein, sodass es unter Last schnell autoskaliert. Schließlich kann eine streng typisierte Sprache helfen, "Garbage in" zu reduzieren, und so eine Schutzschicht bilden, bevor Daten an die dynamisch typisierten Python-Processors weitergereicht werden.
Mit Apache Bench und etwas Feintuning bei der gzip-Kompression konnte ich den Netzwerk-Transfer um 82 % reduzieren und durchschnittlich 5,295 Millisekunden pro Request erreichen – aus meinem Heimnetzwerk in Montana, USA, zu Googles us-central1-Servern. Ein Kollege empfahl mir Snappy, das die CPU-Kosten senken kann und gleichzeitig eine ordentliche Netzwerkoptimierung bietet (per Trial-and-Error die beste Kombination finden).
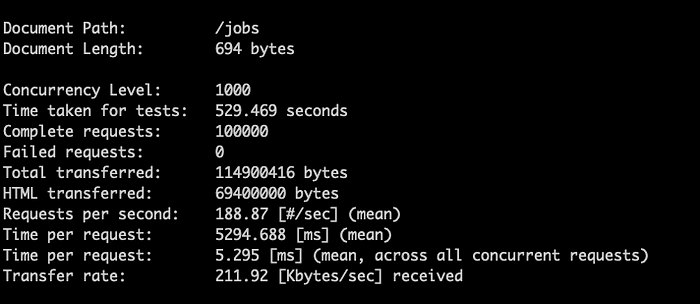
API-Performance mit und ohne Kompression im Benchmark
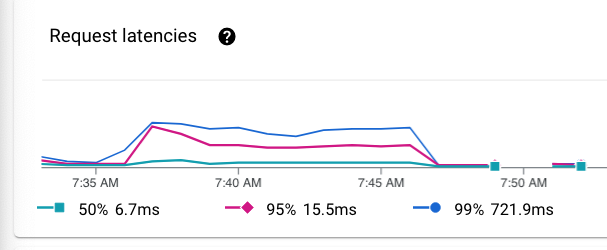
Analyse von Cloud-Infrastruktur-Overhead und Request-Latenzen
React oder nicht? In mehreren Unternehmen haben wir die React-Bibliothek für den Web-UI-Layer eingesetzt, in anderen Angular. Ich beobachte VueJS und andere Frameworks, habe mich aber für React entschieden, weil ich damit mehr eigene Erfahrung habe und es in meinem aktuellen Unternehmen zum Einsatz kommt. Früher habe ich React-Apps mit create-react-app aufgesetzt, in letzter Zeit aber beeindruckende Berichte über bessere SSR-Performance und einfacheres Routing mit NextJS gelesen.
Material UI oder nicht?
Ich habe ein paar Tage CSS-Frameworks wie Material UI, Tailwind und schließlich Chakra UI ausprobiert. Früher habe ich Semantic UI genutzt, wollte diesmal aber etwas mit moderneren Styling-Techniken. Chakra hat mich (vorerst) überzeugt – damit ist diese Demo gebaut.
Effizienz und Wirtschaftlichkeit
Ein weiterer Wettbewerbsvorteil kann Kosteneffizienz sein. Sie ermöglicht es einem Unternehmen, wettbewerbsfähiger zu agieren und gleichzeitig höhere Margen zu erzielen. Da ich häufig andere bei der Optimierung ihrer Public-Cloud-Infrastruktur berate, wollte ich es selbst auf die Probe stellen und herausfinden, wie effizient sich ein kompletter KI-App-Stack betreiben lässt – im Spannungsfeld zwischen menschlichen und technischen Anforderungen.
Nachdem ich diesen Stack einen Monat lang aufgebaut und betrieben habe, kann ich erfreut berichten, dass diese einzelne Umgebung mit minimaler Last weniger als 80 USD gekostet hat. Mehrere Umgebungen und steigende Nutzung treiben die Kosten mit der Zeit natürlich nach oben. Die serverlose Architektur und weitere Entscheidungen wie komprimierte Daten oder das serialisierte Datendesign (Arrays statt Hashes, um redundante Daten zu vermeiden) sollten die Betriebskosten dennoch sehr niedrig halten.
Eine einzelne Umgebung, die eine Demo zu sehr niedrigen Kosten betreibt (bisher)
Nächste Schritte
Wie ich im ersten Artikel erwähnt habe, haben wir viele Inhalte ausgespart, die in ML-Tutorials normalerweise behandelt werden. Diese Demo nutzt "Supervised Learning" und erstellt einen "binären Klassifikator". Wir haben aber alle schon von neuronalen Netzen usw. gehört – das sind andere Lernarten.
Ich habe dieses "Rauschen" bewusst weggelassen, damit der Fokus zunächst auf einem Gesamtverständnis liegt. Wenn Sie auf Ihrer Reise in die Welt von KI und ML weiterkommen wollen, finden Sie hier einige hilfreiche Ressourcen, um die breitere Palette an Problemen und Lösungen besser zu verstehen, die KI und ML adressieren können:
- Elements of AI (kostenloser Online-Kurs der Universität Helsinki)
- Algorithmus-Übersichtsdiagramm (verschiedene Tools und Problemstellungen)
- Den richtigen Algorithmus wählen (gute Diagramme zu unterschiedlichen Typen)
- Plattform-Vergleich
Es gibt kommerzielle Lösungen wie Databricks, AI Platform und Sagemaker oder Open-Source-Lösungen wie ML Flow und Kubeflow. Jede hat ihre Vor- und Nachteile, dazu zusätzliche Kosten, potenzielle Fehlerquellen und eine eigene Lernkurve.
Mein Fazit: Wer wirklich verstehen will, wie man eine ML-Pipeline für Vorhersagen und Retraining baut, baut die Komponenten am besten selbst – so wie man Mathe von Hand lernt, bevor man sich auf einen Taschenrechner verlässt. Ich hoffe, diese Einblicke gefallen Ihnen – sie sind nur ein kleiner Ausschnitt Ihrer KI-Reise.
Ich bin dankbar, mit einem Team erfahrener Data Scientists arbeiten zu dürfen. Je mehr ich lerne, desto mehr werde ich es mit weiteren Artikeln wie diesem weitergeben. Wenn Sie zu unserem Team bei DoiT stoßen möchten, besuchen Sie unsere Karriereseite oder schreiben Sie mir eine Nachricht auf Twitter oder LinkedIn.