Cómo armar las piezas de tu propio pipeline de ML
La mayoría de los tutoriales que encuentro solo cubre una parte de la solución completa. Algunos muestran un Notebook (ya llegaremos a eso) con entrenamiento de modelos, predicción y análisis. Otros explican cómo crear una API para servir un modelo. Quise tomar otro camino y mostrar cómo se puede diseñar una aplicación de extremo a extremo con la web app, la API y el reentrenamiento automático del modelo a partir de las interacciones del usuario.
Requisito previo: video demo
Lee la parte 1 de esta serie para ver el demo de cuatro minutos de la aplicación en funcionamiento, junto con el contexto sobre los conceptos y la terminología de machine learning. A continuación, repasaremos los pasos que seguí para diseñar y crear el demo del pipeline de ML, y las decisiones que tomé en el camino.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Diseño general de la solución
Partí de requisitos no funcionales muy específicos en cuanto a eficiencia de recursos, escalabilidad y rendimiento por debajo del segundo. Muchos modelos de predicción podrían servirse simplemente con un programa API y funcionarían bien. Aquí, en cambio, te mostraré cómo diseñar una arquitectura serverless distribuida usando servicios de nube pública, y por qué alguien optaría por este diseño.
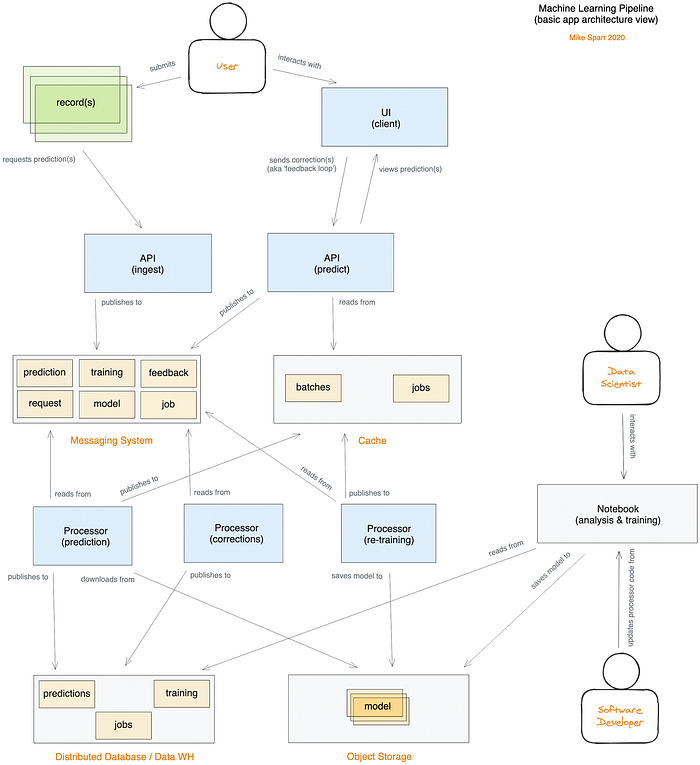
Arquitectura personalizada de pipeline de ML (app serverless distribuida en nube pública)
Si eres data scientist con algo de experiencia en software, parte de esto te puede sonar ajeno; ¡es la revancha! A medida que explores los repositorios del código fuente y veas el código real conectado con el Notebook, espero que las piezas del rompecabezas vayan encajando y te resulte útil.
Empieza con un plan
Sin un plan, lo más probable es que pierdas mucho tiempo. Es como clavar tablas con la esperanza de que tarde o temprano salga un edificio: resulta mucho más eficiente trazar planos, comprar los materiales y luego ensamblar. Diseñar soluciones de software no es muy distinto, aunque cada nivel de experiencia exige un tipo de planificación diferente.
Diseño de arquitectura, UI y API
Para que veas que no me salté ese paso, aquí tienes una foto de algunos de mis bocetos hechos durante el feriado de Acción de Gracias, que terminaron en el diagrama de arquitectura que ves arriba. Después construí el demo en mis ratos libres durante diciembre de 2020.
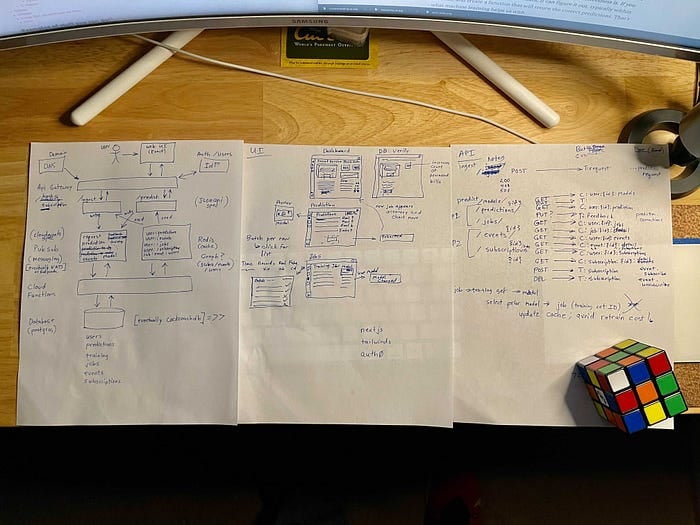
Mockups iniciales de las interfaces de arquitectura, UI y API para el demo de IA
Cómo elegir el algoritmo de machine learning adecuado
Con la ayuda de un colega de DoiT International (en nuestro equipo hay muchos referentes en IA y masters de competencias en Kaggle), me decidí por diseñar un clasificador binario usando un algoritmo lineal de Support Vector Machine (SVM) para entrenar mi modelo. El video de abajo explica en qué consiste, pero no te preocupes si por ahora te queda grande: en mi opinión, entender cómo funcionan los algoritmos no es lo más importante al inicio.
Si tus datos caen de un lado de la línea, son "malos"; si caen del otro, son "buenos". Esa es la base.
En lugar de usar mi proyecto real, por ahora encontré un dataset público con el que armé todo este demo. Más adelante puedo cambiar las features a las de mi proyecto, sumar seguridad y otras piezas necesarias para una startup real.
El stack tecnológico elegido
Como he tenido roles senior en varias empresas, hace tiempo que no programaba activamente nuevos productos de software. Primero pasé un par de días durante el feriado de Acción de Gracias poniéndome al día con las herramientas y frameworks actuales para definir mi "stack". Por simplicidad, dejamos de lado la automatización de DevOps, aunque quizás la incluya en un próximo post.
- Capa UI — contenedores NextJS/React + Chakra UI servidos por Cloud Run
- Capa API — contenedores Golang + Go-Chi servidos por Cloud Run
- Capa de mensajería — Cloud Pub/Sub
- Capa de caché — Cloud Memorystore (Redis)
- Capa de procesamiento — Python Cloud Functions con trigger de Pub/Sub
- Capa de base de datos — Cloud SQL (Postgres)
- Capa de almacenamiento — Cloud Storage Buckets
Para proteger secretos como las contraseñas de bases de datos de las funciones, el demo usa Cloud Secret Manager. Por lo general diseño las cosas de forma agnóstica al proveedor, pero la mayoría de las soluciones administradas de Google Cloud Platform están basadas en productos open source, así que después es más fácil "reemplazarlas" por OSS. Sumar más interfaces en mi código también facilita intercambiar servicios.
"Muéstrame el código"

De verdad dijo "muéstrame el código" y "amo la ciencia de datos"
Código fuente y documentación
Los siguientes repositorios de Github contienen el código funcional del demo que viste en la parte 1 de esta serie. Cada repo incluye un demo y documentación sobre dónde encaja ese componente dentro de la arquitectura general, y cómo puedes instalarlos y ejecutarlos por tu cuenta.
- Web UI — interfaz amigable para visualizar cómo funciona el sistema
- Ingest API — donde se envían los lotes de registros para los que queremos predicciones
- Predict API — sirve predicciones por lotes y recibe correcciones de los usuarios
- Processors — funciones cloud asíncronas que ejecutan tareas de predicción, entrenamiento y persistencia de datos (también incluye el Jupyter Notebook original, el modelo entrenado, el dataset y los archivos de esquema de la base de datos)
El siguiente paso (pasar de demo a app real) sería refinar el código (más robusto), agregar pruebas automatizadas y paginación. Después aprovisionaría la infraestructura con Terraform, refinaría el pipeline de CI/CD y pondría todo detrás de un API Gateway para centralizar autenticación, logging, tracing y rate-limiting. Si decido publicar esos pasos en open source, actualizaré esta serie con una "parte 3". ;-)
Comparación con soluciones comerciales
A medida que recorras esta serie de artículos y los repositorios de Github de arriba, espero que empieces a reconocer las piezas y los términos que al principio parecían abrumadores. Una buena prueba es revisar este diagrama de Google que describe su solución administrada AI Platform. Al ver las cajas, ¿cuántos términos te hacen sentido ahora?
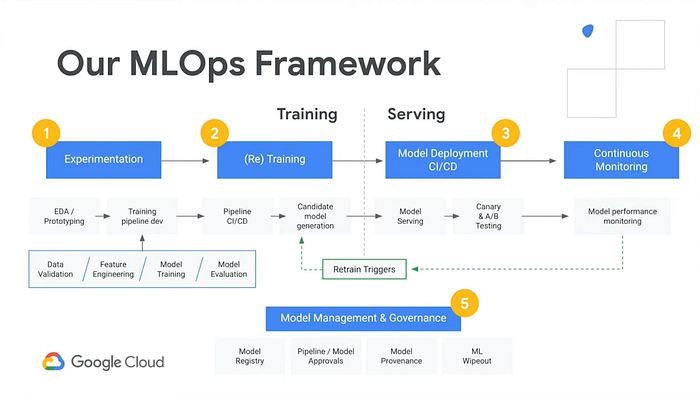
Si exploras el repo del demo ai-demo-functions, encontrarás funcionalidades parecidas:
- "Experimentation" — ver notebook.ipynb
- "(Re) Training" — ver /training/main.py
- "Model Deployment" y "Model Serving" — ver /training/main.py , /prediction/main.py , y /prediction-to-cache/main.py
- "Continuous Monitoring" y "Retrain Triggers" — ver /feedback-to-db/main.py y /feedback-to-training/main.py
- "Model Management & Governance" — ver /training-to-cache/main.py y training-to-db/main.py
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Rendimiento
Muchas veces, un diferenciador clave entre las soluciones del mercado es el rendimiento. Buena parte de las decisiones de diseño estuvieron guiadas por objetivos de desempeño.
¿Python o no?
En el Jupyter Notebook donde corrí los experimentos iniciales, medí el tiempo de cada operación para asegurarme de que el lenguaje Python y las librerías elegidas cumplieran con lo que necesitaba.
Uno de esos experimentos fue el servicio de predicción en sí. Cargué los datos de entrada del usuario en una estructura DataFrame de Pandas, ejecuté la predicción y tardó alrededor de 6 milisegundos. Por suerte, un colega me pasó el dato de que con un array de Numpy podía ser más rápido y, en efecto, el tiempo de predicción bajó a 2 milisegundos: una victoria, en mi opinión.
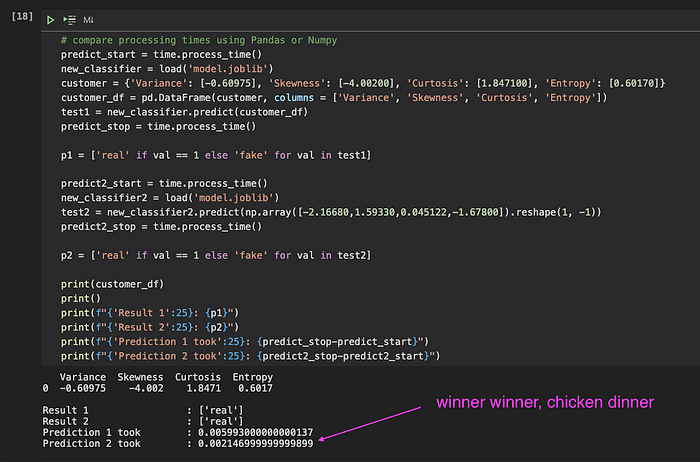
Comparativa de tiempo de procesamiento (y consumo de memoria) entre estructuras de datos
¿Funciones serverless o no?
Otra preocupación que tenía eran los tiempos de cold start de las funciones serverless y la velocidad con que procesan. Tras experimentar con algunas funciones de prueba, di con una forma de precargar librerías y reducir drásticamente el tiempo de ejecución de la función de predicción a unos 8 milisegundos. Todas las pruebas indicaron que Python y Google Cloud Functions cumplían con lo que necesitaba.
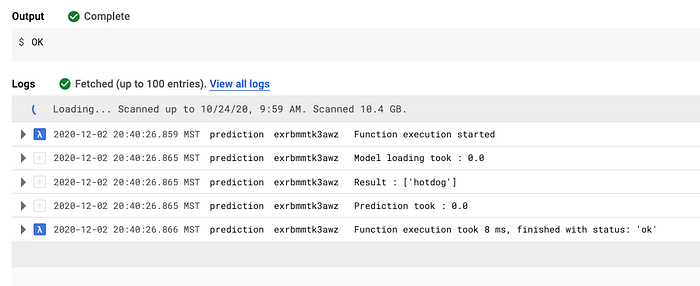
Pruebas iniciales del tiempo de ejecución de predicción en Cloud Function (8 milisegundos)
Ahora bien, si los tiempos de entrenamiento del modelo o el dataset fueran distintos, podría tomar otras decisiones, dadas las restricciones fijas de timeouts y límites de memoria.
- Cloud Functions — máximo 4 Gb de memoria; máximo 9 m de ejecución
- Cloud Run — máximo 8 Gb de memoria; máximo 15 m de ejecución (60 m en beta)
- Cloud Run (Anthos) — más memoria; máximo 24 h de ejecución (gke 16+)
- para trabajos más largos, considera GKE o correr el contenedor en VMs
Tips de pro
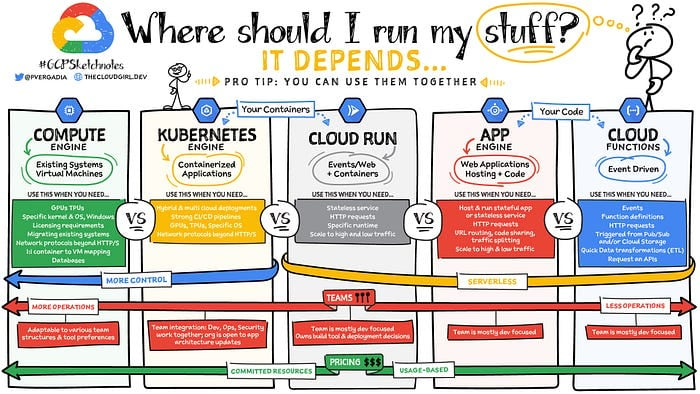
Fuente: Google (Priyanka Avergadia)
¿Contenedores para la API o no?
Me decidí por Golang y Google Cloud Run para la capa de API. Quería construir algo en Golang, y es muy rápido, con alta concurrencia y un consumo mínimo de recursos, parecido a NodeJS. Además, el tamaño de la imagen Docker es pequeño, así que bajo carga puede autoescalar rápidamente. Por último, un lenguaje fuertemente tipado ayuda a reducir el "garbage in" y suma una capa de defensa antes de pasar los datos a los procesadores Python con tipado dinámico.
Usando Apache Bench y experimentando con compresión gzip, logré reducir la transferencia de red en un 82 % y promediar 5,295 milisegundos por request desde mi red doméstica en Montana, EE. UU., hasta los servidores us-central1 de Google. Otro colega me recomendó Snappy, que puede reducir los costos de CPU y aun así ofrecer una buena optimización de red (es cuestión de probar y ajustar para encontrar la mejor combinación).
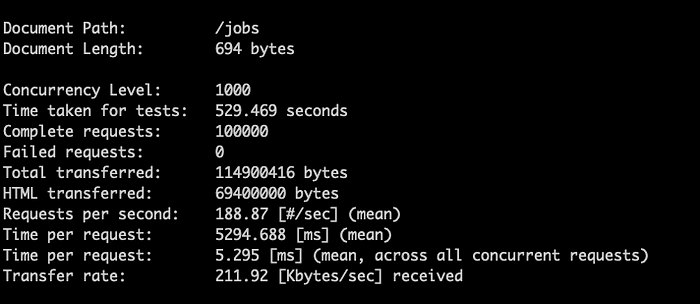
Benchmark del rendimiento de la API con y sin compresión
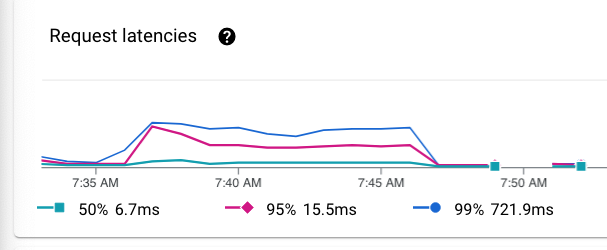
Análisis del overhead de la infraestructura cloud y de las latencias de request
¿React o no? En varias empresas usamos la librería React para la capa de UI web, y en otras usamos Angular. Vengo siguiendo VueJS y otros, pero elegí React porque es con lo que tengo más experiencia y es lo que usamos en mi empresa actual. Antes solía iniciar apps en React con create-react-app, pero he visto reportes muy positivos sobre las mejoras en el rendimiento de SSR y la simplicidad del routing con NextJS.
¿Material UI o no?
Pasé un par de días probando frameworks CSS como Material UI, Tailwinds y, finalmente, Chakra UI. En el pasado había usado Semantic UI, pero quería algo con técnicas de estilo más modernas. Chakra me convenció (por ahora), así que es lo que usé para construir este demo.
Eficiencia y costo accesible
Otra ventaja competitiva que puede tener una empresa es la eficiencia en costos. Eso le permite ser más competitiva y, al mismo tiempo, gozar de mejores márgenes de utilidad. Como suelo asesorar a otros sobre cómo optimizar su infraestructura de nube pública, quise ponerlo a prueba y ver qué tan eficiente podía correr todo un stack de aplicación de IA, equilibrando las necesidades humanas y tecnológicas.
Después de construir y mantener este stack durante un mes, me alegra contarte que este único entorno con carga mínima costó menos de USD 80. Por supuesto, varios entornos y un mayor uso harán crecer el costo con el tiempo. La arquitectura serverless y otras decisiones, como la compresión de datos e incluso el diseño de datos serializados (arrays vs. hashes para eliminar datos redundantes), deberían mantener los costos operativos bastante bajos.
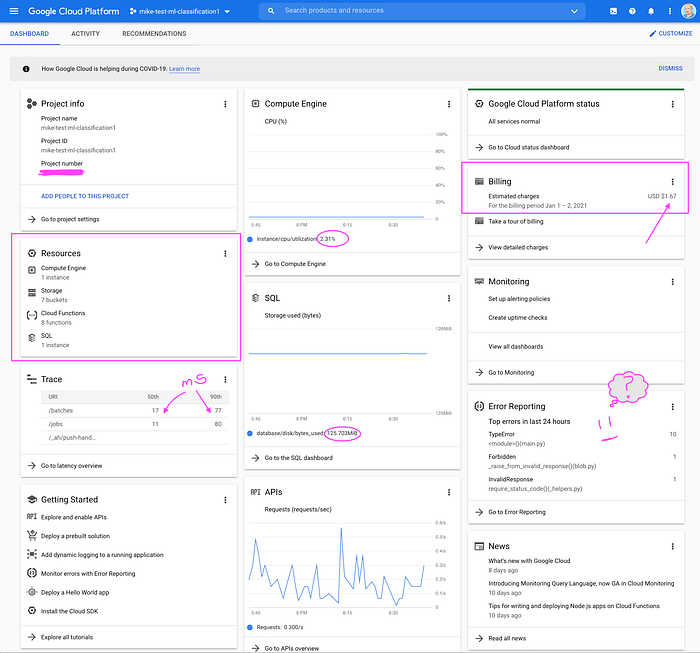
Un solo entorno corriendo un demo a costo muy bajo (hasta ahora)
Próximos pasos
Como mencioné en el primer artículo, dejamos fuera mucho contenido que normalmente se cubre en los tutoriales de ML. Este demo usa "aprendizaje supervisado" y crea un "clasificador binario", pero todos hemos oído hablar de redes neuronales, etc., que son tipos de aprendizaje distintos.
Eliminé a propósito ese "ruido" para que la atención inicial estuviera en una comprensión general. A medida que sigas avanzando en tu camino por la IA y el ML, aquí van algunos recursos útiles para entender mejor el tipo de problemas y soluciones que la IA y el ML pueden resolver:
- Elements of AI (curso gratuito en línea de la Universidad de Helsinki)
- Diagrama general de algoritmos (distintos tipos de herramientas y problemas)
- Cómo elegir el algoritmo correcto (buenos diagramas de los distintos tipos)
- Comparación de plataformas
Existen soluciones comerciales como Databricks, AI Platform o Sagemaker, y soluciones open source como ML Flow y Kubeflow. Cada una tiene sus pros y contras, además de costos adicionales, puntos de falla y curvas de aprendizaje.
Llegué a la conclusión de que, para entender de verdad cómo construir un pipeline de ML que sirva y reentrene predicciones, lo mejor es construir tú mismo los componentes (como aprender matemáticas a mano antes de depender de la calculadora). Espero que disfrutes estas reflexiones y que sean apenas una pequeña parte de tu recorrido en la IA.
Estoy agradecido de trabajar con un equipo de data scientists expertos, así que, a medida que vaya aprendiendo más, lo iré devolviendo con más artículos como este. Si te interesa sumarte a nuestro equipo en DoiT, visita nuestra página de carreras o escríbeme un mensaje por Twitter o LinkedIn.