自分だけのMLパイプラインを組み立てる
世の中のチュートリアルの多くは、ソリューション全体のごく一部しか扱っていません。モデルの学習・予測・分析をNotebook(後ほど触れます)で見せるものもあれば、モデルを配信するAPIの作り方を解説するものもあります。本記事ではあえて違うアプローチを取り、Webアプリ・API・ユーザー操作を起点とした自動再学習までを含む、エンドツーエンドのアプリケーション設計を紹介します。
事前準備:デモ動画
本シリーズの前編では、実際に動作するアプリの4分間デモと、機械学習の概念や用語の基礎を解説しています。後編では、MLパイプラインのデモを設計・構築する上で踏んだステップと、その過程で下した判断を見ていきます。
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
ソリューションの全体設計
まずは、リソース効率・スケーラビリティ・サブセカンドのレスポンスといった非機能要件を明確にするところから着手しました。多くの予測モデルはAPIで配信するだけでも十分機能します。ただし本記事では、パブリッククラウドのサービスを活用した分散型サーバーレスアーキテクチャの設計方法と、そうした設計を選ぶ理由を紹介していきます。
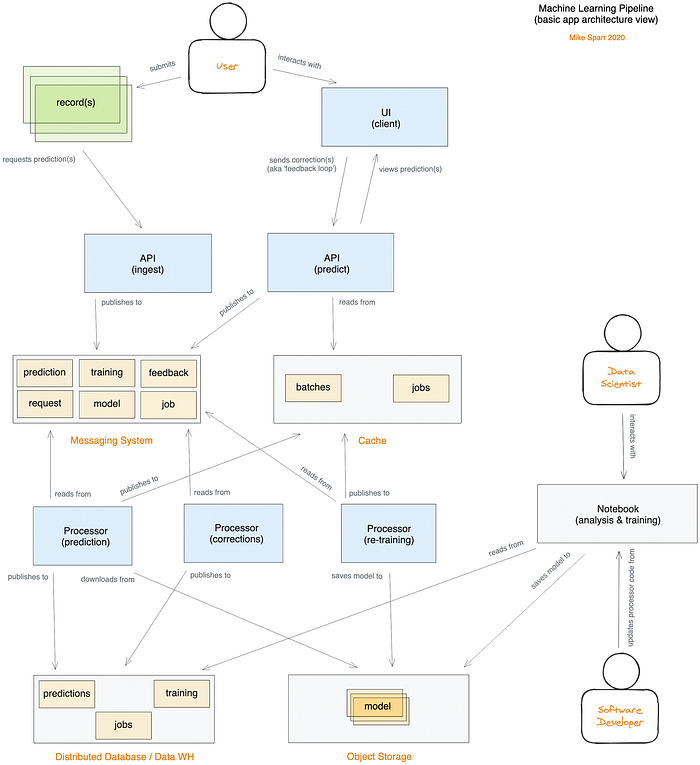
カスタムMLパイプラインのアーキテクチャ(パブリッククラウド上にホストする分散型サーバーレスアプリ)
ソフトウェアの経験が少しあるデータサイエンティストの方には、馴染みのない部分もあるかもしれません——お互い様ですね! ソースコードリポジトリを覗き、Notebookと対応する実コードを見ていただければ、パズルのピースが組み合わさってお役に立てるはずです。
まずは計画から
計画なしに進めると、多くの時間を無駄にしてしまいます。板を釘で打ち続ければいつか建物ができあがる、というのと同じで、図面を引き、資材を揃え、それから組み立てるほうがはるかに効率的です。ソフトウェア設計も基本的には変わりませんが、経験レベルによって必要な計画の種類は変わってきます。
アーキテクチャ・UI・APIの設計
このステップを飛ばしていない証拠として、感謝祭休暇中に描いたラフスケッチの写真を以下に掲載します。これが上のアーキテクチャ図の元になりました。その後、2020年12月の空き時間にデモアプリを構築しました。
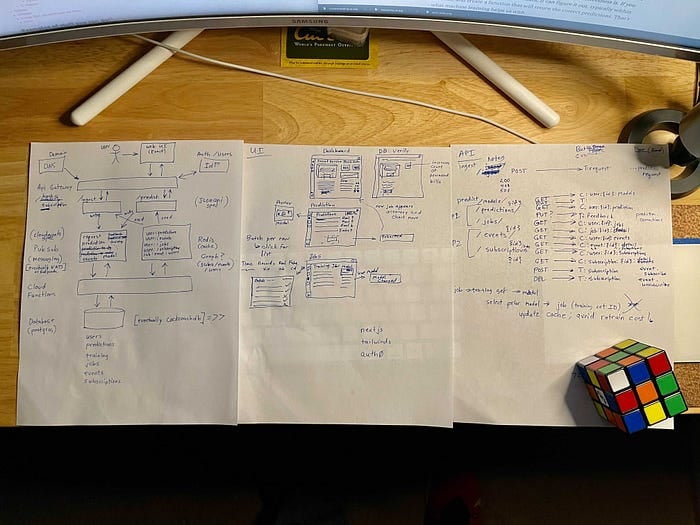
AIデモアプリのアーキテクチャ・UI・APIインターフェースの初期モックアップ
適切な機械学習アルゴリズムの選定
DoiT Internationalの同僚(弊社チームには多くのAIエキスパートやKaggleコンペティションマスターがいます)の協力を得て、サポートベクターマシン(SVM)の線形アルゴリズムを使ったバイナリ分類器でモデルを学習させることに決めました。下の動画でその仕組みを解説していますが、現時点でピンと来なくても問題ありません——アルゴリズムの内部動作を詳しく理解することは、最初の段階ではそれほど重要ではないと考えています。
データが線の片側にあれば「悪い」、もう片側にあれば「良い」。これが基本です。
今回は実プロジェクトを使う代わりに、デモ用の公開データセットを見つけ、それで一通り構築することにしました。後から自分のプロジェクト用にfeaturesを差し替えたり、セキュリティなど実際のスタートアップに必要な要素を追加したりすることも可能です。
採用した技術スタック
これまで複数の会社でシニアロールを務めていた関係で、新しいソフトウェア製品を実際にコーディングする機会はしばらくありませんでした。そこでまず感謝祭休暇の数日間を使って最新のツールやフレームワークを学び直し、自分なりの「スタック」を決めました。簡略化のためDevOps自動化は今回省きますが、別の機会に取り上げるかもしれません。
- UIレイヤー — Cloud Runでホストする NextJS/React + Chakra UI コンテナ
- APIレイヤー — Cloud Runでホストする Golang + Go-Chi コンテナ
- メッセージングレイヤー — Cloud Pub/Sub
- キャッシュレイヤー— Cloud Memorystore(Redis)
- プロセッサーレイヤー — Pub/SubトリガーのPython Cloud Functions
- データベースレイヤー — Cloud SQL(Postgres)
- ストレージレイヤー— Cloud Storage Buckets
関数で使うデータベースパスワードなどのシークレット保護には、Cloud Secret Managerを利用しています。普段はベンダーロックインを避ける設計を心がけていますが、Google Cloud Platformのマネージドサービスの多くはオープンソース製品をベースにしているため、後からOSSに「置き換える」のも比較的容易です。コード内にインターフェースを増やしておけば、サービスの差し替えもさらにスムーズになります。
「コードを見せろ」

本当に「コードを見せろ」「データサイエンス大好き」と言ったらしい
ソースコードとドキュメント
以下のGitHubソースコードリポジトリには、本シリーズ前編で紹介したデモアプリの実動コードが収められています。各リポジトリには、そのコンポーネントが全体アーキテクチャのどこに位置づけられるかの説明と、自分でインストール・実行する手順のドキュメントが付属しています。
- Web UI — システムの動作を可視化するユーザーフレンドリーなインターフェース
- Ingest API — 予測したいレコードのバッチを送信するAPI
- Predict API — バッチ予測を返し、ユーザーからの修正を受け取るAPI
- Processors — 予測・学習・データ永続化を担う非同期クラウドファンクション群(オリジナルのJupyter Notebook、学習済みモデル、データセット、データベーススキーマファイルも含む)
次のステップ(デモから本番アプリへの移行)としては、コードのリファクタリング(より堅牢に)、自動テストの追加、ページネーションの実装が挙げられます。続いてTerraformでインフラをプロビジョニングし、CI/CDパイプラインを整え、API Gatewayを前段に配置して認証・ロギング・トレーシング・レート制限を一元化していきたいところです。これらの工程をオープンソース化することにしたら、本シリーズの「第3回」として更新する予定です。;-)
商用ソリューションとの比較
本シリーズと上記のGitHubリポジトリを読み進めるうちに、最初は圧倒された部品や用語が次第に腹落ちしてくるはずです。腕試しとして、GoogleのAI Platformマネージドソリューションを示した下の図を見てみましょう。各ボックスを眺めて、いくつの用語の意味が分かるようになったでしょうか?
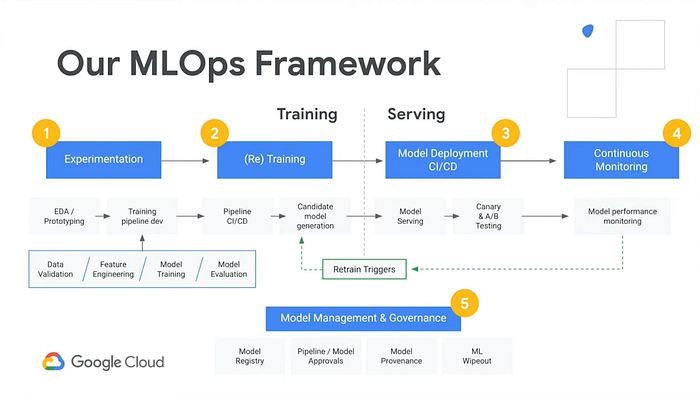
デモアプリのai-demo-functionsリポジトリを見ていくと、同様の機能が実装されていることが分かります。
- 「Experimentation(実験)」 — notebook.ipynbを参照
- 「(Re) Training(再学習)」 — /training/main.pyを参照
- 「Model Deployment(モデルのデプロイ)」「Model Serving(モデル配信)」 — /training/main.py、/prediction/main.py、/prediction-to-cache/main.pyを参照
- 「Continuous Monitoring(継続的モニタリング)」「Retrain Triggers(再学習トリガー)」 — /feedback-to-db/main.pyと/feedback-to-training/main.pyを参照
- 「Model Management & Governance(モデル管理とガバナンス)」 — /training-to-cache/main.pyとtraining-to-db/main.pyを参照
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
パフォーマンス
市場のソリューションを差別化する大きな要素のひとつがパフォーマンスです。本デモにおける設計判断の多くも、パフォーマンス目標に強く影響を受けています。
Pythonか、それ以外か?
初期実験を行ったJupyter Notebookでは、各処理にかかる時間を計測し、Python言語と選定したライブラリが要件を満たせるかを確認しました。
そのひとつが予測処理そのものです。ユーザー入力データをPandas DataFrameに読み込んで予測を実行したところ、約6ミリ秒かかりました。幸い同僚から「Numpy配列なら速くなるかも」とアドバイスをもらい、実際に試してみると予測時間は2ミリ秒まで短縮されました——個人的には大きな収穫です。
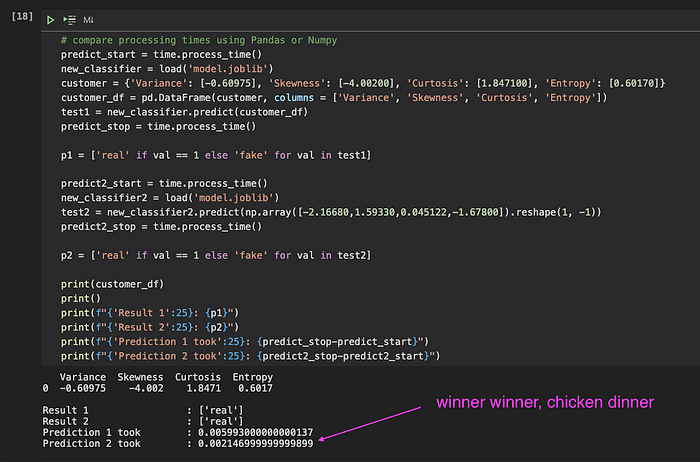
データ構造ごとの処理時間(とメモリ消費量)の比較
サーバーレス関数か、それ以外か?
もうひとつの懸念は、サーバーレス関数のコールドスタート時間と処理速度でした。いくつかのテスト関数を試した結果、ライブラリをプリロードする方法を見つけ、予測関数の実行時間を約8ミリ秒まで大幅に短縮できました。一連のテストから、PythonとGoogle Cloud Functionsで要件を満たせることが確認できました。
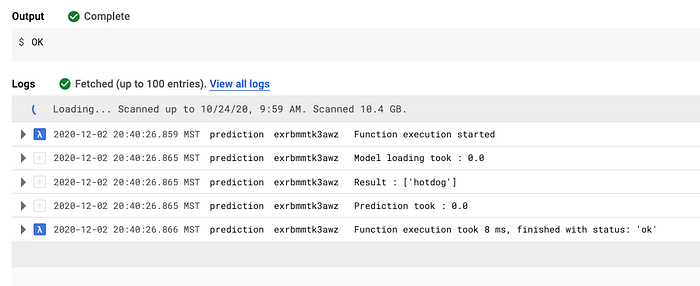
Cloud Function予測の実行時間に関する初期テスト(8ミリ秒)
もしモデルの学習時間やデータセットが違っていたら、固定のタイムアウトやメモリ制限を踏まえて別の判断をした可能性もあります。
- Cloud Functions — メモリ最大4Gb、最大9分の実行時間
- Cloud Run — メモリ最大8Gb、最大15分の実行時間(ベータ版で60分)
- Cloud Run(Anthos) — より大きなメモリ、最大24時間の実行(gke 16以上)
- 長時間ジョブにはGKEやVM上でのコンテナ実行を検討
プロのヒント
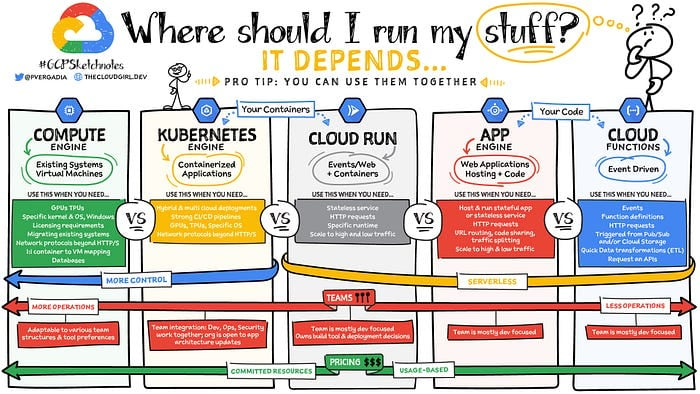
出典:Google(Priyanka Avergadia)
APIにコンテナを使うかどうか?
APIレイヤーにはGolangとGoogle Cloud Runを採用しました。GolangでCorporateを作ってみたかったのと、NodeJSと同様に少ないリソースで非常に高速な並行処理ができるからです。さらにDockerイメージのサイズが小さいため、負荷時のオートスケールも素早く行えます。加えて、強い型付けを持つ言語は「ゴミデータの混入」を抑え、動的型付けのPythonプロセッサーへ渡す前の防御層として機能します。
Apache Benchを使いgzip圧縮を試したところ、米国モンタナ州の自宅ネットワークからGoogleのus-central1サーバーへのリクエストで、ネットワーク転送量を82%削減し、リクエストあたり平均5.295ミリ秒を達成しました。別の同僚からはSnappyを勧められました。CPUコストを抑えつつ、十分なネットワーク最適化が得られる可能性があります(最適な組み合わせは試行錯誤で見つけるしかありません)。
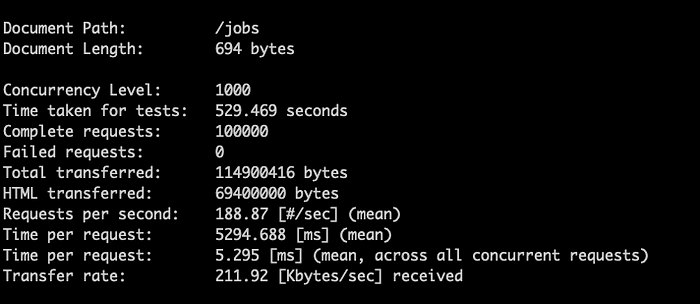
圧縮の有無によるAPIパフォーマンスのベンチマーク
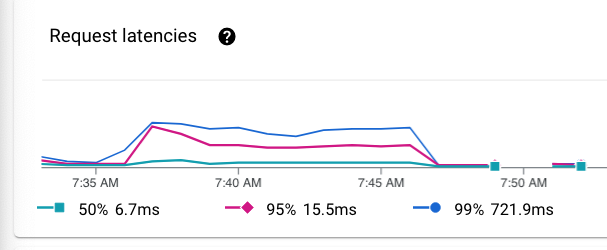
クラウドインフラのオーバーヘッドとリクエスト遅延の分析
Reactか、それ以外か? いくつかの会社ではWeb UIレイヤーにReactを使ってきましたが、Angularを採用していた会社もあります。VueJSなども追ってはいますが、個人的な経験が豊富で現職でも使っているReactを選びました。これまではcreate-react-appでReactアプリを立ち上げていましたが、NextJSを使うとSSRのパフォーマンスとルーティングの簡潔さが大きく向上するという報告が印象的でした。
Material UIか、それ以外か?
Material UI、Tailwind、そして最終的にChakra UIといったCSSフレームワークを数日かけて試しました。これまではSemantic UIを使ってきましたが、より新しいスタイリング手法を採用したものを試したかったのです。今回はChakra UIに軍配が上がったので、このデモはChakraで構築しています。
効率性とコストパフォーマンス
もうひとつの競争優位性となり得るのが、コスト効率です。これにより他社よりも競争力を高めつつ、より高い利益率を確保できます。普段からパブリッククラウドのインフラ最適化について他社にアドバイスする立場として、自分でも実践し、AIアプリのスタック全体をどこまで効率的に運用できるか、人とテクノロジー双方のニーズのバランスを取りながら検証してみました。
このスタックを1か月構築・運用してみたところ、最小負荷の単一環境であれば80ドル未満で済むことが確認できました。もちろん、複数環境の運用や使用量の増加に伴い、コストは時間とともに膨らんでいきます。とはいえ、サーバーレスアーキテクチャをはじめ、データ圧縮や、シリアライズ設計(重複データを排除するためにハッシュではなく配列を採用)といった選択により、運用コストはかなり低く抑えられるはずです。
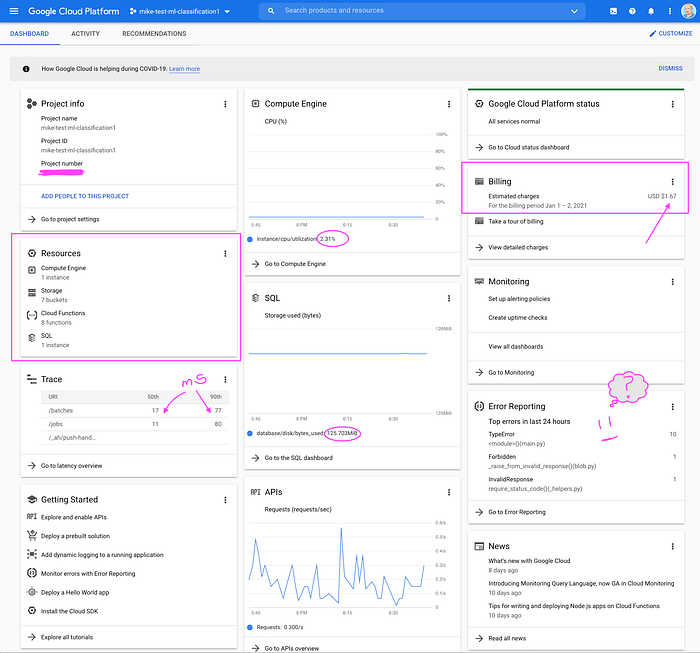
非常に低コストでデモを稼働させている単一環境(現時点では)
次のステップ
前編でも触れた通り、一般的なMLチュートリアルで扱う多くの内容は省略しています。本デモでは「教師あり学習」を用いて「バイナリ分類器」を作りましたが、ニューラルネットワークなど別の学習タイプの話もよく耳にしますね。
あえてこの「ノイズ」を取り除き、まずは全体像の把握に集中できるようにしました。AIやMLの旅を続ける皆さんに向けて、AIやMLが解決し得る問題やソリューションをより幅広く理解するための有用なリソースをいくつか紹介します。
- Elements of AI(ヘルシンキ大学による無料オンラインコース)
- アルゴリズム概要図(さまざまなツールと問題の種類)
- 適切なアルゴリズムの選び方(種類別の分かりやすい図)
- プラットフォーム比較
商用ソリューションにはDatabricks、AI Platform、Sagemakerなどがあり、オープンソースにはML FlowやKubeflowがあります。それぞれにメリット・デメリットがあり、追加コスト・障害ポイント・学習コストも伴います。
予測の配信と再学習を行うMLパイプラインの構築方法を本当の意味で理解するには、自分でコンポーネントを組み立ててみるのが一番だと考えました(電卓に頼る前に、まず手で計算して数学を学ぶようなものです)。本記事の知見が、皆さんのAIの旅のささやかな一片としてお役に立てば幸いです。
エキスパートのデータサイエンティストチームと働けることに感謝しています。学んだことは、こうした記事を通じて「ペイ・イット・フォワード」していくつもりです。DoiTのチームに参加してみたい方は、ぜひ採用ページをご覧いただくか、TwitterやLinkedInでメッセージをお送りください。