Une perspective stratégique pour déployer l'IA vocale temps réel à l'ère de la generative AI en entreprise

La prochaine frontière : pourquoi la voix, pourquoi maintenant ?
L'IA conversationnelle a atteint un point d'inflexion. La voix n'est plus une curiosité : c'est le canal le plus humain, le plus efficace et le plus fin émotionnellement pour qu'une entreprise dialogue avec ses clients, ses collaborateurs et ses partenaires. Aujourd'hui, l'IA générative speech-to-speech rend enfin ces expériences vocales concrètes, scalables et économiquement viables. Le moment d'agir, c'est maintenant.
Pourquoi maintenant ?
Pourquoi tout cela se cristallise-t-il aujourd'hui ? Plusieurs évolutions clés convergent :
- Les grands modèles de langage unifiés speech-to-speech, comme Amazon Nova Sonic, fusionnent reconnaissance vocale, raisonnement et génération vocale dans une architecture unique en temps réel
- La latence chute fortement, tandis que la qualité des conversations progresse
- Clients et collaborateurs attendent plus que jamais des interactions vocales fluides
La maturité des technologies génératives, combinée à des attentes croissantes, redéfinit le champ du possible — et celui de la compétitivité.
Qu'est-ce qu'un assistant vocal IA ?
Un assistant vocal IA est un agent conversationnel capable d'écouter, de raisonner et de répondre dans un langage parlé naturel, en gérant en temps réel des dialogues complexes à plusieurs tours. Conçus avec un niveau de sécurité et de gouvernance adapté à l'entreprise, ces assistants n'ont plus rien à voir avec les bots scriptés d'hier.
Ils savent :
- Répondre avec fluidité, sans pauses robotiques
- Refléter l'émotion et le ton
- Saisir les nuances de l'intention utilisateur
- S'intégrer aux référentiels de connaissances de l'entreprise et déclencher des actions
Autant d'atouts qui les rendent idéaux pour les entretiens RH, le service client, les appels commerciaux proactifs ou le coaching des collaborateurs.
La valeur métier de l'IA générative vocale
Pour les dirigeants qui évaluent l'IA vocale, la promesse est convaincante :
- Réduire les coûts opérationnels en automatisant les interactions vocales courantes
- Améliorer la satisfaction client grâce à des conversations plus naturelles et empathiques
- Servir les utilisateurs 24h/24, dans toutes les langues et sur toutes les zones géographiques
- Ouvrir de nouvelles sources de revenus via une approche vocale proactive
- Outiller les collaborateurs avec des assistants vocaux de connaissance disponibles à la demande
La voix est le canal préféré des utilisateurs. L'IA générative la rend enfin scalable, sécurisée et homogène.
Du STT→LLM→TTS au speech-to-speech unifié : un changement de paradigme
Historiquement, les systèmes d'IA vocale reposent sur un pipeline en cascade de composants distincts. On le représente souvent par STT→LLM→TTS, soit Speech-to-Text→Large Language Model→Text-to-Speech. Dans un assistant vocal ou un bot d'appel classique, l'entrée vocale franchit les étapes suivantes :
- Reconnaissance automatique de la parole (ASR) : la parole de l'utilisateur est convertie en texte via un modèle speech-to-text (Amazon Transcribe, Google Speech API, etc.).
- Compréhension du langage / traitement par le LLM : le texte transcrit est transmis à un modèle de langage ou à un gestionnaire de dialogue (par exemple un LLM), qui produit une réponse textuelle à partir de la requête et du contexte.
- Synthèse vocale (TTS) : la réponse textuelle de l'IA est convertie en audio par un moteur de synthèse vocale (Amazon Polly, WaveNet de Google, etc.).
- Lecture audio : la voix synthétisée est restituée à l'utilisateur.
Chacune de ces étapes mobilise généralement des modèles ou des services distincts, à orchestrer dans un ordre précis. Le framework open source Pipecat de Daily (utilisé dans les architectures de référence AWS) en est une bonne illustration : il combine WebRTC pour le streaming audio, un détecteur d'activité vocale (pour repérer quand l'utilisateur parle), Amazon Transcribe pour l'ASR, un LLM (modèle texte Amazon Nova) pour la NLU/NLG et Amazon Polly pour le TTS. La Figure 1 ci-dessous présente une telle architecture vocale en cascade dans un contexte d'entreprise, où plusieurs services AWS coopèrent pour traiter une requête utilisateur de bout en bout.
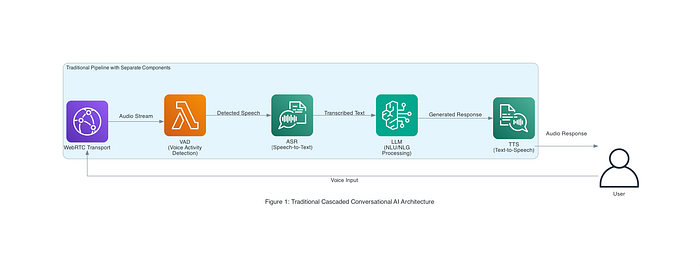
Figure 1 : architecture conversationnelle traditionnelle en cascade (référence AWS Pipecat). L'entrée vocale circule via le transport WebRTC, la VAD (détection d'activité vocale), l'ASR (speech-to-text), un LLM pour la NLU/NLG, et le TTS pour la réponse. Chaque composant ajoute du temps de traitement et autant de points de défaillance potentiels.
Ce pipeline modulaire a l'avantage de tirer parti de composants spécialisés pour chaque tâche, mais il s'accompagne d'inconvénients. Les transferts entre services introduisent de la latence : l'utilisateur doit souvent finir de parler avant que l'IA ne commence à formuler sa réponse, d'où des silences perceptibles. Chaque composant peut aussi générer des erreurs (transcription imparfaite, sortie TTS au rendu robotique), qui s'accumulent et dégradent la qualité globale de la conversation. Maintenir une cohérence conversationnelle devient compliqué lorsque l'ASR et le TTS ignorent leurs nuances mutuelles ou la tonalité émotionnelle de l'échange. En somme, les interactions paraissent moins naturelles à cause des délais système et de la juxtaposition de briques disjointes.
Amazon Nova Sonic : une rupture technologique
Amazon Nova Sonic marque un grand pas en avant. Plutôt que d'assembler des composants distincts pour la transcription, le raisonnement et la synthèse vocale, Nova Sonic unifie l'ensemble du processus conversationnel dans un pipeline unique, fluide et sécurisé.
En un coup d'œil, Nova Sonic sait :
- Écouter et comprendre en temps réel
- Générer des réponses au rendu humain
- S'exprimer avec des voix expressives et adaptatives
- Exécuter des appels de fonctions pour passer à l'action
- Ancrer ses réponses dans la connaissance de l'entreprise
Le service est exposé sous forme d'API via Bedrock : pas besoin d'héberger ou d'entraîner les modèles soi-même. Cette simplicité lève les freins à la mise en production, y compris dans des environnements régulés ou particulièrement sensibles.
De la vision à l'exécution : comment DoiT vous accompagne
Chez DoiT International, nous estimons que toute initiative d'IA vocale réussie repose sur trois piliers essentiels :
✅ Une conversation naturelle, propulsée par les capacités speech-to-speech unifiées de Nova Sonic
✅ Une infrastructure temps réel bâtie sur WebRTC sécurisé, le streaming et des microservices conteneurisés
✅ Des contrôles de niveau entreprise pour la conformité, la gouvernance et la supervision
Nos équipes aident les organisations à concrétiser ces piliers grâce à un framework éprouvé qui transforme la recherche en déploiements réels, sécurisés et scalables.
Comment cela s'articule :
Le blueprint de référence combine un front-end WebRTC sécurisé, des microservices conteneurisés sur AWS Fargate et un backend Nova Sonic géré via Bedrock pour des conversations vocales temps réel. Une IAM basée sur les rôles, une gestion sécurisée des secrets, une distribution CloudFront et une observabilité complète viennent parachever le design pour assurer la confiance à grande échelle.
Pour aller plus loin, consultez notre dépôt GitHub de référence. À noter : ce dépôt est destiné à des fins d'évaluation et de test uniquement et n'est pas encore prêt pour un déploiement en production.
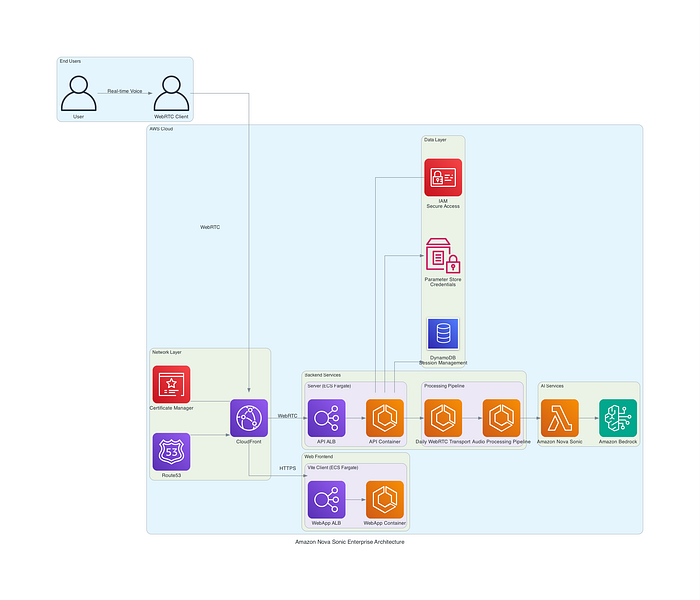
Figure 1 : schéma d'architecture haut niveau présentant l'intégration complète entre les composants front-end, les services back-end et les ressources cloud AWS.
Composants de l'architecture AWS
L'implémentation Nova Sonic s'appuie sur plusieurs services AWS clés :
- Service Nova Sonic ✅ Capacités IA speech-to-speech centrales
✅ Traitement audio temps réel
✅ Génération de réponses en streaming
✅ Options de personnalisation vocale 2. Amazon Bedrock ✅ Intégration de modèles de fondation
✅ Génération de réponses contextualisées
✅ Capacités d'appel de fonctions
✅ Gestion des connaissances 3. Services de conteneurs ✅ ECS Fargate pour les services back-end conteneurisés
✅ Auto-scaling en fonction de la demande
✅ Optimisation des ressources
✅ Automatisation des déploiements 4. Services support ✅ CloudFront pour la diffusion mondiale de contenu
✅ DynamoDB pour la gestion des états
✅ S3 pour le stockage des enregistrements
✅ CloudWatch pour l'observabilité
Points d'intégration clés
L'architecture s'organise autour de plusieurs points d'intégration critiques :
- Intégration front-end / back-end ✅ Signalisation WebRTC via des endpoints FastAPI
✅ Échange sécurisé des identifiants de room
✅ Initialisation des flux multimédias
✅ Synchronisation de l'état des connexions 2. Intégration back-end / AWS ✅ Authentification sécurisée aux services AWS
✅ Connexions en streaming vers Nova Sonic
✅ Synchronisation d'état avec DynamoDB
✅ Intégration du monitoring avec CloudWatch 3. Intégration des composants du pipeline ✅ Interfaces de frames standardisées
✅ Communication événementielle
✅ Flux de données bidirectionnel
✅ Architecture modulaire des composants
Considérations de sécurité et de scalabilité
L'implémentation intègre des fonctionnalités de sécurité et de mise à l'échelle de niveau entreprise :
- Mesures de sécurité ✅ Authentification de room par token
✅ Transmission multimédia chiffrée
✅ Gestion sécurisée des credentials
✅ Contrôle d'accès basé sur les rôles 2. Stratégie de scaling ✅ Mise à l'échelle horizontale des services back-end
✅ Pooling des connexions pour une utilisation optimale des ressources
✅ Déploiement régional pour une couverture mondiale
✅ Auto-scaling piloté par les métriques de connexion 3. Mécanismes de résilience ✅ Reconnexion automatique
✅ Dégradation contrôlée en cas d'incident de service
✅ Gestion exhaustive des erreurs
✅ Mécanismes de récupération de session
Cette architecture constitue un blueprint pour les organisations qui souhaitent déployer Nova Sonic en environnement entreprise, avec une attention particulière à la sécurité, à la scalabilité et à l'intégration aux systèmes existants.
Architecture du pipeline de traitement vocal
La capacité de rupture d'Amazon Nova Sonic repose sur un pipeline de traitement vocal avancé, capable d'interactions speech-to-speech quasi temps réel. Contrairement aux assistants vocaux classiques qui attendent la fin d'un énoncé avant de répondre, Nova Sonic traite en continu les flux audio dans les deux sens, pour des conversations naturelles à latence minimale.
Le pipeline de traitement vocal comprend les composants clés suivants :
- Couche de capture et de streaming audio ✅ Protocole WebRTC pour la transmission audio temps réel
✅ Traitement audio dans le navigateur avec annulation d'écho et réduction de bruit
✅ Encodage à débit adaptatif selon les conditions réseau 2. Composant de reconnaissance vocale ✅ ASR (reconnaissance automatique de la parole) en streaming continu
✅ Reconnaissance phonémique à faible latence
✅ Modélisation linguistique contextuelle pour une précision accrue 3. Moteur de traitement sémantique ✅ Détection d'intention en temps réel pendant que l'utilisateur parle
✅ Gestion du contexte multi-tours pour la cohérence de la conversation
✅ Formulation et optimisation des requêtes pour l'interaction avec le LLM 4. Backend IA générative Nova Sonic ✅ Génération de tokens en streaming avec un buffering minimal
✅ Synthèse vocale neuronale avec personnalisation des voix
✅ Contrôle de la prosodie et du ton pour un rendu vocal naturel 5. Génération et mixage de la sortie ✅ Mixage audio dynamique pour une conversation sans rupture
✅ Techniques d'optimisation de la latence
✅ Boucle de feedback temps réel pour le contrôle de la qualité audio
Flux de communication WebRTC
L'implémentation WebRTC met en place des flux audio bidirectionnels sécurisés et à faible latence entre l'application cliente et le service Nova Sonic :
- Établissement de session ✅ Le protocole ICE (Interactive Connectivity Establishment) identifie les meilleurs chemins réseau
✅ Les serveurs STUN/TURN facilitent le franchissement de NAT
✅ Le SDP (Session Description Protocol) négocie les capacités multimédias 2. Transmission multimédia sécurisée ✅ DTLS (Datagram Transport Layer Security) assure le chiffrement
✅ SRTP (Secure Real-time Transport Protocol) sécurise le streaming audio
✅ Adaptation de la bande passante en fonction du réseau 3. Traitement audio ✅ Traitement audio côté client (annulation d'écho, suppression de bruit)
✅ Amélioration audio côté serveur
✅ Techniques de compensation de la perte de paquets
Architecture AWS et orchestration des fonctions
L'implémentation tire parti de plusieurs services AWS au sein d'une architecture scalable et résiliente :
- Composants côté client ✅ Distribution CloudFront pour la diffusion mondiale
✅ Application Load Balancer pour la répartition du trafic
✅ ECS Fargate pour l'hébergement d'applications conteneurisées 2. Pipeline de traitement ✅ Amazon Bedrock pour les capacités d'IA générative
✅ Amazon Transcribe pour la reconnaissance vocale
✅ Amazon Polly pour la synthèse vocale
✅ Fonctions Lambda personnalisées pour l'orchestration 3. Services back-end ✅ DynamoDB pour la gestion des sessions et des métadonnées
✅ Parameter Store pour la gestion sécurisée des credentials
✅ CloudWatch pour la journalisation et le monitoring complets 4. Couche de sécurité ✅ Certificats ACM pour le chiffrement TLS
✅ Rôles IAM pour un contrôle d'accès fin
✅ AWS WAF pour la protection web (firewall applicatif)
L'implémentation AWS s'appuie sur l'infrastructure as code (IaC) via AWS CDK, ce qui rend les déploiements reproductibles et les environnements cohérents. L'architecture suit les principes de l'AWS Well-Architected Framework en matière de sécurité, de fiabilité, d'efficacité de la performance, d'optimisation des coûts et d'excellence opérationnelle.
Optimisation des performances
La performance à faible latence de Nova Sonic résulte de plusieurs optimisations techniques :
- Optimisation de l'inférence en streaming ✅ Traitement parallèle des chunks audio
✅ Stratégies de buffering adaptatives
✅ Génération précoce de la réponse à partir d'entrées partielles 2. Réduction de la latence réseau ✅ Modèle de déploiement edge computing
✅ Pooling des connexions vers les services back-end
✅ Déploiement régional pour la proximité avec les utilisateurs finaux 3. Mise à l'échelle des ressources ✅ Auto-scaling des services ECS selon la demande
✅ Capacité réservée pour des performances stables
✅ Répartition des workloads entre zones de disponibilité
Implémentation des composants front-end
L'implémentation front-end de Nova Sonic illustre comment les technologies web modernes permettent des interactions vocales temps réel à latence minimale. Le code du dossier /vite-client propose une approche prête pour la production pour bâtir des interfaces d'IA vocale naturelles et réactives.
Implémentation du client WebRTC
L'implémentation WebRTC côté client est encapsulée dans la classe ChatbotClient du fichier app.js, qui gère le cycle de vie de la connexion et le traitement des médias :
class ChatbotClient {
constructor() {
// Initialize client state
this.rtviClient = null;
this.videoManager = null;
this.setupDOMElements();
this.setupEventListeners();
this.initializeClientAndTransport();
}
// ...
}
L'implémentation s'appuie sur des bibliothèques spécialisées :
@pipecat-ai/client-js: fournit la classeRTVIClientpour les interactions vocales temps réel@pipecat-ai/daily-transport: permet la communication WebRTC via l'infrastructure Daily.co. Les 10 000 premières minutes participant sont gratuites.
Caractéristiques principales de l'implémentation WebRTC :
- Abstraction de la couche de transport ✅ Encapsulation de la complexité WebRTC derrière une interface de transport
✅ Prise en charge automatique de la négociation des candidats ICE
✅ Stratégies de reconnexion transparentes en cas de coupure réseau 2. Gestion des flux multimédias ✅ Souscription et désinscription dynamiques aux pistes
✅ Négociation automatique du format des médias
✅ Qualité multimédia optimisée selon les conditions de bande passante 3. Gestion de l'état des connexions ✅ Transitions d'état robustes (connexion en cours, connecté, déconnecté)
✅ Architecture événementielle pour des mises à jour réactives de l'UI
✅ Gestion exhaustive des erreurs en cas d'échec de connexion
Composants de gestion du microphone et de la caméra
Le projet met en œuvre une gestion avancée des périphériques multimédias via la classe VideoManager, qui propose :
- Initialisation des périphériques et flux d'autorisation ✅ Demandes d'accès caméra ergonomiques
✅ Gestion détaillée des erreurs en cas de refus
✅ Retour visuel pendant l'initialisation des périphériques 2. Gestion des pistes multimédias ✅ Traitement séparé des pistes locales et distantes
✅ Optimisation de la qualité des flux vidéo
✅ Nettoyage automatique des pistes à la déconnexion 3. Intégration aux éléments multimédias ✅ Création et configuration dynamiques des éléments audio/vidéo
✅ Adaptation responsive de la mise en page
✅ Réglages de lecture optimisés pour la faible latence
L'exemple suivant, tiré de VideoManager.js, montre comment les flux caméra sont initialisés :
async toggleLocalCamera() {
try {
// Request camera access through the browser
const stream = await navigator.mediaDevices.getUserMedia({
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
});
// Store the stream for later use
this._localStream = stream;
// Update the local video element with this stream
this.localVideo.srcObject = stream;
// Ensure the video plays
await this.localVideo.play();
} catch (error) {
// Handle permission errors with user-friendly messaging
}
}
Interface utilisateur pour l'interaction vocale
L'interface utilisateur est pensée pour une interaction vocale intuitive avec les caractéristiques suivantes :
- Contrôles de connexion ✅ Indicateurs visuels clairs sur l'état de la connexion
✅ Connexion/déconnexion en un clic
✅ Interface de gestion des autorisations 2. Retour visuel ✅ Affichage de la transcription en temps réel
✅ Indicateurs visuels animés pendant la prise de parole du bot
✅ Indicateurs de statut de connexion 3. Capacités de debug ✅ Interface de logs complète
✅ Suivi des statistiques réseau
✅ Visualisation des niveaux audio
Principales technologies et bibliothèques front-end
L'implémentation front-end s'appuie sur plusieurs technologies web modernes :
- Vite — pour un développement rapide et des builds de production optimisés
- API WebRTC — pour la communication audio/vidéo temps réel
- Media Streams API — pour accéder aux caméras et microphones des appareils
- Conteneurisation — configuration Docker pour un déploiement homogène
- Nginx — pour le service de fichiers statiques et le proxy optionnel
Gestion de la connexion avec le back-end
La connexion front-end / back-end repose sur un protocole robuste qui :
- Établit des connexions sécurisées par room ✅ Récupère les identifiants de room depuis l'endpoint
/connectdu back-end
✅ Sécurise les connexions par token
✅ Traite les événements participants (arrivée, départ) 2. Gère efficacement la transmission des médias ✅ Adaptation de la bande passante
✅ Gestion des transitions réseau
✅ Métriques de qualité et diagnostics 3. Optimise la latence pour l'interaction vocale ✅ Configure les éléments audio pour minimiser le délai de traitement
✅ Optimise le buffering audio
✅ Recourt à l'accélération matérielle quand elle est disponible
Cette architecture permet d'atteindre la latence critique inférieure à 300 ms qui rend les conversations Nova Sonic naturelles et fluides.
Implémentation des composants back-end
L'implémentation côté serveur, dans le dossier /server, montre comment construire un back-end scalable et prêt pour la production destiné aux applications d'IA vocale Nova Sonic. Elle illustre les schémas d'intégration et les choix d'architecture nécessaires pour déployer des solutions d'IA vocale de niveau entreprise.
WebRTC via l'implémentation Daily Transport
Le back-end s'appuie sur l'infrastructure Daily.co pour gérer les sessions WebRTC à travers une implémentation de transport spécialisée :
# Set up Daily transport with video/audio parameters
transport = DailyTransport(
room_url,
token,
"Chatbot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
video_in_enabled=True,
video_out_enabled=True,
video_out_width=1024,
video_out_height=576,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=True,
),
)
Caractéristiques principales de cette implémentation de transport :
- Gestion des rooms ✅ Création dynamique de rooms sécurisées
✅ Authentification par token
✅ Nettoyage automatique des ressources inutilisées 2. Configuration des médias ✅ Contrôle indépendant des entrées/sorties audio et vidéo
✅ Réglages de résolution et de qualité
✅ Intégration de la détection d'activité vocale (VAD) 3. Gestion des événements ✅ Système d'événements complet pour les changements d'état du transport
✅ Gestion du cycle de vie des participants
✅ Contrôle et gestion des enregistrements
Patterns d'appels de fonctions pour l'intégration d'outils
L'implémentation illustre des patterns avancés d'appel de fonctions qui permettent l'intégration d'outils avec le LLM :
# Register functions with the LLM service
register_functions(llm)
# Set up context with function schemas
context = OpenAILLMContext(
messages=[\
{"role": "system", "content": f"{system_instruction}"},\
{\
"role": "user",\
"content": "Hello, I'm here for my interview.",\
},\
],
tools=function_tools_schema,
)
Cette architecture permet :
- Système d'enregistrement d'outils ✅ Enregistrement dynamique des schémas de fonctions
✅ Interfaces de fonctions typées
✅ Prise en charge des fonctions synchrones et asynchrones 2. Gestion du contexte ✅ Préservation du contexte conversationnel d'une interaction à l'autre
✅ Fenêtrage efficace du contexte pour les longues conversations
✅ Suivi conversationnel avec état 3. Exécution des fonctions ✅ Exécution sécurisée des fonctions outils
✅ Gestion des erreurs et mécanismes de retry
✅ Intégration des résultats dans le contexte de la conversation
Architecture du pipeline et composants
Le back-end met en œuvre une architecture de pipeline avancée à l'aide du framework Pipecat :
pipeline = Pipeline(
[\
transport.input(),\
rtvi,\
context_aggregator.user(),\
llm,\
ta,\
transport.output(),\
context_aggregator.assistant(),\
]
)
Cette approche en pipeline apporte :
- Chaîne de traitement modulaire ✅ Séparation claire des responsabilités
✅ Composants pluggables pour la personnalisation
✅ Interfaces de traitement de frames standardisées 2. Flux de données bidirectionnel ✅ Traitement des entrées de l'utilisateur vers le système
✅ Traitement des sorties du système vers l'utilisateur
✅ Propagation des événements dans les deux sens 3. Intégration de l'observabilité ✅ Collecte de métriques au niveau du pipeline
✅ Diagnostics au niveau des composants
✅ Points de monitoring des performances
Traitement et gestion de l'audio
L'implémentation comprend des capacités de traitement audio avancées :
- Détection d'activité vocale ✅ Détection d'activité vocale par ML, basée sur Silero VAD
✅ Ajustement dynamique du seuil
✅ Détection vocale robuste au bruit 2. Gestion de la transcription ✅ Conversion speech-to-text en temps réel
✅ Prise en charge des résultats partiels pour un retour immédiat
✅ Synchronisation du transcript final 3. Optimisation de la sortie audio ✅ Mixage dynamique des flux audio
✅ Techniques de gestion de la latence
✅ Synchronisation de la lecture
Intégration avec les services AWS Nova Sonic
Le cœur de l'implémentation, c'est l'intégration aux services AWS Nova Sonic :
# Initialize AWS Nova Sonic LLM service
llm = AWSNovaSonicLLMService(
secret_access_key=NOVA_AWS_SECRET_ACCESS_KEY,
access_key_id=NOVA_AWS_ACCESS_KEY_ID,
region=os.getenv("NOVA_AWS_REGION", "us-east-1"),
voice_id=os.getenv("NOVA_VOICE_ID", "tiffany"),
send_transcription_frames=True
)
Cette intégration met en avant :
- Authentification sécurisée ✅ Gestion des credentials AWS
✅ Contrôle d'accès basé sur les rôles
✅ Gestion sécurisée des variables d'environnement 2. Personnalisation vocale ✅ Sélection et configuration de la voix
✅ Caractéristiques prosodiques et vocales
✅ Options de support multilingue 3. Optimisation du streaming ✅ Streaming de tokens en temps réel
✅ Génération progressive des réponses
✅ Configuration à latence minimale 4. Fonctionnalités avancées ✅ Intégration des frames de transcription
✅ Réponses contextualisées
✅ Gestion des interruptions
Plan d'action exécutif pour l'IA générative vocale
Voici un guide pratique pour démarrer :
- Identifier les expériences clients ou collaborateurs qui gagneraient le plus à des interactions vocales plus rapides et plus naturelles
- Bâtir un business case axé sur les coûts, l'expérience ou les revenus additionnels
- Évaluer les partenaires capables de combiner les bonnes expertises cloud, IA et sécurité
- Lancer un pilote et mesurer les résultats avec des critères de succès clairs
- Mettre en place les contrôles de gouvernance et de sécurité pour passer à l'échelle
- Déployer par étapes, en s'appuyant sur l'infrastructure-as-code et des patterns d'observabilité éprouvés
Et après ?
La voix est l'interface la plus naturelle dont nous disposions. Grâce à l'IA générative, elle peut désormais rivaliser de scalabilité, de sécurité et d'intelligence avec les systèmes textuels. L'avenir de l'engagement client et collaborateur s'écrira autour de conversations vocales au rendu humain.
Pour les organisations en pointe, le moment d'investir, c'est maintenant.
Chez DoiT International, nous combinons une expertise approfondie du cloud, de la sécurité et de l'IA générative pour faire de vos solutions vocales un succès durable, à grande échelle.
Construisons ensemble la prochaine génération d'IA conversationnelle. Contactez DoiT International dès aujourd'hui !