Uma perspectiva estratégica para implementar IA voice-first em tempo real na era da IA generativa

A próxima fronteira: por que voz, por que agora?
A IA conversacional chegou a um ponto de inflexão. A voz deixou de ser novidade. É a forma mais humana, eficiente e emocionalmente inteligente de as empresas se conectarem com clientes, colaboradores e parceiros. Hoje, a IA generativa speech-to-speech finalmente torna essas experiências voice-first práticas, escaláveis e com bom custo-benefício. A hora de mudar é agora.
Por que agora?
Por que isso está acontecendo agora? Várias mudanças importantes estão convergindo:
- Modelos de linguagem unificados speech-to-speech, como o Amazon Nova Sonic, reúnem reconhecimento de fala, raciocínio e geração de fala em uma única arquitetura em tempo real
- A latência cai drasticamente, enquanto a qualidade da conversa melhora
- Clientes e colaboradores esperam, mais do que nunca, interações fluidas baseadas em voz
A combinação entre uma tecnologia generativa madura e expectativas crescentes está redefinindo o que é possível — e o que é competitivo.
O que é um assistente de voz com IA?
Um assistente de voz com IA é um agente conversacional capaz de ouvir, raciocinar e responder em linguagem falada natural, conduzindo diálogos complexos de múltiplas etapas em tempo real. Projetados com segurança e governança de nível empresarial, esses assistentes vão muito além dos bots tradicionais baseados em scripts.
Eles são capazes de:
- Responder com fluidez, sem pausas robóticas
- Refletir emoção e tom
- Entender intenções sutis do usuário
- Integrar-se ao conhecimento da empresa e executar ações
Isso os torna ideais para casos como entrevistas de RH, atendimento ao cliente, ligações proativas de vendas ou coaching de colaboradores.
O valor de negócio da IA generativa por voz
Para líderes seniores que estão avaliando IA por voz, o argumento de negócio é convincente:
- Reduzir custos operacionais ao automatizar interações de voz rotineiras
- Aumentar a satisfação do cliente com conversas mais naturais e empáticas
- Atender usuários 24 horas por dia, em diferentes idiomas e regiões
- Abrir novas fontes de receita por meio de abordagens proativas por voz
- Dar autonomia aos colaboradores com assistentes de conhecimento por voz, instantâneos e sob demanda
A voz é o canal preferido das pessoas. A IA generativa finalmente a torna escalável, segura e consistente.
De STT→LLM→TTS para speech-to-speech unificado: uma mudança de paradigma
Tradicionalmente, sistemas de IA por voz são construídos a partir de um pipeline em cascata com componentes separados. Esse pipeline costuma ser representado como STT→LLM→TTS, ou seja, Speech-to-Text→Large Language Model→Text-to-Speech. Em um assistente de voz ou bot de chamada típico, a fala de entrada passa pelas seguintes etapas:
- Reconhecimento Automático de Fala (ASR): a fala do usuário é convertida em texto por um modelo speech-to-text (por exemplo, Amazon Transcribe ou Google Speech API).
- Compreensão de linguagem / processamento por LLM: o texto transcrito segue para um modelo de linguagem ou gerenciador de diálogo (como um LLM), que gera uma resposta em texto a partir da consulta e do contexto do usuário.
- Síntese de fala (TTS): a resposta em texto da IA é convertida em áudio falado por um motor de síntese de voz (por exemplo, Amazon Polly ou WaveNet, da Google).
- Reprodução de áudio: a fala sintetizada é reproduzida ao usuário como resposta.
Cada uma dessas etapas geralmente envolve modelos ou serviços distintos, que precisam ser orquestrados em sequência. O framework open-source Pipecat, da Daily (usado em arquiteturas de referência da AWS), exemplifica essa abordagem: integra WebRTC para streaming de áudio, um detector de atividade de voz (para identificar quando o usuário está falando), Amazon Transcribe para ASR, um LLM (modelo de texto Amazon Nova) para NLU/NLG e Amazon Polly para TTS. A Figura 1 abaixo ilustra essa arquitetura de IA por voz em cascata em um cenário corporativo, em que múltiplos serviços AWS atuam em conjunto para processar uma única consulta do usuário de ponta a ponta.
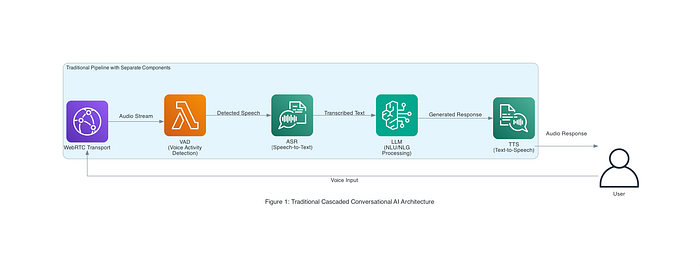
Figura 1: arquitetura tradicional de IA conversacional em cascata (referência AWS Pipecat). A entrada de voz percorre transporte WebRTC, VAD (detecção de atividade de voz), ASR (speech-to-text), um LLM para NLU/NLG e TTS para a resposta. Cada componente acrescenta tempo de processamento e potenciais pontos de falha.
Embora esse pipeline modular tenha a vantagem de aproveitar componentes especializados em cada tarefa, ele também traz desvantagens. As trocas entre serviços introduzem latência — em geral, o usuário precisa terminar de falar para que a IA comece a formular uma resposta, o que gera pausas perceptíveis. Cada componente também pode introduzir erros (como falhas de transcrição ou uma saída de TTS com som robótico) que se acumulam e reduzem a qualidade da conversa como um todo. Manter a coerência do diálogo é desafiador quando ASR e TTS desconhecem as nuances um do outro ou o tom emocional da conversa. Em resumo, as interações podem soar menos naturais por causa dos atrasos do sistema e da desarticulação entre as partes.
Amazon Nova Sonic: um avanço tecnológico
O Nova Sonic, da Amazon, representa um grande salto. Em vez de unir componentes separados de speech-to-text, raciocínio e text-to-speech, o Nova Sonic unifica todo o processo conversacional em um único pipeline simplificado e seguro.
De forma resumida, o Nova Sonic é capaz de:
- Ouvir e compreender em tempo real
- Gerar respostas com naturalidade humana
- Falar com vozes expressivas e adaptativas
- Executar function calls para realizar ações
- Embasar respostas no conhecimento da empresa
Ele é entregue como API por meio do Bedrock, então não é preciso hospedar nem treinar modelos por conta própria. Essa simplicidade derruba barreiras à adoção em produção, mesmo em ambientes regulados ou sensíveis à segurança.
Da visão à execução: como a DoiT ajuda
Na DoiT International, acreditamos que toda iniciativa bem-sucedida de IA por voz se apoia em três pilares essenciais:
✅ Conversa natural impulsionada pelas capacidades unificadas de speech-to-speech do Nova Sonic
✅ Infraestrutura em tempo real construída sobre WebRTC seguro, streaming e microsserviços conteinerizados
✅ Controles de nível empresarial para conformidade, governança e monitoramento
Nosso time ajuda as organizações a colocar esses pilares em prática com um framework bem arquitetado, transformando pesquisa em implantações seguras, escaláveis e prontas para o mundo real.
Como tudo se conecta:
O blueprint de referência reúne um front-end WebRTC seguro, microsserviços conteinerizados em AWS Fargate e um backend Nova Sonic gerenciado pelo Bedrock para conversas voz-a-voz em tempo real. IAM com controle por papéis, gerenciamento seguro de segredos, distribuição via CloudFront e observabilidade abrangente completam o desenho, dando confiança em escala.
Para mais informações, acesse nosso repositório de referência no GitHub. Vale lembrar que o repositório se destina apenas a avaliação e testes e ainda não é adequado para implantação em produção.
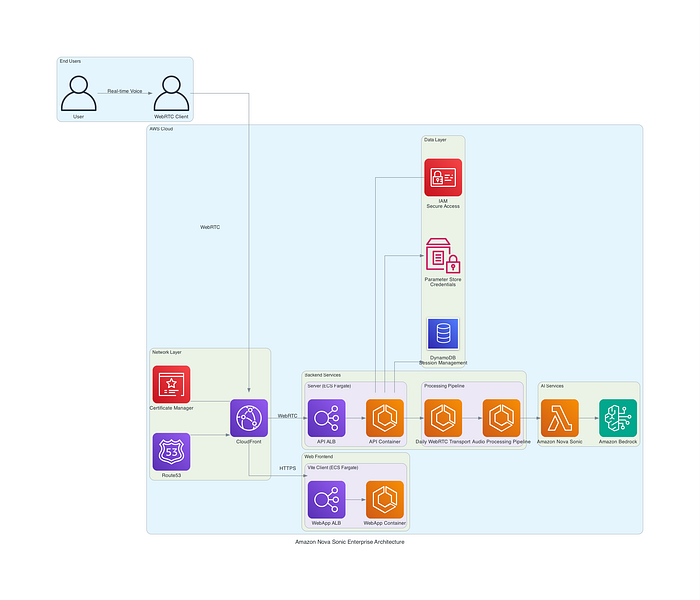
Figura 1: diagrama de arquitetura de alto nível mostrando a integração completa entre componentes de frontend, serviços de backend e recursos da nuvem AWS.
Componentes da arquitetura AWS
A implementação do Nova Sonic utiliza vários serviços-chave da AWS:
- Serviço Nova Sonic ✅ Capacidades centrais de IA speech-to-speech
✅ Processamento de áudio em tempo real
✅ Geração de respostas em streaming
✅ Opções de personalização de voz 2. Amazon Bedrock ✅ Integração com modelos de fundação
✅ Geração de respostas sensíveis ao contexto
✅ Capacidades de function calling
✅ Gestão de conhecimento 3. Serviços de contêineres ✅ ECS Fargate para serviços de backend conteinerizados
✅ Auto-scaling conforme a demanda
✅ Otimização de recursos
✅ Automação de implantação 4. Serviços de apoio ✅ CloudFront para entrega global de conteúdo
✅ DynamoDB para gerenciamento de estado
✅ S3 para armazenamento de gravações
✅ CloudWatch para observabilidade
Pontos-chave de integração
A arquitetura é construída em torno de vários pontos críticos de integração:
- Integração frontend-backend ✅ Sinalização WebRTC via endpoints FastAPI
✅ Troca segura de credenciais de sala
✅ Inicialização de fluxo de mídia
✅ Sincronização do estado de conexão 2. Integração backend-AWS ✅ Autenticação segura nos serviços AWS
✅ Conexões em streaming com o Nova Sonic
✅ Sincronização de estado com o DynamoDB
✅ Integração de monitoramento com o CloudWatch 3. Integração de componentes do pipeline ✅ Interfaces de frame padronizadas
✅ Comunicação orientada a eventos
✅ Fluxo de dados bidirecional
✅ Arquitetura modular de componentes
Considerações de segurança e escalabilidade
A implementação incorpora recursos de segurança e escalabilidade de nível empresarial:
- Medidas de segurança ✅ Autenticação de sala baseada em token
✅ Transmissão de mídia criptografada
✅ Gerenciamento seguro de credenciais
✅ Controle de acesso baseado em papéis 2. Estratégia de escalabilidade ✅ Escala horizontal dos serviços de backend
✅ Connection pooling para uso eficiente de recursos
✅ Implantação regional para cobertura global
✅ Auto-scaling com base em métricas de conexão 3. Recursos de resiliência ✅ Tratamento automático de reconexão
✅ Degradação graciosa durante interrupções de serviço
✅ Tratamento abrangente de erros
✅ Mecanismos de recuperação de sessão
Essa arquitetura serve como blueprint para organizações que querem implementar o Nova Sonic em ambientes corporativos, com atenção especial à segurança, à escalabilidade e à integração com sistemas existentes.
Arquitetura do pipeline de processamento de voz
A capacidade revolucionária do Amazon Nova Sonic se baseia em um pipeline avançado de processamento de voz que viabiliza interações speech-to-speech praticamente em tempo real. Diferentemente dos assistentes de voz tradicionais, que processam enunciados completos antes de responder, o Nova Sonic processa fluxos de áudio bidirecionalmente e de forma contínua, permitindo um fluxo de conversa natural com latência mínima.
O pipeline de processamento de voz é composto pelos seguintes componentes principais:
- Camada de captura e streaming de áudio ✅ Protocolo WebRTC para transmissão de áudio em tempo real
✅ Processamento de áudio no navegador, com cancelamento de eco e redução de ruído
✅ Codificação adaptativa de bitrate conforme as condições da rede 2. Componente de reconhecimento de fala ✅ ASR (Reconhecimento Automático de Fala) com streaming contínuo
✅ Reconhecimento em nível de fonema com baixa latência
✅ Modelagem de linguagem sensível ao contexto para maior precisão 3. Engine de processamento semântico ✅ Detecção de intenção em tempo real enquanto o usuário fala
✅ Gerenciamento de contexto multi-turno para coerência da conversa
✅ Formulação e otimização de consultas para a interação com o LLM 4. Backend de IA generativa Nova Sonic ✅ Geração de tokens em streaming com mínimo buffering
✅ Síntese de fala neural com personalização de voz
✅ Controle de prosódia e tom para uma fala natural 5. Geração e mixagem de saída ✅ Mixagem dinâmica de áudio para conversas fluidas
✅ Técnicas de otimização de latência
✅ Loop de feedback em tempo real para controle de qualidade do áudio
Fluxo de comunicação WebRTC
A implementação WebRTC viabiliza fluxos de áudio bidirecionais, seguros e de baixa latência entre o aplicativo cliente e o serviço Nova Sonic:
- Estabelecimento de sessão ✅ O protocolo ICE (Interactive Connectivity Establishment) identifica os melhores caminhos de rede
✅ Servidores STUN/TURN facilitam a travessia de NAT
✅ SDP (Session Description Protocol) negocia capacidades de mídia 2. Transmissão segura de mídia ✅ DTLS (Datagram Transport Layer Security) provê criptografia
✅ SRTP (Secure Real-time Transport Protocol) garante streaming de áudio seguro
✅ Adaptação de banda conforme as condições da rede 3. Processamento de áudio ✅ Processamento de áudio no cliente (cancelamento de eco, supressão de ruído)
✅ Aprimoramento de áudio no servidor
✅ Técnicas de ocultação de perda de pacotes
Arquitetura AWS e orquestração de funções
A implementação aproveita diversos serviços AWS em uma arquitetura escalável e resiliente:
- Componentes voltados ao cliente ✅ Distribuição CloudFront para entrega global de conteúdo
✅ Application Load Balancer para distribuição de tráfego
✅ ECS Fargate para hospedagem de aplicações conteinerizadas 2. Pipeline de processamento ✅ Amazon Bedrock para capacidades de IA generativa
✅ Amazon Transcribe para reconhecimento de fala
✅ Amazon Polly para síntese de fala
✅ Funções Lambda customizadas para orquestração 3. Serviços de backend ✅ DynamoDB para gerenciamento de sessões e metadados
✅ Parameter Store para gerenciamento seguro de credenciais
✅ CloudWatch para logging e monitoramento abrangentes 4. Camada de segurança ✅ Certificados ACM para criptografia TLS
✅ Roles IAM para controle de acesso granular
✅ AWS WAF para proteção de firewall de aplicações web
A implementação na AWS usa infraestrutura como código (IaC) com o AWS CDK, o que permite implantações reproduzíveis e ambientes consistentes. A arquitetura segue os princípios do AWS Well-Architected Framework para segurança, confiabilidade, eficiência de desempenho, otimização de custos e excelência operacional.
Otimização de desempenho
O desempenho de baixa latência do Nova Sonic é alcançado por meio de várias otimizações técnicas:
- Otimização de inferência em streaming ✅ Processamento paralelo de blocos de áudio
✅ Estratégias adaptativas de buffering
✅ Geração antecipada de respostas com base em entradas parciais 2. Redução de latência de rede ✅ Modelo de implantação com edge computing
✅ Connection pooling para serviços de backend
✅ Implantação regional para proximidade dos usuários finais 3. Escalonamento de recursos ✅ Auto-scaling de serviços ECS conforme a demanda
✅ Capacidade reservada para desempenho consistente
✅ Distribuição de workloads entre zonas de disponibilidade
Implementação dos componentes de frontend
A implementação de frontend do Nova Sonic mostra como tecnologias web modernas podem viabilizar interações de voz em tempo real com latência mínima. A implementação no diretório /vite-client exibe uma abordagem pronta para produção na construção de interfaces de IA por voz que parecem naturais e responsivas.
Implementação do cliente WebRTC
A implementação WebRTC do lado cliente está encapsulada na classe ChatbotClient, dentro de app.js, que cuida do ciclo de vida da conexão e do gerenciamento de mídia:
class ChatbotClient {
constructor() {
// Initialize client state
this.rtviClient = null;
this.videoManager = null;
this.setupDOMElements();
this.setupEventListeners();
this.initializeClientAndTransport();
}
// ...
}
A implementação se apoia em bibliotecas especializadas:
@pipecat-ai/client-js: fornece a classeRTVIClientpara interações de voz em tempo real@pipecat-ai/daily-transport: viabiliza comunicação WebRTC pela infraestrutura da Daily.co. Os primeiros 10.000 minutos de participante são gratuitos.
Principais recursos da implementação WebRTC:
- Abstração da camada de transporte ✅ Encapsulamento da complexidade do WebRTC por meio de uma interface de transporte
✅ Tratamento automático da negociação de candidatos ICE
✅ Estratégias de reconexão fluidas para interrupções de rede 2. Gerenciamento de fluxo de mídia ✅ Inscrição e cancelamento dinâmico de tracks
✅ Negociação automática de formatos de mídia
✅ Qualidade de mídia otimizada conforme as condições de banda 3. Gerenciamento do estado de conexão ✅ Transições robustas de estado (conectando, conectado, desconectado)
✅ Arquitetura orientada a eventos para atualizações de UI responsivas
✅ Tratamento abrangente de erros em falhas de conexão
Componentes de microfone e câmera
O projeto implementa um gerenciamento sofisticado de dispositivos de mídia por meio da classe VideoManager, que oferece:
- Inicialização de dispositivos e fluxo de permissão ✅ Solicitações de permissão de câmera amigáveis ao usuário
✅ Tratamento detalhado de erros para negações de permissão
✅ Feedback visual durante a inicialização do dispositivo 2. Gerenciamento de tracks de mídia ✅ Tratamento separado de tracks de mídia local e remota
✅ Otimização de qualidade para fluxos de vídeo
✅ Limpeza automática de tracks na desconexão 3. Integração de elementos de mídia ✅ Criação e configuração dinâmica de elementos de áudio/vídeo
✅ Adaptação de layout responsivo
✅ Configurações de reprodução otimizadas para baixa latência
Este exemplo de VideoManager.js mostra como os fluxos de câmera são inicializados:
async toggleLocalCamera() {
try {
// Request camera access through the browser
const stream = await navigator.mediaDevices.getUserMedia({
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
});
// Store the stream for later use
this._localStream = stream;
// Update the local video element with this stream
this.localVideo.srcObject = stream;
// Ensure the video plays
await this.localVideo.play();
} catch (error) {
// Handle permission errors with user-friendly messaging
}
}
Interface de usuário para interação por voz
A interface foi projetada para uma interação por voz intuitiva, com os seguintes recursos:
- Controles de conexão ✅ Indicadores visuais claros do estado da conexão
✅ Conectar/desconectar com um clique
✅ Interface de gerenciamento de permissões 2. Feedback visual ✅ Exibição de transcrição em tempo real
✅ Indicadores visuais animados durante a fala do bot
✅ Indicadores de status da conexão 3. Capacidades de depuração ✅ Interface de logging abrangente
✅ Monitoramento de estatísticas de rede
✅ Visualização do nível de áudio
Principais tecnologias e bibliotecas de frontend
A implementação de frontend usa várias tecnologias web modernas:
- Vite — para desenvolvimento rápido e builds de produção otimizados
- APIs WebRTC — para comunicação de áudio/vídeo em tempo real
- Media Streams API — para acessar câmeras e microfones dos dispositivos
- Conteinerização — configuração Docker para implantação consistente
- Nginx — para servir arquivos estáticos e proxy opcional
Gerenciamento da conexão com o backend
A conexão frontend-backend é gerenciada por um protocolo robusto que:
- Estabelece conexões seguras baseadas em sala ✅ Obtém credenciais de sala no endpoint
/connectdo backend
✅ Protege as conexões com tokens
✅ Lida com eventos de participantes (entrada e saída) 2. Gerencia a transmissão de mídia com eficiência ✅ Implementa adaptação de banda
✅ Lida com transições de rede
✅ Fornece métricas de qualidade e diagnósticos 3. Otimiza a interação por voz com baixa latência ✅ Configura elementos de áudio para o menor atraso de processamento possível
✅ Implementa otimização de buffering de áudio
✅ Usa aceleração de hardware quando disponível
Essa arquitetura possibilita a latência crítica abaixo de 300 ms que faz as conversas no Nova Sonic parecerem naturais e fluidas.
Implementação dos componentes de backend
A implementação do lado servidor no diretório /server mostra como construir um backend escalável e pronto para produção para aplicações de IA por voz com Nova Sonic. Esta implementação ilustra os padrões de integração e as decisões arquiteturais necessárias para entregar soluções de IA por voz de nível empresarial.
WebRTC com implementação Daily Transport
O backend usa a infraestrutura da Daily.co para gerenciar sessões WebRTC por meio de uma implementação especializada de transporte:
# Set up Daily transport with video/audio parameters
transport = DailyTransport(
room_url,
token,
"Chatbot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
video_in_enabled=True,
video_out_enabled=True,
video_out_width=1024,
video_out_height=576,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=True,
),
)
Principais recursos da implementação de transporte:
- Gerenciamento de salas ✅ Criação dinâmica de salas seguras
✅ Autenticação baseada em token
✅ Limpeza automática de recursos não utilizados 2. Configuração de mídia ✅ Controle independente de entrada e saída de áudio/vídeo
✅ Configurações de resolução e qualidade
✅ Integração de Detecção de Atividade de Voz (VAD) 3. Tratamento de eventos ✅ Sistema abrangente de eventos para mudanças de estado do transporte
✅ Gerenciamento do ciclo de vida dos participantes
✅ Controle e gerenciamento de gravações
Padrões de function call para integração de ferramentas
A implementação demonstra padrões avançados de function calling que viabilizam a integração de ferramentas com o LLM:
# Register functions with the LLM service
register_functions(llm)
# Set up context with function schemas
context = OpenAILLMContext(
messages=[\
{"role": "system", "content": f"{system_instruction}"},\
{\
"role": "user",\
"content": "Hello, I'm here for my interview.",\
},\
],
tools=function_tools_schema,
)
Essa arquitetura possibilita:
- Sistema de registro de ferramentas ✅ Registro dinâmico de schemas de função
✅ Interfaces de função type-safe
✅ Suporte a funções síncronas e assíncronas 2. Gerenciamento de contexto ✅ Preservação do contexto da conversa entre interações
✅ Janelamento eficiente de contexto para conversas longas
✅ Rastreamento de conversa com estado 3. Execução de funções ✅ Execução segura de funções de ferramentas
✅ Tratamento de erros e mecanismos de retry
✅ Incorporação dos resultados ao contexto da conversa
Arquitetura e componentes do pipeline
O backend implementa uma arquitetura sofisticada de pipeline com o framework Pipecat:
pipeline = Pipeline(
[\
transport.input(),\
rtvi,\
context_aggregator.user(),\
llm,\
ta,\
transport.output(),\
context_aggregator.assistant(),\
]
)
Essa abordagem em pipeline oferece:
- Cadeia modular de processamento ✅ Separação clara de responsabilidades
✅ Componentes plugáveis para personalização
✅ Interfaces padronizadas de processamento de frames 2. Fluxo de dados bidirecional ✅ Processamento de entrada do usuário para o sistema
✅ Processamento de saída do sistema para o usuário
✅ Propagação de eventos em ambas as direções 3. Integração de observabilidade ✅ Coleta de métricas em nível de pipeline
✅ Diagnósticos em nível de componente
✅ Pontos de monitoramento de desempenho
Processamento e tratamento de áudio
A implementação inclui capacidades sofisticadas de processamento de áudio:
- Detecção de atividade de voz ✅ Detecção de atividade de voz baseada em ML, com Silero VAD
✅ Ajuste dinâmico de threshold
✅ Detecção de fala resistente a ruído 2. Gerenciamento de transcrição ✅ Conversão speech-to-text em tempo real
✅ Tratamento de resultados parciais para feedback imediato
✅ Sincronização da transcrição final 3. Otimização da saída de áudio ✅ Mixagem dinâmica de fluxos de áudio
✅ Técnicas de gerenciamento de latência
✅ Sincronização de reprodução
Integração com os serviços AWS Nova Sonic
O coração da implementação é a integração com os serviços AWS Nova Sonic:
# Initialize AWS Nova Sonic LLM service
llm = AWSNovaSonicLLMService(
secret_access_key=NOVA_AWS_SECRET_ACCESS_KEY,
access_key_id=NOVA_AWS_ACCESS_KEY_ID,
region=os.getenv("NOVA_AWS_REGION", "us-east-1"),
voice_id=os.getenv("NOVA_VOICE_ID", "tiffany"),
send_transcription_frames=True
)
Essa integração demonstra:
- Autenticação segura ✅ Gerenciamento de credenciais AWS
✅ Controle de acesso baseado em papéis
✅ Manuseio seguro de variáveis de ambiente 2. Personalização de voz ✅ Seleção e configuração de voz
✅ Características de prosódia e fala
✅ Opções de suporte multilíngue 3. Otimização de streaming ✅ Streaming de tokens em tempo real
✅ Geração progressiva de respostas
✅ Configuração de latência mínima 4. Recursos avançados ✅ Integração de frames de transcrição
✅ Respostas sensíveis ao contexto
✅ Tratamento de interrupções
Plano de ação executivo para IA generativa por voz
Aqui vai um playbook prático para começar:
- Identifique quais experiências de cliente ou colaborador mais ganhariam com interações de voz mais rápidas e naturais
- Monte um business case focado em custo, experiência ou potencial de receita
- Avalie parceiros que entreguem a combinação certa de expertise em nuvem, IA e segurança
- Faça um piloto e meça resultados com critérios claros de sucesso
- Implemente controles de governança e segurança para escalar com tranquilidade
- Faça o rollout em fases, usando infraestrutura como código e padrões consagrados de observabilidade
Olhando para o futuro
A voz é a interface mais natural que temos. Graças à IA generativa, ela agora pode ser tão escalável, segura e inteligente quanto sistemas baseados em texto. O futuro do engajamento com clientes e colaboradores será construído sobre conversas voice-first, com qualidade humana.
Para organizações com visão de futuro, a hora de investir é agora.
Na DoiT International, combinamos profunda expertise em nuvem, segurança e IA generativa para ajudar você a transformar soluções voice-first em sucesso, com confiabilidade e em escala.
Vamos construir juntos a próxima geração de IA conversacional. Fale com a DoiT International hoje mesmo!