Una mirada estratégica para implementar IA voice-first en tiempo real en la era generativa

La próxima frontera: ¿por qué la voz y por qué ahora?
La IA conversacional llegó a un punto de inflexión. La voz dejó de ser una novedad: es la forma más humana, eficiente y emocionalmente inteligente que tienen las empresas para conectar con clientes, empleados y socios. Hoy, la IA generativa speech-to-speech por fin vuelve estas experiencias voice-first prácticas, escalables y rentables. El momento del cambio es ahora.
¿Por qué ahora?
¿Por qué está ocurriendo justo en este momento? Convergen varios cambios clave:
- Los modelos de lenguaje unificados speech-to-speech, como Amazon Nova Sonic, integran reconocimiento de voz, razonamiento y generación de voz en una sola arquitectura en tiempo real
- La latencia se reduce drásticamente y, al mismo tiempo, mejora la calidad de la conversación
- Clientes y empleados esperan, más que nunca, interacciones por voz fluidas
La combinación de una tecnología generativa madura y expectativas en alza está redefiniendo lo posible — y lo competitivo.
¿Qué es un asistente de voz con IA?
Un asistente de voz con IA es un agente conversacional capaz de escuchar, razonar y responder en lenguaje hablado natural, gestionando diálogos complejos de varios turnos en tiempo real. Diseñados con seguridad y gobernanza de nivel empresarial, estos asistentes están a años luz de los bots tradicionales basados en guiones.
Son capaces de:
- Responder con fluidez, sin pausas robóticas
- Reflejar emoción y tono
- Comprender intenciones matizadas del usuario
- Integrarse con el conocimiento empresarial y ejecutar acciones
Esto los vuelve ideales para casos de uso como entrevistas de RR. HH., atención al cliente, llamadas comerciales proactivas o coaching a empleados.
El valor de negocio de la IA generativa por voz
Para los líderes que evalúan la IA por voz, el caso de negocio es contundente:
- Reducir costos operativos automatizando interacciones de voz rutinarias
- Mejorar la satisfacción del cliente con conversaciones más naturales y empáticas
- Atender a los usuarios las 24 horas, en distintos idiomas y geografías
- Abrir nuevas fuentes de ingresos con campañas proactivas por voz
- Empoderar a los equipos con asistentes de conocimiento por voz disponibles al instante
La voz es el canal que la gente prefiere. La IA generativa por fin la vuelve escalable, segura y consistente.
De STT→LLM→TTS al speech-to-speech unificado: un cambio de paradigma
Tradicionalmente, los sistemas de IA por voz se construyeron con un pipeline en cascada de componentes separados. Suele representarse como STT→LLM→TTS, es decir, Speech-to-Text→Large Language Model→Text-to-Speech. En un asistente de voz o un bot de llamadas típico, la entrada hablada pasa por los siguientes pasos:
- Reconocimiento automático del habla (ASR): el habla del usuario se convierte en texto mediante un modelo speech-to-text (por ejemplo, Amazon Transcribe o Google Speech API).
- Comprensión del lenguaje / procesamiento con LLM: el texto transcrito se envía a un modelo de lenguaje o gestor de diálogo (como un LLM), que produce una respuesta de texto a partir de la consulta y el contexto del usuario.
- Síntesis Text-to-Speech (TTS): la respuesta de texto de la IA se convierte en audio hablado mediante un motor de síntesis de voz (por ejemplo, Amazon Polly o WaveNet de Google).
- Reproducción de audio: el habla sintetizada se reproduce al usuario como respuesta.
Cada uno de estos pasos suele involucrar modelos o servicios distintos, que se orquestan de manera secuencial. El framework open-source Pipecat de Daily (utilizado en arquitecturas de referencia de AWS) es un buen ejemplo de este enfoque: integra WebRTC para el streaming de audio, un detector de actividad de voz (para identificar cuándo habla el usuario), Amazon Transcribe para ASR, un LLM (modelo de texto Amazon Nova) para NLU/NLG y Amazon Polly para TTS. La Figura 1, a continuación, ilustra una arquitectura de IA por voz en cascada en un entorno empresarial, donde varios servicios de AWS trabajan en conjunto para resolver una consulta del usuario de extremo a extremo.
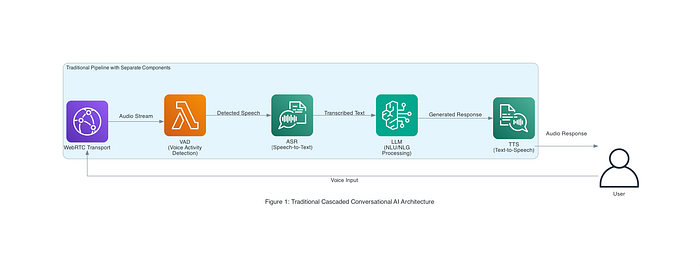
Figura 1: arquitectura tradicional en cascada de IA conversacional (de la referencia AWS Pipecat). La entrada de voz pasa por el transporte WebRTC, VAD (detección de actividad de voz), ASR (speech-to-text), un LLM para NLU/NLG y TTS para la respuesta. Cada componente añade tiempo de procesamiento y posibles puntos de falla.
Si bien este pipeline modular tiene la ventaja de aprovechar componentes especializados para cada tarea, también arrastra desventajas. La transferencia entre servicios introduce latencia: por lo general, el usuario tiene que terminar de hablar antes de que la IA empiece a formular una respuesta, lo que provoca pausas notorias. Cada componente puede sumar errores (por ejemplo, fallos de transcripción o un TTS con sonido robótico) que se acumulan y reducen la calidad conversacional general. Mantener la coherencia de la conversación se vuelve difícil cuando el ASR y el TTS desconocen los matices del otro o el tono emocional del intercambio. En síntesis, las interacciones se sienten menos naturales por los retrasos del sistema y la falta de cohesión entre las partes.
Amazon Nova Sonic: un avance tecnológico
Nova Sonic, de Amazon, representa un gran salto adelante. En lugar de unir componentes separados de speech-to-text, razonamiento y text-to-speech, Nova Sonic unifica todo el proceso conversacional en un único pipeline optimizado y seguro.
De un vistazo, Nova Sonic puede:
- Escuchar y entender en tiempo real
- Generar respuestas que suenan humanas
- Hablar con voces expresivas y adaptativas
- Ejecutar function calls para tomar acciones
- Fundamentar las respuestas en el conocimiento empresarial
Se entrega como API a través de Bedrock, así que no necesitas alojar ni entrenar los modelos por tu cuenta. Esta simplicidad elimina barreras para la adopción en producción, incluso en entornos regulados o con alta sensibilidad a la seguridad.
De la visión a la ejecución: cómo ayuda DoiT
En DoiT International creemos que toda iniciativa exitosa de IA por voz se sostiene en tres pilares esenciales:
✅ Conversación natural impulsada por las capacidades unificadas speech-to-speech de Nova Sonic
✅ Infraestructura en tiempo real construida sobre WebRTC seguro, streaming y microservicios containerizados
✅ Controles de nivel empresarial para cumplimiento, gobernanza y monitoreo
Nuestro equipo acompaña a las organizaciones a llevar estos pilares a la práctica con un framework bien arquitectado que traduce la investigación en despliegues seguros, escalables y reales.
Cómo se integra todo:
El blueprint de referencia combina un front end seguro con WebRTC, microservicios containerizados en AWS Fargate y un backend Nova Sonic gestionado por Bedrock para conversaciones voz a voz en tiempo real. IAM basado en roles, secretos seguros, distribución con CloudFront y observabilidad integral completan el diseño, dando confianza a escala.
Para más información, visita nuestro repositorio de referencia en GitHub. Ten en cuenta que este repositorio está pensado solo para evaluación y pruebas, y todavía no es apto para despliegue en producción.
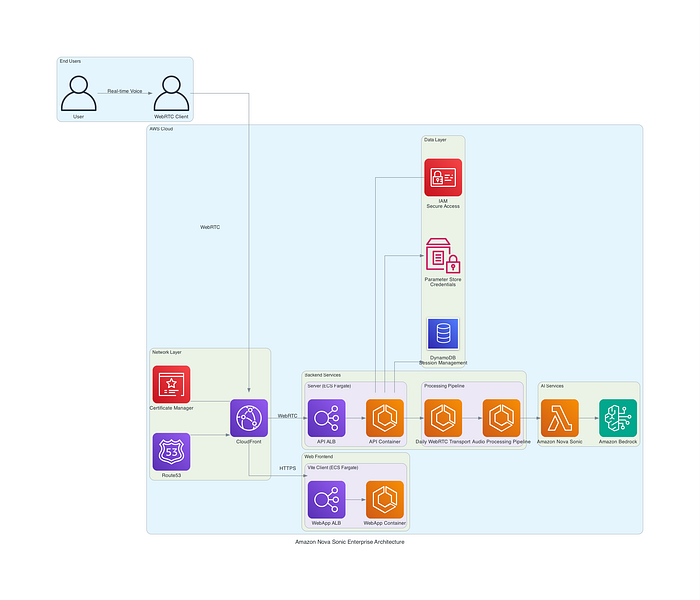
Figura 1: diagrama de arquitectura de alto nivel que muestra la integración completa entre los componentes del frontend, los servicios del backend y los recursos de la nube de AWS.
Componentes de la arquitectura AWS
La implementación de Nova Sonic se apoya en varios servicios clave de AWS:
- Servicio Nova Sonic ✅ Capacidades centrales de IA speech-to-speech
✅ Procesamiento de audio en tiempo real
✅ Generación de respuestas en streaming
✅ Opciones de personalización de voz 2. Amazon Bedrock ✅ Integración de modelos fundacionales
✅ Generación de respuestas con conciencia del contexto
✅ Capacidades de function calling
✅ Gestión del conocimiento 3. Servicios de contenedores ✅ ECS Fargate para servicios de backend containerizados
✅ Auto-escalado según la demanda
✅ Optimización de recursos
✅ Automatización del despliegue 4. Servicios de soporte ✅ CloudFront para entrega global de contenidos
✅ DynamoDB para gestión de estado
✅ S3 para almacenamiento de grabaciones
✅ CloudWatch para observabilidad
Puntos clave de integración
La arquitectura se construye en torno a varios puntos críticos de integración:
- Integración Frontend-Backend ✅ Señalización WebRTC vía endpoints FastAPI
✅ Intercambio seguro de credenciales de sala
✅ Inicialización del flujo de medios
✅ Sincronización del estado de conexión 2. Integración Backend-AWS ✅ Autenticación segura con servicios de AWS
✅ Conexiones de streaming a Nova Sonic
✅ Sincronización de estado con DynamoDB
✅ Integración de monitoreo con CloudWatch 3. Integración de los componentes del pipeline ✅ Interfaces de frame estandarizadas
✅ Comunicación orientada a eventos
✅ Flujo de datos bidireccional
✅ Arquitectura modular de componentes
Consideraciones de seguridad y escalado
La implementación incorpora funciones de seguridad y escalado de nivel empresarial:
- Medidas de seguridad ✅ Autenticación de salas basada en tokens
✅ Transmisión de medios cifrada
✅ Gestión segura de credenciales
✅ Control de acceso basado en roles 2. Estrategia de escalado ✅ Escalado horizontal de los servicios de backend
✅ Connection pooling para uso eficiente de recursos
✅ Despliegue regional para cobertura global
✅ Auto-escalado según métricas de conexión 3. Funciones de resiliencia ✅ Reconexión automática
✅ Degradación elegante ante interrupciones del servicio
✅ Manejo integral de errores
✅ Mecanismos de recuperación de sesión
Esta arquitectura ofrece un blueprint para las organizaciones que buscan implementar Nova Sonic en entornos empresariales, con especial atención a la seguridad, la escalabilidad y la integración con sistemas existentes.
Arquitectura del pipeline de procesamiento de voz
La capacidad disruptiva de Amazon Nova Sonic se apoya en un pipeline avanzado de procesamiento de voz que habilita interacciones speech-to-speech casi en tiempo real. A diferencia de los asistentes de voz tradicionales, que procesan enunciados completos antes de responder, Nova Sonic procesa flujos de audio de forma continua y bidireccional, lo que permite una conversación natural con mínima latencia.
El pipeline de procesamiento de voz consta de los siguientes componentes clave:
- Capa de captura y streaming de audio ✅ Protocolo WebRTC para transmisión de audio en tiempo real
✅ Procesamiento de audio en el navegador con cancelación de eco y reducción de ruido
✅ Codificación de bitrate adaptativo según las condiciones de la red 2. Componente de reconocimiento de voz ✅ ASR (reconocimiento automático del habla) en streaming continuo
✅ Reconocimiento de baja latencia a nivel de fonemas
✅ Modelado de lenguaje con conciencia del contexto para mayor precisión 3. Motor de procesamiento semántico ✅ Detección de intención en tiempo real mientras el usuario habla
✅ Gestión de contexto multi-turno para mantener la coherencia conversacional
✅ Formulación y optimización de consultas para la interacción con el LLM 4. Backend de IA generativa Nova Sonic ✅ Generación de tokens en streaming con buffering mínimo
✅ Síntesis de voz neural con personalización
✅ Control de prosodia y tono para una salida de voz natural 5. Generación y mezcla de la salida ✅ Mezcla dinámica de audio para una conversación fluida
✅ Técnicas de optimización de latencia
✅ Bucle de retroalimentación en tiempo real para el control de la calidad de audio
Flujo de comunicación WebRTC
La implementación de WebRTC habilita flujos de audio bidireccionales seguros y de baja latencia entre la aplicación cliente y el servicio Nova Sonic:
- Establecimiento de la sesión ✅ El protocolo ICE (Interactive Connectivity Establishment) identifica las rutas de red óptimas
✅ Los servidores STUN/TURN facilitan el atravesamiento de NAT
✅ SDP (Session Description Protocol) negocia las capacidades de medios 2. Transmisión segura de medios ✅ DTLS (Datagram Transport Layer Security) aporta el cifrado
✅ SRTP (Secure Real-time Transport Protocol) asegura el streaming de audio
✅ Adaptación del ancho de banda según las condiciones de la red 3. Procesamiento de audio ✅ Procesamiento de audio en el cliente (cancelación de eco, supresión de ruido)
✅ Mejora de audio en el servidor
✅ Técnicas de ocultación de pérdida de paquetes
Arquitectura AWS y orquestación de funciones
La implementación se apoya en varios servicios de AWS dentro de una arquitectura escalable y resiliente:
- Componentes orientados al cliente ✅ Distribución CloudFront para entrega global de contenidos
✅ Application Load Balancer para distribuir el tráfico
✅ ECS Fargate para hosting de aplicaciones containerizadas 2. Pipeline de procesamiento ✅ Amazon Bedrock para capacidades de IA generativa
✅ Amazon Transcribe para reconocimiento de voz
✅ Amazon Polly para síntesis de voz
✅ Funciones Lambda personalizadas para la orquestación 3. Servicios de backend ✅ DynamoDB para gestión de sesiones y metadatos
✅ Parameter Store para gestión segura de credenciales
✅ CloudWatch para logging y monitoreo integral 4. Capa de seguridad ✅ Certificados ACM para cifrado TLS
✅ Roles IAM para control de acceso de grano fino
✅ AWS WAF como firewall de aplicaciones web
La implementación en AWS utiliza infraestructura como código (IaC) con AWS CDK, lo que permite despliegues reproducibles y entornos consistentes. La arquitectura sigue los principios del AWS Well-Architected Framework en seguridad, fiabilidad, eficiencia del rendimiento, optimización de costos y excelencia operativa.
Optimización del rendimiento
El rendimiento de baja latencia de Nova Sonic se logra mediante varias optimizaciones técnicas:
- Optimización de la inferencia en streaming ✅ Procesamiento paralelo de chunks de audio
✅ Estrategias de buffering adaptativo
✅ Generación temprana de respuestas a partir de entradas parciales 2. Reducción de latencia de red ✅ Modelo de despliegue con edge computing
✅ Connection pooling para los servicios de backend
✅ Despliegue regional para mayor cercanía con los usuarios finales 3. Escalado de recursos ✅ Auto-escalado de servicios ECS según la demanda
✅ Capacidad reservada para un rendimiento consistente
✅ Distribución de workloads entre zonas de disponibilidad
Implementación de los componentes del frontend
La implementación del frontend de Nova Sonic muestra cómo las tecnologías web modernas pueden habilitar interacciones de voz en tiempo real con mínima latencia. La implementación en el directorio /vite-client presenta un enfoque listo para producción para construir interfaces de IA por voz que se sientan naturales y receptivas.
Implementación del cliente WebRTC
La implementación de WebRTC en el cliente está encapsulada en la clase ChatbotClient dentro de app.js, que gestiona el ciclo de vida de la conexión y el manejo de medios:
class ChatbotClient {
constructor() {
// Initialize client state
this.rtviClient = null;
this.videoManager = null;
this.setupDOMElements();
this.setupEventListeners();
this.initializeClientAndTransport();
}
// ...
}
La implementación se apoya en librerías especializadas:
@pipecat-ai/client-js: aporta la claseRTVIClientpara interacciones de voz en tiempo real@pipecat-ai/daily-transport: habilita la comunicación WebRTC mediante la infraestructura de Daily.co. Los primeros 10.000 minutos de participante son gratuitos.
Entre las funciones clave de la implementación de WebRTC se incluyen:
- Abstracción de la capa de transporte ✅ Encapsulación de la complejidad de WebRTC mediante una interfaz de transporte
✅ Manejo automático de la negociación de candidatos ICE
✅ Estrategias de reconexión fluidas ante interrupciones de red 2. Gestión del flujo de medios ✅ Suscripción y desuscripción dinámica de tracks
✅ Negociación automática del formato de medios
✅ Calidad de medios optimizada según las condiciones de ancho de banda 3. Gestión del estado de conexión ✅ Transiciones de estado robustas (conectando, conectado, desconectado)
✅ Arquitectura orientada a eventos para actualizaciones de UI receptivas
✅ Manejo integral de errores ante fallos de conexión
Componentes para el manejo de micrófono y cámara
El proyecto implementa una gestión sofisticada de dispositivos de medios mediante la clase VideoManager, que ofrece:
- Inicialización de dispositivos y flujo de permisos ✅ Solicitudes de permiso de cámara amigables
✅ Manejo detallado de errores ante denegaciones de permisos
✅ Retroalimentación visual durante la inicialización del dispositivo 2. Gestión de tracks de medios ✅ Manejo separado de tracks locales y remotos
✅ Optimización de calidad para los flujos de video
✅ Limpieza automática de tracks al desconectarse 3. Integración con elementos de medios ✅ Creación y configuración dinámica de elementos de audio/video
✅ Adaptación responsiva del layout
✅ Configuración de reproducción optimizada para baja latencia
Este ejemplo de VideoManager.js muestra cómo se inicializan los flujos de cámara:
async toggleLocalCamera() {
try {
// Request camera access through the browser
const stream = await navigator.mediaDevices.getUserMedia({
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
});
// Store the stream for later use
this._localStream = stream;
// Update the local video element with this stream
this.localVideo.srcObject = stream;
// Ensure the video plays
await this.localVideo.play();
} catch (error) {
// Handle permission errors with user-friendly messaging
}
}
Interfaz de usuario para la interacción por voz
La interfaz de usuario está diseñada para una interacción por voz intuitiva, con las siguientes funciones:
- Controles de conexión ✅ Indicadores visuales claros del estado de conexión
✅ Conexión y desconexión con un solo clic
✅ Interfaz para gestión de permisos 2. Retroalimentación visual ✅ Visualización de la transcripción en tiempo real
✅ Indicadores visuales animados mientras habla el bot
✅ Indicadores de estado de conexión 3. Capacidades de depuración ✅ Interfaz integral de logging
✅ Monitoreo de estadísticas de red
✅ Visualización del nivel de audio
Tecnologías y librerías clave del frontend
La implementación del frontend se apoya en varias tecnologías web modernas:
- Vite — Para desarrollo ágil y builds de producción optimizados
- APIs de WebRTC — Para comunicación de audio/video en tiempo real
- API Media Streams — Para acceder a las cámaras y micrófonos del dispositivo
- Containerización — Configuración Docker para un despliegue consistente
- Nginx — Para servir archivos estáticos y proxy opcional
Gestión de la conexión con el backend
La conexión frontend-backend se gestiona mediante un protocolo robusto que:
- Establece conexiones seguras basadas en salas ✅ Obtiene credenciales de sala desde el endpoint
/connectdel backend
✅ Asegura las conexiones con tokens
✅ Maneja los eventos de los participantes (entrada, salida) 2. Gestiona la transmisión de medios de forma eficiente ✅ Implementa adaptación del ancho de banda
✅ Maneja transiciones de red
✅ Provee métricas de calidad y diagnósticos 3. Optimiza para una interacción de voz de baja latencia ✅ Configura los elementos de audio para un retraso de procesamiento mínimo
✅ Implementa optimización del buffering de audio
✅ Aprovecha la aceleración por hardware cuando está disponible
Esta arquitectura habilita la latencia crítica por debajo de 300 ms que vuelve naturales y fluidas las conversaciones con Nova Sonic.
Implementación de los componentes del backend
La implementación del lado del servidor en el directorio /server muestra cómo construir un backend escalable y listo para producción para aplicaciones de IA por voz con Nova Sonic. Esta implementación ilustra los patrones de integración y las decisiones arquitectónicas necesarias para desplegar soluciones de IA por voz de nivel empresarial.
WebRTC con la implementación del transporte Daily
El backend aprovecha la infraestructura de Daily.co para la gestión de sesiones WebRTC mediante una implementación de transporte especializada:
# Set up Daily transport with video/audio parameters
transport = DailyTransport(
room_url,
token,
"Chatbot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
video_in_enabled=True,
video_out_enabled=True,
video_out_width=1024,
video_out_height=576,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=True,
),
)
Las funciones clave de la implementación del transporte incluyen:
- Gestión de salas ✅ Creación dinámica de salas seguras
✅ Autenticación basada en tokens
✅ Limpieza automática de recursos no utilizados 2. Configuración de medios ✅ Control independiente de la entrada y salida de audio/video
✅ Configuración de resolución y calidad
✅ Integración con detección de actividad de voz (VAD) 3. Manejo de eventos ✅ Sistema integral de eventos para los cambios de estado del transporte
✅ Gestión del ciclo de vida de los participantes
✅ Control y gestión de grabaciones
Patrones de function call para integración de herramientas
La implementación demuestra patrones avanzados de function calling que permiten integrar herramientas con el LLM:
# Register functions with the LLM service
register_functions(llm)
# Set up context with function schemas
context = OpenAILLMContext(
messages=[\
{"role": "system", "content": f"{system_instruction}"},\
{\
"role": "user",\
"content": "Hello, I'm here for my interview.",\
},\
],
tools=function_tools_schema,
)
Esta arquitectura permite:
- Sistema de registro de herramientas ✅ Registro dinámico de esquemas de funciones
✅ Interfaces de funciones type-safe
✅ Soporte para funciones síncronas y asíncronas 2. Gestión del contexto ✅ Preservación del contexto conversacional entre interacciones
✅ Ventanas de contexto eficientes para conversaciones largas
✅ Seguimiento de conversaciones con estado 3. Ejecución de funciones ✅ Ejecución segura de funciones de herramientas
✅ Manejo de errores y mecanismos de reintento
✅ Incorporación de los resultados al contexto de la conversación
Arquitectura del pipeline y sus componentes
El backend implementa una sofisticada arquitectura de pipeline mediante el framework Pipecat:
pipeline = Pipeline(
[\
transport.input(),\
rtvi,\
context_aggregator.user(),\
llm,\
ta,\
transport.output(),\
context_aggregator.assistant(),\
]
)
Este enfoque de pipeline ofrece:
- Cadena de procesamiento modular ✅ Separación clara de responsabilidades
✅ Componentes pluggables para personalización
✅ Interfaces estandarizadas de procesamiento de frames 2. Flujo de datos bidireccional ✅ Procesamiento de la entrada del usuario hacia el sistema
✅ Procesamiento de la salida del sistema hacia el usuario
✅ Propagación de eventos en ambos sentidos 3. Integración de observabilidad ✅ Recolección de métricas a nivel de pipeline
✅ Diagnóstico a nivel de componente
✅ Puntos de monitoreo del rendimiento
Procesamiento y manejo de audio
La implementación incluye capacidades sofisticadas de procesamiento de audio:
- Detección de actividad de voz ✅ Detección de actividad de voz basada en ML con Silero VAD
✅ Ajuste dinámico de umbrales
✅ Detección de habla resiliente al ruido 2. Gestión de la transcripción ✅ Conversión de voz a texto en tiempo real
✅ Manejo de resultados parciales para retroalimentación inmediata
✅ Sincronización del transcript final 3. Optimización de la salida de audio ✅ Mezcla dinámica de los flujos de audio
✅ Técnicas de gestión de latencia
✅ Sincronización de la reproducción
Integración con los servicios AWS Nova Sonic
El corazón de la implementación es la integración con los servicios de AWS Nova Sonic:
# Initialize AWS Nova Sonic LLM service
llm = AWSNovaSonicLLMService(
secret_access_key=NOVA_AWS_SECRET_ACCESS_KEY,
access_key_id=NOVA_AWS_ACCESS_KEY_ID,
region=os.getenv("NOVA_AWS_REGION", "us-east-1"),
voice_id=os.getenv("NOVA_VOICE_ID", "tiffany"),
send_transcription_frames=True
)
Esta integración muestra:
- Autenticación segura ✅ Gestión de credenciales de AWS
✅ Control de acceso basado en roles
✅ Manejo seguro de variables de entorno 2. Personalización de voz ✅ Selección y configuración de la voz
✅ Características de prosodia y habla
✅ Opciones de soporte multilingüe 3. Optimización del streaming ✅ Streaming de tokens en tiempo real
✅ Generación progresiva de respuestas
✅ Configuración de mínima latencia 4. Funciones avanzadas ✅ Integración de frames de transcripción
✅ Respuestas con conciencia del contexto
✅ Manejo de interrupciones
Plan de acción ejecutivo para la IA generativa por voz
Aquí tienes un playbook práctico para empezar:
- Identifica qué experiencias de cliente o empleado podrían beneficiarse más de interacciones por voz más rápidas y naturales
- Construye un caso de negocio enfocado en costo, experiencia o aumento de ingresos
- Evalúa partners que aporten la combinación adecuada de experiencia en cloud, IA y seguridad
- Lanza un piloto y mide los resultados con criterios de éxito claros
- Establece controles de gobernanza y seguridad pensando en escalar
- Despliega por fases, con infraestructura como código y patrones de observabilidad probados
Mirando hacia adelante
La voz es la interfaz más natural que tenemos. Gracias a la IA generativa, hoy puede ser tan escalable, segura e inteligente como los sistemas basados en texto. El futuro del engagement con clientes y empleados se construirá sobre conversaciones voice-first, con un tono cercano al humano.
Para las organizaciones con visión de futuro, el momento de invertir es ahora.
En DoiT International combinamos profunda experiencia en cloud, seguridad e IA generativa para ayudarte a llevar al éxito tus soluciones voice-first, con confiabilidad y a escala.
Construyamos juntos la próxima generación de IA conversacional. ¡Contacta hoy a DoiT International!