Una prospettiva strategica per portare l'AI vocale in tempo reale nell'era generativa

La prossima frontiera: perché la voce, perché ora
L'AI conversazionale ha raggiunto un punto di svolta. La voce non è più una novità: è il modo più umano, efficiente ed emotivamente intelligente con cui le aziende possono entrare in contatto con clienti, dipendenti e partner. Oggi l'AI generativa speech-to-speech rende finalmente queste esperienze voice-first concrete, scalabili e sostenibili sul piano economico. Il momento di cambiare è adesso.
Perché proprio ora
Perché tutto questo sta accadendo proprio oggi? Stanno convergendo diverse trasformazioni decisive:
- I modelli linguistici unificati speech-to-speech, come Amazon Nova Sonic, riuniscono riconoscimento vocale, ragionamento e sintesi vocale in un'unica architettura in tempo reale
- La latenza si riduce drasticamente, mentre la qualità della conversazione cresce
- Clienti e dipendenti si aspettano interazioni vocali fluide come mai prima d'ora
L'incontro tra una tecnologia generativa ormai matura e aspettative in continua crescita sta ridefinendo ciò che è possibile e ciò che fa la differenza sul mercato.
Cos'è un assistente AI vocale
Un assistente AI vocale è un agente conversazionale capace di ascoltare, ragionare e rispondere in linguaggio naturale parlato, gestendo dialoghi complessi e multi-turno in tempo reale. Progettati con sicurezza e governance di livello enterprise, questi assistenti hanno ben poco in comune con i tradizionali bot a copione.
Sono in grado di:
- Rispondere in modo fluido, senza pause robotiche
- Cogliere e restituire emozioni e tono di voce
- Interpretare intenzioni utente complesse e ricche di sfumature
- Integrarsi con la knowledge base aziendale ed eseguire azioni
Tutto questo li rende ideali per casi d'uso come colloqui HR, customer service, chiamate di vendita proattive o coaching dei dipendenti.
Il valore di business dell'AI generativa vocale
Per i decision maker che stanno valutando l'AI vocale, il business case è solido:
- Riduzione dei costi operativi grazie all'automazione delle interazioni vocali di routine
- Maggiore soddisfazione del cliente con conversazioni più naturali ed empatiche
- Servizio agli utenti 24/7, in più lingue e in qualsiasi area geografica
- Nuove fonti di ricavo grazie a iniziative vocali proattive
- Dipendenti più autonomi grazie ad assistenti vocali on-demand sempre disponibili
La voce è il canale che le persone preferiscono. L'AI generativa la rende finalmente scalabile, sicura e coerente.
Da STT→LLM→TTS allo speech-to-speech unificato: un cambio di paradigma
Tradizionalmente i sistemi di AI vocale sono stati realizzati con una pipeline a cascata composta da componenti separati. Questa pipeline viene spesso rappresentata come STT→LLM→TTS, ovvero Speech-to-Text→Large Language Model→Text-to-Speech. In un tipico assistente vocale o call bot, l'input parlato attraversa i seguenti passaggi:
- Automatic Speech Recognition (ASR): il parlato dell'utente viene convertito in testo tramite un modello speech-to-text (ad esempio Amazon Transcribe o Google Speech API).
- Comprensione linguistica / elaborazione LLM: il testo trascritto viene passato a un modello linguistico o a un dialogue manager (come un LLM), che genera una risposta testuale a partire dalla query e dal contesto dell'utente.
- Sintesi Text-to-Speech (TTS): la risposta testuale dell'AI viene convertita in audio parlato tramite un motore di sintesi vocale (ad esempio Amazon Polly o WaveNet di Google).
- Riproduzione audio: il parlato sintetizzato viene riprodotto all'utente come risposta.
Ciascuno di questi passaggi richiede in genere modelli o servizi distinti, da orchestrare in sequenza. Il framework open source Pipecat di Daily (impiegato nelle reference architecture AWS) è un esempio chiaro di questo approccio: integra WebRTC per lo streaming audio, un voice activity detector (per rilevare quando l'utente sta parlando), Amazon Transcribe per l'ASR, un LLM (modello testuale Amazon Nova) per NLU/NLG e Amazon Polly per il TTS. La Figura 1 qui sotto illustra una di queste architetture a cascata di AI vocale in un contesto enterprise, in cui diversi servizi AWS lavorano in sinergia per gestire end-to-end una singola query utente.
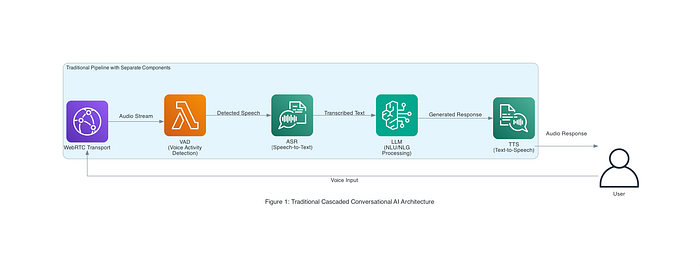
Figura 1: un'architettura tradizionale a cascata di AI conversazionale (dalla reference AWS Pipecat). L'input vocale attraversa il trasporto WebRTC, il VAD (voice activity detection), l'ASR (speech-to-text), un LLM per NLU/NLG e il TTS per la risposta. Ogni componente aggiunge tempo di elaborazione e potenziali punti di guasto.
Questa pipeline modulare ha il vantaggio di sfruttare componenti specializzati per ogni attività, ma porta con sé anche degli svantaggi. Il passaggio tra i servizi introduce latenza: l'utente deve quasi sempre concludere la frase prima che l'AI inizi a formulare la risposta, con pause percepibili. Ogni componente può inoltre introdurre errori (ad esempio errori di trascrizione o un output TTS dal suono robotico) che si sommano e abbassano la qualità complessiva della conversazione. Mantenere la coerenza conversazionale diventa difficile quando ASR e TTS non condividono le reciproche sfumature né il tono emotivo del dialogo. In sintesi, le interazioni risultano meno naturali a causa dei ritardi del sistema e del disallineamento tra parti separate.
Amazon Nova Sonic: una svolta tecnologica
Nova Sonic di Amazon segna un grande balzo in avanti. Invece di assemblare componenti separati per speech-to-text, ragionamento e text-to-speech, Nova Sonic unifica l'intero processo conversazionale in un'unica pipeline ottimizzata e sicura.
In sintesi, Nova Sonic è in grado di:
- Ascoltare e comprendere in tempo reale
- Generare risposte dal tono umano
- Parlare con voci espressive e adattive
- Eseguire function call per agire concretamente
- Ancorare le risposte alla knowledge base aziendale
Viene erogato come API tramite Bedrock: non è quindi necessario ospitare o addestrare i modelli internamente. Questa semplicità abbatte le barriere all'adozione in produzione, anche in ambienti regolamentati o con requisiti stringenti di sicurezza.
Dalla visione all'esecuzione: il contributo di DoiT
In DoiT International riteniamo che ogni iniziativa di AI vocale di successo poggi su tre pilastri fondamentali:
✅ Conversazione naturale, alimentata dalle capacità speech-to-speech unificate di Nova Sonic
✅ Infrastruttura in tempo reale, basata su WebRTC sicuro, streaming e microservizi containerizzati
✅ Controlli di livello enterprise per compliance, governance e monitoraggio
Il nostro team affianca le organizzazioni nel tradurre questi pilastri in pratica, con un framework ben architettato che trasforma la ricerca in deployment sicuri, scalabili e realmente operativi.
Come si concretizza il tutto:
Il blueprint di riferimento mette insieme un front end WebRTC sicuro, microservizi containerizzati su AWS Fargate e un backend Nova Sonic gestito da Bedrock per conversazioni voice-to-voice in tempo reale. IAM basato su ruoli, gestione sicura dei segreti, distribuzione CloudFront e observability completa chiudono il quadro, garantendo affidabilità su larga scala.
Per maggiori informazioni, La invitiamo a consultare il nostro repository GitHub di riferimento. La preghiamo di tenere presente che questo repository è destinato esclusivamente a scopi di valutazione e test e non è ancora adatto al deployment in produzione.
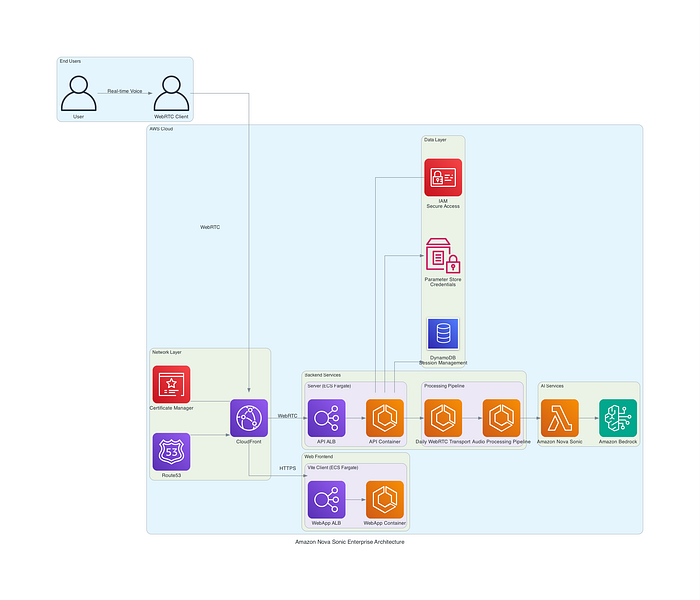
Figura 1: diagramma architetturale di alto livello che illustra l'integrazione completa del sistema tra componenti frontend, servizi backend e risorse AWS cloud.
Componenti dell'architettura AWS
L'implementazione di Nova Sonic si appoggia su diversi servizi AWS chiave:
- Servizio Nova Sonic ✅ Capacità core di AI speech-to-speech
✅ Elaborazione audio in tempo reale
✅ Generazione di risposte in streaming
✅ Opzioni di personalizzazione vocale 2. Amazon Bedrock ✅ Integrazione di foundation model
✅ Generazione di risposte context-aware
✅ Capacità di function calling
✅ Gestione della conoscenza 3. Container Services ✅ ECS Fargate per servizi backend containerizzati
✅ Auto-scaling in base alla domanda
✅ Ottimizzazione delle risorse
✅ Automazione del deployment 4. Servizi di supporto ✅ CloudFront per la distribuzione globale dei contenuti
✅ DynamoDB per la gestione dello stato
✅ S3 per l'archiviazione delle registrazioni
✅ CloudWatch per l'observability
Punti di integrazione chiave
L'architettura ruota attorno a diversi punti di integrazione critici:
- Integrazione frontend-backend ✅ Signaling WebRTC tramite endpoint FastAPI
✅ Scambio sicuro delle credenziali di room
✅ Inizializzazione dei media stream
✅ Sincronizzazione dello stato di connessione 2. Integrazione backend-AWS ✅ Autenticazione sicura ai servizi AWS
✅ Connessioni in streaming a Nova Sonic
✅ Sincronizzazione dello stato con DynamoDB
✅ Integrazione del monitoraggio con CloudWatch 3. Integrazione dei componenti della pipeline ✅ Interfacce frame standardizzate
✅ Comunicazione event-driven
✅ Flusso dati bidirezionale
✅ Architettura a componenti modulari
Considerazioni su sicurezza e scalabilità
L'implementazione integra funzionalità di sicurezza e scalabilità di livello enterprise:
- Misure di sicurezza ✅ Autenticazione di room basata su token
✅ Trasmissione media cifrata
✅ Gestione sicura delle credenziali
✅ Controllo accessi basato sui ruoli 2. Strategia di scaling ✅ Scaling orizzontale dei servizi backend
✅ Connection pooling per un uso efficiente delle risorse
✅ Deployment regionale per copertura globale
✅ Auto-scaling basato sulle metriche di connessione 3. Caratteristiche di resilienza ✅ Gestione automatica della riconnessione
✅ Degradazione controllata in caso di disservizi
✅ Gestione completa degli errori
✅ Meccanismi di recupero della sessione
Questa architettura offre un blueprint per le organizzazioni che vogliono adottare Nova Sonic in ambienti enterprise, con particolare attenzione a sicurezza, scalabilità e integrazione con i sistemi esistenti.
Architettura della pipeline di voice processing
La capacità rivoluzionaria di Amazon Nova Sonic poggia su una pipeline di voice processing avanzata, che abilita interazioni speech-to-speech in tempo quasi reale. A differenza degli assistenti vocali tradizionali, che elaborano le frasi complete prima di rispondere, Nova Sonic processa i flussi audio in modo continuo e bidirezionale, garantendo un dialogo naturale con latenza minima.
La pipeline di voice processing si articola nei seguenti componenti chiave:
- Livello di acquisizione e streaming audio ✅ Protocollo WebRTC per la trasmissione audio in tempo reale
✅ Elaborazione audio nel browser con cancellazione dell'eco e riduzione del rumore
✅ Codifica a bitrate adattivo in base alle condizioni di rete 2. Componente di riconoscimento vocale ✅ ASR (Automatic Speech Recognition) in streaming continuo
✅ Riconoscimento a livello fonemico a bassa latenza
✅ Modellazione linguistica context-aware per maggiore accuratezza 3. Motore di elaborazione semantica ✅ Rilevamento dell'intento in tempo reale, mentre l'utente sta ancora parlando
✅ Gestione del contesto multi-turno per la coerenza della conversazione
✅ Formulazione e ottimizzazione delle query per l'interazione con l'LLM 4. Backend di AI generativa Nova Sonic ✅ Generazione di token in streaming con buffering minimo
✅ Sintesi vocale neurale con personalizzazione della voce
✅ Controllo di prosodia e tono per un output vocale naturale 5. Generazione e mixing dell'output ✅ Mixing audio dinamico per una conversazione fluida
✅ Tecniche di ottimizzazione della latenza
✅ Loop di feedback in tempo reale per il controllo della qualità audio
Flusso di comunicazione WebRTC
L'implementazione WebRTC abilita flussi audio bidirezionali sicuri e a bassa latenza tra l'applicazione client e il servizio Nova Sonic:
- Apertura della sessione ✅ Il protocollo ICE (Interactive Connectivity Establishment) individua i percorsi di rete ottimali
✅ I server STUN/TURN facilitano l'attraversamento del NAT
✅ SDP (Session Description Protocol) negozia le capacità multimediali 2. Trasmissione media sicura ✅ DTLS (Datagram Transport Layer Security) garantisce la cifratura
✅ SRTP (Secure Real-time Transport Protocol) assicura uno streaming audio sicuro
✅ Adattamento della banda in base alle condizioni di rete 3. Elaborazione audio ✅ Elaborazione audio lato client (cancellazione dell'eco, soppressione del rumore)
✅ Miglioramento audio lato server
✅ Tecniche di occultamento della perdita di pacchetti
Architettura AWS e orchestrazione delle funzioni
L'implementazione sfrutta diversi servizi AWS in un'architettura scalabile e resiliente:
- Componenti client-facing ✅ Distribuzione CloudFront per la consegna globale dei contenuti
✅ Application Load Balancer per la distribuzione del traffico
✅ ECS Fargate per l'hosting di applicazioni containerizzate 2. Pipeline di elaborazione ✅ Amazon Bedrock per le capacità di AI generativa
✅ Amazon Transcribe per il riconoscimento vocale
✅ Amazon Polly per la sintesi vocale
✅ Funzioni Lambda personalizzate per l'orchestrazione 3. Servizi backend ✅ DynamoDB per la gestione delle sessioni e dei metadati
✅ Parameter Store per la gestione sicura delle credenziali
✅ CloudWatch per logging e monitoraggio completi 4. Livello di sicurezza ✅ Certificati ACM per la cifratura TLS
✅ Ruoli IAM per un controllo accessi granulare
✅ AWS WAF per la protezione tramite web application firewall
L'implementazione AWS adotta l'infrastructure as code (IaC) tramite AWS CDK, abilitando deployment riproducibili e ambienti coerenti. L'architettura segue i principi dell'AWS Well-Architected Framework in materia di sicurezza, affidabilità, efficienza delle prestazioni, ottimizzazione dei costi ed eccellenza operativa.
Ottimizzazione delle prestazioni
Le prestazioni a bassa latenza di Nova Sonic sono il risultato di diverse ottimizzazioni tecniche:
- Ottimizzazione dell'inferenza in streaming ✅ Elaborazione parallela dei chunk audio
✅ Strategie di buffering adattivo
✅ Generazione anticipata della risposta a partire da input parziali 2. Riduzione della latenza di rete ✅ Modello di deployment edge computing
✅ Connection pooling per i servizi backend
✅ Deployment regionale per la prossimità agli utenti finali 3. Scaling delle risorse ✅ Auto-scaling dei servizi ECS in base alla domanda
✅ Capacità riservata per prestazioni costanti
✅ Distribuzione dei workloads tra availability zone
Implementazione dei componenti frontend
L'implementazione frontend di Nova Sonic mostra come le moderne tecnologie web possano abilitare interazioni vocali in tempo reale con latenza minima. Il codice nella directory /vite-client propone un approccio production-ready alla costruzione di interfacce di AI vocale che risultano naturali e reattive.
Implementazione del client WebRTC
L'implementazione WebRTC lato client è incapsulata nella classe ChatbotClient all'interno di app.js, che si occupa del ciclo di vita della connessione e della gestione dei media:
class ChatbotClient {
constructor() {
// Initialize client state
this.rtviClient = null;
this.videoManager = null;
this.setupDOMElements();
this.setupEventListeners();
this.initializeClientAndTransport();
}
// ...
}
L'implementazione fa leva su librerie specializzate:
@pipecat-ai/client-js: fornisce la classeRTVIClientper le interazioni vocali in tempo reale@pipecat-ai/daily-transport: abilita la comunicazione WebRTC tramite l'infrastruttura Daily.co. I primi 10.000 minuti partecipante sono gratuiti.
Le caratteristiche chiave dell'implementazione WebRTC includono:
- Astrazione del transport layer ✅ Incapsulamento della complessità WebRTC tramite un'interfaccia di trasporto
✅ Gestione automatica della negoziazione dei candidati ICE
✅ Strategie di riconnessione fluide in caso di interruzioni di rete 2. Gestione dei media stream ✅ Sottoscrizione e annullamento dinamico delle tracce
✅ Negoziazione automatica del formato media
✅ Qualità media ottimizzata in base alle condizioni di banda 3. Gestione dello stato di connessione ✅ Transizioni di stato robuste (connecting, connected, disconnected)
✅ Architettura event-driven per aggiornamenti UI reattivi
✅ Gestione completa degli errori di connessione
Componenti per la gestione di microfono e telecamera
Il progetto implementa una gestione sofisticata dei dispositivi multimediali tramite la classe VideoManager, che fornisce:
- Inizializzazione del dispositivo e flusso dei permessi ✅ Richieste di permesso per la telecamera user-friendly
✅ Gestione dettagliata degli errori in caso di permesso negato
✅ Feedback visivo durante l'inizializzazione del dispositivo 2. Gestione delle tracce media ✅ Gestione separata delle tracce media locali e remote
✅ Ottimizzazione della qualità per i flussi video
✅ Pulizia automatica delle tracce alla disconnessione 3. Integrazione degli elementi media ✅ Creazione e configurazione dinamica di elementi audio/video
✅ Adattamento responsive del layout
✅ Impostazioni di playback ottimizzate per la bassa latenza
Questo esempio tratto da VideoManager.js mostra come vengono inizializzati i flussi della telecamera:
async toggleLocalCamera() {
try {
// Request camera access through the browser
const stream = await navigator.mediaDevices.getUserMedia({
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
});
// Store the stream for later use
this._localStream = stream;
// Update the local video element with this stream
this.localVideo.srcObject = stream;
// Ensure the video plays
await this.localVideo.play();
} catch (error) {
// Handle permission errors with user-friendly messaging
}
}
Interfaccia utente per l'interazione vocale
L'interfaccia utente è progettata per un'interazione vocale intuitiva e offre le seguenti funzionalità:
- Controlli di connessione ✅ Indicatori visivi chiari dello stato di connessione
✅ Connessione e disconnessione con un solo clic
✅ Interfaccia di gestione dei permessi 2. Feedback visivo ✅ Visualizzazione della trascrizione in tempo reale
✅ Indicatori visivi animati durante il parlato del bot
✅ Indicatori dello stato di connessione 3. Funzionalità di debug ✅ Interfaccia di logging completa
✅ Monitoraggio delle statistiche di rete
✅ Visualizzazione dei livelli audio
Tecnologie e librerie chiave del frontend
L'implementazione frontend si appoggia su diverse moderne tecnologie web:
- Vite — per uno sviluppo rapido e build di produzione ottimizzate
- API WebRTC — per la comunicazione audio/video in tempo reale
- Media Streams API — per accedere a telecamere e microfoni del dispositivo
- Containerizzazione — configurazione Docker per un deployment coerente
- Nginx — per il serving dei file statici e il proxying opzionale
Gestione della connessione con il backend
La connessione tra frontend e backend è gestita da un protocollo robusto che:
- Stabilisce connessioni sicure basate su room ✅ Ottiene le credenziali della room dall'endpoint
/connectdel backend
✅ Protegge le connessioni con token
✅ Gestisce gli eventi dei partecipanti (ingresso, uscita) 2. Gestisce la trasmissione media in modo efficiente ✅ Implementa l'adattamento della banda
✅ Gestisce le transizioni di rete
✅ Fornisce metriche di qualità e diagnostica 3. Ottimizza per l'interazione vocale a bassa latenza ✅ Configura gli elementi audio per ridurre al minimo il ritardo di elaborazione
✅ Implementa l'ottimizzazione del buffering audio
✅ Sfrutta l'accelerazione hardware quando disponibile
Questa architettura permette di raggiungere la latenza critica sotto i 300 ms che rende le conversazioni con Nova Sonic naturali e fluide.
Implementazione dei componenti backend
L'implementazione lato server presente nella directory /server mostra come costruire un backend scalabile e production-ready per applicazioni di AI vocale Nova Sonic. Illustra i pattern di integrazione e le scelte architetturali necessarie per portare in produzione soluzioni di AI vocale di livello enterprise.
WebRTC con implementazione Daily Transport
Il backend si appoggia all'infrastruttura di Daily.co per la gestione delle sessioni WebRTC, attraverso un'implementazione di trasporto specializzata:
# Set up Daily transport with video/audio parameters
transport = DailyTransport(
room_url,
token,
"Chatbot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
video_in_enabled=True,
video_out_enabled=True,
video_out_width=1024,
video_out_height=576,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=True,
),
)
Le caratteristiche chiave di questa implementazione di trasporto includono:
- Gestione delle room ✅ Creazione dinamica di room sicure
✅ Autenticazione basata su token
✅ Pulizia automatica delle risorse inutilizzate 2. Configurazione media ✅ Controllo indipendente di input e output audio/video
✅ Impostazioni di risoluzione e qualità
✅ Integrazione del Voice Activity Detection (VAD) 3. Gestione degli eventi ✅ Sistema di eventi completo per i cambiamenti di stato del trasporto
✅ Gestione del ciclo di vita dei partecipanti
✅ Controllo e gestione delle registrazioni
Pattern di function call per l'integrazione di tool
L'implementazione presenta pattern avanzati di function calling che abilitano l'integrazione di tool con l'LLM:
# Register functions with the LLM service
register_functions(llm)
# Set up context with function schemas
context = OpenAILLMContext(
messages=[\
{"role": "system", "content": f"{system_instruction}"},\
{\
"role": "user",\
"content": "Hello, I'm here for my interview.",\
},\
],
tools=function_tools_schema,
)
Questa architettura abilita:
- Sistema di registrazione dei tool ✅ Registrazione dinamica degli schemi di funzione
✅ Interfacce di funzione type-safe
✅ Supporto per funzioni sincrone e asincrone 2. Gestione del contesto ✅ Conservazione del contesto conversazionale tra le interazioni
✅ Windowing efficiente del contesto per le conversazioni lunghe
✅ Tracciamento stateful delle conversazioni 3. Esecuzione delle funzioni ✅ Esecuzione sicura delle funzioni dei tool
✅ Gestione degli errori e meccanismi di retry
✅ Inserimento dei risultati nel contesto conversazionale
Architettura della pipeline e suoi componenti
Il backend implementa una sofisticata architettura a pipeline basata sul framework Pipecat:
pipeline = Pipeline(
[\
transport.input(),\
rtvi,\
context_aggregator.user(),\
llm,\
ta,\
transport.output(),\
context_aggregator.assistant(),\
]
)
Questo approccio a pipeline offre:
- Catena di elaborazione modulare ✅ Chiara separazione delle responsabilità
✅ Componenti pluggable per la personalizzazione
✅ Interfacce standardizzate per l'elaborazione dei frame 2. Flusso dati bidirezionale ✅ Elaborazione dell'input dall'utente al sistema
✅ Elaborazione dell'output dal sistema all'utente
✅ Propagazione degli eventi in entrambe le direzioni 3. Integrazione con l'observability ✅ Raccolta di metriche a livello di pipeline
✅ Diagnostica a livello di componente
✅ Punti di monitoraggio delle prestazioni
Elaborazione e gestione dell'audio
L'implementazione include sofisticate capacità di elaborazione audio:
- Voice Activity Detection ✅ Rilevamento dell'attività vocale basato su ML tramite Silero VAD
✅ Regolazione dinamica delle soglie
✅ Rilevamento del parlato resistente al rumore 2. Gestione della trascrizione ✅ Conversione speech-to-text in tempo reale
✅ Gestione dei risultati parziali per un feedback immediato
✅ Sincronizzazione del trascritto finale 3. Ottimizzazione dell'output audio ✅ Mixing dinamico dei flussi audio
✅ Tecniche di gestione della latenza
✅ Sincronizzazione del playback
Integrazione con i servizi AWS Nova Sonic
Il cuore dell'implementazione è l'integrazione con i servizi AWS Nova Sonic:
# Initialize AWS Nova Sonic LLM service
llm = AWSNovaSonicLLMService(
secret_access_key=NOVA_AWS_SECRET_ACCESS_KEY,
access_key_id=NOVA_AWS_ACCESS_KEY_ID,
region=os.getenv("NOVA_AWS_REGION", "us-east-1"),
voice_id=os.getenv("NOVA_VOICE_ID", "tiffany"),
send_transcription_frames=True
)
Questa integrazione mette in luce:
- Autenticazione sicura ✅ Gestione delle credenziali AWS
✅ Controllo accessi basato sui ruoli
✅ Gestione sicura delle variabili d'ambiente 2. Personalizzazione vocale ✅ Selezione e configurazione della voce
✅ Caratteristiche di prosodia e parlato
✅ Opzioni di supporto multilingue 3. Ottimizzazione dello streaming ✅ Streaming di token in tempo reale
✅ Generazione progressiva delle risposte
✅ Configurazione a latenza minima 4. Funzionalità avanzate ✅ Integrazione dei frame di trascrizione
✅ Risposte context-aware
✅ Gestione delle interruzioni
Action plan executive per l'AI generativa vocale
Ecco un playbook pratico per partire:
- Identifichi le esperienze, di clienti o dipendenti, che possono trarre maggior beneficio da interazioni vocali più rapide e naturali
- Costruisca un business case incentrato su costi, esperienza o crescita dei ricavi
- Selezioni i partner in grado di offrire il giusto mix di competenze cloud, AI e sicurezza
- Avvii un pilota e misuri i risultati con criteri di successo chiari
- Predisponga controlli di governance e sicurezza in vista della scalabilità
- Effettui il rollout per fasi, sfruttando infrastructure-as-code e pattern di observability consolidati
Uno sguardo al futuro
La voce è l'interfaccia più naturale di cui disponiamo. Grazie all'AI generativa, oggi può essere scalabile, sicura e intelligente quanto i sistemi text-based. Il futuro dell'engagement con clienti e dipendenti si costruirà su conversazioni voice-first, dal tono umano.
Per le organizzazioni lungimiranti, il momento di investire è proprio adesso.
In DoiT International uniamo competenze profonde in cloud, sicurezza e AI generativa per aiutarLa a fare delle soluzioni voice-first un successo, in modo affidabile e su larga scala.
Costruiamo insieme la prossima generazione di AI conversazionale. Contatti DoiT International oggi stesso!