生成AI時代に、リアルタイムの音声ファーストAIをどう導入するか。経営視点で読み解きます。

次なるフロンティア——なぜ今、音声なのか
会話型AIは大きな転換点を迎えています。音声はもはや目新しい存在ではなく、企業が顧客・従業員・パートナーとつながるうえで、最も人間らしく、効率的で、感情の機微まで伝えられる手段です。そして今、Speech-to-Speech方式の生成AIによって、音声ファーストの体験はようやく実用的でスケーラブル、かつコスト効率にも優れたものになりました。動き出すなら、今です。
なぜ今なのか
なぜ今、この変化が起きているのでしょうか。背景にはいくつかの重要な潮流があります。
- Amazon Nova Sonicに代表される統合型Speech-to-Speech大規模言語モデルが、音声認識・推論・音声生成を単一のリアルタイムアーキテクチャに集約
- 会話の品質を高めながら、レイテンシを劇的に短縮
- シームレスな音声対話を求める顧客・従業員の期待が、かつてなく高まっている
成熟した生成AI技術と高まるユーザー期待の重なりが、何が実現可能で、何が競争優位を生むのかを塗り替えつつあります。
音声AIアシスタントとは
音声AIアシスタントとは、自然な話し言葉で聞き、考え、応答する会話型エージェントです。複雑なマルチターン対話をリアルタイムにこなし、エンタープライズグレードのセキュリティとガバナンスを前提に設計されている点で、従来のスクリプト型ボットとは一線を画します。
主な特徴は次のとおりです。
- 機械的な間を感じさせない、滑らかな応答
- 感情やトーンの反映
- ニュアンスを含むユーザーの意図理解
- 社内ナレッジとの連携やアクション実行
こうした特性により、人事面接、カスタマーサービス、能動的なセールスコール、従業員コーチングなど、多様なユースケースに最適です。
音声生成AIがもたらすビジネス価値
音声AIの導入を検討する経営層にとって、ビジネスケースは明快です。
- 定型的な音声対応を自動化し、運用コストを削減
- より自然で共感的な会話により、顧客満足度を向上
- 言語・地域を問わず、24時間365日の対応を実現
- 能動的な音声アウトリーチによる新たな収益機会の創出
- 従業員に、必要なときすぐ使えるオンデマンドの音声ナレッジアシスタントを提供
音声は、人々が最も好むチャネルです。生成AIによって、それがようやくスケーラブルかつ安全で、品質の揃ったものになりました。
STT→LLM→TTSから統合型Speech-to-Speechへ——パラダイムシフト
従来の音声AIシステムは、独立したコンポーネントを直列につないだカスケード型パイプラインとして構築されてきました。これはしばしばSTT→LLM→TTS、すなわちSpeech-to-Text→Large Language Model→Text-to-Speechと表現されます。一般的な音声アシスタントやコールボットでは、音声入力は次のような流れで処理されます。
- 自動音声認識(ASR):ユーザーの発話を、Speech-to-Textモデル(Amazon TranscribeやGoogle Speech APIなど)でテキスト化します。
- 言語理解 / LLM処理:書き起こされたテキストを言語モデルや対話マネージャー(LLMなど)に渡し、ユーザーの問い合わせと文脈に基づいたテキスト応答を生成します。
- Text-to-Speech(TTS)合成:AIのテキスト応答を、音声合成エンジン(Amazon PollyやGoogleのWaveNetなど)で音声に変換します。
- 音声再生:合成された音声を、回答としてユーザーに再生します。
各ステップは個別のモデルやサービスで構成されることが多く、順序立ててオーケストレーションする必要がありました。AWSのリファレンスアーキテクチャでも採用されているDailyのオープンソースフレームワークPipecatは、このパイプライン方式の代表例です。音声ストリーミング用のWebRTC、発話の有無を検出するボイスアクティビティ検出器、ASR用のAmazon Transcribe、NLU/NLG用のLLM(Amazon Novaテキストモデル)、TTS用のAmazon Pollyを組み合わせています。下の図1は、エンタープライズ環境におけるこうしたカスケード型音声AIアーキテクチャを示しており、複数のAWSサービスが連携して、ひとつのユーザー問い合わせをエンドツーエンドで処理しています。
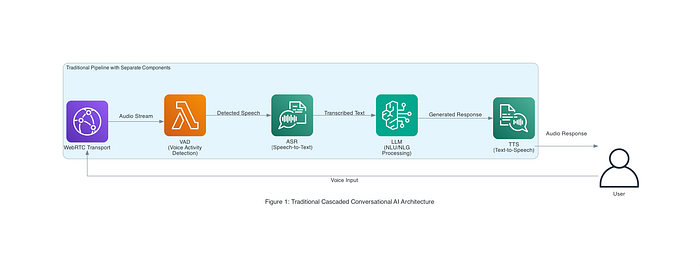
図1:従来型のカスケード型会話AIアーキテクチャ(AWS Pipecatリファレンスより)。音声入力はWebRTCトランスポート、VAD(ボイスアクティビティ検出)、ASR(Speech-to-Text)、NLU/NLG用LLM、応答用TTSの順に処理されます。各コンポーネントは処理時間と障害ポイントを増やす要因になります。
このモジュール型パイプラインには、各タスクに特化したコンポーネントを使い分けられる利点がある一方、欠点もあります。サービス間の受け渡しがレイテンシを生み、ユーザーが話し終えるまでAIが応答を組み立てられず、会話に目立った間が生じがちです。各コンポーネントには誤認識やぎこちないTTS出力といったエラーが付きものであり、それらが積み重なって会話品質を損ないます。さらに、ASRとTTSが互いの細部や会話の感情的なトーンを共有していないため、会話の一貫性を保つことも難しくなります。要するに、システム遅延と分断されたコンポーネント同士のすれ違いによって、対話が不自然に感じられてしまうのです。
Amazon Nova Sonic——技術的ブレークスルー
AmazonのNova Sonicは、大きな飛躍をもたらしました。Speech-to-Text、推論、Text-to-Speechという別々のコンポーネントを継ぎ合わせるのではなく、会話プロセス全体をひとつの合理化された安全なパイプラインに統合しているのです。
Nova Sonicの主な特長は次のとおりです。
- リアルタイムに聞き取り、理解する
- 人間らしい応答を生成する
- 表現豊かで適応性のある音声で話す
- 関数呼び出しによりアクションを実行する
- 社内ナレッジに根ざした回答を返す
BedrockのAPIとして提供されるため、自前でモデルをホスティングしたり学習させたりする必要はありません。このシンプルさが、規制業界やセキュリティ要件の厳しい環境においても、本番導入のハードルを大きく下げます。
構想から実行へ——DoiTの支援
DoiT Internationalは、音声AIの取り組みを成功に導くには3つの柱が欠かせないと考えています。
✅ Nova Sonicの統合型Speech-to-Speech機能による自然な会話
✅ 安全なWebRTC、ストリーミング、コンテナ化マイクロサービスで構築されたリアルタイムインフラ
✅ コンプライアンス、ガバナンス、モニタリングを担保するエンタープライズグレードの統制
当社のチームは、これらの柱を実装に落とし込むウェルアーキテクテッドなフレームワークを通じて、研究成果を安全でスケーラブルな実運用システムへと変えていきます。
全体像:
このリファレンス設計は、安全なWebRTCフロントエンド、AWS Fargate上のコンテナ化マイクロサービス、Bedrockマネージドの Nova Sonicバックエンドを組み合わせ、リアルタイムの音声対音声会話を実現します。ロールベースのIAM、セキュアなシークレット管理、CloudFront配信、包括的なオブザーバビリティが設計を完成させ、スケール時の信頼性を支えます。
詳細は、リファレンスGitHubリポジトリをご覧ください。なお、本リポジトリは評価・検証目的を想定しており、本番環境への導入にはまだ適していません。
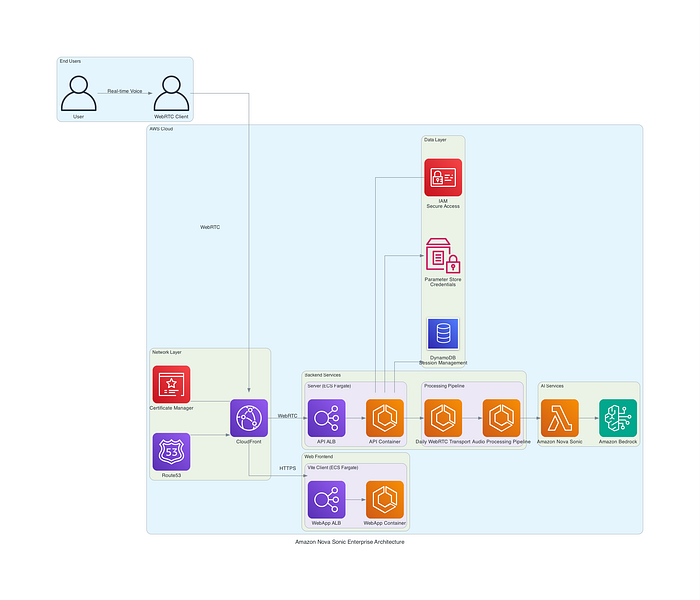
図1:フロントエンド、バックエンドサービス、AWSクラウドリソースを横断したシステム統合の全体像を示すハイレベルアーキテクチャ図。
AWSアーキテクチャの構成要素
Nova Sonicの実装では、以下の主要なAWSサービスを活用しています。
- Nova Sonicサービス ✅ コアとなるSpeech-to-Speech AI機能
✅ リアルタイム音声処理
✅ ストリーミング応答生成
✅ 音声カスタマイズオプション 2. Amazon Bedrock ✅ 基盤モデルとの統合
✅ 文脈を踏まえた応答生成
✅ 関数呼び出し機能
✅ ナレッジ管理 3. コンテナサービス ✅ コンテナ化バックエンド向けのECS Fargate
✅ 需要に応じたオートスケーリング
✅ リソース最適化
✅ デプロイ自動化 4. サポートサービス ✅ グローバルコンテンツ配信用のCloudFront
✅ ステート管理用のDynamoDB
✅ 録音保存用のS3
✅ オブザーバビリティ用のCloudWatch
主要な統合ポイント
このアーキテクチャは、いくつかの重要な統合ポイントを軸に構築されています。
- フロントエンドとバックエンドの統合 ✅ FastAPIエンドポイント経由のWebRTCシグナリング
✅ セキュアなルーム認証情報の交換
✅ メディアストリームの初期化
✅ 接続状態の同期 2. バックエンドとAWSの統合 ✅ AWSサービスへのセキュアな認証
✅ Nova Sonicへのストリーミング接続
✅ DynamoDBによる状態同期
✅ CloudWatchによるモニタリング統合 3. パイプラインコンポーネントの統合 ✅ 標準化されたフレームインターフェース
✅ イベント駆動型の通信
✅ 双方向のデータフロー
✅ モジュール型のコンポーネント構成
セキュリティとスケーリングに関する考慮事項
本実装には、エンタープライズグレードのセキュリティとスケーリング機能が組み込まれています。
- セキュリティ対策 ✅ トークンベースのルーム認証
✅ メディア伝送の暗号化
✅ セキュアな認証情報管理
✅ ロールベースアクセス制御 2. スケーリング戦略 ✅ バックエンドサービスの水平スケーリング
✅ 効率的なリソース利用のためのコネクションプーリング
✅ グローバル対応のためのリージョン展開
✅ 接続メトリクスに基づくオートスケーリング 3. レジリエンス機能 ✅ 自動再接続の処理
✅ サービス障害時のグレースフルデグラデーション
✅ 包括的なエラーハンドリング
✅ セッション復旧の仕組み
このアーキテクチャは、セキュリティ・スケーラビリティ・既存システムとの統合に重点を置き、エンタープライズ環境でNova Sonicを導入したい組織のための設計図となります。
音声処理パイプラインのアーキテクチャ
Amazon Nova Sonicの画期的な能力は、ほぼリアルタイムのSpeech-to-Speech対話を可能にする高度な音声処理パイプラインに支えられています。発話を最後まで聞き終えてから応答する従来の音声アシスタントとは異なり、Nova Sonicは音声ストリームを双方向に連続処理することで、最小限のレイテンシで自然な会話の流れを生み出します。
音声処理パイプラインは、以下の主要コンポーネントで構成されます。
- 音声キャプチャ・ストリーミング層 ✅ リアルタイム音声伝送のためのWebRTCプロトコル
✅ エコーキャンセルとノイズ低減を備えたブラウザベースの音声処理
✅ ネットワーク状況に応じたアダプティブビットレートエンコーディング 2. 音声認識コンポーネント ✅ 連続ストリーミングASR(自動音声認識)
✅ 低レイテンシの音素レベル認識
✅ 精度を高める文脈考慮型の言語モデリング 3. 意味解析エンジン ✅ ユーザーの発話中にリアルタイムで意図を検出
✅ 会話の一貫性を保つマルチターンのコンテキスト管理
✅ LLMとのやり取りに向けたクエリ生成と最適化 4. Nova Sonic生成AIバックエンド ✅ 最小限のバッファリングによるストリーミングトークン生成
✅ 音声カスタマイズに対応したニューラル音声合成
✅ 自然な発話のためのプロソディ・トーン制御 5. 出力生成・ミキシング ✅ シームレスな会話のためのダイナミック音声ミキシング
✅ レイテンシ最適化技術
✅ 音声品質を制御するリアルタイムのフィードバックループ
WebRTC通信フロー
WebRTCを採用することで、クライアントアプリケーションとNova Sonicサービスの間に、安全かつ低レイテンシの双方向音声ストリームが実現します。
- セッションの確立 ✅ ICE(Interactive Connectivity Establishment)プロトコルが最適なネットワーク経路を特定
✅ STUN/TURNサーバーがNATトラバーサルを支援
✅ SDP(Session Description Protocol)がメディア機能をネゴシエート 2. セキュアなメディア伝送 ✅ DTLS(Datagram Transport Layer Security)による暗号化
✅ SRTP(Secure Real-time Transport Protocol)による安全な音声ストリーミング
✅ ネットワーク状況に応じた帯域適応 3. 音声処理 ✅ クライアント側の音声処理(エコーキャンセル、ノイズ抑制)
✅ サーバー側の音声品質強化
✅ パケットロス補償技術
AWSアーキテクチャと関数オーケストレーション
本実装では、スケーラブルかつ堅牢なアーキテクチャの中で、複数のAWSサービスを活用しています。
- クライアント向けコンポーネント ✅ グローバルコンテンツ配信用のCloudFrontディストリビューション
✅ トラフィック分散用のApplication Load Balancer
✅ コンテナ化アプリケーションのホスティング用ECS Fargate 2. 処理パイプライン ✅ 生成AI機能のためのAmazon Bedrock
✅ 音声認識用のAmazon Transcribe
✅ 音声合成用のAmazon Polly
✅ オーケストレーション用のカスタムLambda関数 3. バックエンドサービス ✅ セッション管理とメタデータ用のDynamoDB
✅ 認証情報のセキュアな管理に使うParameter Store
✅ 包括的なロギング・モニタリング用のCloudWatch 4. セキュリティ層 ✅ TLS暗号化用のACM証明書
✅ きめ細かなアクセス制御を担うIAMロール
✅ Webアプリケーションファイアウォールとして機能するAWS WAF
AWS実装では、AWS CDKによるインフラストラクチャ・アズ・コード(IaC)を採用し、再現性のあるデプロイと一貫した環境を実現しています。アーキテクチャはAWS Well-Architectedフレームワークの原則に沿っており、セキュリティ、信頼性、パフォーマンス効率、コスト最適化、運用上の優秀性を満たしています。
パフォーマンス最適化
Nova Sonicの低レイテンシは、いくつかの技術的な最適化によって実現されています。
- ストリーミング推論の最適化 ✅ 音声チャンクの並列処理
✅ アダプティブなバッファリング戦略
✅ 部分入力に基づく早期応答生成 2. ネットワークレイテンシの低減 ✅ エッジコンピューティングのデプロイモデル
✅ バックエンドサービス向けのコネクションプーリング
✅ エンドユーザーに近接させるリージョン展開 3. リソースのスケーリング ✅ 需要に応じたECSサービスのオートスケーリング
✅ 安定したパフォーマンスのための予約キャパシティ
✅ アベイラビリティゾーンをまたいだワークロード分散
フロントエンドコンポーネントの実装
Nova Sonicのフロントエンド実装は、最新のWeb技術を用いて、最小限のレイテンシでリアルタイム音声対話を実現する方法を示しています。/vite-clientディレクトリのコードは、自然で応答性の高い音声AIインターフェースを構築するための、本番運用にも耐えうるアプローチを提示します。
WebRTCクライアントの実装
クライアント側のWebRTC実装は、app.js内のChatbotClientクラスにカプセル化されており、接続のライフサイクルとメディア管理を担います。
class ChatbotClient {
constructor() {
// Initialize client state
this.rtviClient = null;
this.videoManager = null;
this.setupDOMElements();
this.setupEventListeners();
this.initializeClientAndTransport();
}
// ...
}
本実装では、専用のライブラリを活用しています。
@pipecat-ai/client-js:リアルタイム音声対話用のRTVIClientクラスを提供@pipecat-ai/daily-transport:Daily.coのインフラを介したWebRTC通信を実現。最初の10,000参加者分は無料です。
WebRTC実装の主な特徴は次のとおりです。
- トランスポート層の抽象化 ✅ トランスポートインターフェースによってWebRTCの複雑さをカプセル化
✅ ICE候補ネゴシエーションの自動処理
✅ ネットワーク障害時のシームレスな再接続戦略 2. メディアストリーム管理 ✅ トラックの動的なサブスクライブ・解除
✅ メディアフォーマットの自動ネゴシエーション
✅ 帯域状況に応じたメディア品質の最適化 3. 接続状態の管理 ✅ 堅牢な状態遷移(接続中、接続済み、切断済み)
✅ UIを軽快に更新するイベント駆動型アーキテクチャ
✅ 接続失敗時の包括的なエラーハンドリング
マイクとカメラのハンドリングコンポーネント
本プロジェクトでは、VideoManagerクラスを通じて高度なメディアデバイス管理を実装しています。提供される機能は次のとおりです。
- デバイス初期化と権限フロー ✅ ユーザーフレンドリーなカメラ権限リクエスト
✅ 権限拒否時の詳細なエラーハンドリング
✅ デバイス初期化中の視覚的なフィードバック 2. メディアトラック管理 ✅ ローカルとリモートのメディアトラックを個別にハンドリング
✅ ビデオストリームの品質最適化
✅ 切断時のトラック自動クリーンアップ 3. メディア要素の統合 ✅ 音声/映像要素の動的な生成と構成
✅ レスポンシブなレイアウト適応
✅ 低レイテンシ向けに最適化された再生設定
以下はVideoManager.jsからの抜粋で、カメラストリームを初期化する流れを示しています。
async toggleLocalCamera() {
try {
// Request camera access through the browser
const stream = await navigator.mediaDevices.getUserMedia({
video: {
width: { ideal: 1280 },
height: { ideal: 720 }
}
});
// Store the stream for later use
this._localStream = stream;
// Update the local video element with this stream
this.localVideo.srcObject = stream;
// Ensure the video plays
await this.localVideo.play();
} catch (error) {
// Handle permission errors with user-friendly messaging
}
}
音声対話のためのユーザーインターフェース
ユーザーインターフェースは、直感的な音声対話を支える以下の機能を備えています。
- 接続コントロール ✅ 接続状態が一目で分かるビジュアルインジケーター
✅ ワンクリックでの接続/切断
✅ 権限管理のためのインターフェース 2. 視覚的フィードバック ✅ リアルタイムの書き起こし表示
✅ ボット発話中のアニメーション付きビジュアルインジケーター
✅ 接続ステータスのインジケーター 3. デバッグ機能 ✅ 包括的なロギングインターフェース
✅ ネットワーク統計のモニタリング
✅ オーディオレベルの可視化
主なフロントエンド技術とライブラリ
フロントエンド実装では、複数の最新Web技術を活用しています。
- Vite — 高速な開発と最適化された本番ビルド
- WebRTC API — リアルタイムの音声/映像通信
- Media Streams API — デバイスのカメラとマイクへのアクセス
- コンテナ化 — 一貫したデプロイのためのDocker構成
- Nginx — 静的ファイル配信とオプションのプロキシ機能
バックエンドとの接続管理
フロントエンドとバックエンドの接続は、堅牢なプロトコルで管理されており、以下を実現します。
- セキュアなルームベース接続の確立 ✅ バックエンドの
/connectエンドポイントからルーム認証情報を取得
✅ トークンによる接続のセキュア化
✅ 参加者イベント(参加・退出)の処理 2. メディア伝送の効率的な管理 ✅ 帯域適応の実装
✅ ネットワーク切替への対応
✅ 品質メトリクスと診断情報の提供 3. 低レイテンシの音声対話への最適化 ✅ 処理遅延を最小化する音声要素の構成
✅ 音声バッファリングの最適化
✅ 利用可能な場合はハードウェアアクセラレーションを活用
このアーキテクチャによって、Nova Sonicの会話を自然で滑らかに感じさせる、300ミリ秒未満という重要なレイテンシが実現します。
バックエンドコンポーネントの実装
/serverディレクトリのサーバーサイド実装は、Nova Sonic音声AIアプリケーション向けに、スケーラブルで本番運用に耐えるバックエンドを構築する方法を示しています。エンタープライズグレードの音声AIソリューションをデプロイするうえで必要となる、統合パターンとアーキテクチャの判断軸が読み取れます。
Daily Transportを用いたWebRTC実装
バックエンドは、専用のトランスポート実装を介してDaily.coのインフラを活用し、WebRTCセッションを管理します。
# Set up Daily transport with video/audio parameters
transport = DailyTransport(
room_url,
token,
"Chatbot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
video_in_enabled=True,
video_out_enabled=True,
video_out_width=1024,
video_out_height=576,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=True,
),
)
トランスポート実装の主な特徴は次のとおりです。
- ルーム管理 ✅ セキュアなルームの動的生成
✅ トークンベースの認証
✅ 未使用リソースの自動クリーンアップ 2. メディア構成 ✅ 音声/映像の入出力を独立して制御
✅ 解像度・品質の設定
✅ ボイスアクティビティ検出(VAD)の統合 3. イベント処理 ✅ トランスポートの状態変化を扱う包括的なイベントシステム
✅ 参加者ライフサイクルの管理
✅ 録音の制御と管理
ツール連携のための関数呼び出しパターン
本実装では、LLMとツールを連携させるための高度な関数呼び出しパターンを示しています。
# Register functions with the LLM service
register_functions(llm)
# Set up context with function schemas
context = OpenAILLMContext(
messages=[\
{"role": "system", "content": f"{system_instruction}"},\
{\
"role": "user",\
"content": "Hello, I'm here for my interview.",\
},\
],
tools=function_tools_schema,
)
このアーキテクチャによって、次のことが可能になります。
- ツール登録の仕組み ✅ 関数スキーマの動的登録
✅ 型安全な関数インターフェース
✅ 同期・非同期関数の両方をサポート 2. コンテキスト管理 ✅ やり取りをまたいだ会話コンテキストの保持
✅ 長い会話に対する効率的なコンテキストウィンドウ管理
✅ ステートフルな会話のトラッキング 3. 関数の実行 ✅ ツール関数のセキュアな実行
✅ エラーハンドリングとリトライの仕組み
✅ 実行結果を会話コンテキストへ反映
パイプラインアーキテクチャとコンポーネント
バックエンドは、Pipecatフレームワークを用いて高度なパイプラインアーキテクチャを実装しています。
pipeline = Pipeline(
[\
transport.input(),\
rtvi,\
context_aggregator.user(),\
llm,\
ta,\
transport.output(),\
context_aggregator.assistant(),\
]
)
このパイプラインアプローチが提供するものは、次のとおりです。
- モジュール型の処理チェーン ✅ 責務の明確な分離
✅ カスタマイズ可能なプラガブルコンポーネント
✅ 標準化されたフレーム処理インターフェース 2. 双方向のデータフロー ✅ ユーザーからシステムへの入力処理
✅ システムからユーザーへの出力処理
✅ 双方向のイベント伝播 3. オブザーバビリティ統合 ✅ パイプラインレベルのメトリクス収集
✅ コンポーネントレベルの診断情報
✅ パフォーマンスモニタリングのポイント
音声処理とハンドリング
本実装には、高度な音声処理機能が組み込まれています。
- ボイスアクティビティ検出 ✅ Silero VADを用いたMLベースのボイスアクティビティ検出
✅ しきい値の動的調整
✅ ノイズに強い発話検出 2. 書き起こしの管理 ✅ リアルタイムのSpeech-to-Text変換
✅ 即時フィードバックのための部分結果ハンドリング
✅ 最終書き起こしの同期 3. 音声出力の最適化 ✅ 音声ストリームの動的ミキシング
✅ レイテンシ管理技術
✅ 再生の同期
AWS Nova Sonicサービスとの統合
本実装の中核は、AWS Nova Sonicサービスとの統合にあります。
# Initialize AWS Nova Sonic LLM service
llm = AWSNovaSonicLLMService(
secret_access_key=NOVA_AWS_SECRET_ACCESS_KEY,
access_key_id=NOVA_AWS_ACCESS_KEY_ID,
region=os.getenv("NOVA_AWS_REGION", "us-east-1"),
voice_id=os.getenv("NOVA_VOICE_ID", "tiffany"),
send_transcription_frames=True
)
この統合が示すのは、次のような点です。
- セキュアな認証 ✅ AWS認証情報の管理
✅ ロールベースアクセス制御
✅ 環境変数のセキュアな取り扱い 2. 音声カスタマイズ ✅ 音声の選択と構成
✅ プロソディと発話特性の調整
✅ 多言語対応オプション 3. ストリーミングの最適化 ✅ リアルタイムのトークンストリーミング
✅ 段階的な応答生成
✅ 最小レイテンシの構成 4. 高度な機能 ✅ 書き起こしフレームの統合
✅ 文脈を踏まえた応答
✅ 割り込みのハンドリング
音声生成AI導入に向けた経営アクションプラン
導入をすぐ動かすための実践的なプレイブックです。
- より迅速で自然な音声対話の効果が最も大きい、顧客または従業員の体験を見極める
- コスト・体験・収益のいずれかに焦点を絞ってビジネスケースを構築する
- クラウド・AI・セキュリティの専門性をバランスよく備えたパートナーを評価する
- 明確な成功基準のもとでパイロットを実施し、結果を測定する
- スケール展開に備え、ガバナンスとセキュリティ統制を整える
- インフラストラクチャ・アズ・コードと実証済みのオブザーバビリティパターンを活用し、段階的に展開する
今後の展望
音声は、私たちが手にしている最も自然なインターフェースです。生成AIによって、その音声がテキストベースのシステムと同じくらいスケーラブルで、安全で、知的なものになりつつあります。これからの顧客・従業員エンゲージメントは、音声ファーストで人間らしい会話を土台に築かれていくでしょう。
先見性のある組織にとって、投資すべきタイミングはまさに今です。
DoiT Internationalは、クラウド、セキュリティ、生成AIの深い知見を組み合わせ、音声ファーストソリューションをスケールさせながら確実に成功へ導きます。
次世代の会話型AIを、ぜひ私たちと一緒に。 DoiT International へお気軽にお問い合わせください。