Comparatif en duel de deux outils de transformation utilisés pour construire des pipelines de données cloud.

La plupart des professionnels de la donnée touchent à la transformation, mais quel produit est fait pour vous ?
Parmi les enjeux les plus importants rencontrés par les clients de DoiT figurent la transformation et le traitement de données issues de sources variées vers de multiples cibles.
Beaucoup de nos clients s'appuient sur des services de Data Warehousing comme Snowflake ou Google BigQuery pour stocker et gérer leurs données. Ils cherchent à savoir comment exploiter efficacement ces données sans avoir à exécuter et maintenir manuellement le code de leurs pipelines.
Autrefois, avec les bases de données relationnelles et les infrastructures de data warehouse classiques, c'était le terrain de jeu des outils ETL : des solutions comme SSIS, Informatica ou SAS Data Integration Studio servaient à orchestrer l'extraction source-cible, la transformation et le chargement de ces données dans le data warehouse retenu.
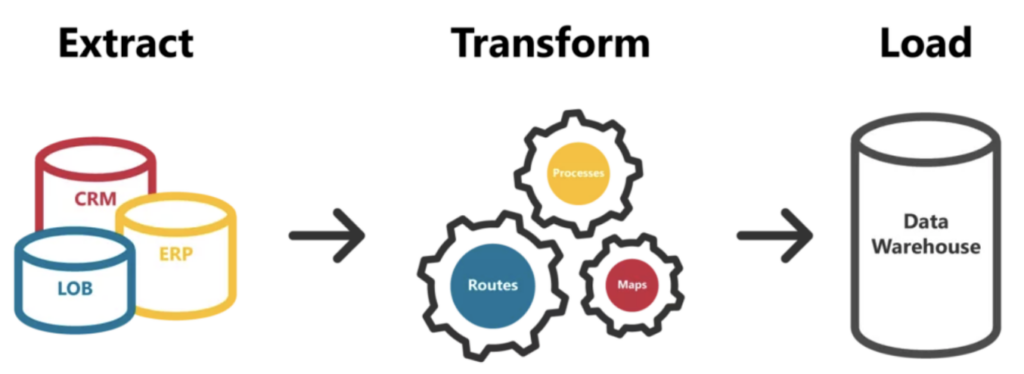
Mais le secteur a évolué avec l'arrivée des Cloud Data Warehouses comme Snowflake, BigQuery, Redshift, etc. Ces plateformes de nouvelle génération, par leur architecture et leur efficacité, se prêtent davantage à une logique ELT : elles absorbent très bien les transformations exécutées en pushdown directement sur le data warehouse. Les outils mentionnés plus haut deviennent alors superflus, car chaque fournisseur cloud propose en général sa propre solution efficace pour la partie EL de l'ELT et le chargement des données dans les data warehouses cloud qu'il prend en charge nativement.
Place à l'outil de transformation !
Ces dernières années, beaucoup de nos clients ont adopté des connecteurs spécialisés pour gérer l'extraction des données depuis leurs sources, et des outils de transformation pour effectuer les calculs lourds au sein du data warehouse. Ensemble, ces étapes d'ingestion et de transformation forment ce que l'on appelle aujourd'hui un pipeline de données cloud.
D'où l'essor d'outils comme Fivetran pour la première partie de la chaîne, et dbt pour la seconde. Mais imaginez un outillage alternatif capable de gérer l'ingestion dans vos pipelines, d'effectuer les transformations lourdes nécessaires et d'orchestrer le tout efficacement, sans recourir à des outils complémentaires comme des DAGs Apache Airflow pour piloter vos jobs de transformation.
Présentation d'Ascend.io
![]()
Ascend.io est un acteur majeur de l'automatisation de pipelines de données, avec pour ambition de bâtir les pipelines les plus intelligents au monde.
Ascend est une plateforme unique qui détecte et propage les changements à travers votre écosystème, garantit l'exactitude des données et chiffre le coût de vos data products. Elle vous permet ainsi de gérer et de construire un pipeline d'ingestion, d'effectuer des transformations complexes et de les orchestrer dans un pipeline métier plus large, le tout depuis un seul endroit.
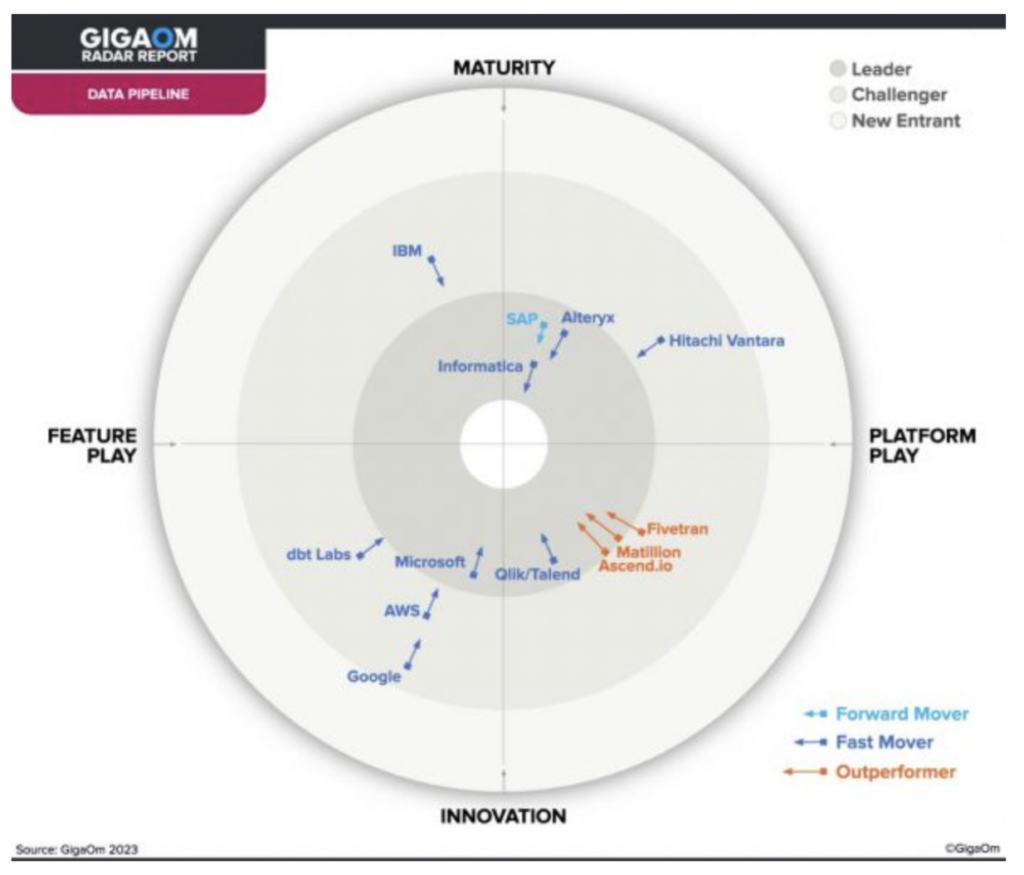
Un récent rapport GigaOm a identifié Ascend comme l'un des trois seuls acteurs surperformants du marché des pipelines de données, ce qui en fait un choix idéal pour un pipeline moderne.
Le service Ascend.io détecte automatiquement les changements à la source et les propage à travers votre pipeline via le Data Warehouse de votre choix, supprimant toute planification ou exécution manuelle de jobs pour vos équipes.
Il offre également une intégration de premier ordre avec différents fournisseurs de Data Warehouse grâce à des optimisations de tables/vues comme le partitionnement au sein même des dataflows Ascend, optimisant la gestion des données tout au long de vos pipelines.
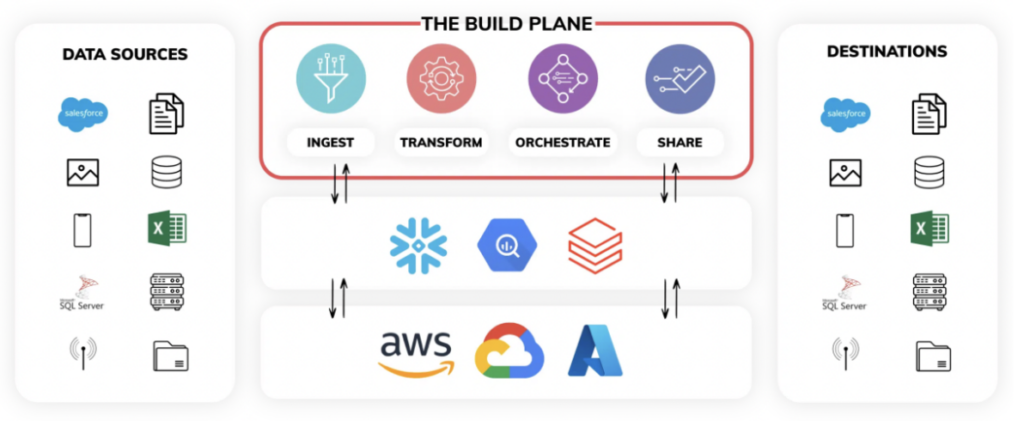
Le service de pipeline de données Ascend, exploité pleinement, comporte 3 plans principaux :
- Le Build Plane - Voyez le build plane comme une vue unifiée pour programmer toute la logique d'ingestion et de transformation de vos pipelines. Vous pouvez aussi programmer vos pipelines dans Ascend via du code backend, à l'aide de son SDK et de son CLI. L'interface visualise toute la lignée des données et supervise les opérations en temps réel.
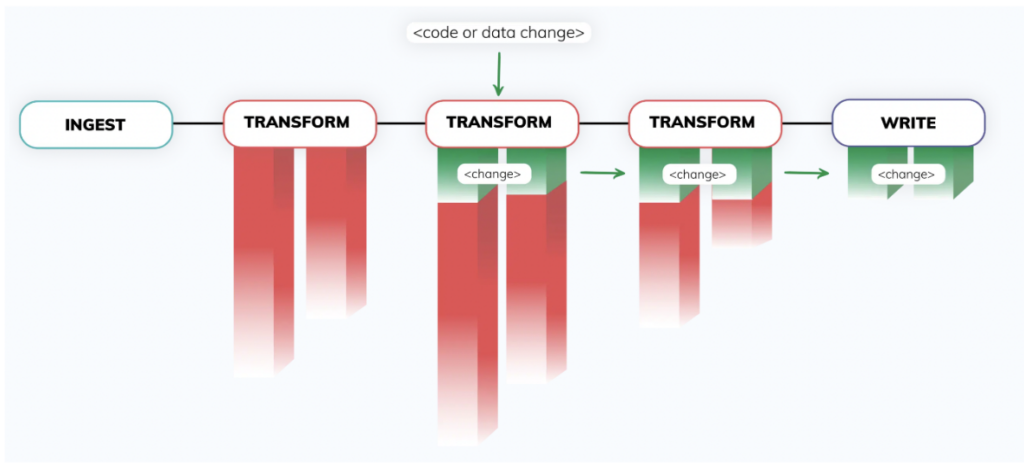
 2. Le Control Plane - Au cœur de la plateforme Ascend se trouve un control plane sophistiqué, propulsé par une technologie unique de fingerprinting. Ce moteur entièrement autonome détecte en permanence les changements dans les données et le code à travers de vastes réseaux de pipelines parmi les plus complexes, et y répond en temps réel. Les pipelines restent synchronisés sans aucun code d'orchestration supplémentaire.
2. Le Control Plane - Au cœur de la plateforme Ascend se trouve un control plane sophistiqué, propulsé par une technologie unique de fingerprinting. Ce moteur entièrement autonome détecte en permanence les changements dans les données et le code à travers de vastes réseaux de pipelines parmi les plus complexes, et y répond en temps réel. Les pipelines restent synchronisés sans aucun code d'orchestration supplémentaire.
- L'Ops Plane - L'ops plane d'Ascend aide à intégrer des pipelines de données intelligents dans l'entreprise. Il répond à trois piliers clés des opérations data : il renforce la confiance métier, chiffre les coûts de traitement et instaure de la transparence. L'ops plane supervise les séquences de workloads en temps réel, à mesure que les données sont ingérées et traitées dans l'ensemble du réseau de pipelines connectés.
Ascend est aujourd'hui compatible avec les data clouds Google BigQuery, Snowflake et Databricks, et la prise en charge d'autres services s'étendra prochainement.
C'est clairement un service à étudier sérieusement pour des workloads de pipelines de données cloud, compte tenu de son puissant moteur d'automatisation et de sa capacité à prendre en charge le développement par interface comme par code. Nous sommes ravis de vous proposer ce tour d'horizon détaillé.
Présentation de dbt
![]()
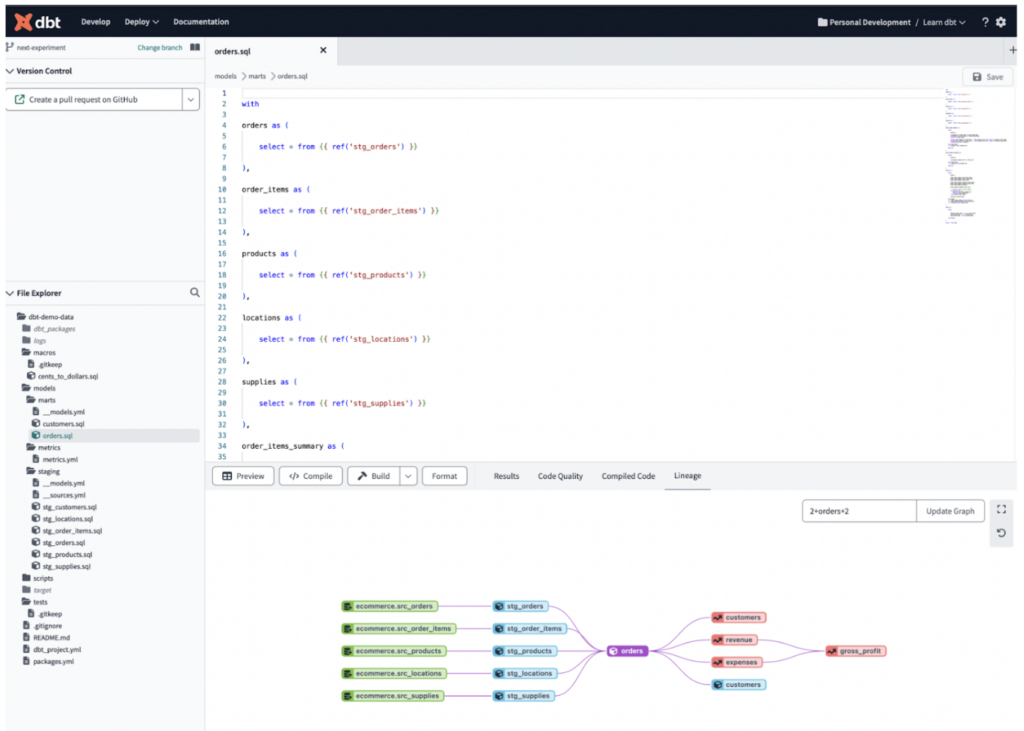
dbt est un outil de pipeline de transformation basé sur SQL qui permet aux équipes de déployer rapidement et collectivement du code analytique en suivant les bonnes pratiques du génie logiciel : modularité, portabilité, CI/CD et documentation. Il facilite la collaboration sur les tâches de développement via des dépôts et s'est imposé comme un outil incontournable ces dernières années.
dbt se décline en deux formats :
- Le service dbt Cloud — une version de dbt avec interface graphique qui prend également en charge le déploiement et l'exécution directe des modèles dbt. Ce service propose une version gratuite pour utilisateur unique et une tarification par paliers pour les équipes de développeurs.
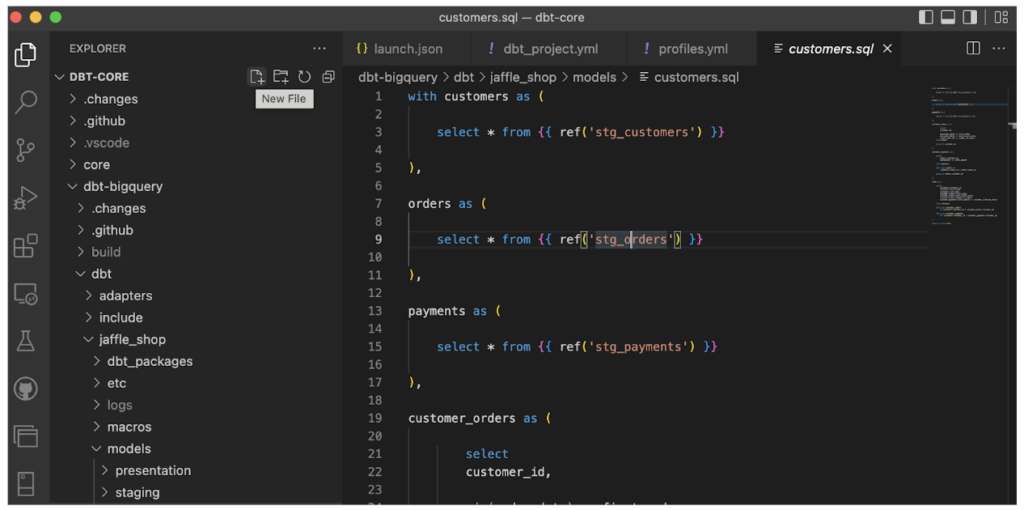
- dbt Core — la version code de dbt, gratuite, utilisable depuis la plupart des IDE comme Visual Studio Code par exemple. Comme dbt Cloud, elle peut être reliée au dépôt de votre choix et orchestrée avec des outils comme Apache Airflow pour coordonner vos pipelines de données.
Au-delà de la coordination du développement et du déploiement de divers jobs de transformation, dbt permet d'exécuter des tests unitaires sur vos données et fournit la lignée des données via ses fonctionnalités de catalogage, ce qui simplifie considérablement la documentation du flux de bout en bout de vos pipelines ELT.
dbt est compatible avec différentes offres de Data Warehousing et de Data Lake, dont Snowflake, BigQuery, Redshift, Databricks et Starburst, ce qui en fait un choix prisé des grandes entreprises qui en utilisent plusieurs.
Le Bake-Off DoiT : notre évaluation
Ascend et dbt sont clairement deux outils efficaces pour la transformation de données, chacun avec ses avantages propres, mais lequel convient le mieux à un cas d'usage courant de pipeline ? Voici la démarche que nous avons suivie pour les départager.
Notre scénario : la collecte et la transformation en masse de données météorologiques quotidiennes pour le mois d'août, avec des millions d'enregistrements ingérés depuis Google Cloud Storage, puis traités via des pipelines dans Snowflake et Google BigQuery, séparément, à la fois sur Ascend.io et dbt Cloud.
Notre pseudo-pipeline comportera les étapes standard suivantes :
- Lecture des données météo brutes quotidiennes depuis le Data Warehouse retenu et combinaison de plusieurs extractions journalières en une seule table en vue d'analyses complémentaires.
- Segmentation de ces données en différentes catégories (météo chaude, tiède et froide) — via des transformations basiques sur le jeu de données combiné.
- Réalisation de transformations d'agrégation et statistiques plus avancées sur les jeux de données segmentés. Ainsi qu'une jointure de nos données transformées avec une table de référence des localisations contenant les codes des zones météo.
- Restitution des jeux de données finaux dans une couche pseudo-data mart / présentation au sein des data warehouses retenus.
Dans notre cas, nous voulons d'abord comparer le temps nécessaire pour bâtir de tels processus du point de vue d'un développeur, sur Ascend.io comme sur dbt — car le temps consacré à construire vos solutions de données est une variable clé de la performance de votre équipe.
Une fois les jobs construits, nous évaluerons les aspects suivants pour mesurer le bake-off et le coût total de possession de chaque solution :
- Les temps d'exécution de l'ensemble des pipelines de bout en bout (avec démarrages à chaud et à froid pour le pipeline Ascend, en raison de l'infrastructure Spark sous-jacente).
- Les crédits consommés (pour Snowflake) et les octets scannés (pour BigQuery) dans les deux pipelines.
- La gestion des erreurs — nous introduirons des défaillances dans les deux pipelines et examinerons les mécanismes de récupération de chacun.
- L'introduction de nouveaux fichiers de données météo dans les pipelines et la ré-exécution qui en découle pour mettre à jour les jeux de données, afin de tester la performance respective des pipelines lors de l'ingestion de nouvelles données.
- Le niveau d'interaction et de contrôle sur les Data Warehouses sous-jacents — c'est-à-dire l'arrêt des Virtual Warehouses dans Snowflake, le partitionnement automatique au sein des jobs Ascend, et bien d'autres tâches d'orchestration de pipeline courantes.
Maintenant que les règles du jeu sont posées, passons à la mise en œuvre du scénario et voyons comment nos données météo sont enrichies dans les deux solutions.
Le Bake-Off DoiT : préparation du terrain
Passons en revue le processus de développement côté Ascend et côté dbt.
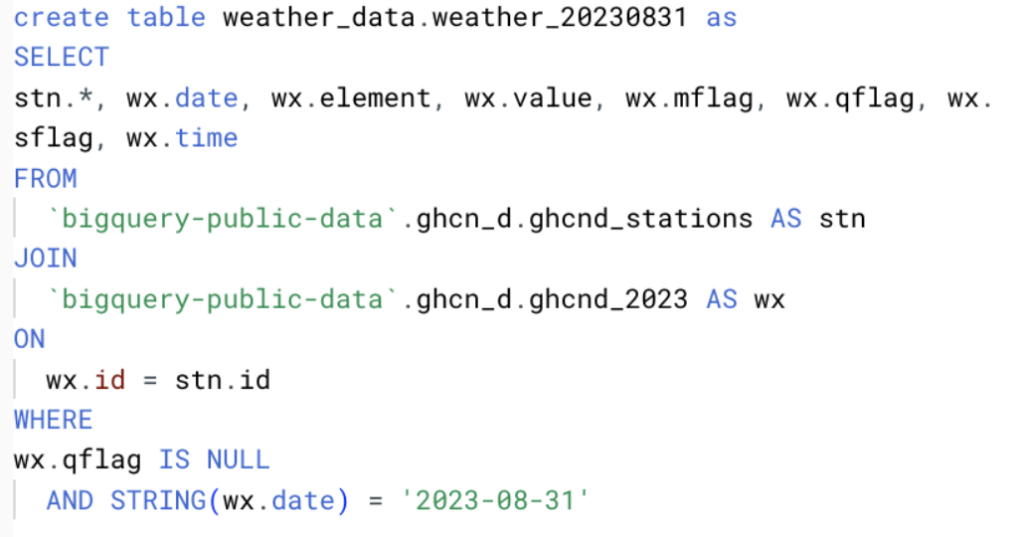
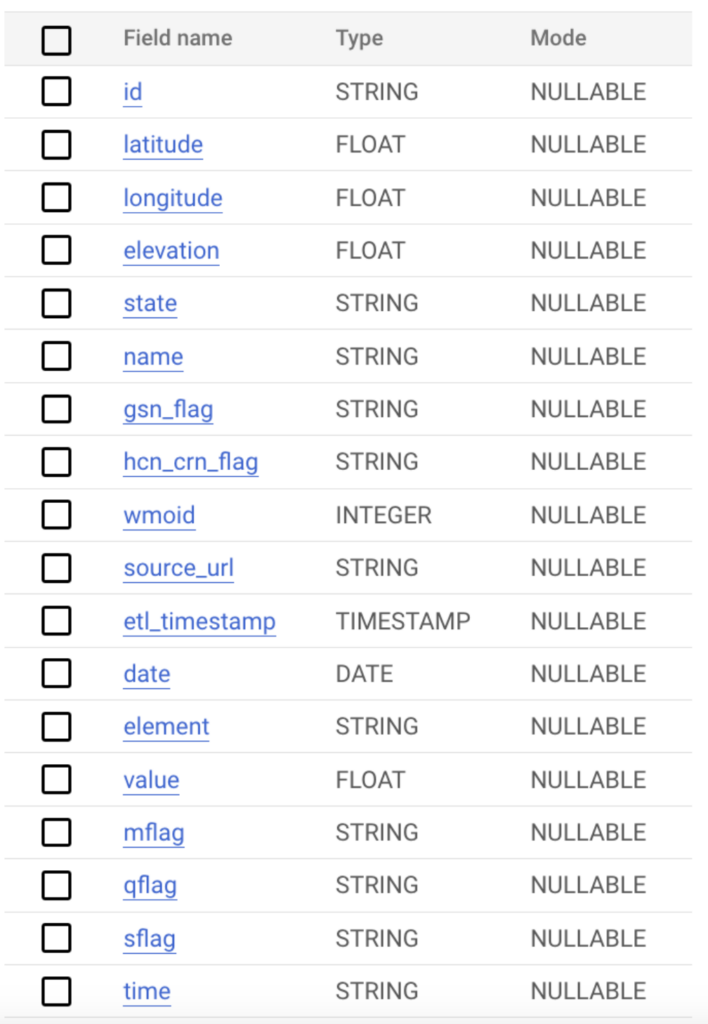
Pour notre étude de cas, nous avons collecté les données météo depuis les datasets publics ghcn_d de Google.
Pour disposer d'un volume de données suffisant, nous avons sélectionné l'ensemble des champs et créé des fichiers quotidiens entre le 1er août et le 31 août 2023 inclus, selon la requête ci-dessous.
Les données suivent le schéma ci-dessous et totalisent plusieurs millions d'enregistrements. Pour tester plusieurs scénarios, nous les avons stockées à la fois dans des tables BigQuery et dans Google Cloud Storage afin d'éprouver différentes méthodes d'ingestion entre les plateformes.
Processus de développement Ascend
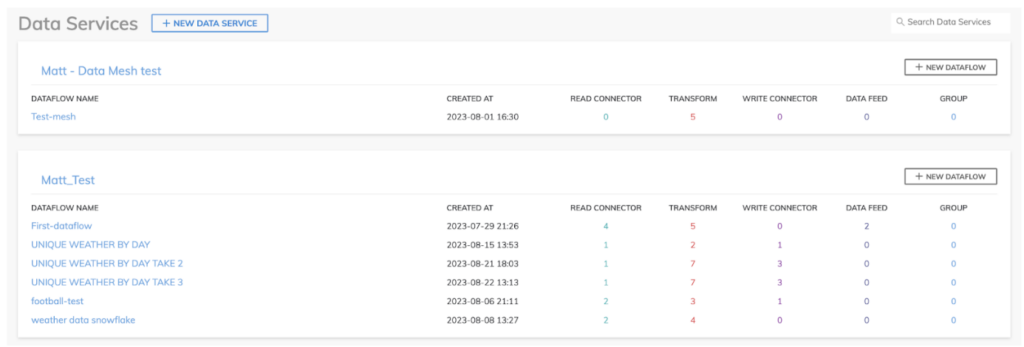
Dans Ascend.io, vous créez un pipeline de données en construisant des Dataflows ; ces derniers sont stockés dans des Data Services qui fournissent un modèle de sécurité partagé pour vos différents pipelines, comme illustré dans notre environnement playground.
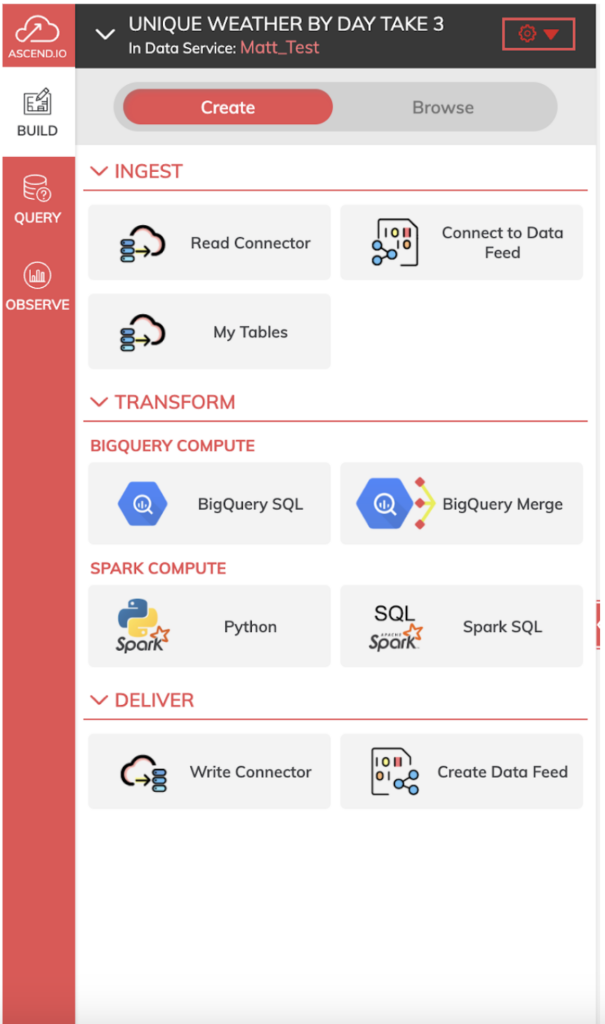
Les Dataflows d'Ascend mettent à votre disposition divers composants ingest/read, transform et deliver/write utilisables à chaque étape de votre pipeline.
Pour notre pipeline, nous voulons d'abord utiliser des Read Components afin d'ingérer les fichiers initiaux de données météo depuis GCS ou directement depuis BigQuery.
Nous utilisons ensuite des composants de transformation pour mettre nos données en forme. J'ai choisi BigQuery SQL pour ce bake-off car c'est la variante de SQL avec laquelle je suis le plus à l'aise, mais vous avez le choix entre plusieurs langages — Python, Spark SQL ou SnowSQL (s'il est activé) — pour construire vos transformations dans Ascend.
Enfin, nous utilisons un composant d'écriture pour réinjecter le résultat de notre pipeline entièrement transformé dans le data warehouse retenu.
Le pipeline ci-dessous est celui que j'ai construit pour ce bake-off. Il se compose de trois routes de données pour différents niveaux de scénarios météo chaud/froid en vue de notre analyse finale :
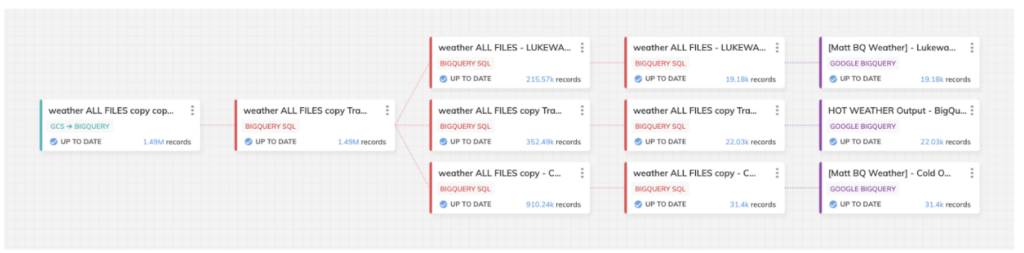
La conception du pipeline est identique sur BigQuery comme sur Snowflake, mais la capture d'écran provient du modèle conçu pour BigQuery.
Pour notre connecteur de lecture, nous avons d'abord configuré la connexion aux fichiers de notre bucket GCS (Google Cloud Storage). Pour cela, nous avons utilisé un compte de service ayant accès au bucket en question.
Comme nous avons plusieurs fichiers météo, nous pouvons spécifier un préfixe dans Ascend pour qu'il sache ingérer tous les fichiers répondant à des conventions de nommage similaires.
Nous avons également intégré des en-têtes dans nos fichiers CSV ; il faut donc activer l'option permettant de les exclure dans le composant de lecture d'Ascend.
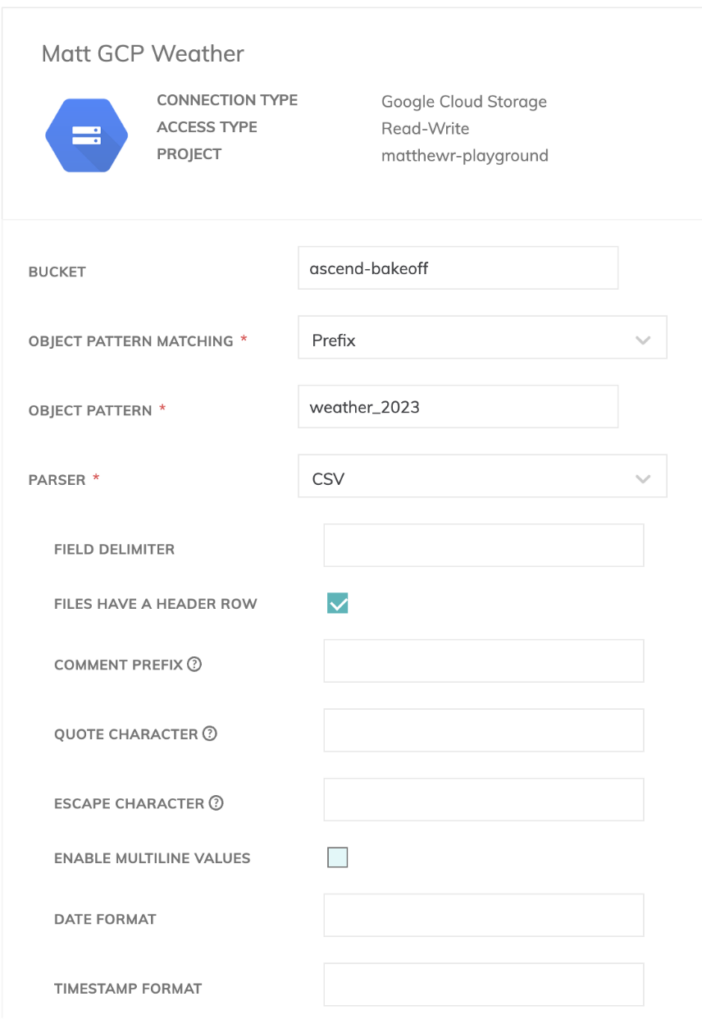
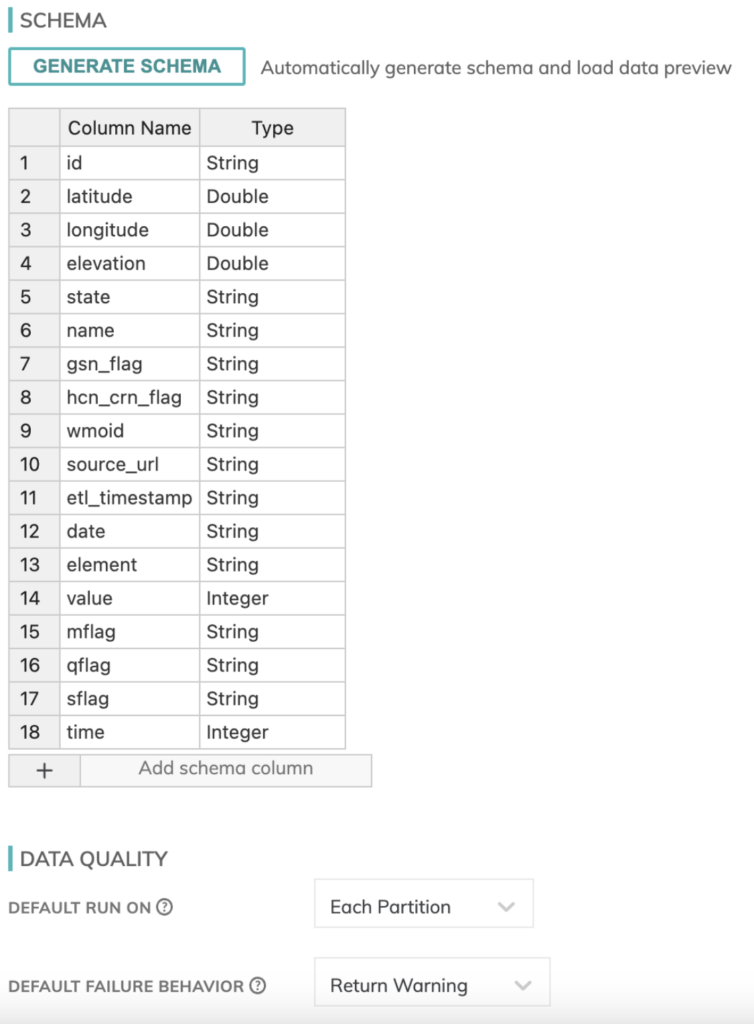
Il faut aussi définir un schéma pour nos données météo. Heureusement, Ascend dispose d'un détecteur de schéma intégré pour les composants de lecture, ce qui simplifie grandement la tâche.
Vous pouvez également définir ici des contrôles de qualité de données et des comportements en cas d'échec pour piloter vos jobs de bout en bout.
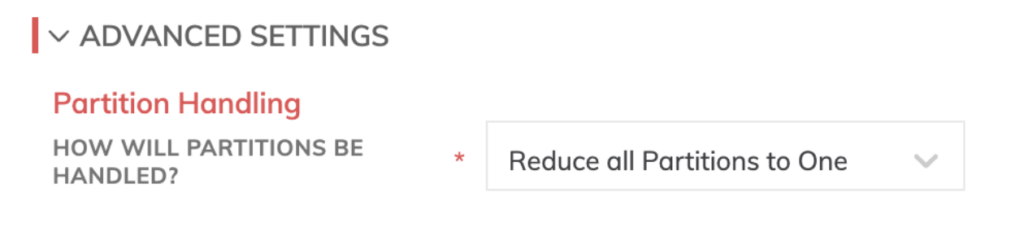
Autre fonction intéressante de la plateforme Ascend : le partitionnement de jeux de données spécifique au pipeline. Il segmente vos données en blocs cohérents et les traite indépendamment, accélérant ainsi le débit de vos pipelines au sein du data warehouse retenu.

Comme on peut le voir sur un sous-ensemble de 20 jours de nos données, les partitions sont segmentées à raison d'une partition par jour de fichiers météo.
Côté transformations, leur configuration dans Ascend est tout aussi simple. Il suffit de spécifier le langage de votre choix et d'écrire le code dans la fenêtre principale du composant, comme illustré ci-dessous.
À noter que, à l'image du langage de macros de dbt, Ascend utilise la logique Jinja pour référencer les noms des composants des étapes précédentes du pipeline. Les développeurs familiers avec ce style se sentiront à l'aise sur les deux plateformes.
Pour ne pas alourdir cette section, je n'inclus ici qu'un seul composant de transformation basique à titre d'illustration. Notez toutefois qu'un guide de référence complet des transformations construites pour ce pipeline est disponible dans un dépôt GitHub, dont le lien figure en fin d'article.
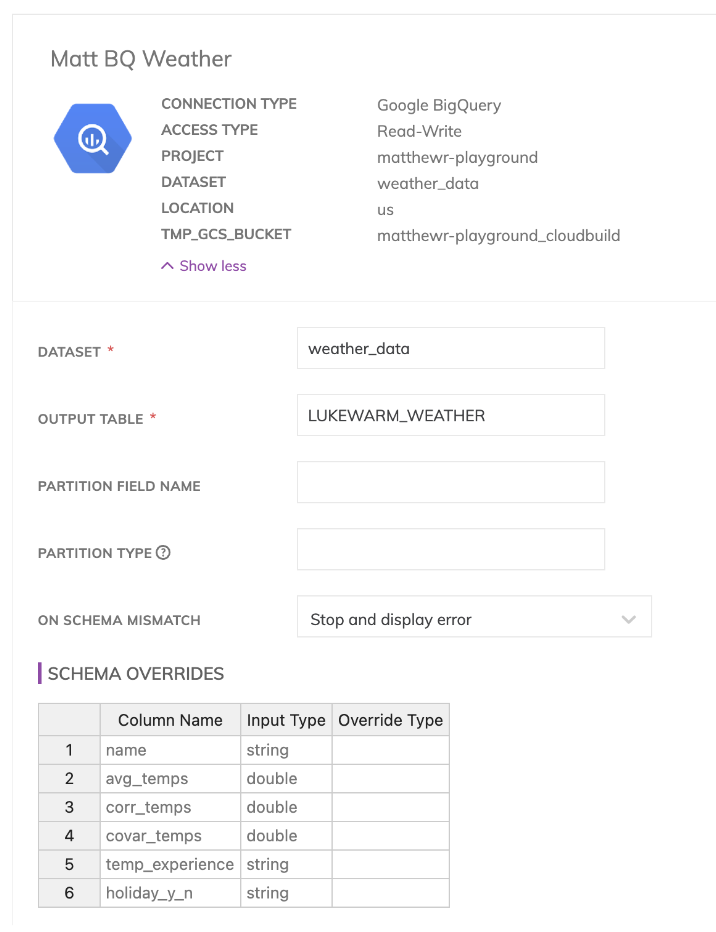
Enfin, pour nos composants d'écriture ou reverse-ETL, nous devons à nouveau spécifier une connexion vers notre data warehouse BigQuery.
Nos connexions se configurent depuis l'espace Admin d'Ascend.io, comme illustré ici. Elles sont indispensables aux composants de lecture comme d'écriture, et Ascend.io prend en charge une grande variété de connexions, comme les data warehouses Snowflake ou BigQuery, ou des buckets de stockage sur n'importe quel cloud.
À partir de là, les composants d'écriture sont assez simples. Il suffit de spécifier une connexion, la structure du schéma de sortie, puis pour le data warehouse retenu le nom de votre table de sortie, ainsi que les options spécifiques au cloud (comme le nom du dataset dans BigQuery ou le schema dans Snowflake).
À noter qu'Ascend matérialise par défaut les données à chaque étape de transformation du pipeline dans les dataplanes Snowflake ou BigQuery. La création d'un connecteur de sortie vers le data warehouse n'est donc pas nécessaire, mais reste disponible si vous souhaitez effectuer des ajustements finaux de schéma sans impliquer d'autre logique de transformation.
En matière d'effort de développement global, malgré ce qui semble être plusieurs étapes dans mon processus et mon explication, la construction de ce pipeline m'a pris environ 10 minutes au total, en incluant le temps consacré à la configuration de mes connexions à GCS, BigQuery et Snowflake dans mes comptes playground Ascend.io pour cette démo.
À souligner également : chaque fois que de nouveaux fichiers météo étaient ajoutés conformément à nos règles du jeu, ils étaient automatiquement détectés par notre service de données Ascend, et le pipeline pouvait être ré-exécuté à volonté en intégrant les nouveaux fichiers et données.
Le grand intérêt d'Ascend pour ce type de cas d'usage, c'est qu'une fois mon pipeline en place, il demande très peu de maintenance pour le reste de son cycle de vie. Modifier la logique ou ajouter de nouvelles étapes au processus ne nécessite vraiment pas beaucoup de travail supplémentaire. Lorsque ces changements surviennent, le contrôleur d'automatisation les détecte et identifie automatiquement les sections du pipeline à ré-exécuter, ainsi que les partitions du jeu de données à rafraîchir. Plus impressionnant encore, cela peut se produire à travers plusieurs pipelines interconnectés : une seule modification de modèle déclenchera automatiquement, via le service, des dizaines de jobs de traitement et de DAGs, sans que j'aie à intervenir. Un sérieux point fort pour Ascend.
Processus de développement dbt
Pour la partie dbt de ce bake-off, j'ai utilisé le service dbt Cloud via mon compte gratuit. Ce choix paraissait plus naturel, car dbt Cloud dispose de sa propre orchestration intégrée et n'exige pas de service tiers comme Airflow, ce qui offre une comparaison plus juste avec l'expérience tout-en-un d'Ascend.
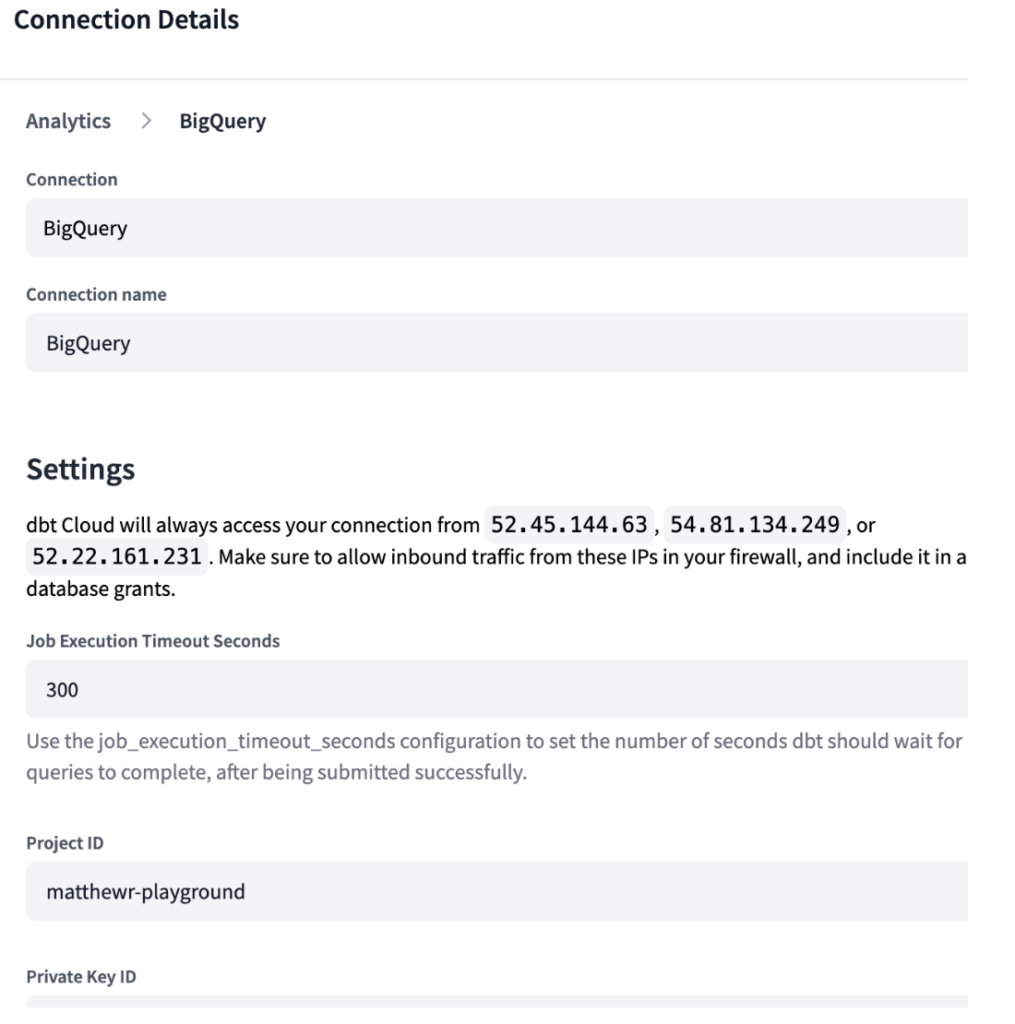
Comme pour Ascend, dans dbt Cloud il faut spécifier votre environnement de développement. dbt étant conçu pour se connecter au data warehouse de votre choix, nous avons dû créer des connexions pour nos environnements BigQuery et Snowflake, avec les identifiants nécessaires comme illustré ci-dessous.
dbt comporte plusieurs répertoires qui constituent l'infrastructure de ses pipelines, dont Models (contenant les jobs SQL exécutés dans le DWH retenu), Tests (contenant les tests unitaires sur ces modèles), Macros (contenant la logique réutilisable pour vos jobs) et Seeds, entre autres.
Pour les besoins de ce pipeline, nous avons reproduit dans dbt la logique exacte de notre pipeline Ascend sous la forme de différents fichiers de modèles .sql afin de répliquer le même processus.
Voici une vue du DAG de notre processus dbt construit pour la logique du bake-off :

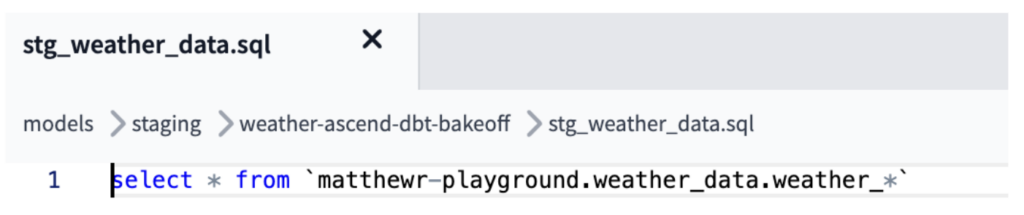
Pour répliquer l'ingestion et la combinaison des fichiers CSV obtenus avec les connecteurs de lecture Ascend, le modèle stg_weather_data dans dbt a combiné les multiples fichiers/tables sources via la logique d'external source pour GCS, ou via une logique de wildcard depuis BigQuery, afin de fusionner toutes nos données en un seul fichier comme dans le job équivalent Ascend (illustré ci-dessous).
Cela a permis de gérer le scénario d'ajout de fichiers supplémentaires mentionné dans nos règles du jeu, la clause wildcard étant conçue pour récupérer les nouveaux fichiers chargés dans BigQuery (la logique peut aussi être adaptée pour récupérer les nouveaux fichiers ajoutés dans GCS).
Nous avons ensuite créé divers modèles dbt dans différents répertoires pour les couches Staging/Mart du data warehousing, la table mart finale étant utilisée dans notre exemple pour produire la table équivalente dans nos data warehouses BigQuery ou Snowflake, respectivement. Cela permet d'obtenir les mêmes résultats avec exactement la même syntaxe SQL que nos exécutions sous Ascend, pour une vraie comparaison de bake-off.
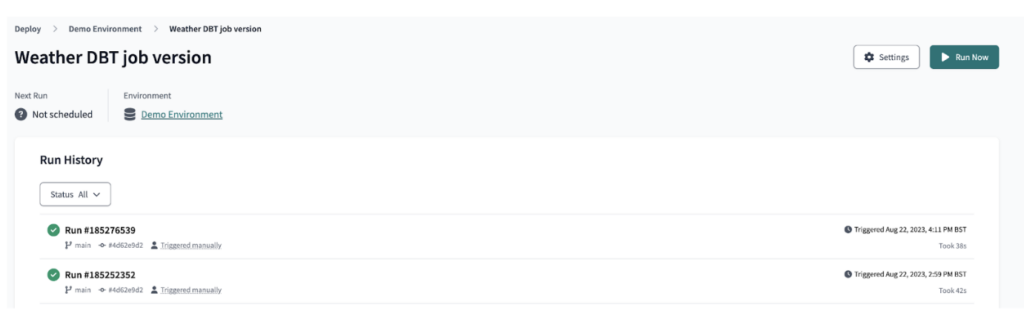
Avec dbt Cloud, nous avons ensuite déployé la sortie dbt sous forme de job, utilisé pour orchestrer l'exécution du pipeline dbt comme illustré.
Conséquence de la configuration de l'orchestration du job dbt cloud : le temps total de développement s'est révélé légèrement plus long que pour le pipeline Ascend équivalent. De plus, dbt étant une solution basée sur le code, du temps supplémentaire a été nécessaire pour configurer la partie ingestion standard du pipeline (via la configuration des fichiers .yml) et la sortie de la table finale de présentation, intégrée au connecteur d'écriture du pipeline Ascend.
Ce pipeline équivalent a pris environ 20 minutes à construire dans dbt.
À noter également que, contrairement à Ascend, dbt ne propose pas de mécanisme automatisé pour partitionner vos données dès l'ingestion. Il n'a pas non plus la capacité de détecter les fichiers supplémentaires ajoutés à votre bucket source ni de déclencher de nouvelles ingestions incrémentales par lots peu après leur détection (que ce soit dans GCS ou BigQuery).
Vous pouvez appliquer le partitionnement et le clustering BigQuery dans vos fichiers .yml dbt, mais cela nécessite une configuration supplémentaire et n'équivaut pas aux partitions d'ingestion créées automatiquement dans Ascend.
Par ailleurs, bien que la logique de gestion d'erreurs de dbt soit prise en charge via divers packages comme Great Expectations, il s'agit là encore d'une fonctionnalité à configurer en installant ces packages. Une bonne maîtrise de la syntaxe de ces packages est aussi requise pour ajouter cette logique à vos jobs, là où Ascend propose un simple jeu de cases à cocher.
Le Bake-Off DoiT : résultats
Et voici le moment que nous attendions tous. À nous de jouer !
Nos tests des deux pipelines de bout en bout ont donné les résultats de performance suivants :
Temps d'exécution
Cold Start — temps moyen de la première exécution des pipelines complets
- Ascend : 2 min 6 s
- dbt : 47 s
Sur les premiers temps d'exécution globaux, on constate que le pipeline dbt Cloud a été plus rapide lors du démarrage à froid. Mais cela tient probablement à l'infrastructure sous-jacente des pipelines Ascend, où des clusters Kubernetes sont provisionnés à la volée pour exécuter le job, puis mis en veille entre les exécutions afin de réduire les coûts de calcul.
Nous avons donc effectué une seconde mesure pour comparer à équivalence, dans un scénario de démarrage à chaud où les clusters Ascend étaient déjà provisionnés.
Hot Start — temps moyen des exécutions ultérieures des pipelines complets
- Ascend : 10 s
- dbt : 32 s
Les exécutions suivantes ont montré qu'Ascend était nettement plus rapide, à volumes de données et code de transformation identiques. Cela s'explique probablement par la nature dynamique et parallélisée des clusters Ascend, qui permet de multi-threader le traitement des étapes individuelles et donc de réduire significativement les temps d'exécution.
Comparaison des crédits Snowflake utilisés et des octets BigQuery
Crédits Snowflake par job
Pour les crédits utilisés tout au long des pipelines complets côté Ascend et dbt, nous avons fait en sorte qu'ils utilisent des schemas différents au sein de notre base Snowflake pour le bake-off. Concrètement, le pipeline Ascend a utilisé les connexions sources_ascend et ascend_t_conn, tandis que le pipeline dbt a utilisé les schemas dbt_mrichardson et public.
Le pipeline Ascend s'est révélé sensiblement plus efficace que le pipeline dbt en matière de crédits Snowflake consommés. Le total des crédits utilisés s'élevait à :
- Consommation pipeline Ascend = 61,165 + 28,071 = 89,236 crédits
- Consommation pipeline dbt = 1924,652 + 33,685 = 1958,337 crédits

Cet écart important côté Snowflake s'explique en partie par les capacités de partitionnement qu'Ascend a appliquées à nos données météo. Comme chaque fichier était propagé de manière incrémentale sans nécessiter de réduction complète à l'ingestion, beaucoup moins de calcul a été nécessaire pour exécuter le pipeline, et tout autant lors de son développement. Cet écart est aussi imputable à d'autres fonctionnalités d'économie et de gestion du calcul de la plateforme Ascend, comme l'arrêt des Snowflake Virtual Warehouses dès la fin du traitement du pipeline pour éviter d'accumuler du temps d'activité inutile.
Slots BigQuery utilisés par job
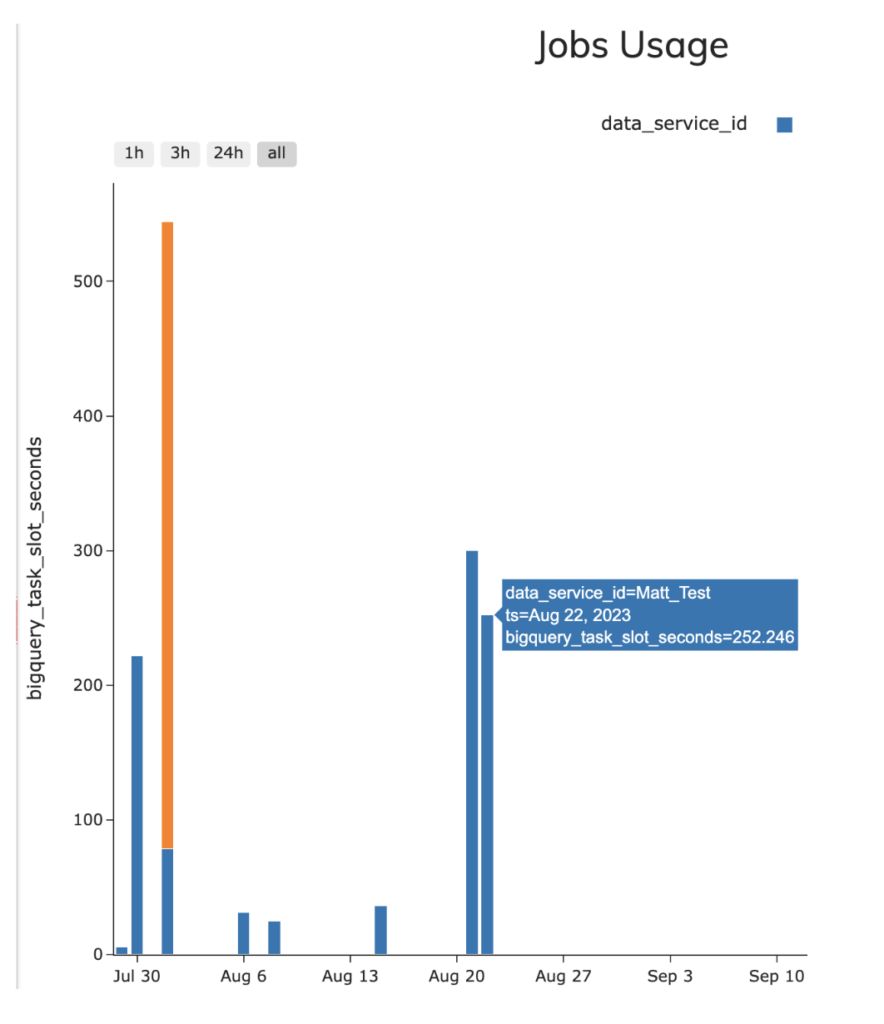
- Ascend — 4,18 slots/seconde en moyenne (252,46 slot-secondes au total)
- dbt — 3,2 slots/seconde en moyenne (189,34 slot-secondes au total)
Côté BigQuery, les deux pipelines exécutaient les jobs assez efficacement du point de vue des slots, dbt Cloud étant en moyenne légèrement plus efficace tout au long de l'exécution. Cette légère différence d'utilisation des slots tient à la nature des paramètres d'exécution de mon Data Service dans Ascend par rapport à mon DAG de test construit dans dbt, en termes de parallélisme : le premier exécutait davantage d'étapes de mon pseudo processus ETL en parallèle, ce qui entraîne une plus forte contention de slots dans Ascend que dans dbt sur mon exemple basique (en raison de l'allocation des threads dans ma configuration dbt).
Pour vérifier, j'ai ajusté l'exécution de mon pipeline dbt en ajoutant l'option –threads:4 afin d'élargir le parallélisme, et j'ai alors observé une moyenne très similaire d'environ 4,3 slots/seconde, due à une contention légèrement plus importante des ressources de slots lors de la ré-exécution.
Pour vérifier ces statistiques, j'ai utilisé la requête d'exemple information_schema depuis la vue JOBS pour tester les deux pipelines (incluse dans le dépôt GitHub joint). À noter toutefois que, dans l'interface Ascend, la vue ci-dessous est intégrée à l'outil pour mesurer l'utilisation des BQ Slots et la consommation de crédits Snowflake pour les pipelines exécutés via Ascend, comme illustré sur la capture suivante.
Scénarios de gestion d'erreurs
Nous avons également testé plusieurs scénarios de gestion d'erreurs sur les deux pipelines, à savoir :
- Pipelines arrêtés à 70 % des points de chargement et également en plein milieu des transformations, en introduisant des erreurs simulant des bugs classiques dans le code ou dans les données ingérées. Nous avons ensuite tenté de redémarrer le pipeline à partir de cette défaillance pour observer le comportement.
- Ajout d'un nouveau fichier CSV erroné aux pipelines pour les faire trébucher délibérément.
Voici ce que nous avons constaté lors de ces tests directs.
Gestion d'erreurs Ascend
- Les deux scénarios — défaillance à 70 % d'une exécution de pipeline et ajout d'un nouveau fichier CSV mal formé au bucket — ont échoué proprement. Ascend offre des paramètres avancés pour contrôler le comportement des pipelines en cas d'erreurs. La récupération après défaillance d'Ascend est elle aussi bien plus élégante. Grâce à la matérialisation de chaque étape du pipeline, il a pu simplement reprendre depuis le dernier composant complet et redémarrer pile au point de défaillance. Cela a permis d'éviter une quantité significative de recalculs qui auraient été nécessaires si le pipeline devait être ré-exécuté en intégralité.
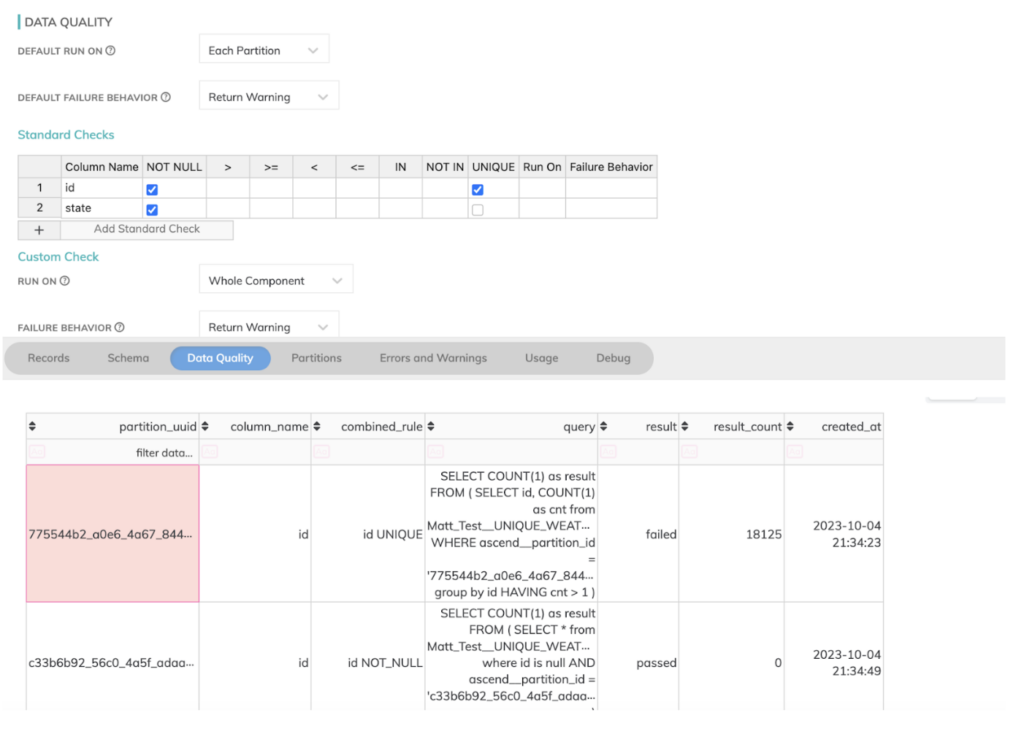
- Par ailleurs, à l'instar de dbt, Ascend.io propose également des contrôles de qualité de données utiles pour détecter les problèmes dans nos fichiers CSV défectueux et les empêcher d'entrer dans le système. Tout est intégré nativement et nécessite très peu de configuration supplémentaire pour en tirer parti, comme illustré ci-dessous depuis l'onglet data quality d'Ascend, où j'avais inséré quelques valeurs erronées dans nos fichiers de données sources.
Gestion d'erreurs dbt
Les scénarios mentionnés ci-dessus se prêtaient moins bien à dbt. Nous pouvions stocker/conserver les erreurs dans une table de gestion d'erreurs similaire à celle du pipeline Ascend. Toutefois, ces capacités exigeaient le téléchargement de packages dbt supplémentaires (à souligner en particulier : le package dbt-expectations fourni par catalogia offre de bonnes fonctionnalités côté qualité de données). Et même si nous avons pu mettre en place un processus de redémarrage dans notre pipeline, cela impliquait soit une ré-exécution manuelle des jobs, soit une configuration d'erreur supplémentaire ajoutée à dbt Cloud dans les paramètres de retry de nos jobs.
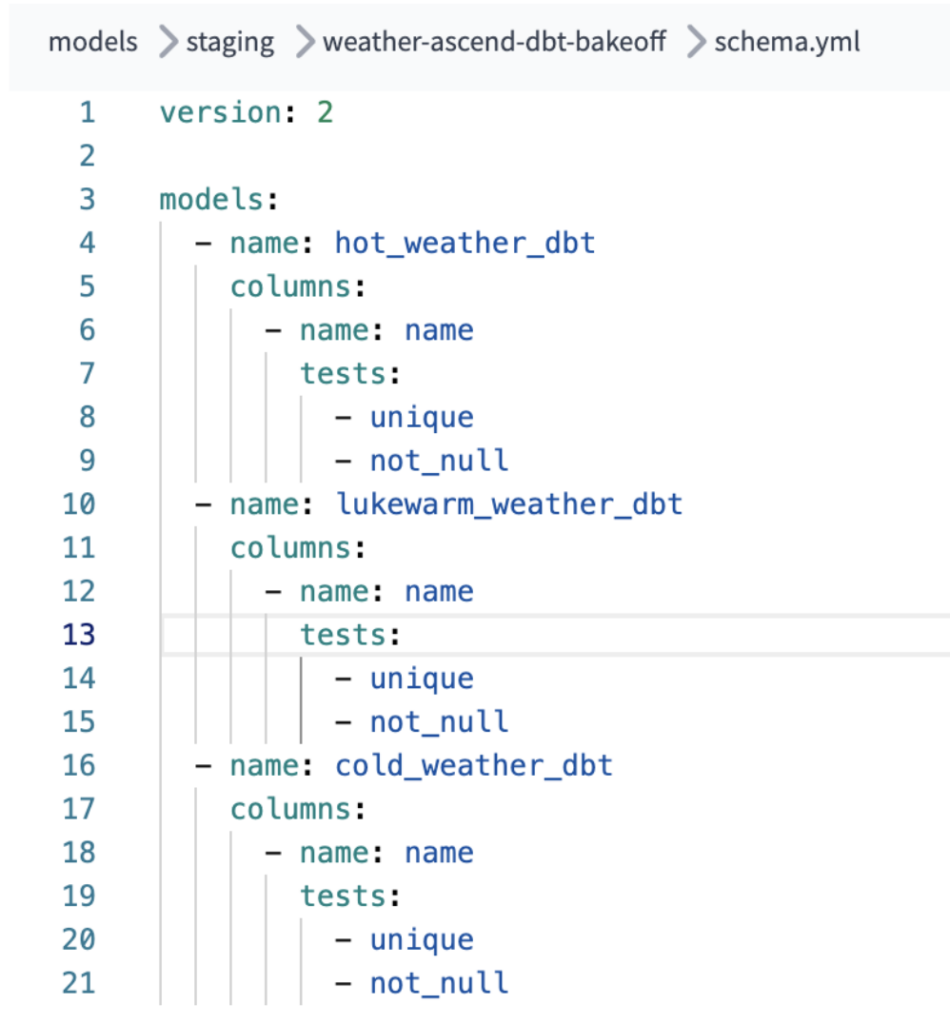
Une configuration supplémentaire pour permettre les tests not-null et unique sur chacun de nos modèles dbt était également nécessaire pour que le pipeline dbt effectue ces vérifications. Ce n'est pas un effort supplémentaire excessif, mais cela peut désorienter des développeurs moins familiers ou expérimentés avec la configuration d'un projet dbt Core / dbt Cloud.
Observations finales
À l'issue de nos tests sur l'étude de cas des données météo, sur Ascend.io comme sur dbt, il apparaît clairement que les deux services peuvent répondre aux besoins de cas d'usage de transformation de données. Toutefois, après des tests approfondis des fonctionnalités natives et des extensions tierces des deux services, on voit aussi que le bon outillage dépend de celui qui correspond le mieux à vos besoins.
Avec Ascend.io, vous disposez d'un outil de pipeline de données cloud tout-en-un qui optimise et orchestre automatiquement vos pipelines en arrière-plan. Son interface plus conviviale rend la création de pipelines simple et efficace pour des développeurs de différents niveaux d'expérience. Il intègre des techniques d'optimisation des performances pour faire tourner vos pipelines sans accroc, sans exiger un niveau d'expertise pointu en infrastructure de données ni des heures de codage manuel.
Selon nous, Ascend.io mérite assurément un essai pour vos besoins de pipelines de données cloud, en particulier lorsque vos processus de gestion de données peuvent gagner à être moins maintenus et moins dépendants d'outils d'orchestration multiples. Sa simplicité de mise en place des jobs et ses paramètres prêts à l'emploi pour réduire les coûts de calcul cloud font du service Ascend une excellente alternative à des outils plus orientés code comme dbt, selon votre cas d'usage.
À titre de référence, les pipelines construits dans Ascend et dbt pour cet article sont disponibles dans le dépôt GitHub ici.