Comparamos lado a lado duas ferramentas de transformação de dados usadas para montar cloud data pipelines.

A maioria dos profissionais de dados já mexeu com transformação de dados, mas qual produto é o ideal para você?
Algumas das maiores dores enfrentadas pelos clientes da DoiT estão ligadas à transformação e ao processamento de dados vindos de várias fontes para diversos destinos.
Boa parte dos nossos clientes usa serviços de Data Warehousing, como Snowflake ou Google BigQuery, para armazenar e gerenciar seus dados. E quer descobrir como administrar esses dados de forma eficiente, sem precisar rodar e manter manualmente o código dos data pipelines.
No passado, com bancos relacionais e infraestruturas tradicionais de data warehouse, esse era o território das ferramentas de ETL — soluções como SSIS, Informatica ou SAS Data Integration Studio cuidavam da extração da origem para o destino, da transformação e do carregamento desses dados em um data warehouse de escolha.
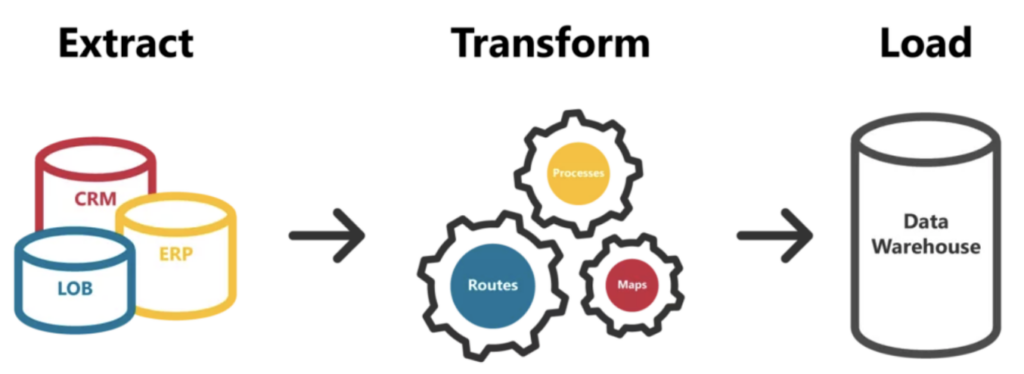
Mas o setor evoluiu com a chegada dos Cloud Data Warehouses, como Snowflake, BigQuery, Redshift, etc. Essas plataformas de nova geração, pela sua estrutura e eficiência, se encaixam melhor em um modelo ELT; elas dão conta do trabalho de transformação executado como workloads de pushdown no próprio data warehouse. Isso elimina a necessidade das ferramentas citadas, já que cada provedor de nuvem costuma oferecer uma solução eficiente para o lado "EL" do ELT e para carregar os dados nos cloud data warehouses que ele suporta nativamente.
Entra em cena a ferramenta de transformação!
Nos últimos anos, muitos dos nossos clientes adotaram ferramentas específicas de conectores de dados para cuidar da extração das fontes e ferramentas de transformação para fazer os cálculos pesados dentro do data warehouse. Juntas, essas etapas de ingestão e transformação formam o que muita gente hoje chama de cloud data pipeline.
Foi isso que impulsionou o uso de ferramentas como Fivetran para a primeira parte da solução, e dbt para a segunda. Mas e se existisse um conjunto alternativo de ferramentas capaz de cuidar da ingestão dos seus data pipelines, executar as transformações pesadas necessárias e orquestrar tudo isso de forma eficiente, sem precisar trazer ferramentas extras, como DAGs do Apache Airflow, para gerenciar seus jobs de transformação?
Conhecendo o Ascend.io
![]()
O Ascend.io é um dos grandes players em Automação de Data Pipeline, voltado para construir os data pipelines mais inteligentes do mundo.
O Ascend é uma plataforma única que detecta e propaga mudanças por todo o seu ecossistema, garante a precisão dos dados e quantifica o custo dos seus produtos de dados. No fim das contas, isso permite gerenciar e construir um pipeline de ingestão, executar transformações complexas e orquestrar tudo isso como parte de um pipeline de negócios mais amplo, em um só lugar!
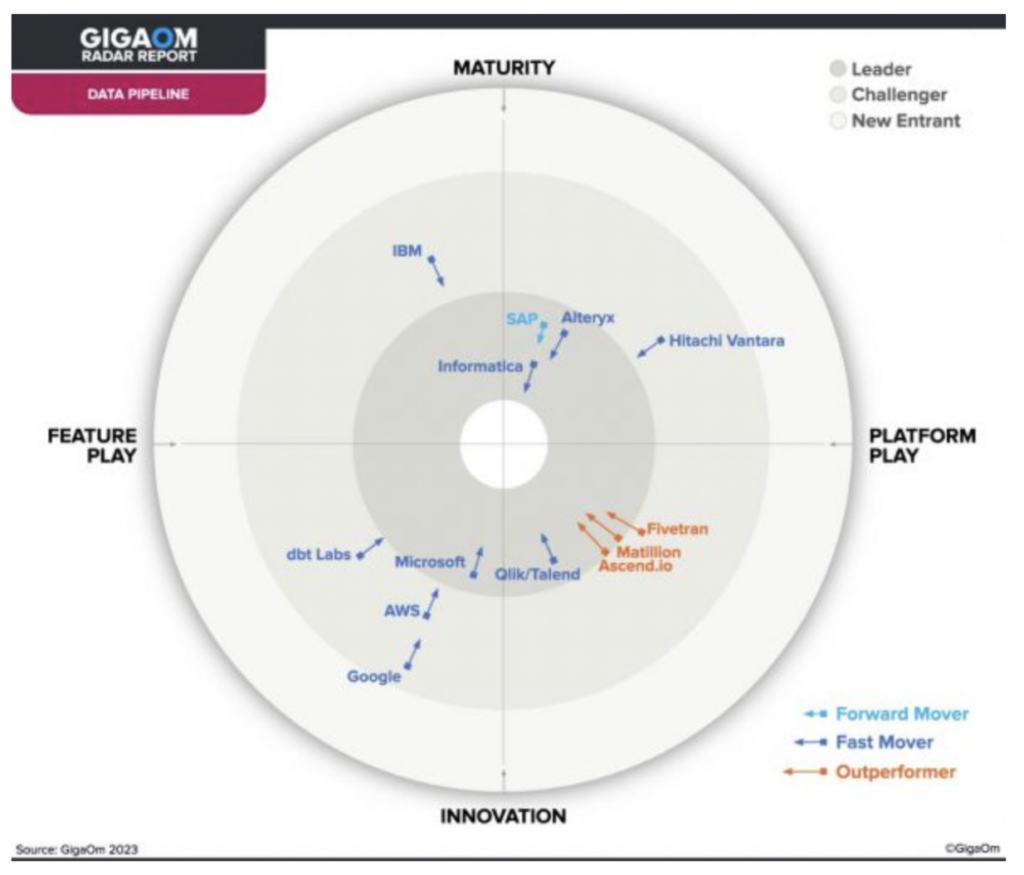
Um relatório recente da GigaOm classificou o Ascend como um dos apenas três outperformers no espaço de Data Pipeline, o que faz dele uma escolha ideal para um data pipeline moderno.
O serviço Ascend.io detecta qualquer mudança nas suas fontes e propaga essas alterações automaticamente pelo seu data pipeline, no Data Warehouse de escolha, eliminando o agendamento ou a execução manual de jobs pelas suas equipes.
Ele também oferece integração de primeira linha com diversos provedores de Data Warehouse, por meio de otimizações de tabelas/views, como o particionamento dentro dos próprios dataflows do Ascend, otimizando a forma como os dados trafegam pelos seus pipelines no Ascend.
O serviço de data pipeline do Ascend, quando aproveitado ao máximo, conta com 3 planos principais:
- Build Plane - Pense no build plane como um painel único para programar toda a lógica de ingestão e transformação do pipeline. Você também pode programar pipelines no Ascend via código de backend usando seu SDK e CLI. A interface visualiza toda a linhagem dos dados e monitora as operações em tempo real.
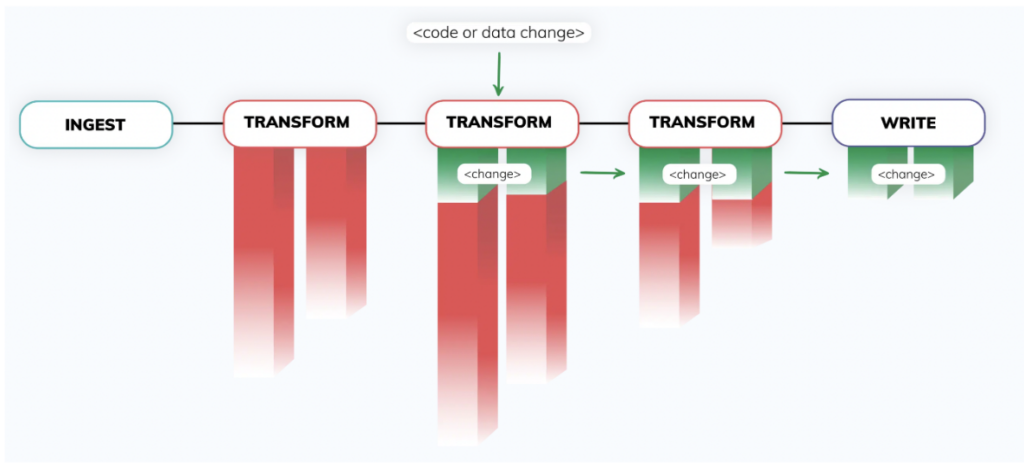
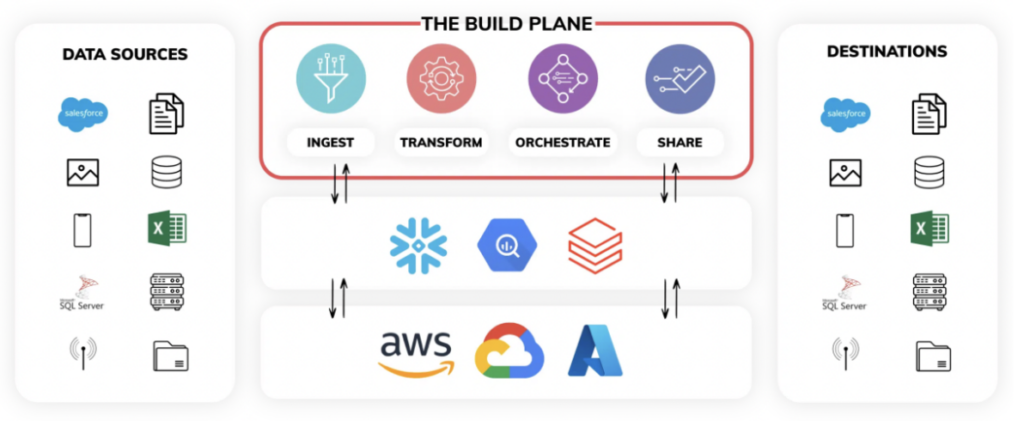 2. Control Plane - No coração da plataforma Ascend está um sofisticado control plane, alimentado por uma tecnologia exclusiva de fingerprinting. Esse mecanismo totalmente autônomo detecta o tempo todo mudanças em dados e código em redes vastas dos data pipelines mais complexos e responde a essas mudanças em tempo real. Os data pipelines permanecem sincronizados sem precisar de nenhum código adicional de orquestração.
2. Control Plane - No coração da plataforma Ascend está um sofisticado control plane, alimentado por uma tecnologia exclusiva de fingerprinting. Esse mecanismo totalmente autônomo detecta o tempo todo mudanças em dados e código em redes vastas dos data pipelines mais complexos e responde a essas mudanças em tempo real. Os data pipelines permanecem sincronizados sem precisar de nenhum código adicional de orquestração.
- Ops Plane - O ops plane do Ascend ajuda a integrar data pipelines inteligentes ao negócio. Ele cobre três pilares essenciais das operações de dados: aumenta a confiança do negócio, quantifica os custos de processamento de dados e gera transparência. O ops plane monitora as sequências de workloads em tempo real, conforme os dados são ingeridos e processados em toda a rede de pipelines interligados.
Atualmente, o Ascend é compatível com os data clouds Google BigQuery, Snowflake e Databricks, e a compatibilidade com outros serviços tende a crescer em breve.
Esse é, sem dúvida, um serviço para considerar com seriedade em workloads de cloud data pipeline, dada sua robusta engine de automação e a capacidade de suportar tanto desenvolvimento via UI quanto baseado em código. Estamos animados em compartilhar este mergulho profundo sobre como usá-lo!
Conhecendo o dbt
![]()
O dbt é uma ferramenta de pipeline de transformação baseada em SQL que permite às equipes implantar código de analytics de forma rápida e colaborativa, seguindo as melhores práticas de engenharia de software, como modularidade, portabilidade, CI/CD e documentação. Ele permite que as equipes trabalhem juntas em tarefas de desenvolvimento via repositórios e vem sendo uma ferramenta bem popular no mercado nos últimos anos.
O dbt vem em dois formatos:
- O serviço dbt Cloud - uma versão do dbt baseada em UI que também faz a implantação e a execução dos modelos dbt diretamente. Esse serviço tem uma versão gratuita para usuários individuais e cobra em diferentes faixas de preço para times de desenvolvedores.
- dbt Core - é a versão do dbt baseada em código, gratuita, que pode ser usada na maioria das IDEs, como o Visual Studio Code, por exemplo. Assim como o dbt Cloud, ele também pode ser ligado a um repositório à sua escolha e ser orquestrado em conjunto com ferramentas como o Apache Airflow para coordenar seus data pipelines.
Além de coordenar o desenvolvimento e a implantação de diversos jobs de transformação, o dbt permite rodar testes unitários nos seus dados e fornece linhagem de dados por meio dos seus recursos de catalogação, o que torna a documentação ponta a ponta dos seus pipelines ELT muito mais simples!
O dbt é compatível com diversas ofertas de Data Warehousing e Data Lake, incluindo Snowflake, BigQuery, Redshift, Databricks & Starburst, o que faz dele uma escolha popular entre grandes empresas que utilizam várias dessas plataformas.
O Bake-Off da DoiT: Nossa Avaliação
Tanto o Ascend quanto o dbt são, claramente, ferramentas eficazes para transformação de dados, e cada um tem suas vantagens próprias e contrastantes — mas qual deles se encaixa melhor em um caso de uso comum de data pipeline? Seguimos os passos abaixo para fazer um bake-off entre os dois serviços.
Nosso cenário: a coleta e transformação em massa de dados meteorológicos diários de agosto, com milhões de registros ingeridos do Google Cloud Storage, processados em data pipelines no Snowflake e no Google BigQuery, separadamente, tanto no Ascend.io quanto no dbt Cloud.
Nosso pseudo pipeline terá as seguintes etapas padrão:
- Ler os dados meteorológicos diários brutos do Data Warehouse de escolha e combinar várias extrações diárias em uma única tabela para análise posterior.
- Segmentar esses dados em diferentes categorias (clima quente, morno e frio, respectivamente) — fazendo transformações básicas no conjunto combinado para chegar a esse resultado.
- Realizar agregações e transformações estatísticas mais avançadas nos conjuntos de dados segmentados. Além de cruzar (join) nossos dados transformados com uma tabela de lookup de localizações, contendo códigos de localização das nossas áreas meteorológicas.
- Enviar os conjuntos de dados finais para uma camada pseudo data mart/apresentação nos nossos data warehouses de escolha.
No nosso caso, primeiro queremos comparar o tempo necessário para construir esses processos do ponto de vista do desenvolvedor, tanto no Ascend.io quanto no dbt, já que uma variável-chave para a performance da equipe é o tempo gasto montando suas soluções de dados.
Com os jobs prontos, queremos avaliar os seguintes pontos como parte do bake-off e do custo total de propriedade de cada solução:
- Os tempos de execução do conjunto completo de data pipelines, do início ao fim (usando tanto hot quanto cold starts no pipeline do Ascend, por causa da infraestrutura Spark envolvida)
- Os créditos consumidos (no Snowflake) e bytes escaneados (no BigQuery) em ambos os data pipelines
- O tratamento de erros — vamos introduzir falhas em ambos os pipelines e investigar como cada um se recupera
- A entrada de novos arquivos de dados meteorológicos nos data pipelines e a reexecução para atualizar os datasets, para testar a performance de cada pipeline quando novos dados são ingeridos
- O nível de interação e controle sobre os Data Warehouses subjacentes — ou seja, parar Virtual Warehouses no Snowflake, particionamento automático nos jobs do Ascend e várias outras tarefas comuns de orquestração de pipeline
Agora que definimos as regras do bake-off, vamos desenvolver o cenário e ver como os nossos dados meteorológicos são enriquecidos nas duas soluções!
O Bake-Off da DoiT: Montando o Caso
Vamos passar pelo processo de desenvolvimento, tanto pelo lado do Ascend quanto do dbt.
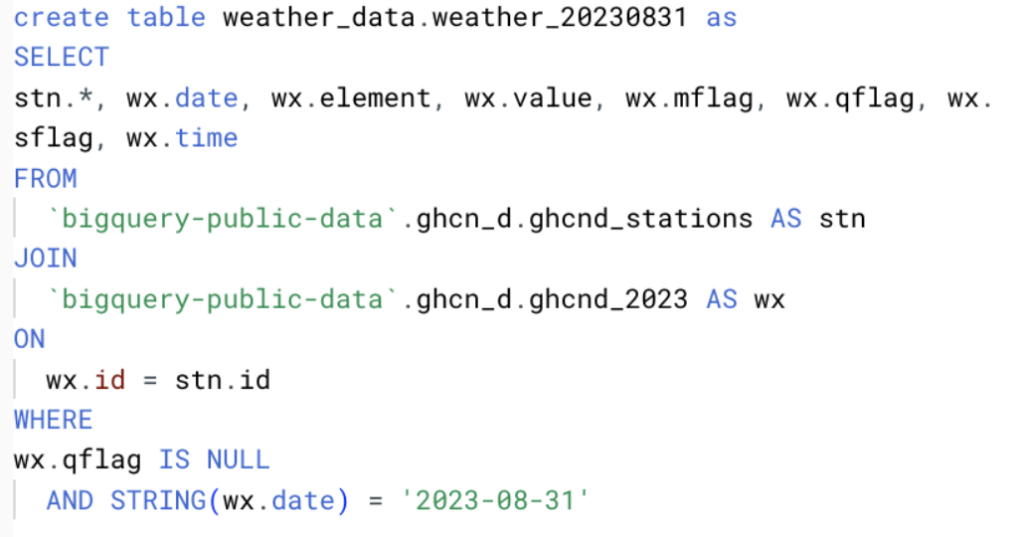
Para o nosso estudo de caso, coletamos os dados meteorológicos dos datasets públicos ghcn_d do Google.
Para garantir um bom volume, selecionamos todos os campos desses dados e geramos arquivos diários entre 01/08/2023 e 31/08/2023, conforme a query abaixo.
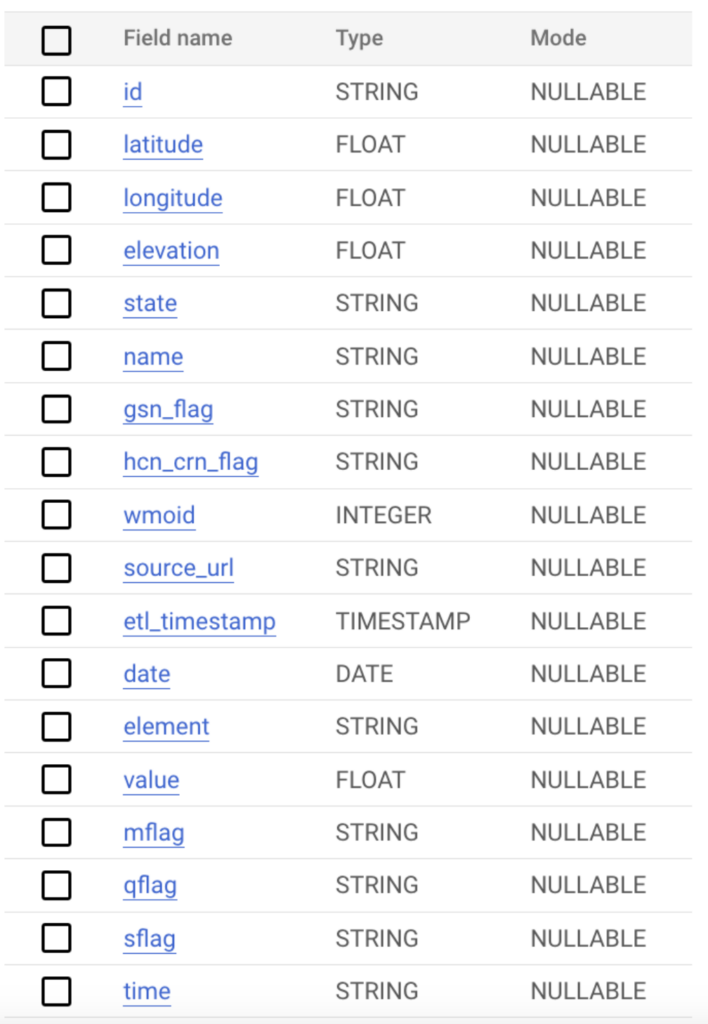
Os dados, neste caso, têm o schema abaixo e milhões de registros no total. Para testar vários cenários, armazenamos esses dados em tabelas do BigQuery e no Google Cloud Storage, a fim de testar diferentes métodos de ingestão entre as plataformas.
Processo de Desenvolvimento no Ascend
No Ascend.io, você cria um data pipeline montando Dataflows, que ficam armazenados dentro de Data Services, o que oferece um modelo de segurança compartilhado para os seus diferentes data pipelines, como dá para ver no nosso ambiente de playground.
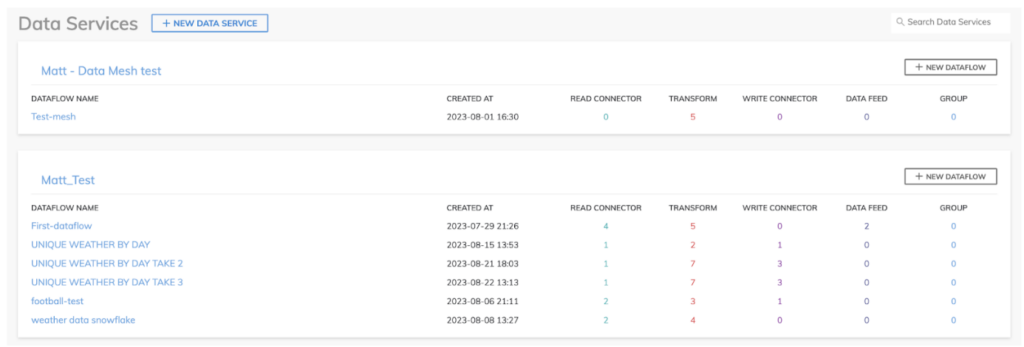
Os Dataflows do Ascend trazem diversos componentes de ingest/read, transform e deliver/write para usar em cada etapa do seu pipeline.
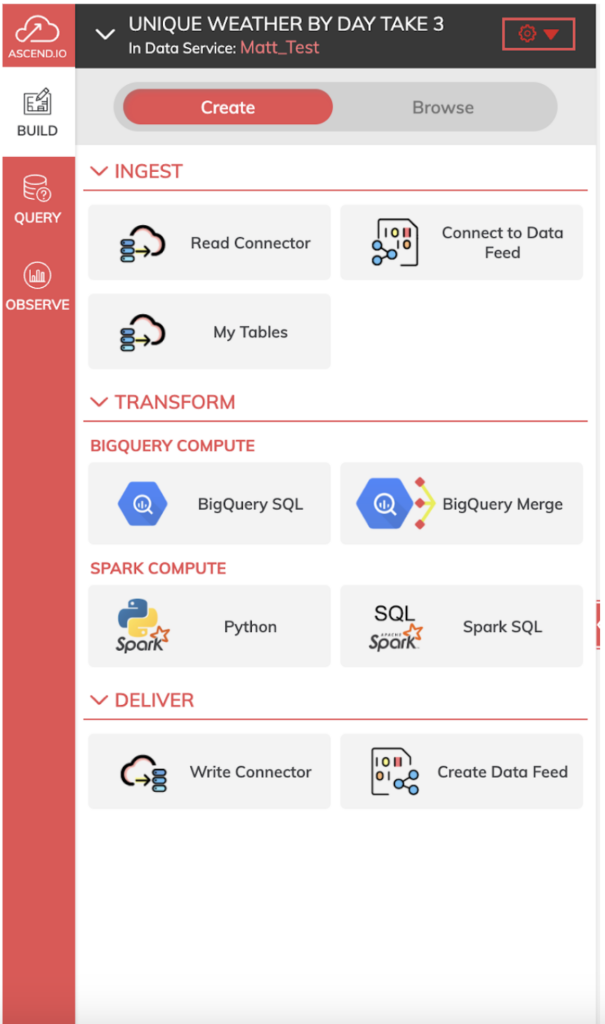
No nosso pipeline, queremos primeiro usar Read Components para ingerir os arquivos iniciais de dados meteorológicos, vindos diretamente do GCS ou do BigQuery.
Em seguida, usamos componentes de transformação para moldar os dados conforme o nosso processo. Usei BigQuery SQL neste bake-off, por ser o sabor de SQL com o qual tenho mais familiaridade, mas você pode escolher entre várias linguagens, como Python, Spark SQL ou SnowSQL (se habilitado), para construir suas transformações no Ascend.
Por fim, usamos um componente de write para gravar a saída do pipeline totalmente transformado de volta no data warehouse de escolha.
O pipeline ilustrado abaixo é o que montei para este bake-off. Ele é formado por três rotas de dados, para diferentes graus de cenários de clima quente/frio na nossa análise final:
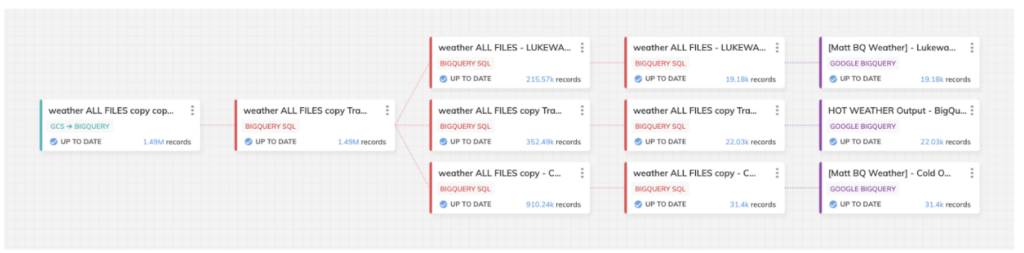
O design desse pipeline foi o mesmo no BigQuery e no Snowflake, mas o screenshot é do template projetado no BigQuery.
No nosso conector de leitura, primeiro configuramos a conexão com os arquivos no bucket do GCS (Google Cloud Storage). Para isso, precisamos usar uma service account com acesso ao bucket em questão.
Como temos vários arquivos meteorológicos, podemos definir um prefixo para eles no Ascend, para que ele saiba que precisa ingerir todos os arquivos com convenções de nomes parecidas no nosso pipeline.
Também ingerimos linhas de cabeçalho nos nossos arquivos CSV, então precisamos marcar a opção de excluí-las dentro do componente de leitura do Ascend.
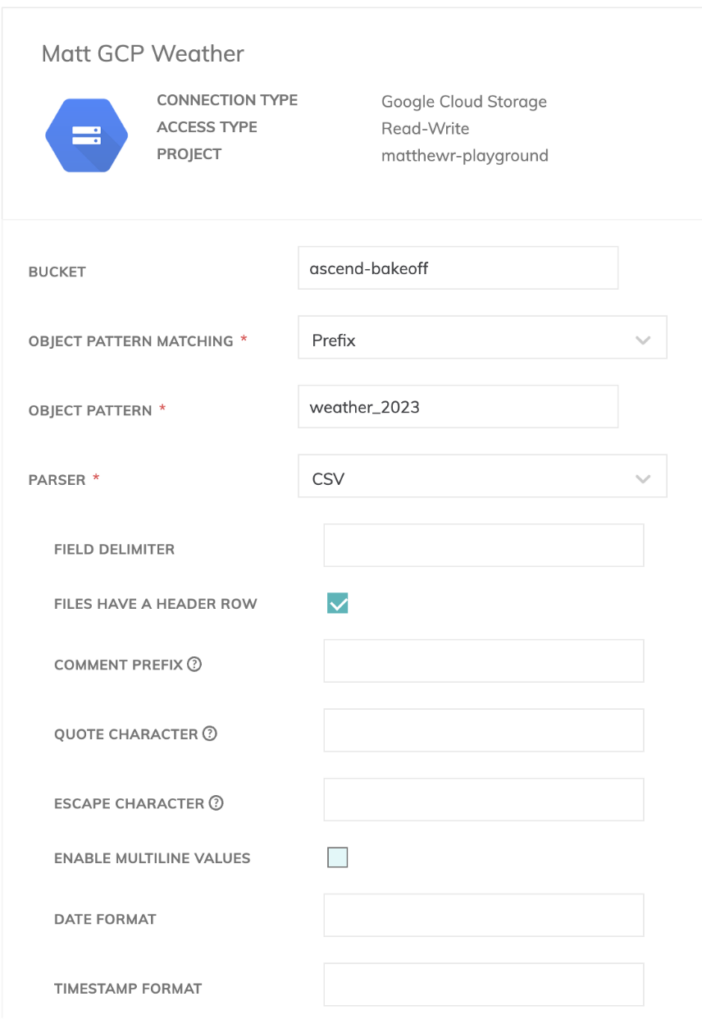
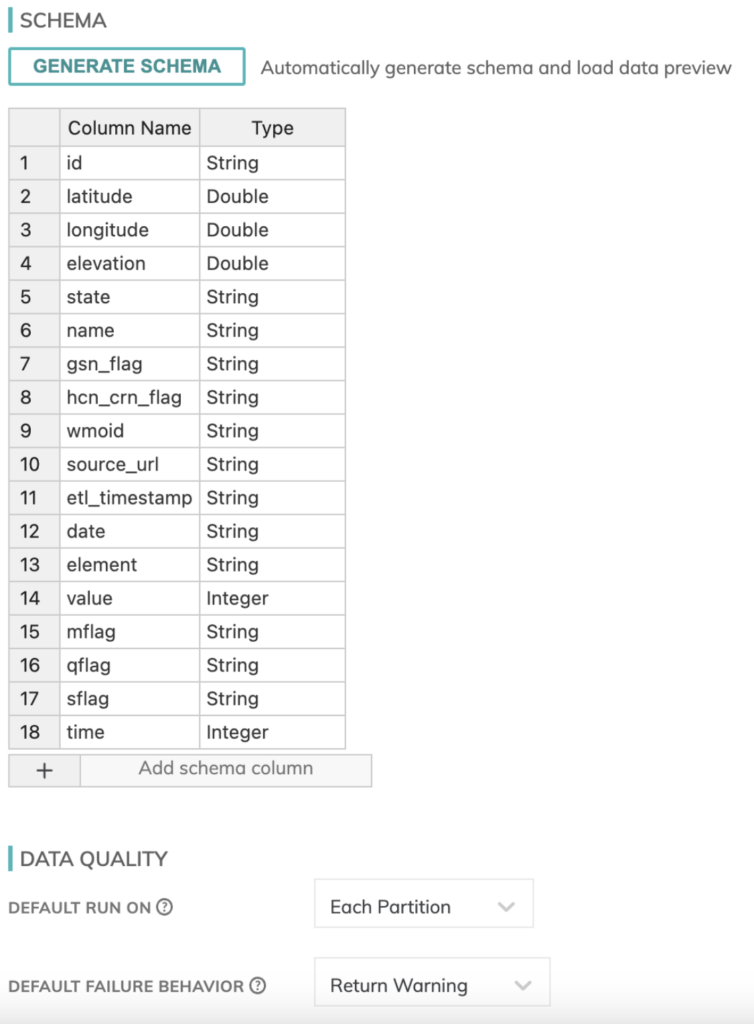
Também precisamos definir um schema para os nossos dados meteorológicos. Por sorte, o Ascend tem um detector de schema integrado nos componentes de leitura, então isso ficou bem simples de montar.
Você também pode definir aqui verificações de qualidade de dados e o comportamento em caso de falha, para gerenciar seus jobs do início ao fim.
Outra função interessante da plataforma Ascend é o particionamento de datasets específico do pipeline. Isso segmenta seus dados em pedaços significativos e os processa de forma independente, acelerando o throughput dos seus data pipelines no data warehouse de escolha.

Como dá para ver em um subset de 20 dias dos nossos dados, as partições são segmentadas, uma para cada dia dos arquivos meteorológicos.
Em relação às transformações, configurá-las no Ascend também foi simples. Basta escolher a linguagem desejada e escrever o código na janela principal do componente, conforme ilustrado abaixo.
Vale destacar que, assim como a linguagem de macros do dbt, o Ascend usa lógica Jinja para referenciar nomes de componentes de etapas anteriores do pipeline. Quem já está acostumado com esse estilo vai se sentir em casa em qualquer uma das plataformas.
Para não alongar demais esta seção, coloquei aqui apenas um componente básico de transformação a título de ilustração. Mas vale lembrar que adicionamos um guia de referência completo das transformações deste pipeline de exemplo em um repositório do GitHub, linkado no fim deste post.
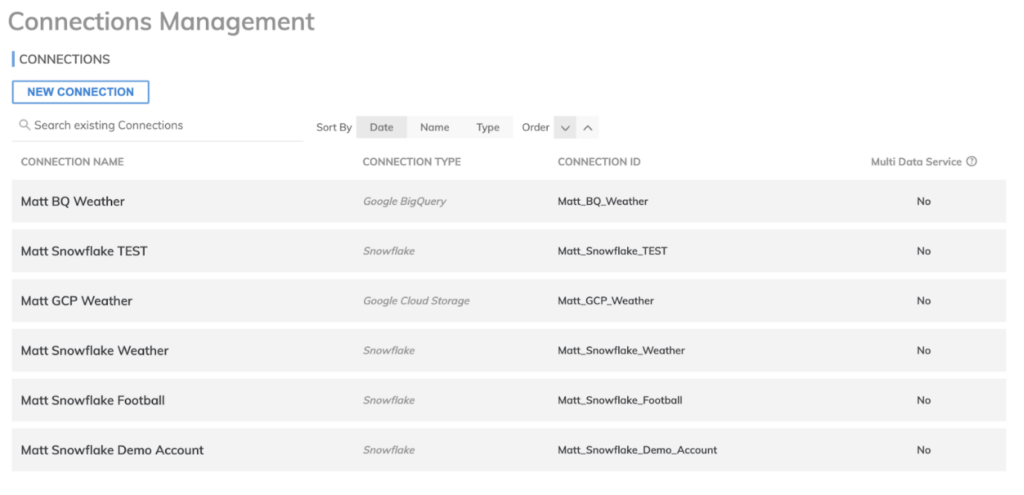
Por fim, para os nossos componentes de write ou "reverse-ETL", precisamos novamente especificar uma conexão com o data warehouse no BigQuery.
As conexões podem ser configuradas dentro da área Admin no Ascend.io, como mostrado aqui. Elas são essenciais tanto para componentes de leitura quanto de escrita, e o Ascend.io suporta uma variedade de conexões, como data warehouses Snowflake ou BigQuery, ou buckets de armazenamento em qualquer nuvem.
A partir daí, os componentes de escrita são bem simples. Basta especificar uma conexão, o layout do schema de saída, depois, no data warehouse de escolha, o nome da tabela de saída e quaisquer outras opções específicas da nuvem (como nome do dataset no BigQuery ou schema no Snowflake).
Vale notar que, por padrão, o Ascend materializa os dados em cada etapa de transformação do pipeline nos dataplanes do Snowflake ou do BigQuery. Por isso, criar um conector de saída de volta para o data warehouse não é obrigatório, mas está disponível caso você queira fazer ajustes finos no schema que não envolvam outra lógica de transformação.
Em termos de esforço total de desenvolvimento, apesar de parecer que tem várias etapas no meu processo e na explicação aqui, esse pipeline levou cerca de 10 minutos para ser montado por completo, incluindo o tempo gasto para configurar minhas conexões com GCS, BigQuery & Snowflake nas minhas contas de playground do Ascend.io para esta demonstração.
Outra coisa interessante: sempre que novos arquivos de Weather eram adicionados, conforme as nossas regras originais, eles eram detectados automaticamente pelo nosso data service do Ascend e o pipeline conseguia ser reexecutado sob demanda diante das novas adições de arquivos/dados.
O grande trunfo do Ascend para esse tipo de caso de uso é que, depois que o pipeline está pronto, ele exige pouca manutenção pelo restante do ciclo de vida. Realmente não é preciso muito trabalho extra para mudar a lógica ou acrescentar novas etapas ao processo. Quando essas mudanças acontecem, o controlador de automação as detecta e descobre sozinho quais partes do pipeline precisam ser reexecutadas e quais partições do dataset precisam ser atualizadas. Mais impressionante ainda: isso pode acontecer em vários pipelines interconectados, ou seja, uma única alteração no meu modelo é orquestrada automaticamente pelo serviço, disparando dezenas de jobs de processamento e DAGs sem que eu precise mexer em nada. Esse é um grande ponto positivo do serviço Ascend!
Processo de Desenvolvimento no dbt
No lado do dbt deste bake-off, usei o serviço dbt Cloud com a minha conta gratuita. Pareceu a opção mais natural, porque o dbt Cloud tem orquestração integrada própria, sem exigir um serviço de terceiros como o Airflow, garantindo uma comparação mais justa com a experiência all-in-one do Ascend.
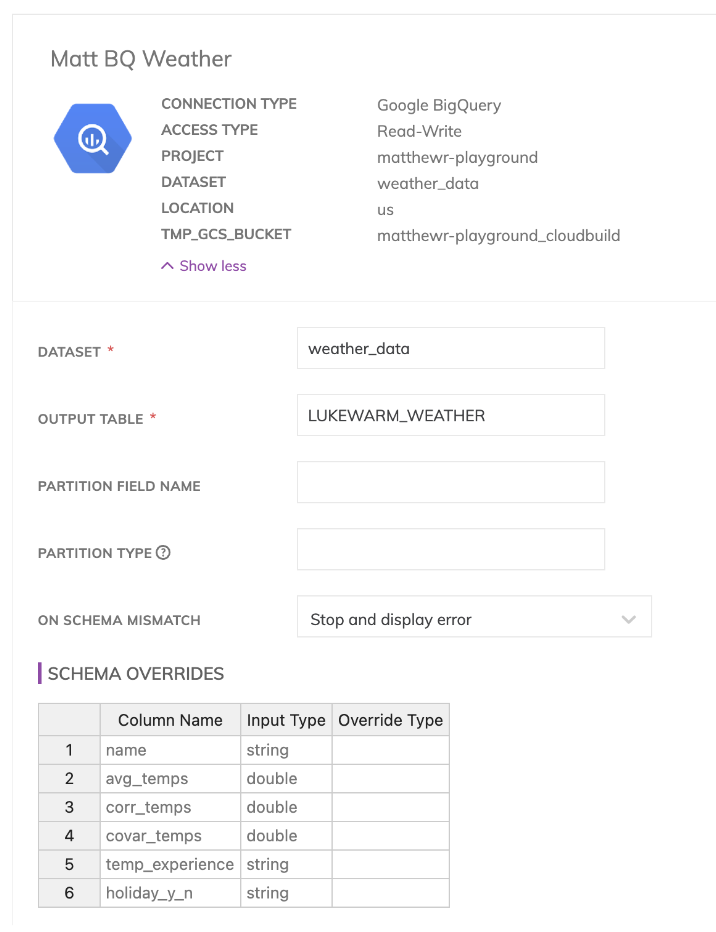
Assim como no Ascend, no dbt Cloud você precisa especificar o ambiente de desenvolvimento. Como o dbt foi feito para se conectar ao seu data warehouse de escolha, criamos conexões para os ambientes BigQuery e Snowflake, com as credenciais necessárias, conforme abaixo.
O dbt tem vários diretórios que compõem a infraestrutura dos seus pipelines, como Models (com os jobs SQL executados no DWH de escolha), Tests (com testes unitários sobre esses modelos), Macros (com lógica reutilizável para os jobs) & Seeds, entre outros.
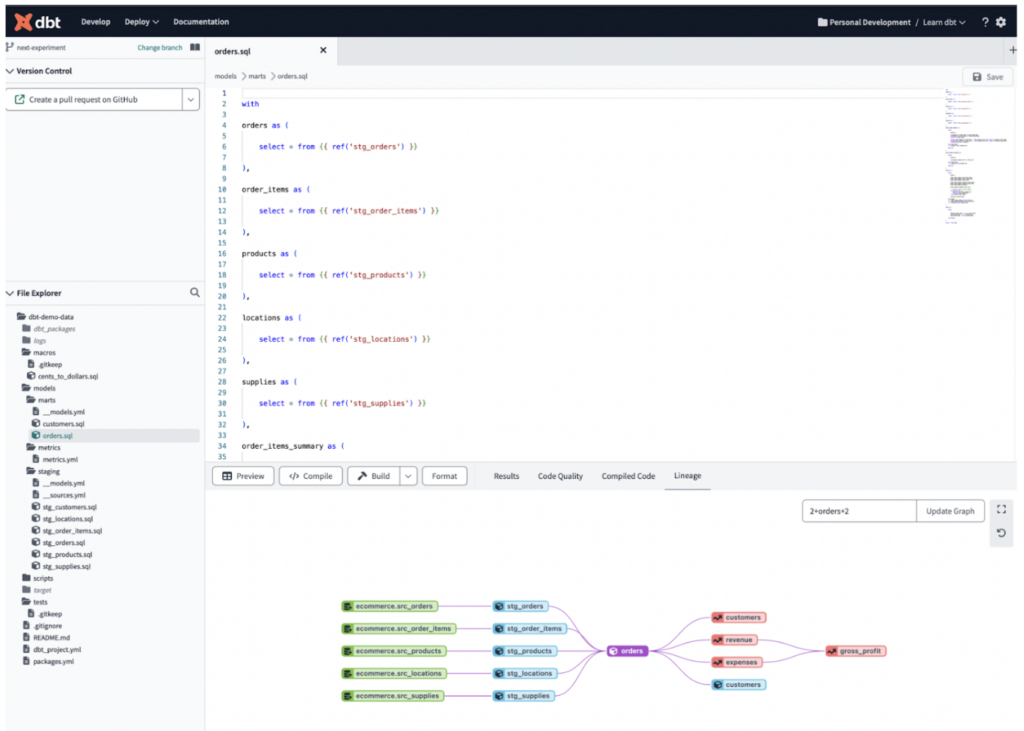
Para este pipeline, replicamos a mesma lógica do nosso pipeline Ascend dentro do dbt em vários arquivos de modelo .sql, reproduzindo o mesmo processo.
Abaixo, uma visão do DAG do nosso processo dbt construído para a lógica do bake-off:

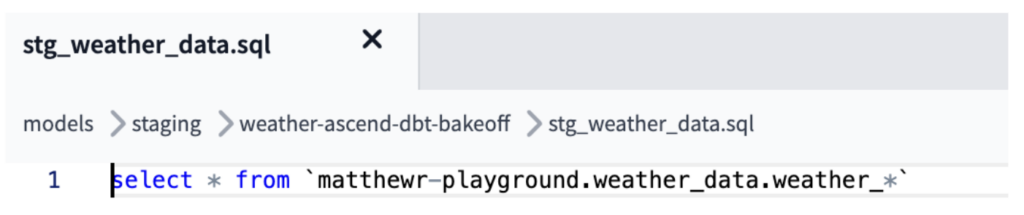
Neste caso, para replicar a ingestão & combinação dos arquivos CSV que vêm dos conectores de leitura do Ascend, o modelo "stg_weather_data" no dbt juntou os múltiplos arquivos/tabelas de origem usando lógica de external source no GCS, ou usou lógica de wildcard do BigQuery para combinar todos os dados em um único arquivo, como no job equivalente do Ascend (mostrado abaixo).
Isso deu conta do cenário de arquivos adicionais mencionado nas nossas regras do bake-off, com a cláusula wildcard pegando esses arquivos conforme novos eram carregados no BigQuery (a lógica também pode ser ajustada para captar novos arquivos adicionados no GCS).
Em seguida, criamos vários modelos dbt em diretórios diferentes para as camadas de data warehousing Staging/Mart, com a tabela mart final usada no nosso exemplo para gerar a tabela equivalente nos data warehouses BigQuery ou Snowflake, respectivamente. Assim, conseguimos os mesmos resultados com a mesma sintaxe SQL das execuções no Ascend, garantindo uma comparação real de bake-off.
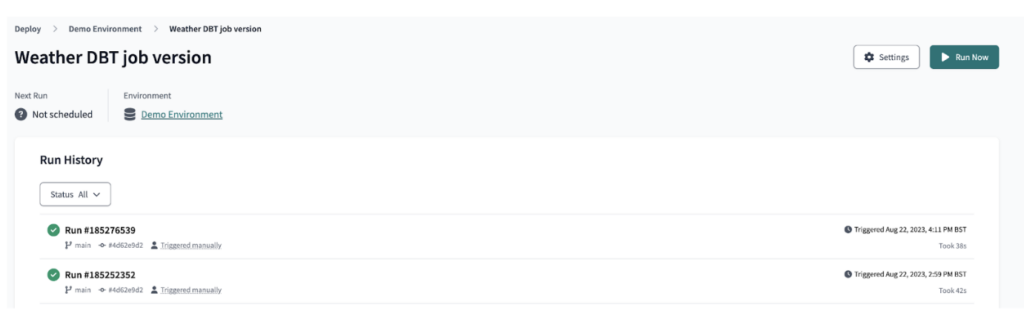
Usando o dbt Cloud, implantamos a saída do dbt como um job, que orquestrou a execução do pipeline dbt, conforme ilustrado.
Por conta da configuração da orquestração do job no dbt cloud, o tempo total de desenvolvimento foi um pouco maior do que a montagem equivalente do pipeline no Ascend. Além disso, como o dbt é uma solução baseada em código, foi preciso tempo extra para configurar o lado padrão de ingestão do pipeline (via configuração de arquivo .yml) e a saída da tabela final da camada de apresentação, que já vinha embutida no conector de write do pipeline Ascend.
Esse pipeline equivalente levou cerca de 20 minutos para ser construído no dbt.
Vale notar também que, ao contrário do Ascend, o dbt não tem mecanismos automáticos para dividir os dados em partições na ingestão. Ele também não consegue detectar arquivos adicionais incluídos no seu bucket de origem nem disparar novas ingestões em batch incrementais logo após a detecção (seja no GCS ou no BigQuery).
Você pode aplicar particionamento e clustering do BigQuery nos arquivos .yml do dbt, mas isso exige configuração extra e não equivale às partições de ingestão criadas automaticamente pelo Ascend.
Além disso, embora a lógica de tratamento de erros do dbt seja suportada por meio de pacotes como o Great Expectations, isso também é algo que você precisa configurar instalando esses pacotes. Para acrescentar essa lógica aos seus jobs, é preciso ainda dominar a sintaxe desses pacotes, em vez de simplesmente marcar configurações em checkboxes, como acontece no Ascend.
O Bake-Off da DoiT: Resultados
E agora, o momento que todos esperávamos. Mãos à massa!
Os testes de ambos os pipelines, do início ao fim, nos deram os seguintes resultados de performance:
Tempos de execução
"Cold Start" - tempo médio da primeira execução dos pipelines completos
- Ascend: 2 min e 6 s
- dbt: 47 s
Olhando para os tempos iniciais de execução, o pipeline do dbt Cloud foi mais rápido no cold-start. Mas isso provavelmente é influenciado pela infraestrutura dos pipelines Ascend nos bastidores, em que clusters Kubernetes são iniciados sob demanda para a execução do job e ficam ociosos entre jobs para reduzir os custos de compute.
Por isso, fizemos uma nova checagem de runtime para uma comparação justa, em um cenário de hot-start, com os clusters do Ascend já iniciados.
"Hot Start" - tempo médio das execuções subsequentes dos pipelines completos
- Ascend: 10 s
- dbt: 32 s
As execuções subsequentes mostraram que o Ascend é bem mais rápido com os mesmos volumes de dados e o mesmo código de transformação rodando em ambos os pipelines. Isso provavelmente se deve à natureza dinâmica e paralelizada dos clusters do Ascend, ou seja, o processamento de cada etapa pode ser multi-thread e, com isso, ficar bem mais rápido.
Comparação de créditos do Snowflake usados & Bytes do BigQuery
Créditos do Snowflake por job
Em relação aos créditos consumidos ao longo dos pipelines completos, tanto no Ascend quanto no dbt, segmentamos cada um para usar schemas diferentes no nosso Snowflake Database para o bake-off. Mais especificamente, o pipeline Ascend usou as conexões "sources_ascend" e "ascend_t_conn", e o pipeline dbt usou os schemas "dbt_mrichardson" e "public".
O pipeline Ascend foi visivelmente mais eficiente do que o pipeline dbt em termos de créditos do Snowflake consumidos. O total de créditos foi:
- Consumo do Pipeline Ascend = 61,165 + 28,071 = 89,236 créditos
- Consumo do Pipeline dbt = 1.924,652 + 33,685 = 1.958,337 créditos

Essa diferença grande no Snowflake se explica, em parte, pelo particionamento que o Ascend aplicou aos nossos dados meteorológicos. Como cada arquivo foi propagado de forma incremental, sem precisar de uma redução completa na ingestão, exigiu-se bem menos compute para rodar o pipeline e também durante o desenvolvimento. Outra parte da diferença vem de outros recursos de economia e gestão de compute da plataforma Ascend, como desligar os Snowflake Virtual Warehouses assim que o pipeline termina o processamento, evitando acumular tempo de uptime desnecessário.
Slots do BigQuery usados por job
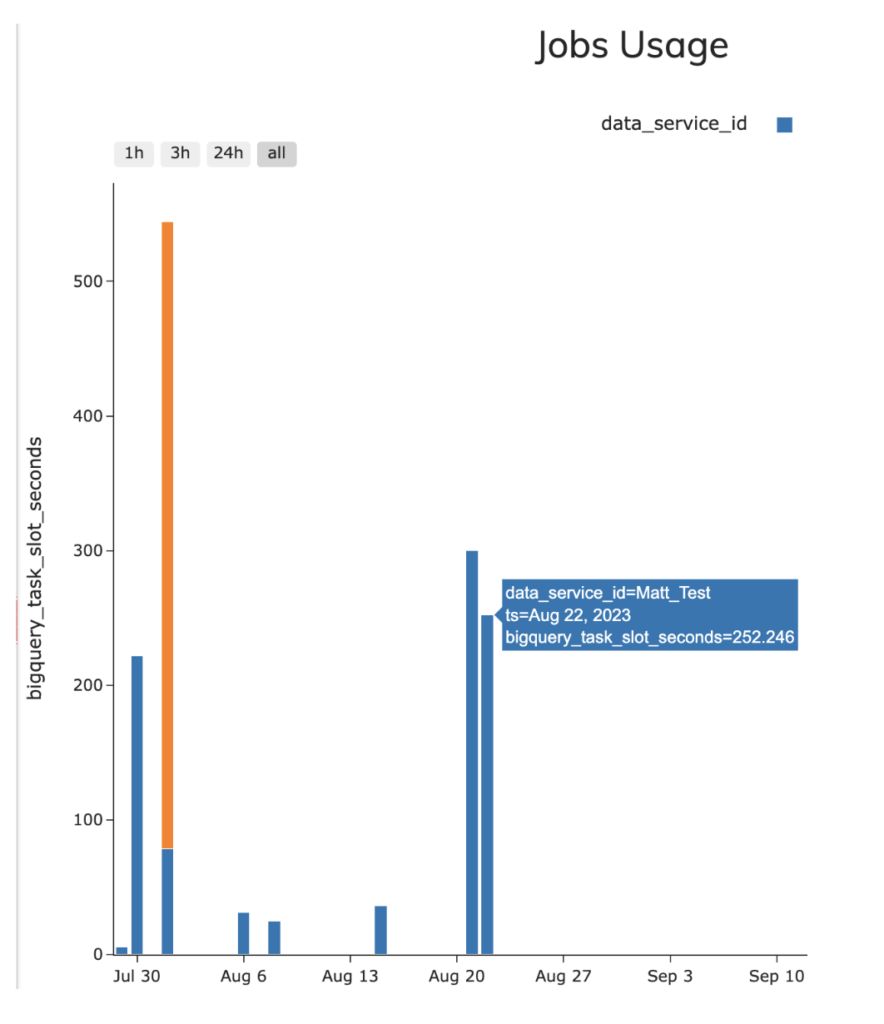
- Ascend - 4,18 slots por segundo em média (252,46 slot seconds totais)
- dbt - 3,2 slots por segundo em média (189,34 slot seconds totais)
No BigQuery, os dois pipelines conseguiram executar os jobs de forma bem eficiente do ponto de vista de slots, com o dbt Cloud sendo um pouco mais eficiente, em média, ao longo da execução. Investigando o motivo dessa pequena diferença na utilização de slots, percebemos que ela veio das configurações de execução do meu Data Service no Ascend versus o DAG de teste construído no dbt, em termos do paralelismo de cada execução: o Ascend rodou mais etapas do meu pseudo processo de ETL em paralelo, gerando uma maior contenção de slots no Ascend versus o dbt no meu exemplo (por causa da alocação de threads na minha configuração do dbt).
Para testar, ajustei a execução do meu pipeline dbt acrescentando a opção –threads:4 para ampliar o paralelismo do meu pipeline dbt e observei um desempenho médio de slots por segundo bem parecido, em torno de 4,3 slots por segundo, devido à contenção um pouco maior por recursos de slot na nova execução.
Para conferir essas estatísticas, usei a query de exemplo do information_schema na view JOBS para testar os dois pipelines (incluída no repositório do GitHub que acompanha este post). Vale notar, porém, que na interface do Ascend a visão abaixo já vem incluída na ferramenta para medir a utilização de Slots do BQ e o consumo de Créditos do Snowflake em pipelines executados no Ascend, conforme o screenshot abaixo.
Cenários de Tratamento de Erros
Também testamos alguns cenários de tratamento de erros nos dois pipelines, especificamente:
- Pipelines parados em 70% dos pontos de carga e também no meio das transformações, com a introdução de erros que simulam bugs comuns no código ou nos dados ingeridos. Em seguida, tentamos retomar o pipeline a partir dessa falha e ver o que acontecia.
- Adicionar um novo arquivo CSV inválido aos pipelines para derrubá-los de propósito.
Eis o que observamos ao testar esses cenários diretamente.
Tratamento de Erros no Ascend
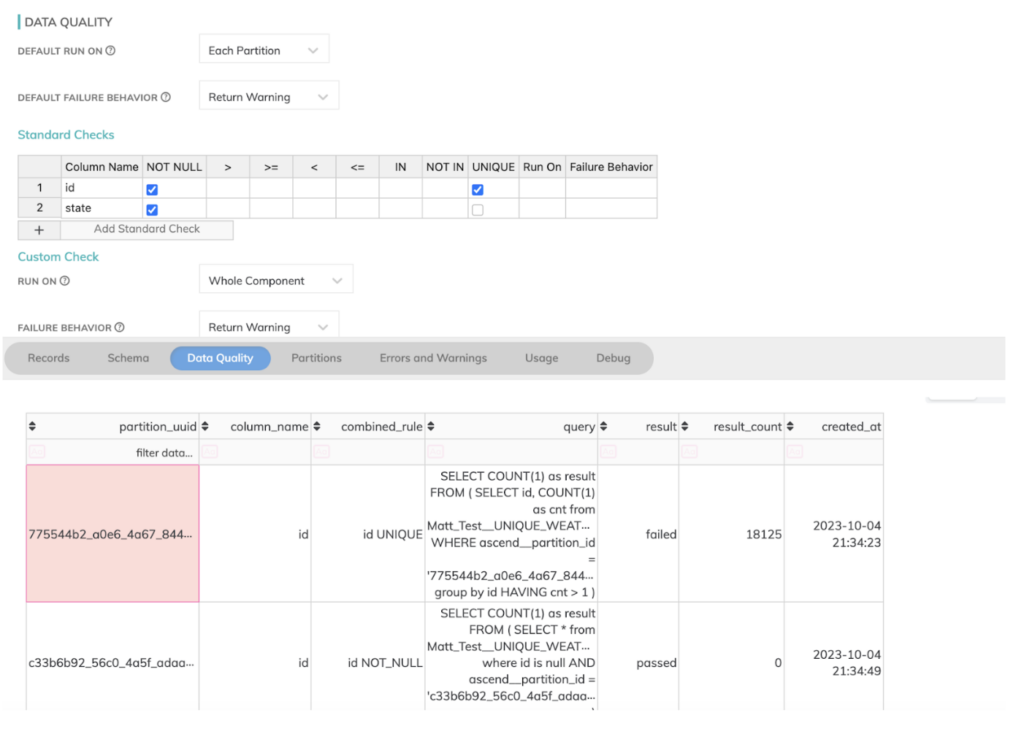
- Tanto o cenário de falha em 70% de uma execução quanto o de inserir um novo arquivo CSV malformado no bucket falharam de forma elegante. O Ascend oferece configurações avançadas para controlar o comportamento do pipeline quando esses erros acontecem. A recuperação do Ascend após uma falha também foi muito mais elegante. Por causa da materialização de cada estágio do pipeline, ele consegue simplesmente retomar a partir do último componente concluído e reiniciar exatamente do ponto da falha. Isso poupou muito reprocessamento que seria necessário se o pipeline tivesse que ser reexecutado por inteiro.
- Além disso, assim como o dbt, o Ascend.io também oferece verificações de qualidade de dados úteis para detectar problemas em arquivos CSV ruins e impedir que entrem no sistema. Tudo isso já vem pronto, nos bastidores, e exige pouquíssima configuração extra para ser aproveitado, como mostra a aba de qualidade de dados do Ascend abaixo, em que inseri alguns valores ruins de campo nos arquivos de origem.
Tratamento de Erros no dbt
Os cenários acima não se encaixaram tão bem no dbt. Conseguimos armazenar/manter erros em uma tabela de tratamento de erros, semelhante ao pipeline Ascend. Mesmo assim, esses recursos exigiram o download de pacotes adicionais do dbt (em particular, o pacote dbt-expectations, da catalogia, oferece boa funcionalidade no lado da qualidade de dados, vale destacar). E embora tenhamos conseguido implementar um processo de reinício no nosso pipeline, isso envolveu ou uma reexecução manual dos jobs ou configuração extra de erro adicionada ao dbt Cloud nas configurações de retry dos jobs.
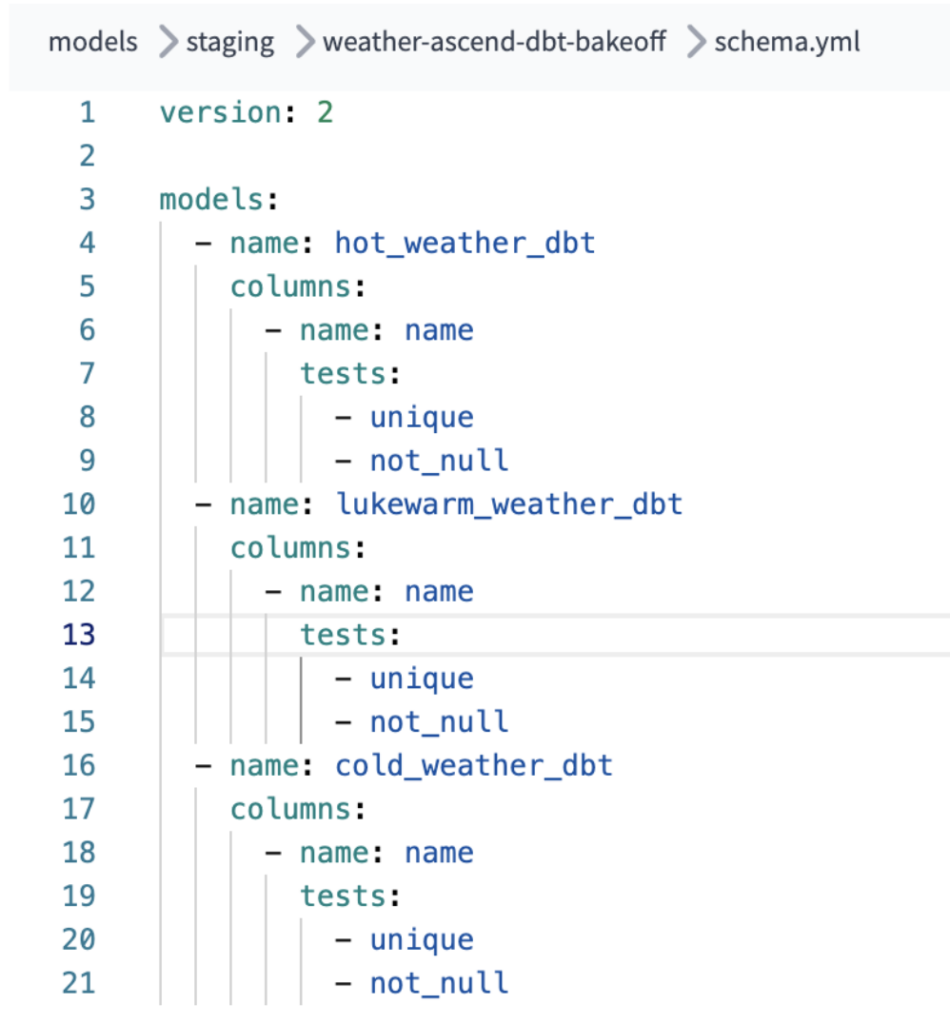
Configuração extra para permitir testes de not-null & unique em cada um dos nossos modelos dbt também foi necessária para que o nosso pipeline dbt fizesse essas verificações. Não foi um esforço excessivo, mas pode confundir desenvolvedores menos familiarizados com a configuração de projetos dbt Core / dbt Cloud.
Considerações Finais
A partir dos testes feitos no estudo de caso de dados meteorológicos, tanto no Ascend.io quanto no dbt, fica claro que os dois serviços conseguem atender bem aos casos de uso de transformação de dados. No entanto, depois de testar a fundo os recursos nativos de cada um e suas extensões de terceiros, percebemos que a melhor escolha de ferramenta depende de qual conjunto se encaixa melhor nas suas necessidades.
Com o Ascend.io, você tem uma ferramenta de cloud data pipeline tudo-em-um que otimiza e orquestra seus data pipelines automaticamente nos bastidores. A UI é mais amigável, tornando a criação de pipelines simples e eficiente para desenvolvedores de diferentes níveis. E ele já traz técnicas de melhoria de performance que fazem seus pipelines rodarem sem solavancos, sem exigir conhecimento de nível especialista em infraestrutura de dados nem horas de codificação manual.
Acreditamos que vale, sim, fazer um trial do Ascend.io para suas necessidades de cloud data pipeline, especialmente quando o seu processo de gerenciamento de dados se beneficiaria de menos manutenção e menos ferramentas de orquestração para administrar. A simplicidade de configuração de jobs e os ajustes de redução de custos de compute em nuvem prontos para uso fazem do Ascend uma ótima alternativa a ferramentas mais focadas em código, como o dbt, dependendo do seu caso de uso.
Como referência deste artigo, os pipelines construídos no Ascend e no dbt podem ser consultados no repositório do Github aqui.