Due strumenti di data transformation per costruire cloud data pipeline messi a confronto diretto.

Molti professionisti dei dati si cimentano con la data transformation, ma quale prodotto fa davvero al caso vostro?
Alcune delle sfide più rilevanti che i clienti DoiT si trovano ad affrontare riguardano la trasformazione e l'elaborazione dei dati provenienti da fonti diverse verso destinazioni altrettanto numerose.
Molti dei nostri clienti utilizzano servizi di Data Warehousing come Snowflake o Google BigQuery per archiviare e gestire i propri dati. Vogliono capire come gestirli in modo efficace, senza dover eseguire e mantenere manualmente il codice delle pipeline.
In passato, con i database relazionali e le infrastrutture di data warehouse tradizionali, questo era il regno degli strumenti ETL: soluzioni come SSIS, Informatica o SAS Data Integration Studio venivano impiegate per gestire l'estrazione source-to-target, la trasformazione e il caricamento dei dati in un data warehouse di scelta.
Il settore, però, si è evoluto con l'avvento dei Cloud Data Warehouse come Snowflake, BigQuery, Redshift e simili. Queste piattaforme di nuova generazione, grazie alla loro architettura e alla loro efficienza, si prestano meglio a un approccio ELT: gestiscono senza problemi il lavoro di trasformazione eseguito come workloads in pushdown direttamente sul data warehouse. Questo rende superflui gli strumenti citati sopra, dal momento che ogni cloud provider dispone in genere di una soluzione efficace per la parte 'EL' dell'ELT e per il caricamento dei dati nei cloud data warehouse supportati nativamente.
Ed ecco entrare in scena lo strumento di trasformazione!
Negli ultimi anni, molti dei nostri clienti hanno adottato data connector specifici per gestire l'estrazione dei dati dalle fonti, e strumenti di trasformazione per eseguire i calcoli più impegnativi all'interno del data warehouse. Insieme, questi passaggi di ingestion e trasformazione formano ciò che oggi molti chiamano cloud data pipeline.
Da qui la crescita nell'utilizzo di strumenti come Fivetran per la prima parte di questa soluzione, e di dbt per la seconda. Ma se esistesse un set di strumenti alternativo in grado di gestire l'ingestion dei dati nelle pipeline, eseguire le trasformazioni più complesse e orchestrare il tutto in modo efficace, senza dover ricorrere a strumenti aggiuntivi come i DAG di Apache Airflow per gestire i job di trasformazione?
Introduzione ad Ascend.io
![]()
Ascend.io è un protagonista di rilievo nella Data Pipeline Automation per la realizzazione delle data pipeline più intelligenti al mondo.
Ascend è un'unica piattaforma che rileva e propaga i cambiamenti lungo tutto il vostro ecosistema, garantisce l'accuratezza dei dati e quantifica il costo dei vostri prodotti dati. In sostanza, vi consente di gestire e costruire una pipeline di ingestion, eseguire trasformazioni complesse e orchestrare il tutto come parte di una pipeline di business più ampia, da un unico punto di controllo!
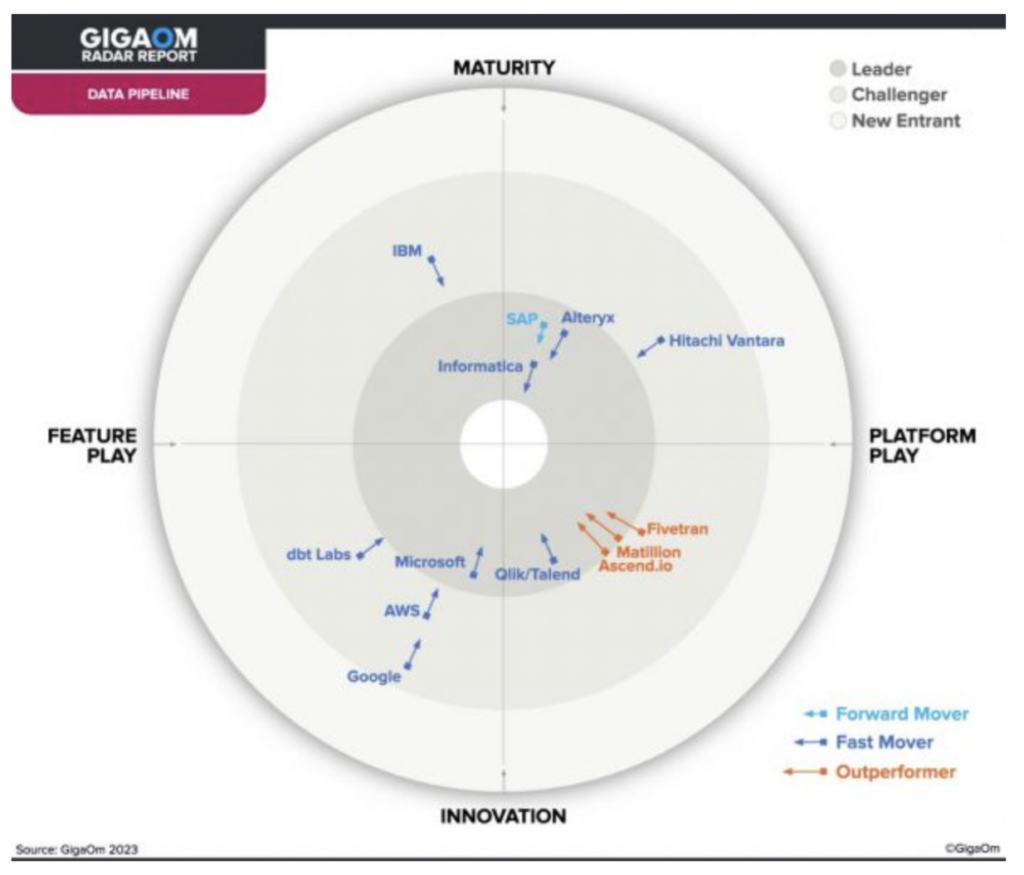
Un recente report di GigaOm ha indicato Ascend tra i soli tre outperformer del settore Data Pipeline, rendendola una scelta ideale per una moderna data pipeline.
Il servizio Ascend.io rileva qualsiasi modifica alle vostre fonti e la propaga automaticamente lungo la data pipeline tramite il Data Warehouse di scelta, eliminando la necessità di pianificare o eseguire manualmente i job da parte dei team.
Offre inoltre un'integrazione di prim'ordine con i principali provider di Data Warehouse, grazie a ottimizzazioni di tabelle e viste come il partizionamento all'interno dei dataflow Ascend, ottimizzando il modo in cui i dati vengono gestiti lungo le pipeline.
Il servizio di data pipeline di Ascend, sfruttato a pieno, comprende 3 piani principali:
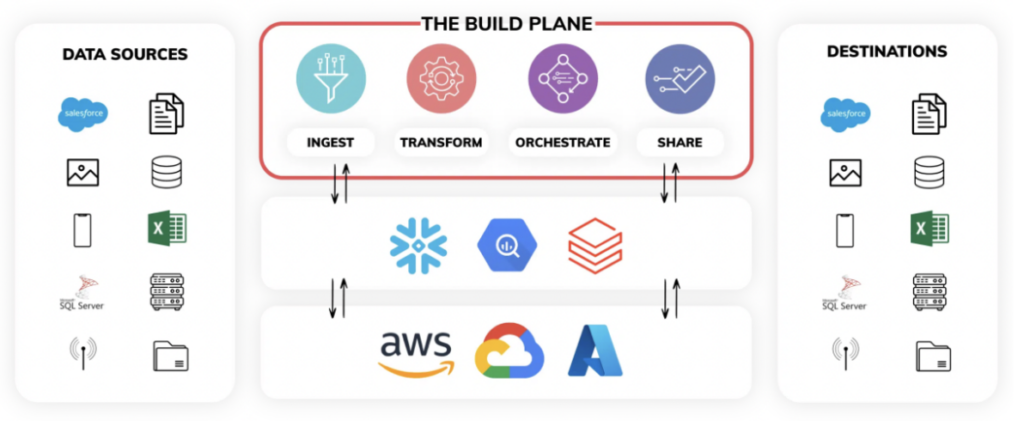
- Il Build Plane - Pensate al build plane come a un single pane of glass da cui programmare tutta la logica di ingestion e trasformazione della pipeline. Potete anche programmare le pipeline in Ascend tramite codice backend, sfruttandone SDK e CLI. La UI visualizza l'intero data lineage e monitora le operazioni in tempo reale.
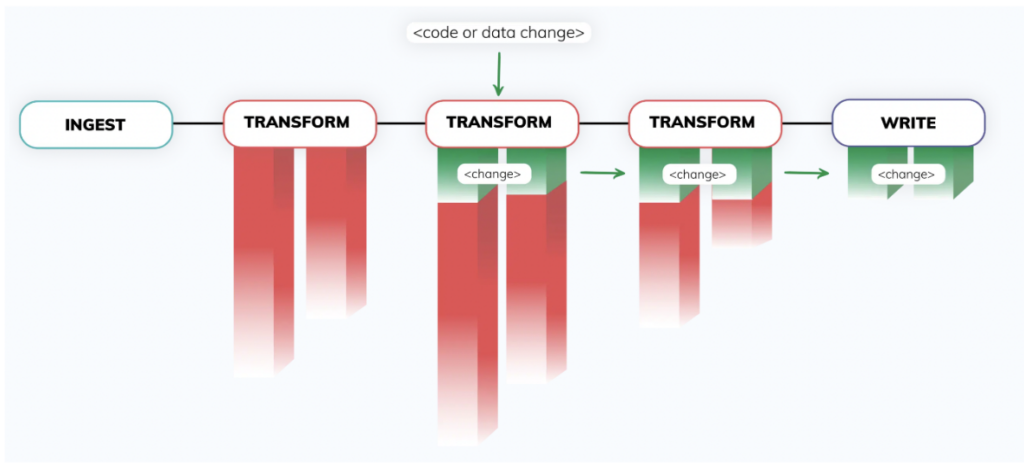
 2. Il Control Plane - Al cuore della piattaforma Ascend si trova un sofisticato control plane, alimentato da un'esclusiva tecnologia di fingerprinting. Questo motore completamente autonomo rileva di continuo i cambiamenti nei dati e nel codice attraverso vaste reti delle data pipeline più complesse, e risponde a tali cambiamenti in tempo reale. Le data pipeline restano sincronizzate senza alcun codice di orchestrazione aggiuntivo.
2. Il Control Plane - Al cuore della piattaforma Ascend si trova un sofisticato control plane, alimentato da un'esclusiva tecnologia di fingerprinting. Questo motore completamente autonomo rileva di continuo i cambiamenti nei dati e nel codice attraverso vaste reti delle data pipeline più complesse, e risponde a tali cambiamenti in tempo reale. Le data pipeline restano sincronizzate senza alcun codice di orchestrazione aggiuntivo.
- L'Ops Plane - L'ops plane di Ascend aiuta a integrare le data pipeline intelligenti nei processi di business. Affronta tre pilastri chiave delle data operations: rafforza la fiducia del business, quantifica i costi di elaborazione dei dati e crea trasparenza. L'ops plane monitora le sequenze di workloads in tempo reale, mentre i dati vengono ingeriti ed elaborati attraverso l'intera rete di pipeline collegate.
Ascend è attualmente compatibile con i data cloud Google BigQuery, Snowflake e Databricks, e la compatibilità con altri servizi continuerà ad ampliarsi nel prossimo futuro.
È senza dubbio un servizio da prendere seriamente in considerazione per i workloads di cloud data pipeline, grazie al suo solido motore di automazione e alla capacità di supportare lo sviluppo sia tramite UI sia tramite codice. Siamo entusiasti di proporvi questo approfondimento sul suo utilizzo!
Introduzione a dbt
![]()
dbt è uno strumento di transformation pipeline basato su SQL che permette ai team di rilasciare codice di analytics in modo rapido e collaborativo, seguendo le best practice del software engineering come modularità, portabilità, CI/CD e documentazione. Consente ai team di collaborare sulle attività di sviluppo tramite repository ed è uno degli strumenti più diffusi sul mercato negli ultimi anni.
dbt è disponibile in due versioni:
- Il servizio dbt Cloud - una versione di dbt basata su UI che gestisce direttamente anche il deployment e l'esecuzione dei modelli dbt; offre una versione gratuita per singoli utenti e diverse fasce di prezzo per team di sviluppatori.
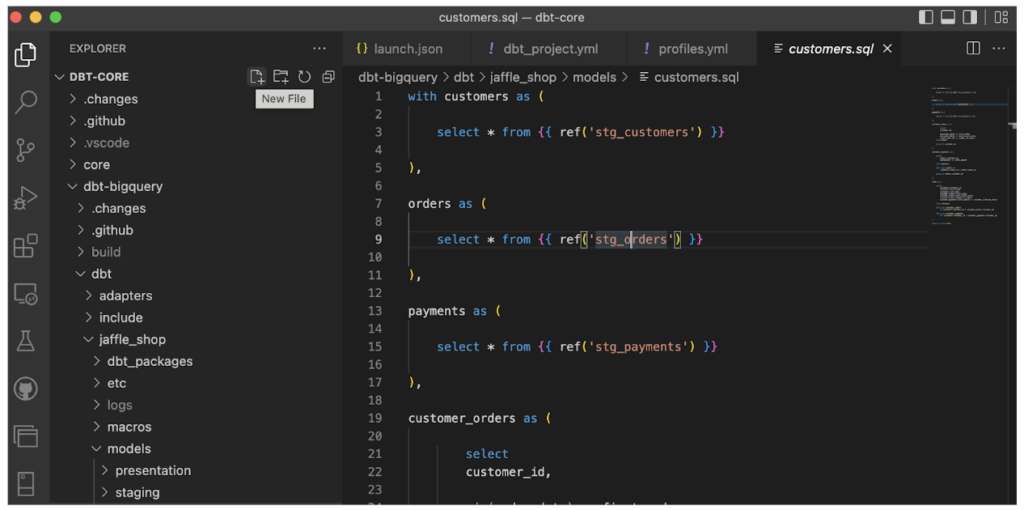
- dbt Core - la versione di dbt basata su codice, gratuita e utilizzabile tramite la maggior parte degli IDE come Visual Studio Code. Al pari di dbt Cloud, può essere collegata a un repository di vostra scelta e orchestrata insieme a strumenti come Apache Airflow per coordinare le data pipeline.
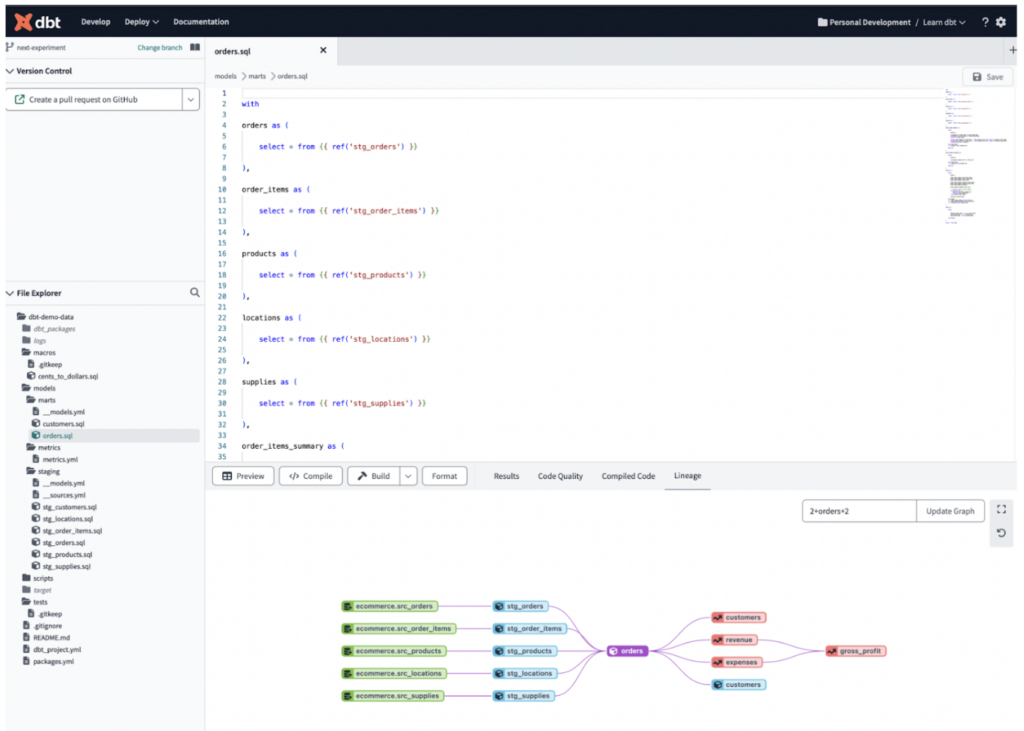
Oltre a coordinare lo sviluppo e il deployment dei vari job di trasformazione, dbt vi consente di eseguire test unitari sui dati e fornisce anche il data lineage grazie alle sue funzionalità di catalogazione, rendendo molto più semplice documentare il flusso end-to-end delle pipeline ELT!
dbt è compatibile con diverse soluzioni di Data Warehousing e Data Lake, tra cui Snowflake, BigQuery, Redshift, Databricks e Starburst, il che lo rende una scelta apprezzata dalle grandi aziende che ne utilizzano più di una.
Il DoiT Bake-Off: la nostra valutazione
Ascend e dbt sono entrambi strumenti efficaci per la data transformation e ognuno ha i propri punti di forza, spesso complementari. Ma quale dei due è più adatto a un caso d'uso comune di data pipeline? Abbiamo seguito i passi descritti di seguito per organizzare un bake-off tra i due servizi.
Il nostro scenario: raccolta e trasformazione massiva di dati meteorologici giornalieri per il mese di agosto, con milioni di record ingeriti da Google Cloud Storage e poi elaborati attraverso data pipeline sia in Snowflake sia in Google BigQuery, separatamente in Ascend.io e dbt Cloud.
La nostra pseudo pipeline si compone dei seguenti passaggi standard:
- Lettura dei dati meteorologici giornalieri grezzi dal Data Warehouse di scelta e combinazione di più estrazioni giornaliere in un'unica tabella per le analisi successive.
- Segmentazione dei dati in categorie diverse (clima caldo, tiepido e freddo), eseguendo trasformazioni di base sul dataset combinato per ottenere questo risultato.
- Esecuzione di trasformazioni di aggregazione e statistiche più avanzate sui dataset suddivisi, oltre al join dei dati trasformati con una tabella di lookup delle località contenente i codici geografici delle nostre aree meteorologiche.
- Output dei dataset finali in uno pseudo data mart / livello di presentazione nei data warehouse di scelta.
Nel nostro caso, vogliamo innanzitutto confrontare il tempo necessario a costruire questi processi dal punto di vista di uno sviluppatore, sia in Ascend.io sia in dbt: una variabile chiave per la performance del team è infatti il tempo speso a costruire le soluzioni dati.
Una volta costruiti i job, vogliamo poi valutare i seguenti aspetti per la nostra analisi del bake-off e del costo totale di possesso di ciascuna soluzione:
- I tempi di esecuzione dell'intero set di data pipeline dall'inizio alla fine (utilizzando sia hot start sia cold start per la pipeline di Ascend, vista l'infrastruttura Spark sottostante)
- I crediti consumati (su Snowflake) e i byte scansionati (su BigQuery) in entrambe le data pipeline
- La gestione degli errori: introdurremo guasti in entrambe le pipeline e analizzeremo le soluzioni di recovery
- L'inserimento di nuovi file di dati meteorologici nelle data pipeline e la conseguente ri-esecuzione per aggiornare i dataset, così da testare la performance delle rispettive pipeline quando vengono ingeriti nuovi dati
- Il livello di interazione e controllo sui Data Warehouse sottostanti, ad esempio l'arresto dei Virtual Warehouse in Snowflake, il partizionamento automatico nei job Ascend e molti altri compiti comuni di orchestrazione delle pipeline
Definite le regole d'ingaggio per questo bake-off, sviluppiamo lo scenario e vediamo come i dati meteorologici vengono arricchiti in entrambe le soluzioni!
Il DoiT Bake-Off: prepariamo il caso
Vediamo il processo di sviluppo sia dal lato Ascend sia dal lato dbt.
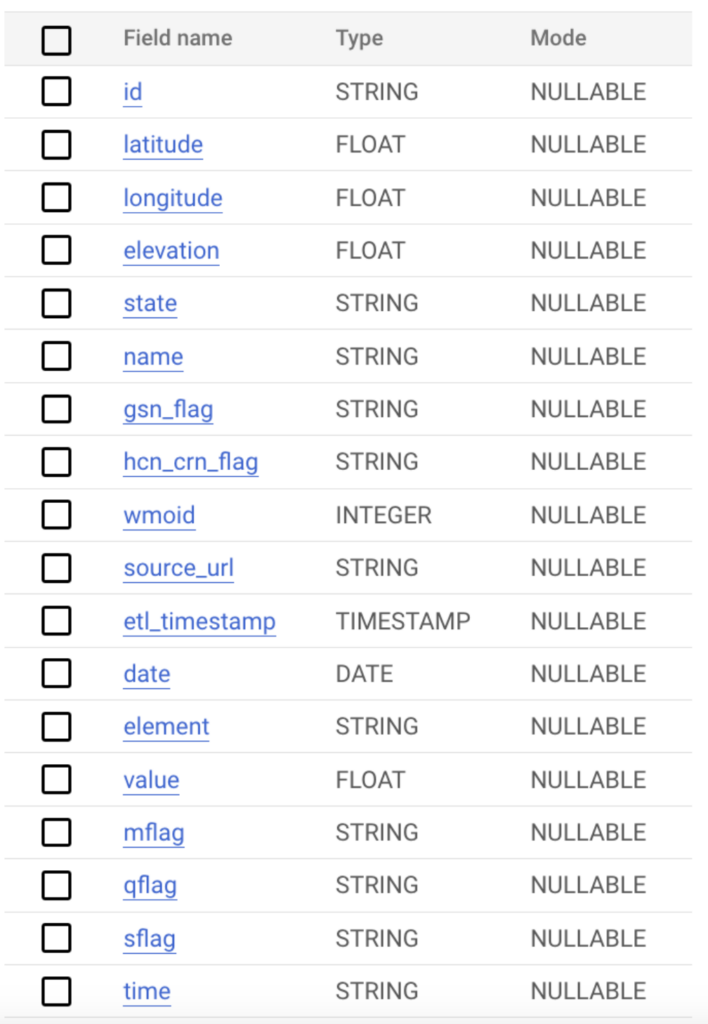
Per il nostro case study abbiamo raccolto i dati meteorologici dai dataset pubblici ghcn_d di Google.
Per ottenere un volume di dati significativo, abbiamo selezionato tutti i campi e creato file giornalieri dal 1° al 31 agosto 2023 inclusi, secondo la query qui sotto.
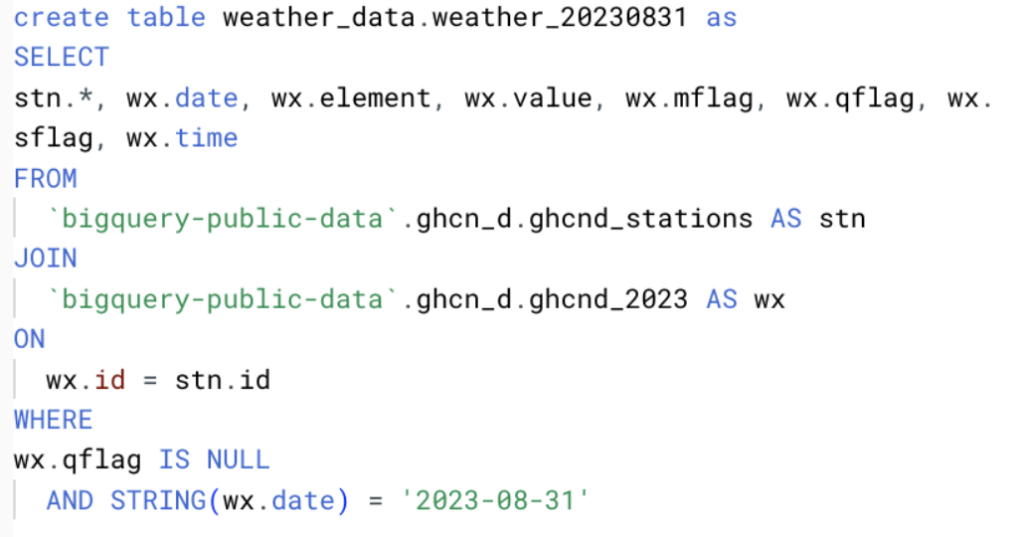
I dati hanno lo schema riportato di seguito e milioni di record in totale. Per testare scenari multipli, li abbiamo archiviati sia in tabelle BigQuery sia in Google Cloud Storage, così da provare diversi metodi di ingestion sulle varie piattaforme.
Processo di sviluppo in Ascend
In Ascend.io potete creare una data pipeline costruendo Dataflow, che a loro volta sono archiviati all'interno dei Data Service: questi offrono un modello di sicurezza condiviso per le diverse data pipeline, come potete vedere nel nostro ambiente di playground.
I Dataflow di Ascend mettono a disposizione vari componenti di ingest/read, transform e deliver/write da utilizzare in ogni passaggio della pipeline.
Per la nostra pipeline, vogliamo prima usare i Read Component per ingerire i file iniziali di dati meteorologici direttamente da GCS o da BigQuery.
Vogliamo poi usare i componenti transform per modellare i dati in funzione del nostro processo. Per questo bake-off ho usato BigQuery SQL, dato che è il dialetto SQL con cui ho più familiarità, ma in Ascend potete scegliere tra diversi linguaggi come Python, Spark SQL o SnowSQL (se abilitato) per costruire le vostre trasformazioni.
Infine, vogliamo usare un componente write per scrivere l'output della pipeline completamente trasformata di nuovo nel data warehouse di scelta.
La pipeline raffigurata qui sotto è quella che ho costruito per questo bake-off. È composta da tre rotte di dati per i diversi gradi di scenari di clima caldo/freddo della nostra analisi finale:
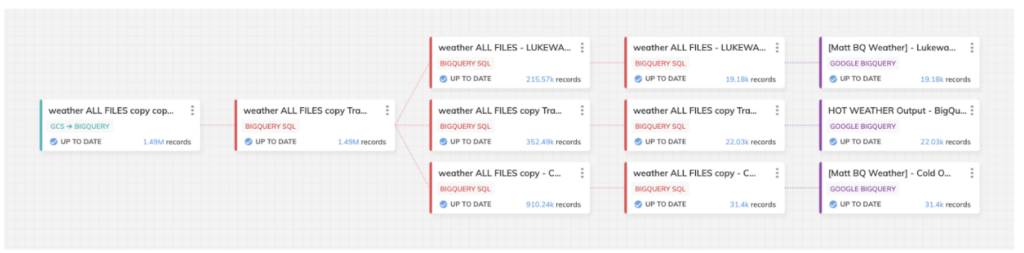
Il design di questa pipeline è identico sia in BigQuery sia in Snowflake, ma lo screenshot è preso dal template progettato per BigQuery.
Per il nostro read connector, abbiamo dovuto innanzitutto configurare la connessione ai file nel bucket GCS (Google Cloud Storage). A tal fine è stato necessario utilizzare un service account con accesso al bucket in questione.
Avendo più file meteorologici, possiamo specificare un prefisso in Ascend, in modo che riconosca quali file con convenzioni di denominazione simili vanno ingeriti per la pipeline.
Abbiamo anche incluso le righe di intestazione nei file CSV, quindi nel componente read di Ascend dobbiamo specificare l'opzione per escluderle.
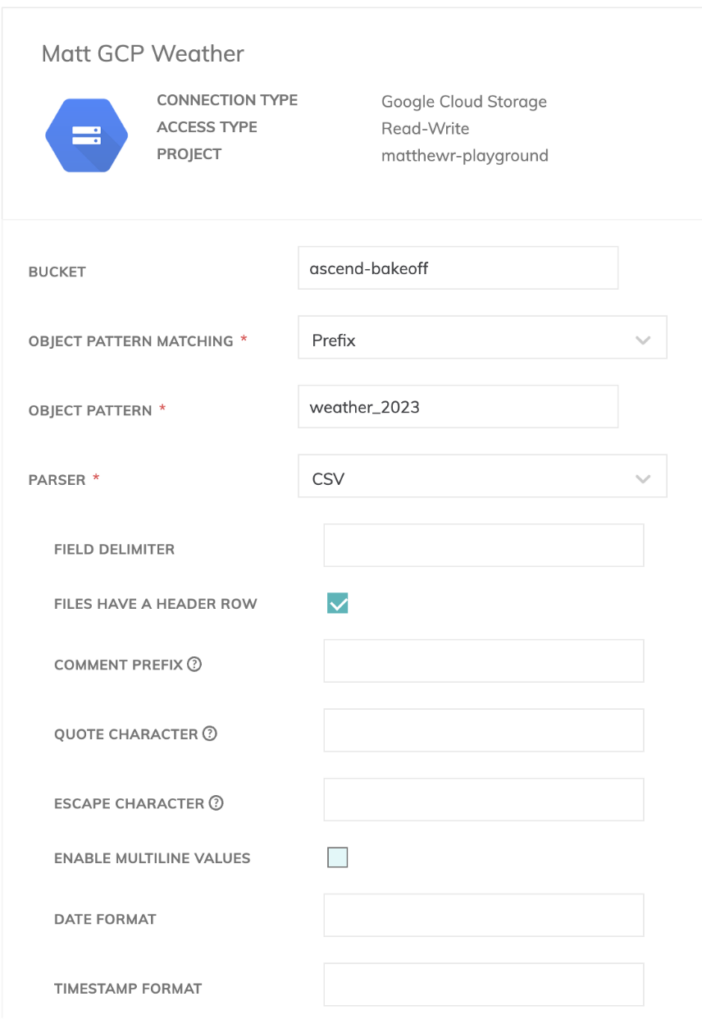
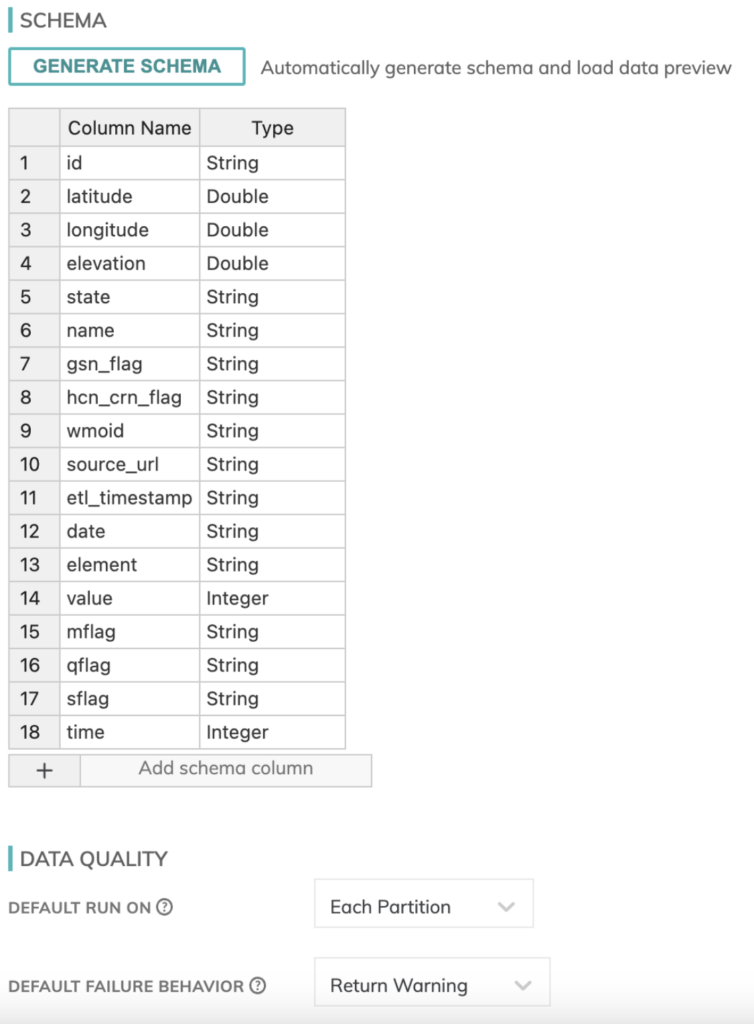
È inoltre necessario definire uno schema per i nostri dati meteorologici. Per fortuna, Ascend dispone di un rilevatore di schema integrato per i componenti read, quindi è stato piuttosto semplice metterlo insieme.
Qui potete anche definire controlli di data quality e parametri di comportamento in caso di errore, per gestire i job dall'inizio alla fine.
Un'altra funzione interessante offerta dalla piattaforma Ascend è il partizionamento del dataset specifico per pipeline. Segmenta i dati in blocchi significativi e li elabora in modo indipendente, accelerando il throughput delle data pipeline all'interno del data warehouse di scelta.

Come potete vedere da un sottoinsieme di 20 giorni dei nostri dati, le partizioni sono segmentate in una per ciascun giorno dei file meteorologici.
Anche la configurazione delle trasformazioni in Ascend è altrettanto semplice. Basta specificare il linguaggio scelto e scrivere il codice nella finestra principale del componente, come illustrato di seguito.
Una cosa da segnalare è che, in modo analogo al linguaggio macro di dbt, Ascend usa la logica Jinja per richiamare i nomi dei componenti dai passaggi precedenti della pipeline. Gli sviluppatori che hanno familiarità con questo stile si troveranno a proprio agio su entrambe le piattaforme.
Per non allungare troppo questa sezione, ho aggiunto qui un solo componente di trasformazione di base a scopo illustrativo. Tenete però presente che abbiamo aggiunto una guida di riferimento completa alle trasformazioni costruite per questa pipeline di esempio in un repository GitHub, linkato in fondo a questo post.
Infine, per i nostri componenti write o di "reverse-ETL", abbiamo dovuto nuovamente specificare una connessione al data warehouse BigQuery.
Le connessioni si configurano nell'area Admin di Ascend.io, come si vede qui. Sono fondamentali sia per i componenti read sia per quelli write, e Ascend.io supporta una vasta gamma di connessioni, tra cui data warehouse Snowflake o BigQuery e storage bucket di qualsiasi cloud.
Da qui in poi, i componenti write sono piuttosto semplici. Basta specificare una connessione, il layout dello schema di output e, per il data warehouse scelto, il nome della tabella di output ed eventuali altre opzioni specifiche del cloud (come il nome del dataset in BigQuery o lo schema in Snowflake).
Da notare che Ascend, di default, materializza i dati a ogni passaggio di trasformazione della pipeline nei data plane di Snowflake o BigQuery. Per questo non è necessario creare un connettore di output verso il data warehouse, ma resta comunque disponibile qualora si vogliano apportare modifiche finali allo schema che non comportino altra logica di trasformazione.
In termini di sforzo complessivo di sviluppo, nonostante quelli che possono sembrare numerosi passaggi nel mio processo e nella spiegazione, questa pipeline mi ha richiesto circa 10 minuti, includendo il tempo necessario per configurare le connessioni a GCS, BigQuery e Snowflake nei miei account playground Ascend.io per questa demo.
Vale la pena sottolineare che, ogni volta che venivano aggiunti nuovi file Weather secondo le regole d'ingaggio originali, questi venivano rilevati automaticamente dall'Ascend data service e la pipeline poteva ri-eseguirsi a piacere a fronte dei nuovi file/dati.
Il bello di Ascend per questo tipo di caso d'uso è che, una volta configurata, la pipeline richiede una manutenzione piuttosto contenuta per il resto del suo ciclo di vita. Non serve molto lavoro aggiuntivo né per modificare la logica né per aggiungere nuovi passaggi al processo. Quando questi cambiamenti avvengono, il controller di automazione li rileva e individua automaticamente quali sezioni della pipeline devono essere rieseguite e quali partizioni del dataset necessitano di un refresh. Cosa ancora più impressionante, ciò può avvenire su numerose pipeline interconnesse: la modifica a un singolo modello viene così orchestrata in automatico dal servizio, che avvia decine di job di elaborazione e DAG senza alcun intervento da parte mia. Un grande punto a favore del servizio Ascend!
Processo di sviluppo in dbt
Per il lato dbt di questo bake-off, ho usato il servizio dbt Cloud tramite il mio account gratuito. Mi è sembrata l'opzione più naturale, dato che dbt Cloud dispone di un'orchestrazione integrata e non richiede un servizio di terze parti come Airflow, garantendo così un confronto più equo con l'esperienza all-in-one di Ascend.
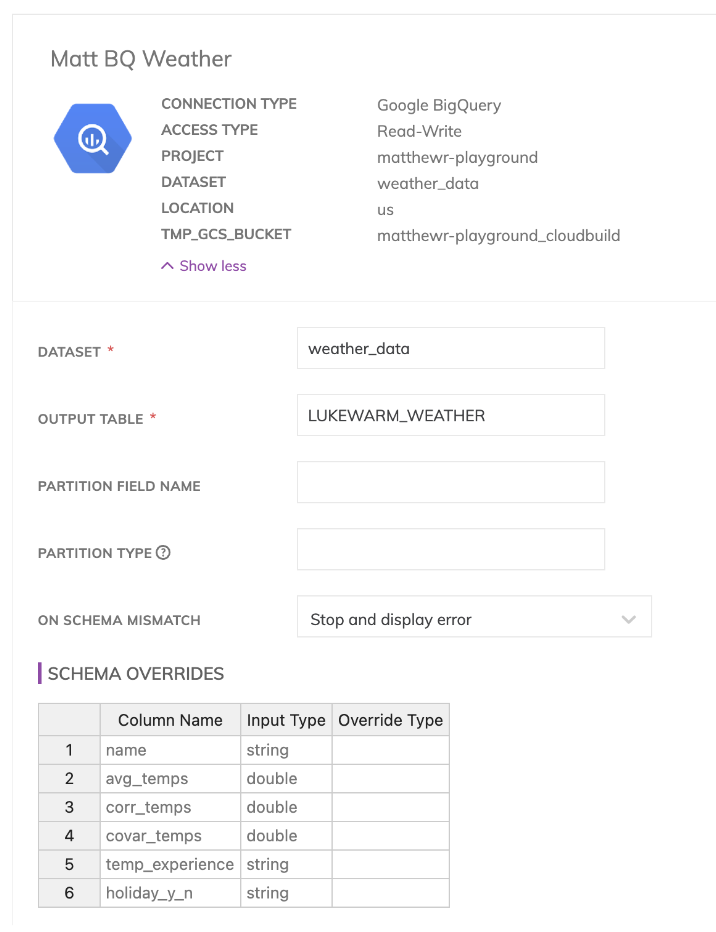
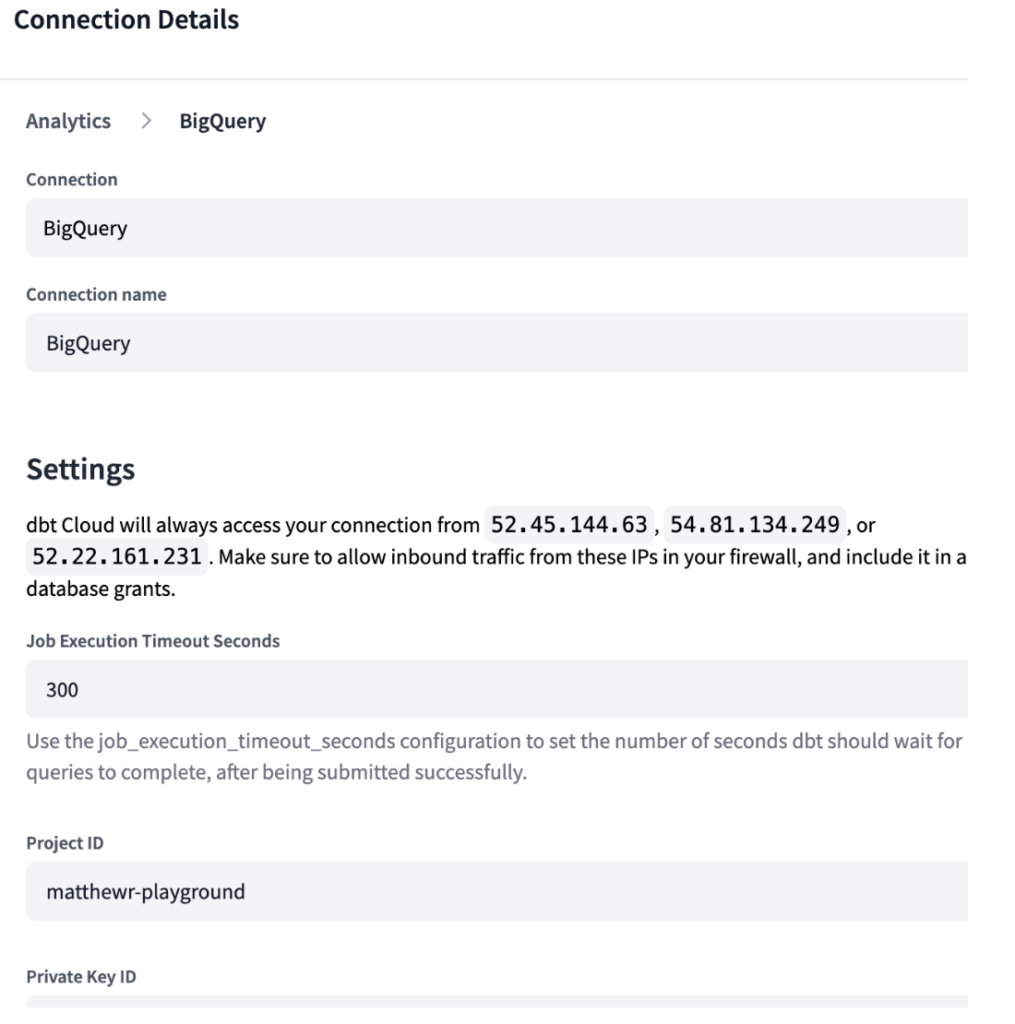
Come per Ascend, anche in dbt Cloud bisogna specificare l'ambiente di sviluppo. Dato che dbt è progettato per connettersi al data warehouse di scelta, abbiamo dovuto creare connessioni sia per i nostri ambienti BigQuery sia Snowflake, con le credenziali necessarie come mostrato di seguito.
dbt è composto da varie directory che costituiscono l'infrastruttura delle sue pipeline, tra cui Models (contenenti job SQL eseguiti nel DWH di scelta), Tests (contenenti test unitari sui modelli stessi), Macros (con logica riutilizzabile per i job) e Seeds, tra le altre.
Ai fini di questa pipeline, abbiamo replicato in dbt la stessa logica della pipeline Ascend sotto forma di vari file model .sql, per riprodurre il medesimo processo.
Di seguito una vista del DAG del processo dbt costruito per la logica del bake-off:

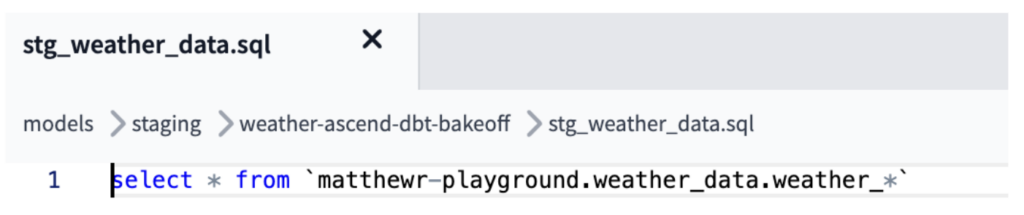
Per replicare l'ingestion e la combinazione dei file CSV ottenute con i read connector di Ascend, il modello "stg_weather_data" in dbt ha unito i molti file/tabelle sorgente utilizzando logica di external source nel caso di GCS o logica wildcard da BigQuery, così da combinare tutti i dati in un unico file come nel job equivalente in Ascend (mostrato di seguito).
Questo approccio ha permesso di gestire lo scenario di file aggiuntivi previsto dalle regole d'ingaggio, con la clausola wildcard progettata per intercettarli man mano che venivano caricati in BigQuery (oppure si può modificare la logica per intercettare nuovi file aggiunti in GCS).
Abbiamo poi creato vari modelli dbt in directory diverse per i livelli di data warehousing Staging/Mart, con la tabella mart finale utilizzata nel nostro esempio per generare la tabella equivalente nei data warehouse BigQuery o Snowflake. Questo ci permette di ottenere gli stessi risultati con la stessa identica sintassi SQL usata nelle esecuzioni in Ascend, per un vero confronto da bake-off.
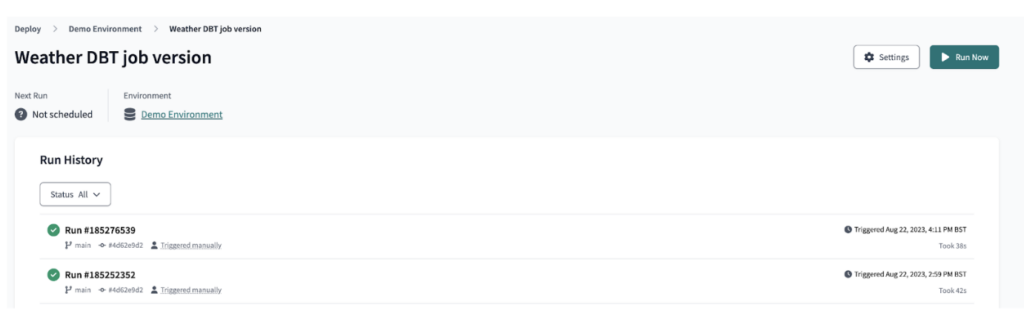
Con dbt Cloud abbiamo poi distribuito l'output dbt come job, utilizzato per orchestrare l'esecuzione della pipeline dbt come illustrato.
A causa della configurazione dell'orchestrazione del job dbt cloud, il tempo totale di sviluppo è risultato leggermente superiore rispetto alla costruzione della pipeline equivalente in Ascend. Inoltre, trattandosi di una soluzione code-based, dbt ha richiesto tempo aggiuntivo per configurare la parte standard di ingestion della pipeline (tramite file .yml) e l'output della tabella finale del livello di presentazione, già integrato nel write connector della pipeline Ascend.
Costruire la pipeline equivalente in dbt ha richiesto circa 20 minuti.
Va anche notato che, a differenza di Ascend, dbt non dispone di meccanismi automatici per suddividere i dati in partizioni durante l'ingestion. Manca inoltre della capacità di rilevare file aggiuntivi inseriti nel bucket sorgente e di avviare nuove ingestion incrementali in batch poco dopo il loro rilevamento (sia in GCS sia in BigQuery).
Potete applicare partizionamento e clustering BigQuery nei file .yml di dbt, ma ciò richiede configurazione aggiuntiva e non è equivalente alle partizioni di ingestion create automaticamente in Ascend.
Inoltre, sebbene la logica di gestione degli errori in dbt sia supportata tramite vari pacchetti come Great Expectations, anche questa è una funzionalità che dovete configurare installando i pacchetti relativi. Serve anche una conoscenza approfondita della sintassi di tali pacchetti per aggiungere questa logica ai job, anziché un semplice set di impostazioni a checkbox come quelle offerte in Ascend.
Il DoiT Bake-Off: i risultati
E ora il momento che tutti aspettavamo. Si va in forno!
I nostri test su entrambe le pipeline dall'inizio alla fine hanno fornito i seguenti risultati di performance:
Tempi di esecuzione
"Cold Start" - tempi medi della prima esecuzione delle pipeline complete
- Ascend: 2 minuti e 6 secondi
- dbt: 47 secondi
Dai tempi iniziali a grandi linee, possiamo osservare che la pipeline dbt Cloud è stata più veloce nell'esecuzione cold-start. Il dato è però probabilmente influenzato dall'infrastruttura sottostante delle pipeline Ascend, dove i cluster Kubernetes vengono avviati al volo per gestire l'esecuzione del job e messi in idle tra un job e l'altro per ridurre i costi di compute.
Abbiamo quindi effettuato un altro controllo dei tempi di esecuzione per un confronto a parità di condizioni in uno scenario hot-start, con i cluster Ascend già avviati.
"Hot Start" - tempo medio di esecuzione successivo delle pipeline complete
- Ascend: 10 secondi
- dbt: 32 secondi
Le esecuzioni successive delle pipeline hanno mostrato Ascend molto più veloce, a parità di volumi di dati e di codice di trasformazione. Il merito è probabilmente della natura dinamica e parallelizzata dei cluster Ascend, che consente di rendere multi-thread l'elaborazione dei singoli passaggi e di ridurla in modo significativo.
Confronto tra crediti Snowflake utilizzati e byte BigQuery
Crediti Snowflake per job
Per quanto riguarda i crediti consumati lungo le pipeline complete sia per Ascend sia per dbt, abbiamo segmentato ognuna in modo da utilizzare schemi diversi all'interno del nostro Snowflake Database per il bake-off. Nello specifico, la pipeline Ascend ha utilizzato le connessioni "sources_ascend" e "ascend_t_conn", mentre la pipeline dbt ha utilizzato gli schemi "dbt_mrichardson" e "public".
La pipeline Ascend è risultata sensibilmente più efficiente di quella dbt in termini di crediti Snowflake utilizzati. Il totale dei crediti consumati è stato:
- Consumo Pipeline Ascend = 61,165 + 28,071 = 89,236 crediti
- Consumo Pipeline dbt = 1924,652 + 33,685 = 1958,337 crediti

Questo ampio divario sul fronte Snowflake è probabilmente dovuto in parte alle capacità di partizionamento applicate da Ascend ai nostri dati meteorologici. Poiché ogni file è stato propagato in modo incrementale senza richiedere una riduzione completa in fase di ingestion, è servito molto meno compute per eseguire la pipeline e analogamente durante il suo sviluppo. Il divario può essere attribuito anche ad altre funzionalità di risparmio costi e gestione del compute della piattaforma Ascend, come lo spegnimento dei Snowflake Virtual Warehouse non appena la pipeline termina l'elaborazione, evitando di accumulare uptime non necessario.
Slot BigQuery utilizzati per job
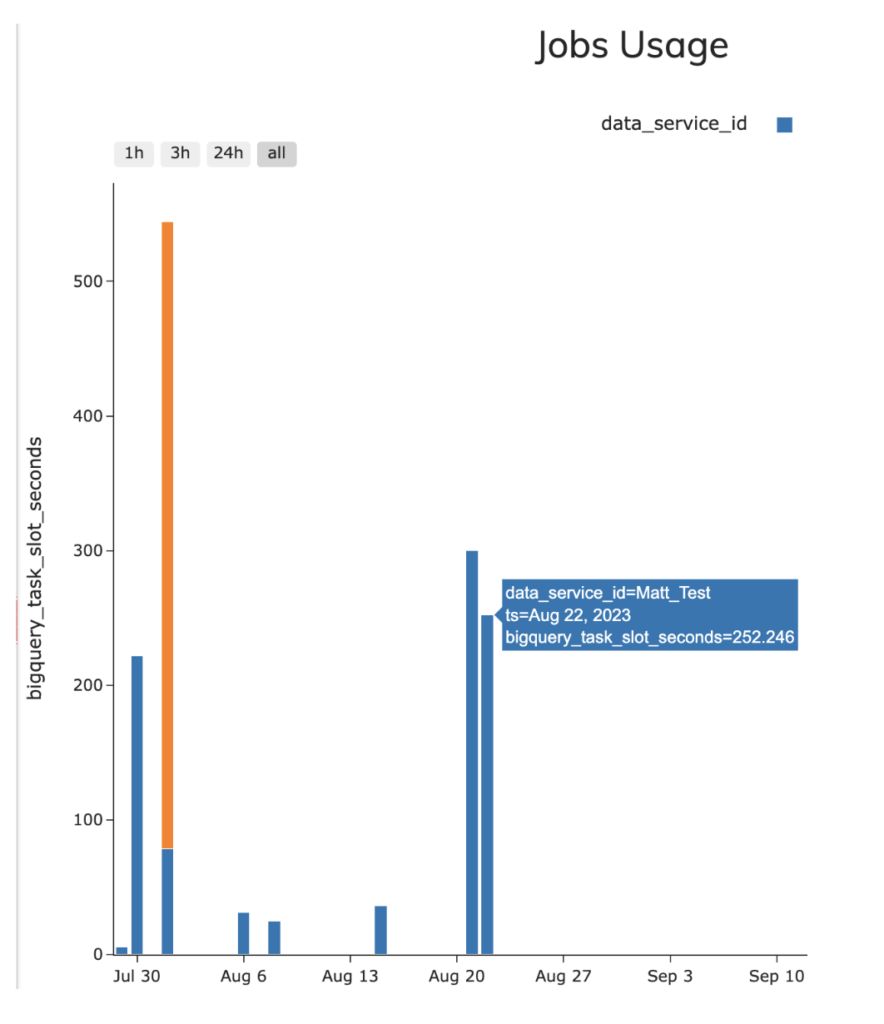
- Ascend - 4,18 slot medi al secondo (252,46 slot-secondi totali)
- dbt - 3,2 slot medi al secondo (189,34 slot-secondi totali)
Sul fronte BigQuery, abbiamo riscontrato che entrambe le pipeline hanno eseguito i job BigQuery in modo abbastanza efficace dal punto di vista degli slot, con dbt Cloud leggermente più efficiente in media durante l'esecuzione. Analizzando le ragioni di questa lieve differenza, è risultato che la causa è da ricercare nelle impostazioni di esecuzione del Data Service in Ascend rispetto al DAG di test costruito in dbt, in termini di parallelismo: nel primo caso più passaggi del mio pseudo processo ETL venivano eseguiti in parallelo, generando una maggiore contesa degli slot in Ascend rispetto a dbt nel mio esempio di base (a causa dell'allocazione dei thread nella mia configurazione dbt).
Per verificarlo, ho modificato l'esecuzione della pipeline dbt aggiungendo l'opzione –threads:4 per ampliarne il parallelismo, ottenendo una performance media di slot al secondo molto simile, intorno a 4,3 slot al secondo, dovuta alla contesa leggermente maggiore per le risorse di slot al momento della ri-esecuzione.
Per controllare queste statistiche ho usato la query di esempio information_schema dalla vista JOBS, applicandola a entrambe le pipeline (inclusa nel repository GitHub allegato); va però segnalato che nell'interfaccia di Ascend è disponibile la vista riportata di seguito, che misura l'utilizzo degli slot BQ e il consumo di crediti Snowflake per le pipeline eseguite con Ascend, come da screenshot.
Scenari di gestione degli errori
Abbiamo anche testato un paio di scenari di gestione degli errori sulle due pipeline, in particolare:
- Pipeline interrotte al 70% dei punti di caricamento e anche a metà delle trasformazioni, introducendo errori che simulavano normali bug nel codice o nei dati ingeriti. Abbiamo poi tentato di riavviare la pipeline da quel punto di fallimento per vedere cosa succedeva.
- Aggiunta di un nuovo file CSV malformato alle pipeline per cercare deliberatamente di metterle in difficoltà.
Testando direttamente questi scenari abbiamo riscontrato quanto segue.
Gestione degli errori in Ascend
- Sia lo scenario di fallimento al 70% dell'esecuzione di una pipeline sia quello dell'aggiunta di un nuovo file CSV malformato al bucket sono stati gestiti in modo elegante. Ascend mette a disposizione impostazioni avanzate per controllare il comportamento delle pipeline al verificarsi di tali errori. Anche il recovery da un fallimento in Ascend è stato molto più pulito: grazie alla materializzazione di ogni stage della pipeline, è stato possibile riprendere semplicemente dall'ultimo componente completato e ripartire proprio dal punto del fallimento. Si è così risparmiata una notevole quantità di ricalcolo che sarebbe stata necessaria se la pipeline avesse dovuto essere rieseguita per intero.
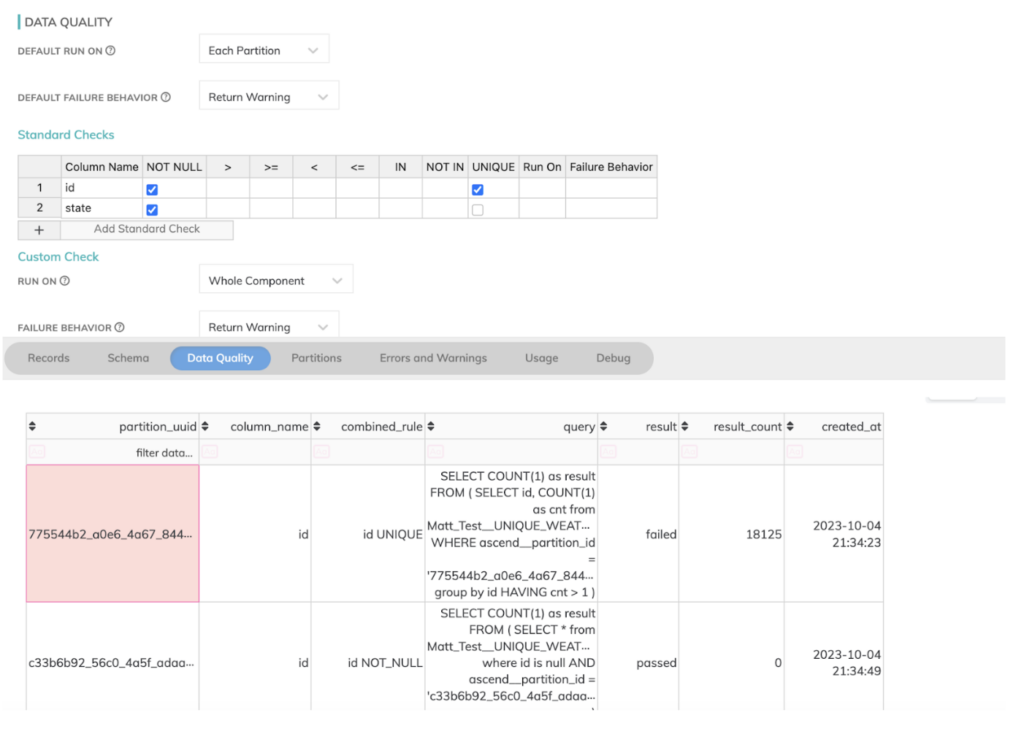
- In aggiunta, in modo analogo a dbt, anche Ascend.io fornisce controlli di data quality utili a rilevare problemi nei file CSV difettosi e a impedire che entrino nel sistema. È tutto integrato e richiede pochissima configurazione aggiuntiva per essere sfruttato, come mostrato di seguito dal tab data quality di Ascend, dove avevo inserito alcuni valori di campo errati nei file di dati sorgente.
Gestione degli errori in dbt
Gli scenari sopra menzionati non si sono adattati altrettanto bene a dbt. Era possibile memorizzare e mantenere gli errori in una tabella di gestione errori simile a quella della pipeline Ascend, ma queste capacità richiedevano il download di pacchetti dbt aggiuntivi (in particolare, va segnalato che il pacchetto dbt-expectations fornito da catalogia offre buone funzionalità sul fronte data quality). E sebbene siamo riusciti a implementare un processo di restart nella pipeline, ciò ha comportato o una ri-esecuzione manuale dei job, oppure una configurazione aggiuntiva per gli errori inserita in dbt Cloud nelle impostazioni di retry dei job stessi.
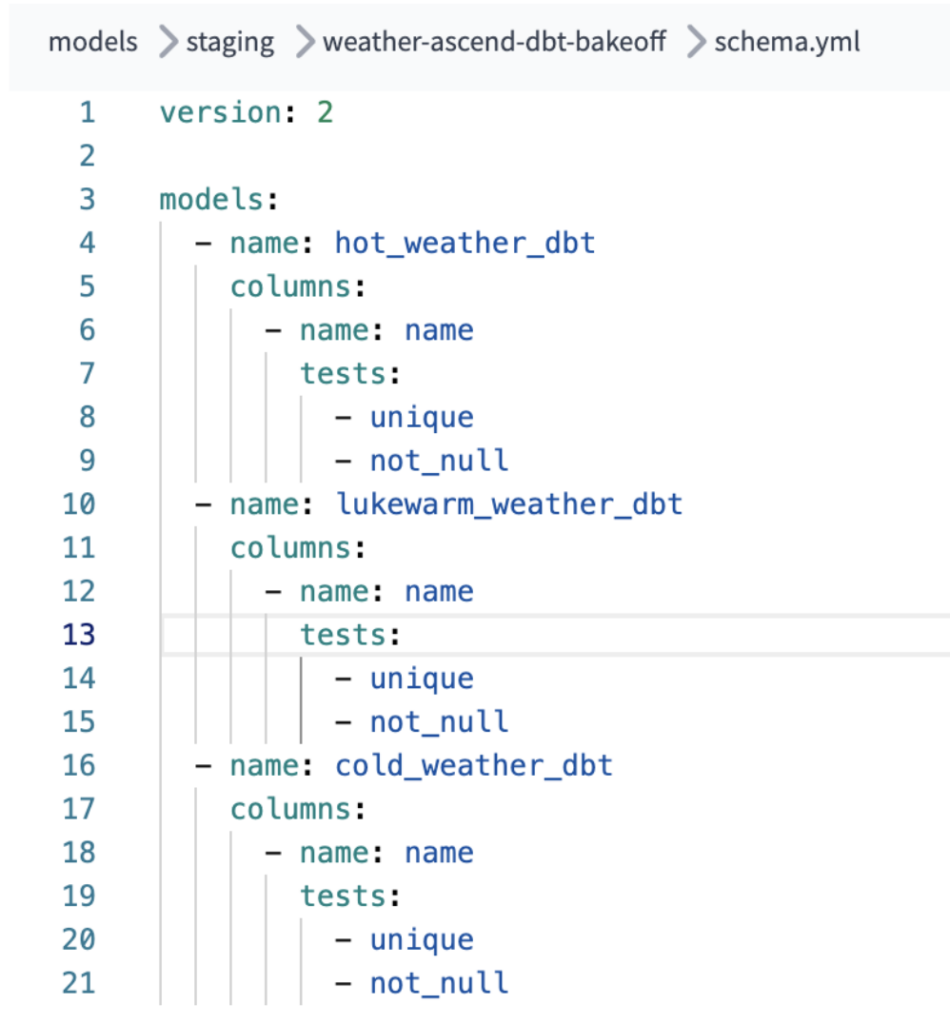
È stata inoltre necessaria una configurazione aggiuntiva per abilitare i test not-null e unique su ciascuno dei modelli dbt, in modo che la pipeline dbt potesse eseguire tali controlli. Non si tratta di uno sforzo eccessivo, ma può mettere in difficoltà sviluppatori meno esperti nella configurazione di progetti dbt Core / dbt Cloud.
Osservazioni finali
Dai nostri test sul case study dei dati meteorologici, sia in Ascend.io sia in dbt, emerge chiaramente che entrambi i servizi sono in grado di soddisfare le esigenze dei casi d'uso di data transformation. Tuttavia, dopo un'ampia sperimentazione delle funzionalità native di entrambi i servizi e delle estensioni di terze parti, possiamo anche dire che il toolset migliore per voi dipende da quale set si adatta meglio alle vostre esigenze.
Con Ascend.io avete uno strumento di cloud data pipeline tutto-in-uno che ottimizza e orchestra le data pipeline in modo automatico. Ha una UI più amichevole che rende la creazione delle pipeline semplice ed efficiente per sviluppatori di diversi livelli di esperienza. Include tecniche di miglioramento delle performance per far funzionare le pipeline senza intoppi, senza richiedere una conoscenza da esperti dell'infrastruttura dati né ore di codifica manuale.
Riteniamo che Ascend.io meriti senz'altro una prova per le vostre esigenze di cloud data pipeline, soprattutto laddove i processi di gestione dei dati possano beneficiare di minore manutenzione e di un numero più ridotto di strumenti di orchestrazione. La semplicità nella configurazione dei job e le impostazioni out-of-the-box per ridurre i costi di compute cloud rendono Ascend un'ottima alternativa a strumenti più orientati al codice come dbt, a seconda del vostro caso d'uso.
Per riferimento, le pipeline costruite in Ascend e dbt sono disponibili nel repository Github qui.