クラウドデータパイプラインの構築に使われる2つのデータ変換ツールを、真っ向から比較します。

データ変換ツールはどれを選ぶべきか?
DoiTのお客様が抱える課題のなかでも特に大きいのが、さまざまなソースから複数のターゲットへとデータを変換・処理することです。
多くのお客様は、SnowflakeやGoogle BigQueryといったデータウェアハウスサービスを利用してデータを保存・管理しており、データパイプラインのコードを自前で実行・保守することなく、いかに効率よくデータを扱うかを模索しています。
かつてリレーショナルデータベースや旧来型のデータウェアハウス基盤が主流だった時代、これはETLツールの領域でした。SSIS、Informatica、SAS Data Integration Studioなどを使い、ソースからターゲットへの抽出・変換、そして任意のデータウェアハウスへのロードを管理していたのです。
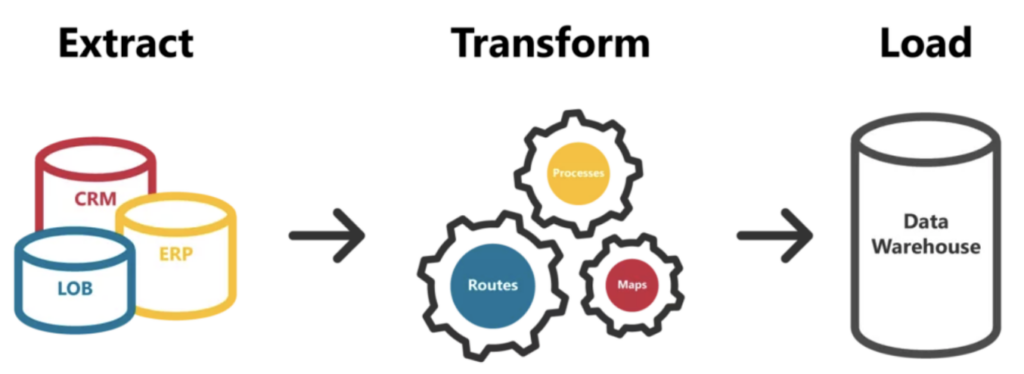
しかしSnowflake、BigQuery、Redshiftといったクラウドデータウェアハウスの登場により、業界は様変わりしました。これら次世代プラットフォームは、その構造と効率性からELT型の方が相性がよく、データウェアハウス側にプッシュダウンされる変換workloadsを十分にこなせます。その結果、先ほど挙げたツール群は不要となり、各クラウドプロバイダーは自社がネイティブにサポートするクラウドデータウェアハウスへのデータロード、すなわちELTの「EL」部分について、それぞれ効果的なソリューションを提供しています。
そこで登場するのが変換ツールです。
近年、多くのお客様が、データソースからの抽出を担うデータコネクタツールと、データウェアハウス内で重い計算処理を担う変換ツールを採用するようになりました。この取り込みと変換のステップを組み合わせたものが、今日多くの人が クラウドデータパイプライン と呼ぶものです。
こうした流れを受けて、抽出側を担うFivetranや、変換側を担うdbtといったツールの利用が大きく拡大しました。しかし、データパイプラインの取り込み側を処理し、必要な重量級の変換を実行し、Apache AirflowのDAGなど追加ツールを持ち込むことなくこれらを効果的にオーケストレーションできる代替ツールセットがあったとしたら、どうでしょうか。
Ascend.ioとは
![]()
Ascend.ioは、世界で最もインテリジェントなデータパイプラインの構築を掲げる、データパイプライン自動化分野の主要プレイヤーです。
Ascendは、エコシステム全体の変更を検知して伝播させ、データの正確性を担保し、データプロダクトのコストを定量化する単一プラットフォームです。これにより、取り込みパイプラインの管理・構築、複雑な変換処理、そしてそれらを包括的なビジネスパイプラインの一部としてオーケストレーションするまでを、一箇所で完結できます。
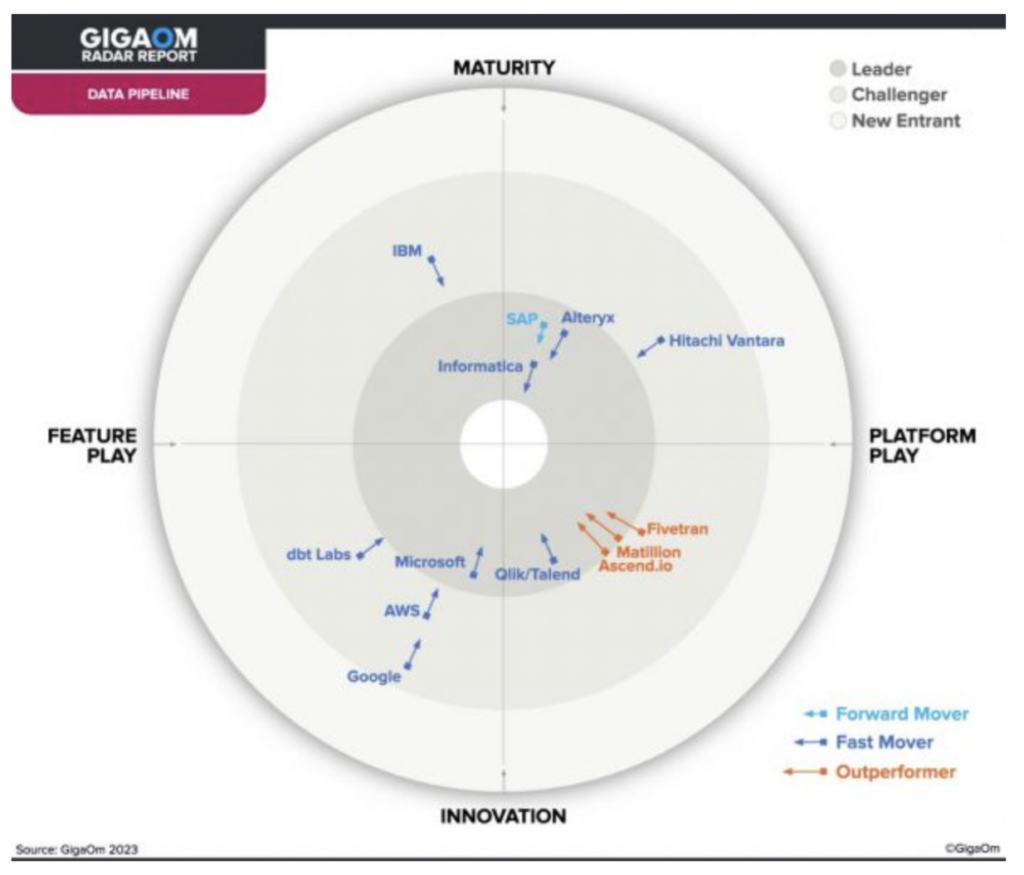
直近のGigaOmレポートでは、Ascendはデータパイプライン領域でわずか3社しかいない「アウトパフォーマー」の1社に挙げられており、モダンなデータパイプラインに最適な選択肢と言えます。
Ascend.ioはソース側の変更を検知すると、選択したデータウェアハウスを介してデータパイプライン全体に自動で伝播させ、チームによるジョブの手動スケジューリングや実行の手間を取り除きます。
さらに、Ascendのデータフロー内でのパーティショニングなど、テーブル/ビュー単位の最適化を通じて主要データウェアハウスとの業界最高水準の統合を実現し、Ascend上のパイプライン全体でデータの扱いを最適化します。
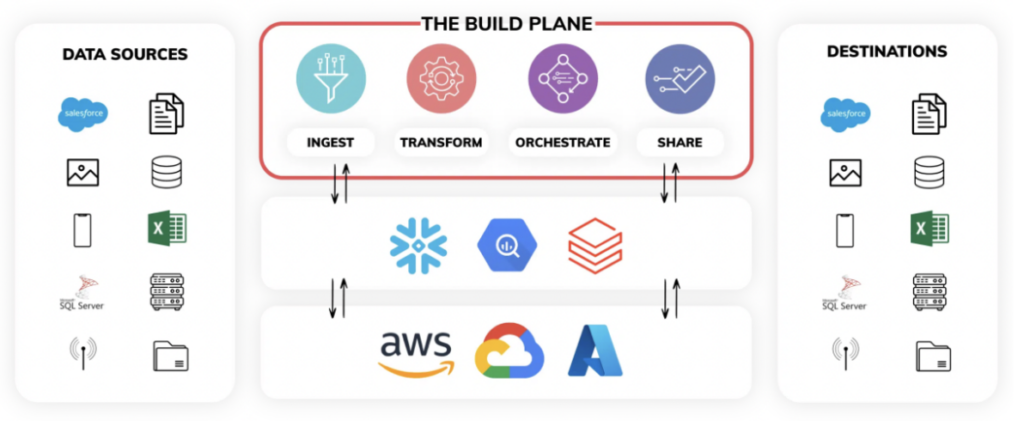
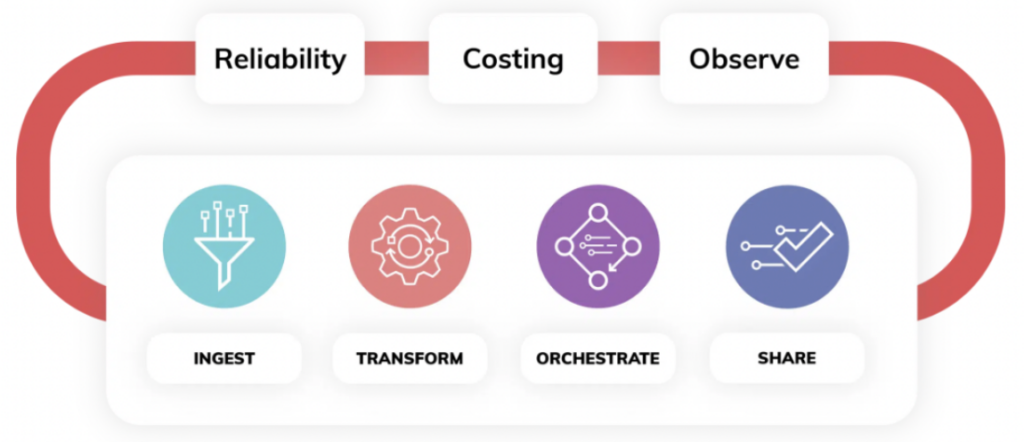
Ascendのデータパイプラインサービスを最大限に活用すると、3つの主要なプレーンで構成されることがわかります。
- Build Plane:パイプラインの取り込みおよび変換ロジックをすべて1画面でプログラミングできる「シングルペインオブグラス」と捉えてください。SDKやCLIを使い、バックエンドコードからAscend内のパイプラインを構築することも可能です。UIではデータリネージを可視化し、運用状況をリアルタイムで監視できます。
 2. Control Plane - Ascendプラットフォームの中核には、独自のフィンガープリンティング技術を活用した高度なコントロールプレーンがあります。この完全自律型のエンジンは、複雑きわまりないデータパイプラインの広大なネットワークにわたって、データとコードの変更を常時検知し、リアルタイムで対応します。データパイプラインは、追加のオーケストレーションコードなしで同期が保たれ続けます。
2. Control Plane - Ascendプラットフォームの中核には、独自のフィンガープリンティング技術を活用した高度なコントロールプレーンがあります。この完全自律型のエンジンは、複雑きわまりないデータパイプラインの広大なネットワークにわたって、データとコードの変更を常時検知し、リアルタイムで対応します。データパイプラインは、追加のオーケストレーションコードなしで同期が保たれ続けます。
- Ops Plane - Ascendのオペレーションプレーンは、インテリジェントなデータパイプラインをビジネスに溶け込ませる役割を担います。データオペレーションの3本柱、すなわち「ビジネスの信頼性向上」「データ処理コストの定量化」「透明性の確保」に対応します。リンクされたパイプラインのネットワーク全体でデータが取り込まれ処理される様子を、workloadsのシーケンス単位でリアルタイムに監視します。
Ascendは現在、Google BigQuery、Snowflake、Databricksの各データクラウドに対応しており、近い将来さらに対応サービスが拡大する予定です。
強力な自動化エンジンを備え、UIベース・コードベースのいずれの開発にも対応できる点を踏まえると、クラウドデータパイプラインのworkloadsで真剣に検討すべきサービスのひとつであることは間違いありません。本記事では、その活用方法を詳しく掘り下げていきます。
dbtとは
![]()
dbtはSQLベースの変換パイプラインツールで、モジュール化、ポータビリティ、CI/CD、ドキュメント化といったソフトウェアエンジニアリングのベストプラクティスにのっとり、チームでスピーディかつ協調的に分析コードをデプロイできます。リポジトリを介して開発タスクを共同で進められ、近年市場で非常に人気を集めているツールです。
dbtには2つの形態があります。
- dbt Cloudサービス:UIベースのdbtで、dbtモデルのデプロイと実行も直接処理します。個人利用向けの無料プランがあり、開発チーム向けには複数の価格帯が用意されています。
- dbt Core:dbtのコードベース版で、無料で利用でき、Visual Studio Codeなど多くのIDEで扱えます。dbt Cloudと同様、お好みのリポジトリと連携でき、Apache Airflowなどのツールと組み合わせてデータパイプラインをオーケストレーションすることもできます。
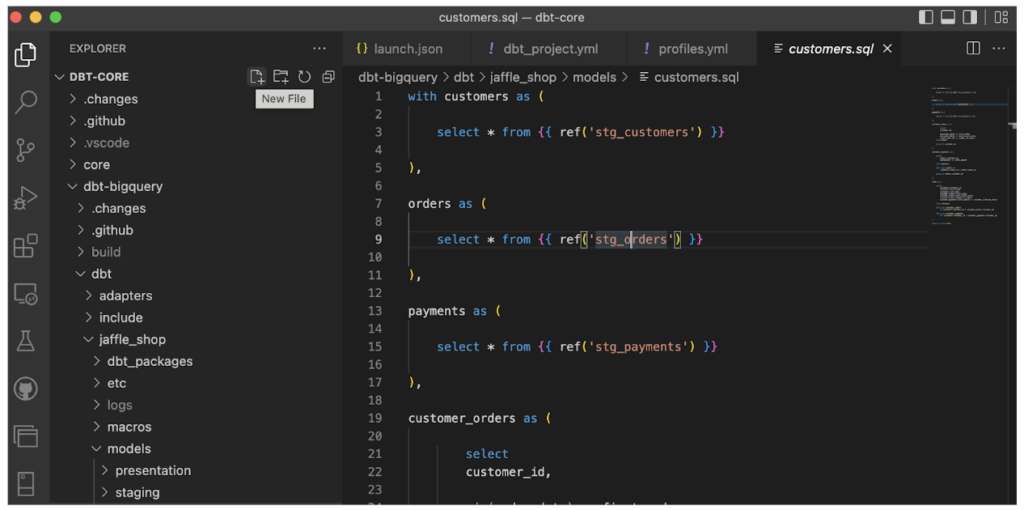
dbtは各種変換ジョブの開発・デプロイを取りまとめるだけでなく、データのユニットテストを実行でき、カタログ機能によりデータリネージも提供するため、ELTパイプラインのエンドツーエンドのフローのドキュメント化が格段に容易になります。
Snowflake、BigQuery、Redshift、Databricks、Starburstをはじめとする多様なデータウェアハウスやデータレイクと連携できるため、これらを併用する大規模エンタープライズに人気の選択肢となっています。
DoiT Bake-Off:評価方法
Ascendとdbtはいずれもデータ変換に有効なツールであり、それぞれ対照的な強みを持っているのは明らかです。では、よくあるデータパイプラインのユースケースには、どちらがより適しているのでしょうか。両サービスの対決にあたり、以下のステップを踏みました。
**シナリオ:**8月の日次気象データを数百万件、Google Cloud Storageから一括で取り込んで変換し、SnowflakeとGoogle BigQueryのそれぞれで、Ascend.ioとdbt Cloudの両方のデータパイプラインを通します。
擬似パイプラインは、以下の標準的なステップで構成します。
- 選択したデータウェアハウスから生の日次気象データを読み取り、複数日分の抽出データを1つのテーブルに統合してさらなる分析に備える。
- このデータを「暑い」「ぬるい」「寒い」のカテゴリに分類するため、統合データセットに対して基本的な変換を行う。
- 分割したデータセットに対して、より高度な集計および統計的な変換を実行する。さらに、変換済みデータを、気象エリアの地点コードを含むロケーションのルックアップテーブルに結合する。
- 最終的なデータセットを、選択したデータウェアハウスの擬似データマート/プレゼンテーション層に出力する。
まずは、Ascend.ioとdbtそれぞれで、開発者視点でこうしたプロセスを構築するのにかかる時間を比較したいと考えました。チームのパフォーマンスを左右する重要な変数のひとつが、データソリューションの構築にかかる時間だからです。
ジョブを構築できたら、対決の評価および各ソリューションの総保有コストを判断するために、次の観点をテストします。
- パイプライン全体の最初から最後までの実行時間(Ascend側はSpark基盤の特性上、ホットスタートとコールドスタートの両方を計測)
- 各データパイプラインで使用したcredits(Snowflake)とスキャンバイト数(BigQuery)
- エラーハンドリング:両パイプラインに障害を発生させ、それぞれのリカバリ手段を検証
- 新しい気象データファイルをパイプラインに追加し、データセットを更新するための再実行を行うことで、新規データ取り込み時の各パイプラインのパフォーマンスを検証
- 基盤となるデータウェアハウスへのアクセスや制御の度合い:SnowflakeのVirtual Warehouseの停止、Ascendジョブ内の自動パーティショニングなど、よくあるパイプラインオーケストレーション業務
対決のルールが固まったところで、シナリオを実装し、両ソリューションで気象データがどのように加工されるかを見ていきましょう。
DoiT Bake-Off:環境を整える
ここからは、Ascendとdbtそれぞれの開発プロセスを順に追っていきます。
本ケーススタディでは、Googleの公開ghcn_dデータセットから気象データを収集しました。
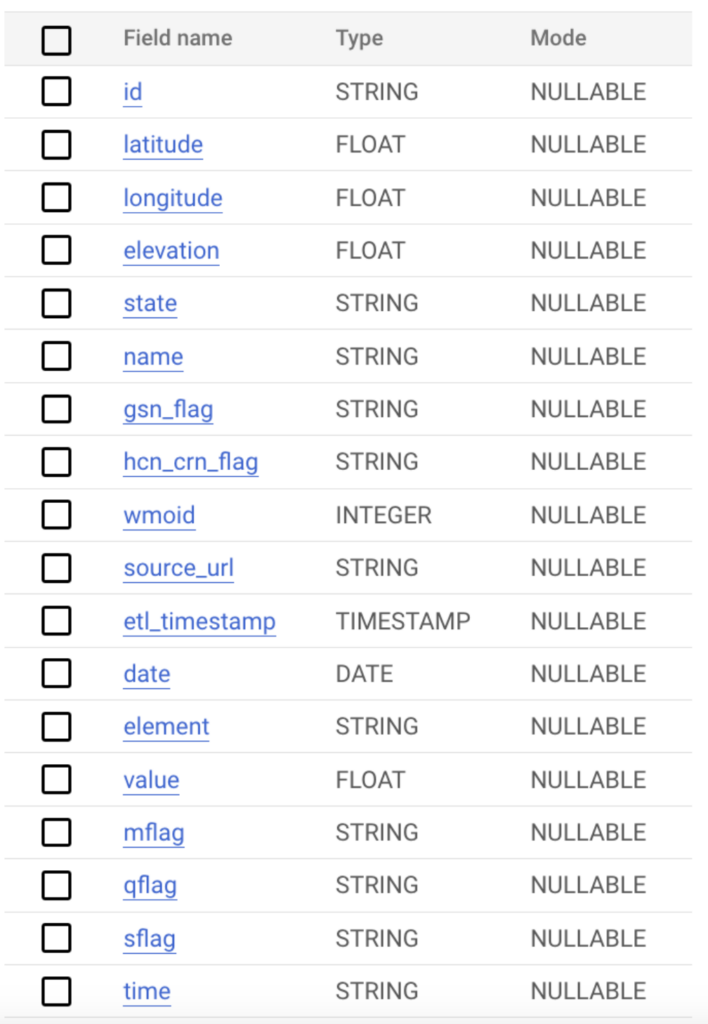
データ量を確保するため、このデータから全フィールドを取得し、以下のクエリのとおり2023年8月1日から8月31日までの日次ファイルを作成しました。
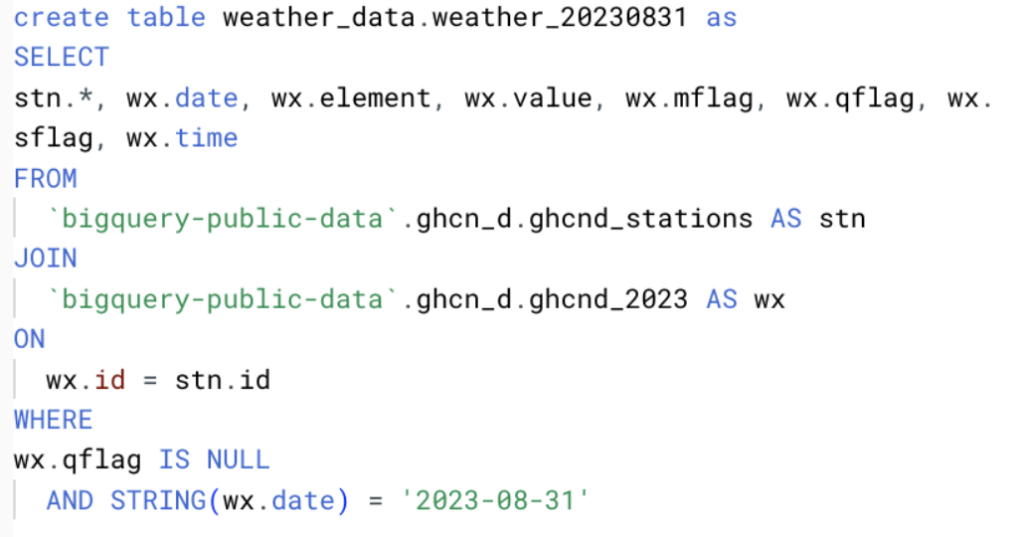
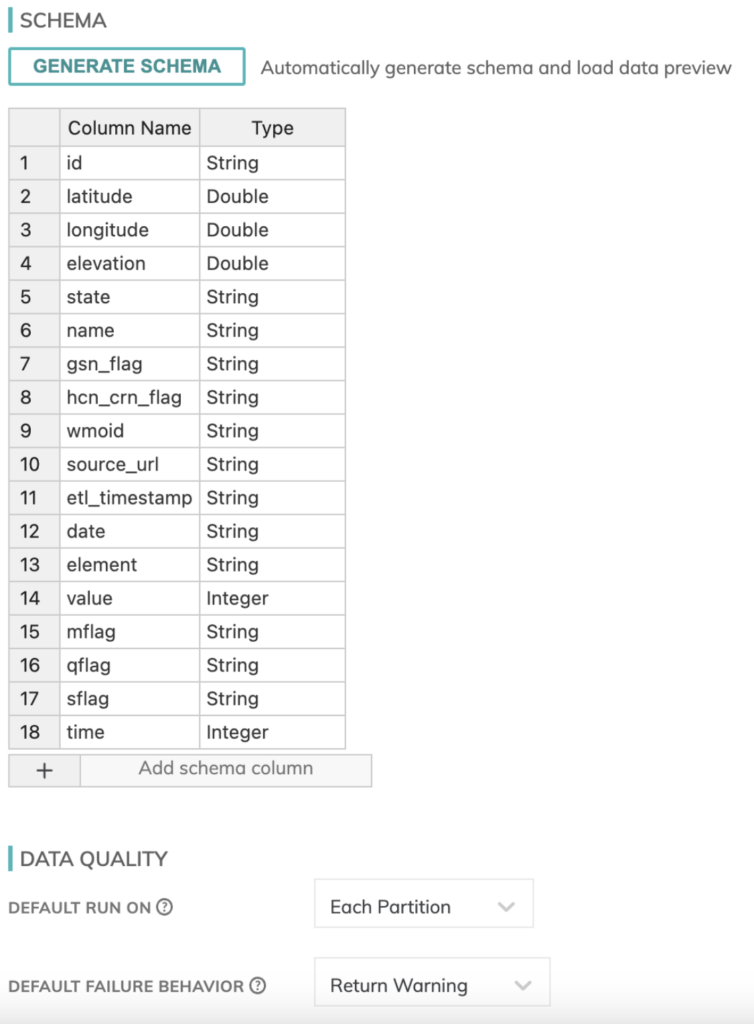
今回のデータは下記のスキーマを持ち、合計で数百万件のレコードがあります。複数シナリオを検証できるよう、このデータをBigQueryのテーブルとGoogle Cloud Storageの双方に保存し、プラットフォームをまたいで多様な取り込み方法を試せるようにしました。
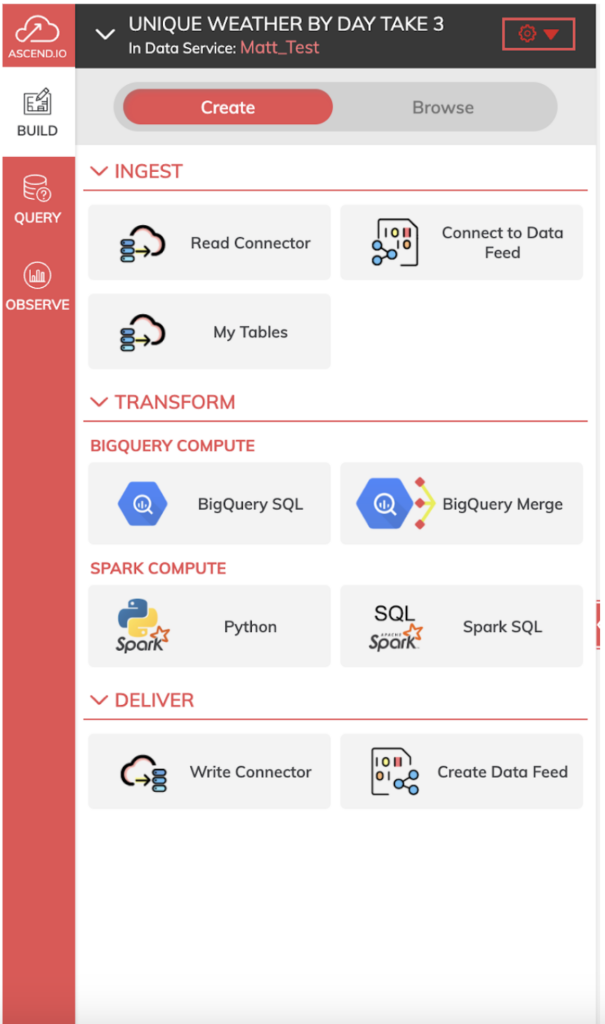
Ascendでの開発プロセス
Ascend.ioでは、Dataflowを作成することでデータパイプラインを組み立てます。DataflowはData Serviceの中に格納され、複数のデータパイプラインに対する共通のセキュリティモデルを提供します。下のplayground環境からも、その様子が確認できます。
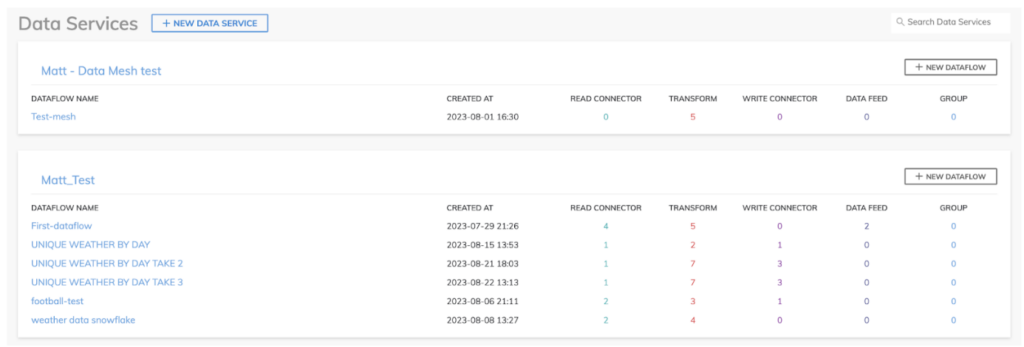
AscendのDataflowでは、パイプラインの各ステップで使える、取り込み/読み取り、変換、配信/書き込み用のさまざまなコンポーネントが用意されています。
今回のパイプラインでは、まずReadコンポーネントを使って、GCSまたはBigQueryから直接、気象データの初期ファイルを取り込みます。
続いてTransformコンポーネントで、プロセスに合わせてデータを整形します。今回の対決では、私が最も慣れているSQLとしてBigQuery SQLを使用しましたが、Ascendの変換処理ではPython、Spark SQL、SnowSQL(有効化時)など複数の言語から選択できます。
最後にWriteコンポーネントで、変換が完了したパイプラインの出力を、選択したデータウェアハウスに書き戻します。
下の図が、今回の対決のために構築したパイプラインです。最終分析に向けて、暑さ/寒さの度合いに応じた3本のデータルートで構成しています。
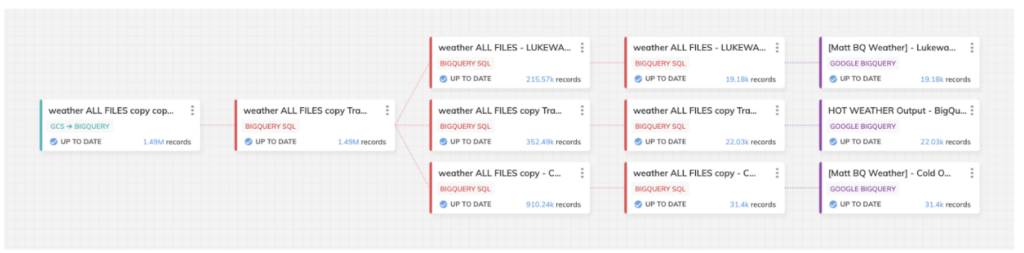
パイプラインの設計はBigQuery版もSnowflake版も同じですが、スクリーンショットはBigQuery向けに作成したテンプレートのものです。
Readコネクタについては、まずGCS(Google Cloud Storage)バケット内のファイルへの接続を設定する必要がありました。そのため、対象バケットへのアクセス権を持つサービスアカウントを使用します。
気象ファイルは複数あるので、Ascend側でプレフィックスを指定すれば、同じ命名規則のファイルをまとめてパイプラインに取り込むよう指示できます。
また、CSVファイルにヘッダー行が含まれているため、AscendのReadコンポーネントでヘッダーを除外するオプションを指定する必要があります。
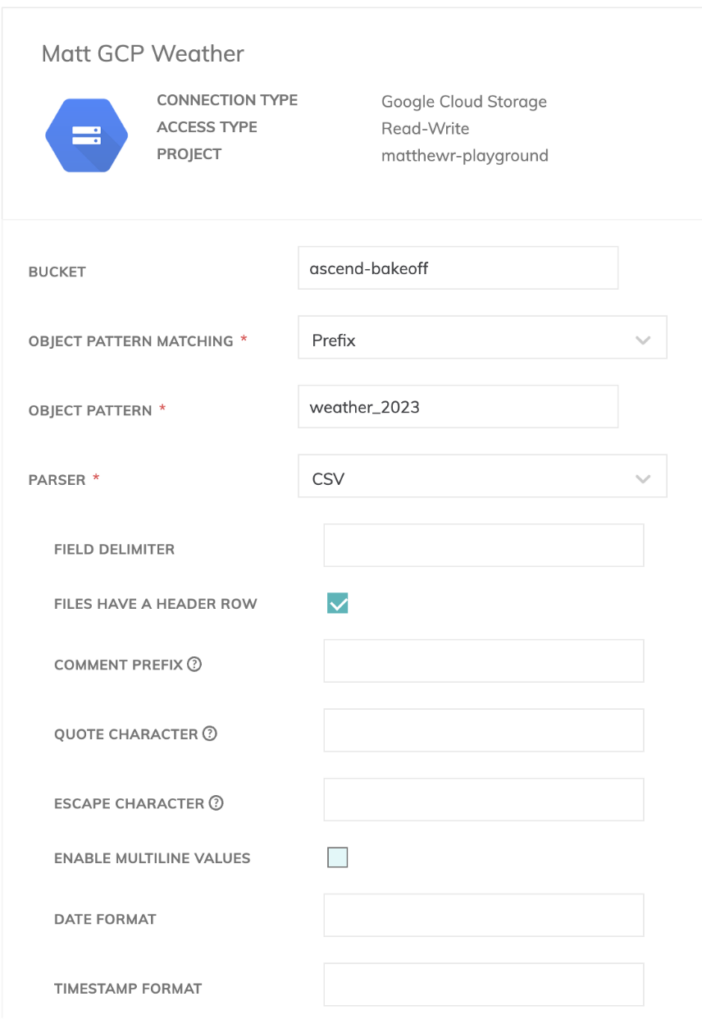
気象データのスキーマも定義する必要があります。幸いAscendのReadコンポーネントにはスキーマ自動検出機能が組み込まれているため、比較的簡単に整えられました。
同じ画面で、ジョブを最初から最後まで管理するためのデータ品質チェックや、障害発生時の挙動も定義できます。
Ascendプラットフォームのもう1つの興味深い機能が、パイプライン単位のデータセットパーティショニングです。データを意味のあるチャンクに分割して独立に処理することで、選択したデータウェアハウス内でのパイプラインのスループットを高めます。

20日分のデータのサブセットからわかるとおり、パーティションは気象ファイルの日付ごとに1つずつ作成されています。
変換処理の設定もAscendではシンプルです。使いたい言語を指定し、コンポーネントのメインウィンドウにコードを書くだけ(下図参照)です。
注目したいのは、dbtのマクロ言語と同様に、AscendもJinjaの記法を使って、パイプラインの前段ステップのコンポーネント名を参照する点です。この書き方に慣れている開発者であれば、どちらのプラットフォームでもすぐに馴染めるでしょう。
本セクションが冗長になりすぎないよう、ここでは説明用に基本的な変換コンポーネントを1つだけ示しています。なお、本サンプルパイプラインで構築した全変換のリファレンスガイドは、本記事末尾にリンクしたGitHubリポジトリにまとめてあります。
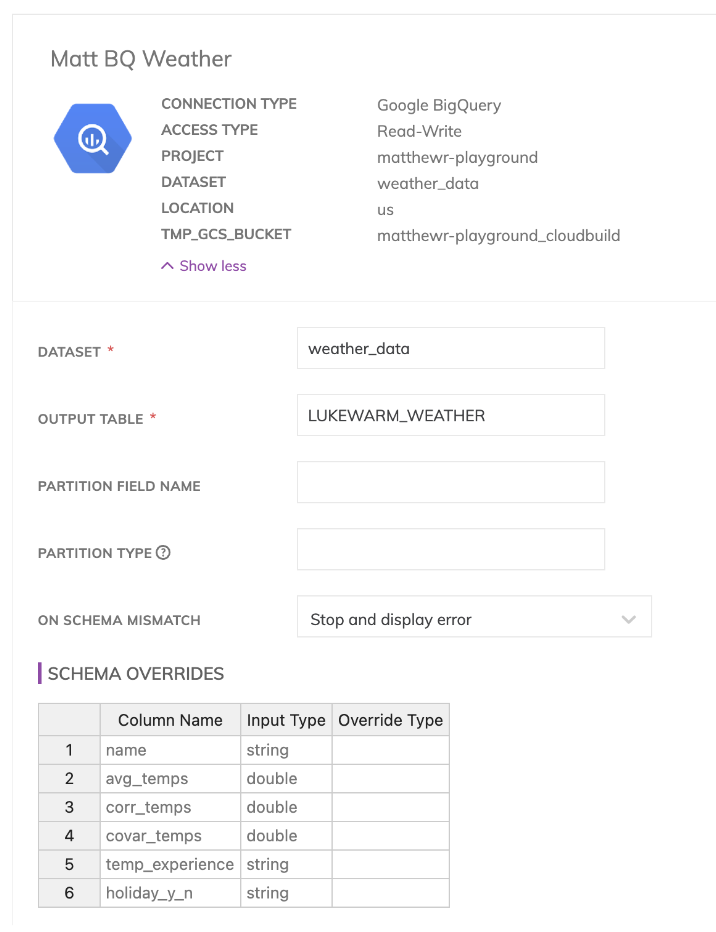
最後にWriteコンポーネント(いわゆる「リバースETL」コンポーネント)では、改めてBigQueryデータウェアハウスへの接続を指定する必要がありました。
接続情報はAscend.ioのAdminエリアで設定できます(下図参照)。これはRead/Write双方のコンポーネントに不可欠なもので、Ascend.ioはSnowflakeやBigQueryのデータウェアハウス、各種クラウドのストレージバケットなど、多様な接続先に対応しています。
接続さえ済ませてしまえば、Writeコンポーネントの設定はかなり単純です。接続、出力スキーマのレイアウト、出力先データウェアハウスのテーブル名、そしてクラウド固有の追加オプション(BigQueryならデータセット名、Snowflakeならスキーマ名など)を指定するだけです。
注意点として、Ascendは既定では、SnowflakeやBigQueryのデータプレーン上で、パイプラインの各変換ステップごとにデータをマテリアライズして動作します。そのため、データウェアハウスへ書き戻すための出力コネクタを必ずしも作る必要はありませんが、他の変換ロジックを伴わないスキーマの最終調整を行いたい場合には利用できます。
全体の開発工数としては、ここまでの説明では多くのステップを踏んでいるように見えるかもしれませんが、このパイプラインの構築は全体で約10分でした。今回のデモ用にAscend.ioのplaygroundアカウントでGCS、BigQuery、Snowflakeへの接続を設定する時間も含めての値です。
付け加えると、当初の対決ルールどおり新しい気象ファイルを追加した際にも、Ascendのデータサービスがそれらを自動で検知し、新規ファイル/データの追加に応じて必要なときにパイプラインを再実行できました。
このようなユースケースでAscendが優れているのは、いったんパイプラインを構築すれば、その後のライフサイクルを通じて保守の手間がかなり少なくて済む点です。ロジックの変更や新しいステップの追加にも、それほど多くの追加作業は要りません。変更があると、自動化コントローラーがそれを検知し、パイプラインのどの部分を再実行すべきか、データセットのどのパーティションをリフレッシュすべきかを自動的に判断します。さらに印象的なのは、これが相互につながった複数のパイプラインをまたいで起こり得ることです。つまり、モデルを1つ変更しただけで、サービス側が自動でオーケストレーションを行い、何十もの処理ジョブやDAGを私の手を介さずに起動してくれます。これはAscendの大きな強みです。
dbtでの開発プロセス
対決のdbt側では、無料アカウントでdbt Cloudを利用しました。dbt CloudはAirflowのようなサードパーティ製のオーケストレーターを必要とせず、独自のオーケストレーション機能を内蔵しているため、Ascendのオールインワン体験とより公平に比較できる、自然な選択肢に思えたからです。
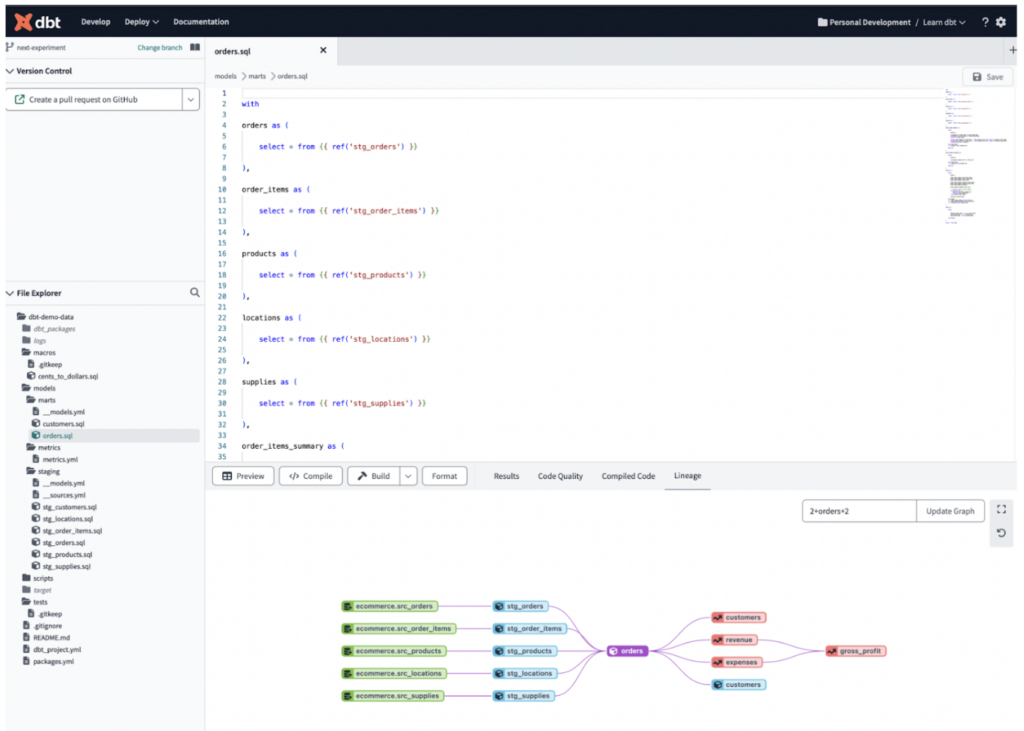
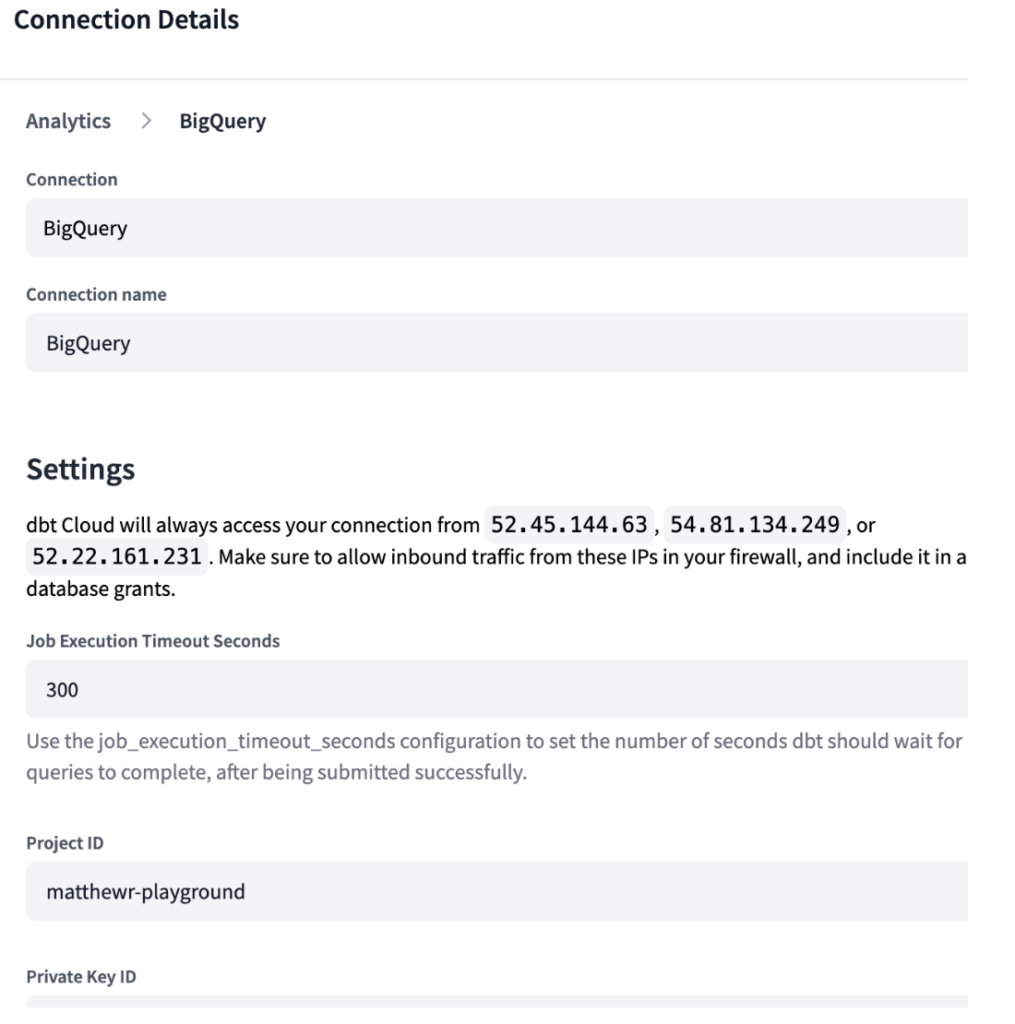
Ascendと同様、dbt Cloudでも開発環境を指定する必要があります。dbtは選択したデータウェアハウスに接続して動作する設計のため、BigQueryとSnowflake両方の環境について接続を作成し、下図のとおり認証情報を登録しました。
dbt自体には、パイプラインの基盤を構成するさまざまなディレクトリがあります。Models(選択したDWH上で実行されるSQLジョブ)、Tests(モデルに対するユニットテスト)、Macros(ジョブで再利用するロジック)、Seedsなどです。
今回のパイプラインでは、Ascendパイプラインとまったく同じロジックを、複数の.sqlモデルファイルとしてdbtに移植し、同じプロセスを再現しました。
下図は、対決ロジック用に構築したdbtプロセスのDAGビューです。

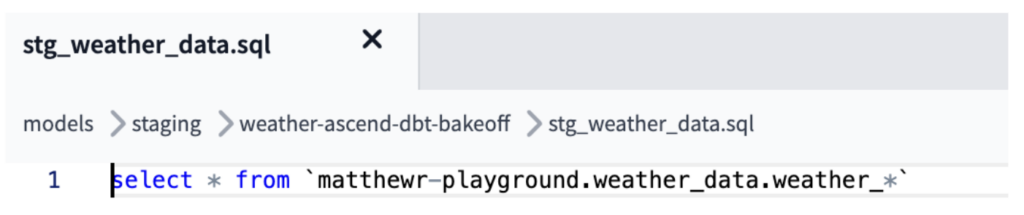
このケースでは、AscendのReadコネクタで取得していたCSVファイルの取り込みと結合を再現するため、dbtの「stg_weather_data」モデルでGCSの場合は外部ソースのロジックを使用し、BigQueryの場合はワイルドカードを使って多数のソースファイル/テーブルを結合し、Ascend側と同様にすべてのデータを1つにまとめました(下図参照)。
これにより、対決ルールに含めた「ファイル追加」シナリオにも対応でき、ワイルドカード句によりBigQueryに新しいファイルがロードされた際にもそれらを取り込めます(GCS側に追加された新ファイルを拾うようにロジックを変更することも可能です)。
続いてStaging/Martデータウェアハウス層用に、ディレクトリを分けて複数のdbtモデルを作成しました。最終のmartテーブルは、BigQueryまたはSnowflakeデータウェアハウスに同等のテーブルを出力するために使用しています。これにより、Ascendでの実行とまったく同じSQL構文で同じ結果を得られ、対決として正味の比較ができます。
その後、dbt Cloudでdbtの出力をジョブとしてデプロイし、図のようにdbtパイプラインの実行をオーケストレーションしました。
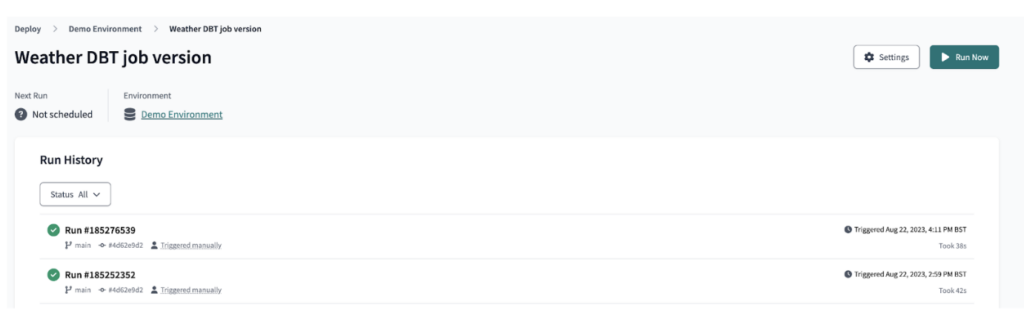
dbt Cloudのジョブのオーケストレーション設定を行った結果、開発時間の合計は同等のAscendパイプラインの構築よりもやや長くなりました。さらにdbtはコードベースのソリューションのため、パイプラインの取り込み側の標準設定(.ymlファイルでの構成)や、Ascendパイプラインではwriteコネクタに組み込まれていた最終プレゼンテーション層テーブルの出力にも、追加の時間が必要でした。
同等のパイプラインの構築には、dbtで20分ほどかかりました。
もう1点付け加えると、dbtにはAscendのように、取り込み時にデータをパーティションに自動分割する仕組みはありません。また、ソースバケット(GCS/BigQueryいずれの場合も)に追加されたファイルを検知し、その直後に新しい増分バッチの取り込みを開始する機能もありません。
dbtの.ymlファイルでBigQueryのパーティショニングやクラスタリングを適用することはできますが、追加の設定が必要であり、Ascendが自動生成する取り込みパーティションと同等のものではありません。
加えて、dbtのエラーハンドリングのロジックはGreat Expectationsなど各種パッケージで補えますが、これも該当パッケージをインストールして設定する必要があります。Ascendのチェックボックスをいくつか設定するだけで済む手軽さとは異なり、ジョブにこのロジックを組み込むには、これらのパッケージのマクロ構文に関する知識も求められます。
DoiT Bake-Off:結果発表
さて、お待ちかねの瞬間です。いざ、対決開始!
両パイプラインを最初から最後までテストした結果、以下のパフォーマンスが得られました。
実行時間
「コールドスタート」 - パイプライン全体の初回実行時間(平均)
- Ascend:2分6秒
- dbt:47秒
初回の実行時間を見ると、コールドスタートではdbt Cloudパイプラインの方が高速でした。ただしこれは、Ascendパイプラインの基盤インフラに起因している可能性が高い結果です。Ascendでは、ジョブ実行のためにKubernetesクラスタをその場で立ち上げ、ジョブ間はアイドル状態にしてコンピュートコストを抑える仕組みになっています。
そこで、Ascendのクラスタが立ち上がっている状態でのホットスタートで、フェアな比較となるよう実行時間をもう一度計測しました。
「ホットスタート」 - パイプライン全体の2回目以降の平均実行時間
- Ascend:10秒
- dbt:32秒
2回目以降の実行では、両パイプラインで同じデータ量・同じ変換コードを処理した場合に、Ascendの方が大幅に高速でした。これはAscendクラスタの動的かつ並列化された構造によるところが大きく、各ステップの処理をマルチスレッドで実行できるため、結果として処理時間が大幅に短縮されたと考えられます。
Snowflake creditsとBigQuery バイト数の比較
ジョブごとのSnowflake credits
Ascendとdbtの両パイプラインで使用したcreditsを比較するため、対決ではSnowflakeデータベース内で利用するスキーマを分けました。具体的には、Ascendパイプラインは「sources_ascend」「ascend_t_conn」の接続を、dbtパイプラインは「dbt_mrichardson」「public」のスキーマを使用しています。
使用credits量で見ると、AscendパイプラインはdbtパイプラインよりもSnowflake creditsの面で明らかに効率的でした。合計使用credits量は次のとおりです。
- Ascendパイプラインの消費量 = 61.165 + 28.071 = 89.236 credits
- dbtパイプラインの消費量 = 1924.652 + 33.685 = 1958.337 credits

Snowflake側でこれほど大きな差が出た要因の1つは、Ascendが気象データに対して行ったパーティショニングにあると考えられます。各ファイルが取り込み時に全件まとめての縮約を必要とせず、増分単位で伝播されたため、パイプラインの実行に必要なコンピュートが大幅に削減され、開発時も同様でした。さらに、パイプライン処理が終わるとすぐにSnowflakeのVirtual Warehouseを停止して不要な稼働時間を減らすなど、Ascendプラットフォーム側のコスト削減・コンピュート管理機能もこの差に寄与しています。
ジョブごとのBigQueryスロット使用量
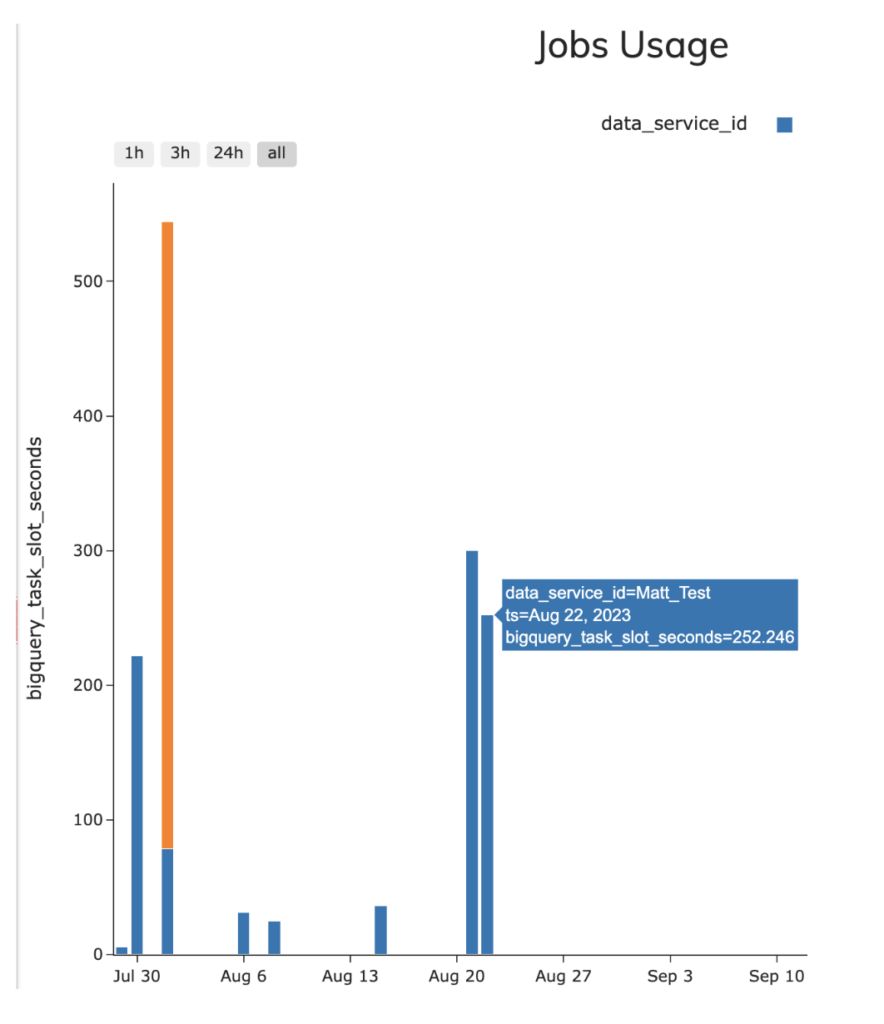
- Ascend:1秒あたり平均4.18スロット(合計252.46スロット秒)
- dbt:1秒あたり平均3.2スロット(合計189.34スロット秒)
BigQueryでは、両パイプラインともにスロット観点でかなり効率よくジョブを実行でき、ジョブ全体の平均ではdbt Cloudの方がわずかに効率的でした。このスロット使用率の差を細かく見ていくと、AscendのData Service実行設定と、dbtで構築したテストDAGとで並列度に違いがあったことが原因でした。前者では擬似ETLプロセスのステップをより多く並列実行するため、今回の単純な構成ではAscendの方がdbtよりもスロット競合が高くなっていたのです(dbt側のthreadsの割り当てによる影響もあります)。
そこで、dbtの実行に–threads:4オプションを追加して並列度を引き上げたところ、再実行時にスロットリソースの競合がやや増えた結果、1秒あたり約4.3スロットというAscendに近い平均パフォーマンスが得られました。
これらの値の確認には、JOBSビューに対するinformation_schemaのサンプルクエリで両パイプラインを計測しました(付属のGitHubリポジトリに含めています)。なお、Ascendのインターフェースには、下のスクリーンショットのとおり、Ascend上で実行したパイプラインのBQスロット使用率およびSnowflake credit消費量を計測するためのビューが組み込まれている点も付け加えておきます。
エラーハンドリングのシナリオ
2つのパイプラインでは、いくつかのエラーハンドリングシナリオも検証しました。具体的には次のとおりです。
- パイプラインへのロード地点の70%地点、および変換途中の段階で、コードや取り込みデータのよくあるバグを模したエラーを差し込んでパイプラインを停止させ、その障害状態からパイプラインの再開を試みて挙動を確認する。
- 意図的にパイプラインを失敗させるため、不正なCSVファイルを新たに追加する。
これらのシナリオを実際に試した結果、次のことがわかりました。
Ascendのエラーハンドリング
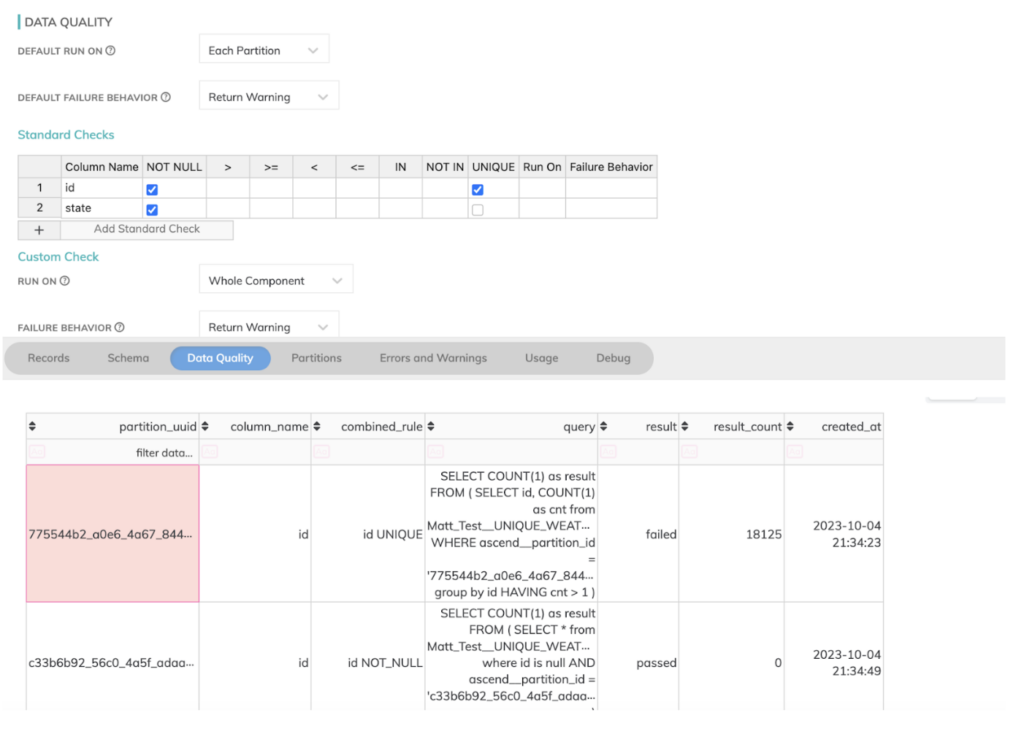
- パイプライン実行の70%地点での失敗、不正なCSVファイルをバケットに追加した場合のいずれのシナリオでも、Ascendはきれいに失敗してくれました。Ascendには、こうしたエラー発生時のパイプラインの挙動を制御する高度な設定が用意されています。さらに、障害からの復旧も非常にスマートでした。各パイプラインステージのデータがマテリアライズされているため、最後に正常完了したコンポーネントから処理を再開し、障害発生地点から続きを実行できます。これにより、パイプライン全体を再実行しなければならない場合に発生するはずだった、相当量の再計算を節約できました。
- さらに、dbtと同様、Ascend.ioにもデータ品質チェックがあり、不正なCSVファイル内の問題を検知してシステム内に取り込まれるのを防ぐのに役立ちます。これらは内部に組み込まれており、ほとんど追加設定なしで活用できます。下の図は、ソースデータファイルにいくつか不正なフィールド値を仕込んだ際のAscendのデータ品質タブの様子です。
dbtのエラーハンドリング
上記のシナリオはdbtにはあまり向いていませんでした。Ascendパイプラインと同じように、エラーハンドリング用テーブルにエラーを保持することは可能ですが、こうした機能を使うには追加のdbtパッケージのインストールが必要でした(特にcatalogiaが提供するdbt-expectationsパッケージは、データ品質まわりで優れた機能を提供しているので、ここで触れておきます)。また、パイプラインに再実行プロセスを実装することはできましたが、ジョブを手動で再実行するか、dbt Cloudのジョブ側のリトライ設定で追加のエラー設定を行う必要がありました。
各dbtモデルでnot-nullチェックやuniqueチェックを行うためにも、追加の設定が必要でした。設定量自体は大したものではありませんが、dbt Coreやdbt Cloudのプロジェクト設定にあまり慣れていない開発者には、つまずきのもとになり得ます。
結びの考察
気象データのケーススタディをAscend.ioとdbtの両方で検証した結果、いずれのサービスもデータ変換のユースケースに十分応えられることが明確になりました。一方で、両サービスのネイティブ機能やサードパーティ拡張を徹底的に試した結果、どちらのツールセットを選ぶべきかは、自社のニーズに最もよく合うのはどちらかによる、ということもはっきり見えてきました。
Ascend.ioは、データパイプラインを内部で自動的に最適化・オーケストレーションしてくれるワンストップのクラウドデータパイプラインツールです。フレンドリーなUIにより、経験レベルの異なる開発者でもパイプライン構築をシンプルかつ効率的に進められます。データ基盤の専門知識や手作業の長時間コーディングがなくても、パイプラインを安定稼働させるためのパフォーマンス向上機能が組み込まれています。
クラウドデータパイプラインの用途、とりわけ保守の手間や管理対象のオーケストレーションツールを減らせるとメリットが大きい場合には、Ascend.ioは試す価値が十分にあると考えています。ジョブセットアップのシンプルさと、デフォルトで備わるクラウドコンピュートのコスト削減設定により、Ascendはユースケースによっては、dbtのようなコード重視のツールに代わる優れた選択肢となります。
本記事で取り上げたAscendとdbtのパイプラインは、こちらのGitHubリポジトリで参照できます。