Zwei Tools zur Datentransformation für den Aufbau von Cloud Data Pipelines im direkten Vergleich.

Datentransformation kennt fast jeder Datenprofi – aber welches Produkt passt zu Ihnen?
Zu den größten Herausforderungen, mit denen DoiT-Kunden zu kämpfen haben, zählen die Transformation und Verarbeitung von Daten aus unterschiedlichen Quellen in zahlreiche Zielsysteme.
Viele unserer Kunden setzen Data-Warehousing-Dienste wie Snowflake oder Google BigQuery ein, um ihre Daten zu speichern und zu verwalten. Sie möchten wissen, wie sich diese Daten effektiv handhaben lassen, ohne Pipeline-Code manuell ausführen und pflegen zu müssen.
Früher – bei relationalen Datenbanken und klassischen Data-Warehouse-Infrastrukturen – war das die Domäne der ETL-Tools: Lösungen wie SSIS, Informatica oder SAS Data Integration Studio steuerten Extraktion, Transformation und das Laden der Daten von der Quelle in das gewählte Data Warehouse.
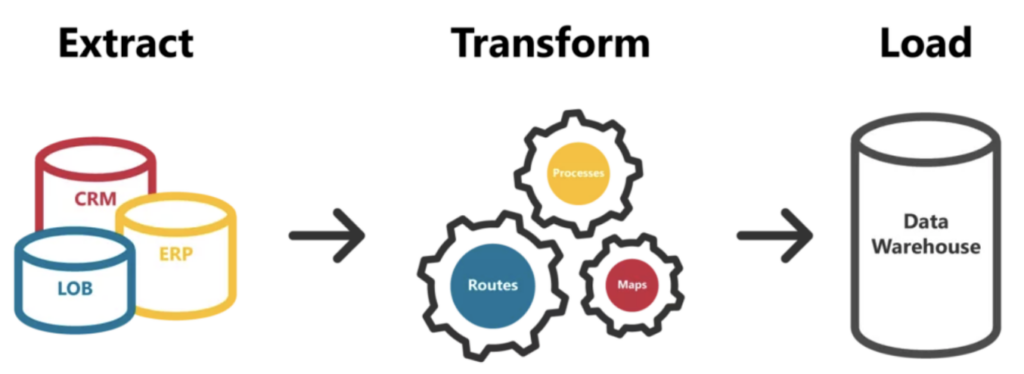
Doch mit dem Aufkommen von Cloud Data Warehouses wie Snowflake, BigQuery, Redshift usw. hat sich die Branche weiterentwickelt. Diese Plattformen der nächsten Generation eignen sich aufgrund ihrer Architektur und Effizienz besser für eine ELT-Struktur: Sie kommen problemlos damit zurecht, dass die Transformationsarbeit als Pushdown-workloads direkt im Data Warehouse erledigt wird. Damit erübrigen sich die genannten klassischen Tools, denn jeder Cloud-Anbieter stellt für den "EL"-Teil von ELT in der Regel eine eigene effektive Lösung bereit, um Daten in die nativ unterstützten Cloud Data Warehouses zu laden.
Auftritt Transformations-Tool!
In den letzten Jahren haben viele unserer Kunden spezielle Daten-Konnektoren für die Extraktion aus den Quellsystemen eingeführt – sowie Transformations-Tools für die rechenintensiven Berechnungen innerhalb des Data Warehouse. Zusammen ergeben diese Ingestion- und Transformationsschritte das, was heute viele als Cloud Data Pipeline bezeichnen.
Das hat unmittelbar dazu geführt, dass Tools wie Fivetran für den ersten Teil und dbt für den zweiten Teil dieser Lösung immer häufiger zum Einsatz kommen. Doch was wäre, wenn es eine Alternative gäbe, die sowohl die Datenaufnahme als auch die anspruchsvollen Transformationen übernimmt – und das Ganze obendrein effektiv orchestriert, ohne dass zusätzliche Werkzeuge wie Apache Airflow DAGs für die Steuerung Ihrer Transformationsjobs nötig sind?
Ascend.io im Überblick
![]()
Ascend.io ist ein bedeutender Anbieter im Bereich Data Pipeline Automation und ermöglicht den Aufbau der weltweit intelligentesten Daten-Pipelines.
Ascend ist eine zentrale Plattform, die Änderungen in Ihrem gesamten Ökosystem erkennt und propagiert, die Datenqualität sicherstellt und die Kosten Ihrer Datenprodukte quantifiziert. So lassen sich Ingestion-Pipelines an einem Ort aufbauen und verwalten, komplexe Transformationen durchführen und das Ganze als Teil einer übergreifenden Business-Pipeline orchestrieren.
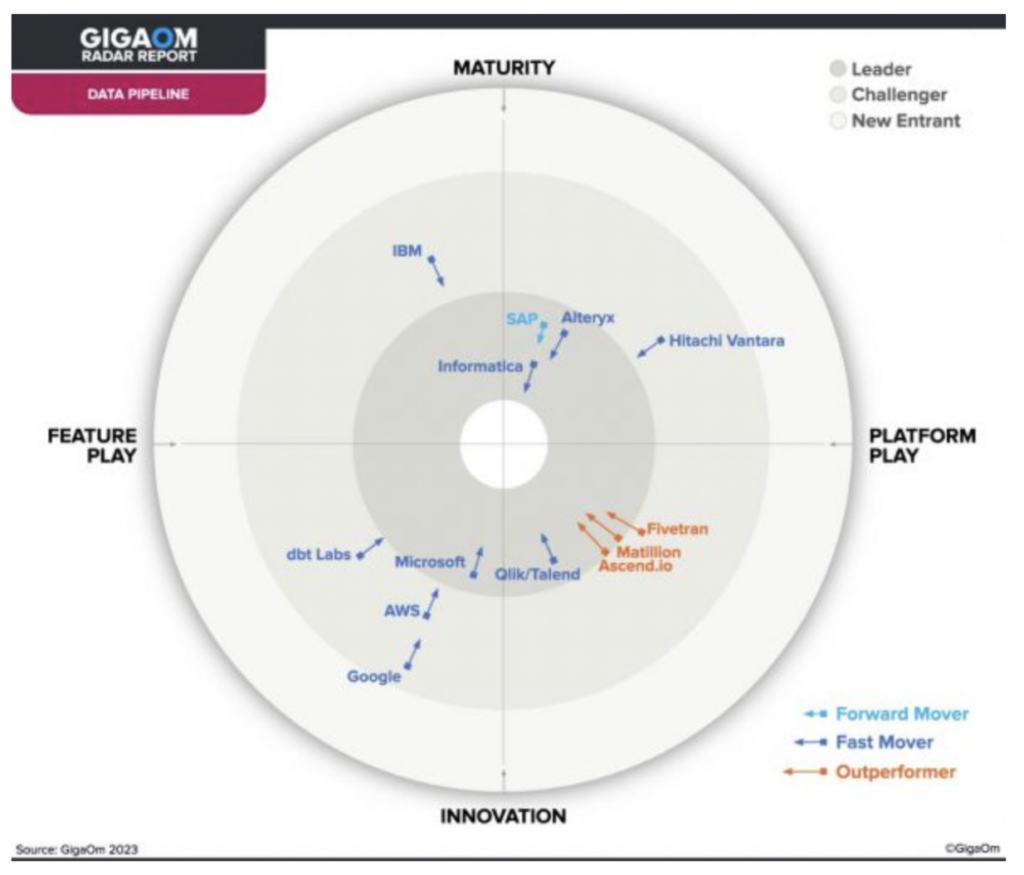
In einem aktuellen GigaOm-Report wurde Ascend als einer von nur drei Outperformern im Bereich Data Pipeline ausgezeichnet – damit ist die Plattform eine ideale Wahl für eine moderne Daten-Pipeline.
Der Ascend.io-Service erkennt Änderungen an Ihren Quellen und propagiert diese automatisch über das Data Warehouse Ihrer Wahl durch Ihre Daten-Pipeline – manuelles Scheduling oder Job-Steuerung durch Ihre Teams entfallen.
Außerdem bietet Ascend erstklassige Integrationen mit verschiedenen Data-Warehouse-Anbietern, inklusive Tabellen- und View-Optimierungen wie Partitionierung innerhalb der Ascend-Dataflows. So wird die Datenverarbeitung in Ihren Ascend-Pipelines durchgängig optimiert.
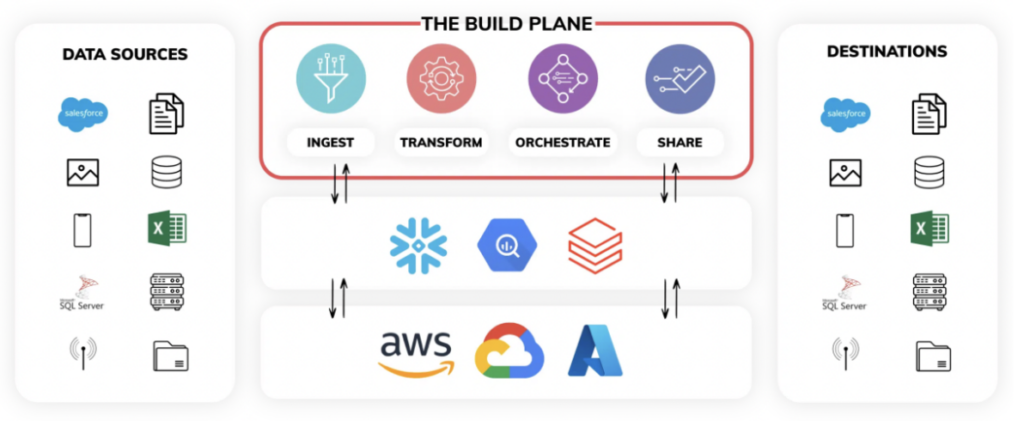
Wenn Sie den Ascend Data Pipeline Service voll ausschöpfen, arbeiten Sie mit drei zentralen Ebenen:
- Build Plane – Stellen Sie sich die Build Plane als zentrale Oberfläche vor, in der die gesamte Logik für Ingestion und Transformation programmiert wird. Pipelines lassen sich auch im Backend per SDK und CLI entwickeln. Die Benutzeroberfläche visualisiert die komplette Data Lineage und überwacht alle Vorgänge in Echtzeit.
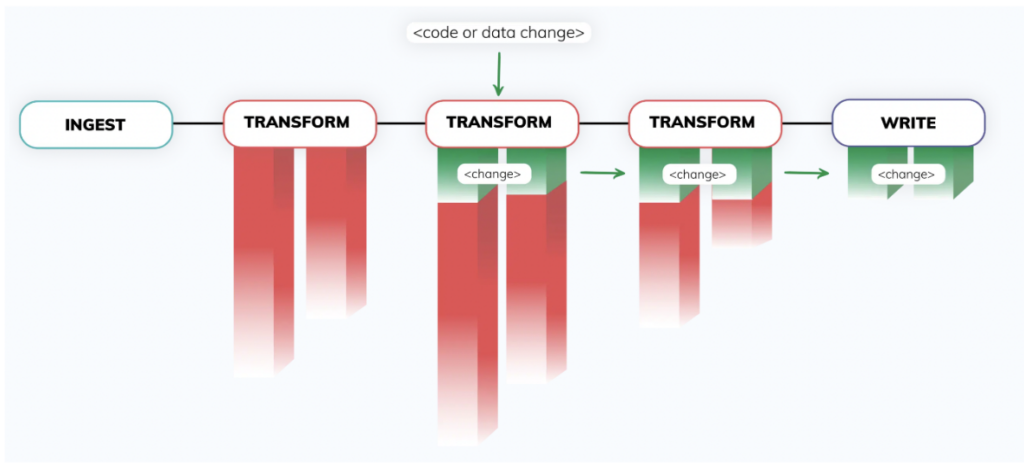
 2. Control Plane – Im Herzen der Ascend-Plattform sitzt eine ausgefeilte Control Plane, angetrieben von einer einzigartigen Fingerprinting-Technologie. Diese vollständig autonome Engine erkennt fortlaufend Änderungen an Daten und Code in weitläufigen Netzwerken selbst komplexester Daten-Pipelines und reagiert in Echtzeit darauf. Die Daten-Pipelines bleiben synchron – ganz ohne zusätzlichen Orchestrierungs-Code.
2. Control Plane – Im Herzen der Ascend-Plattform sitzt eine ausgefeilte Control Plane, angetrieben von einer einzigartigen Fingerprinting-Technologie. Diese vollständig autonome Engine erkennt fortlaufend Änderungen an Daten und Code in weitläufigen Netzwerken selbst komplexester Daten-Pipelines und reagiert in Echtzeit darauf. Die Daten-Pipelines bleiben synchron – ganz ohne zusätzlichen Orchestrierungs-Code.
- Ops Plane – Die Ops Plane von Ascend hilft dabei, intelligente Daten-Pipelines im Unternehmen zu verankern. Sie adressiert die drei zentralen Säulen des Datenbetriebs: Sie steigert das Vertrauen im Business, quantifiziert die Kosten der Datenverarbeitung und schafft Transparenz. Die Ops Plane überwacht die Abfolgen von workloads in Echtzeit, während Daten durch das gesamte Netzwerk verbundener Pipelines aufgenommen und verarbeitet werden.
Ascend ist derzeit kompatibel mit den Data Clouds von Google BigQuery, Snowflake und Databricks – und die Unterstützung weiterer Dienste wird in naher Zukunft kontinuierlich ausgebaut.
Angesichts der starken Automatisierungs-Engine und der Möglichkeit, sowohl per UI als auch per Code zu entwickeln, ist Ascend für Cloud-Data-Pipeline-workloads definitiv einen genauen Blick wert. Wir freuen uns, Ihnen in diesem Deep Dive zu zeigen, wie Sie das Tool einsetzen können.
dbt im Überblick
![]()
dbt ist ein SQL-basiertes Tool für Transformations-Pipelines, mit dem Teams Analytics-Code schnell und gemeinsam ausrollen können – nach Best Practices der Softwareentwicklung wie Modularität, Portabilität, CI/CD und Dokumentation. Die Zusammenarbeit erfolgt über Repositories, und in den letzten Jahren hat sich dbt am Markt als äußerst beliebtes Tool etabliert.
dbt selbst gibt es in zwei Varianten:
- dbt Cloud – eine UI-basierte Version von dbt, die zugleich Deployment und Ausführung der dbt-Modelle direkt übernimmt. Es gibt eine kostenlose Variante für Einzelnutzer; für Entwickler-Teams stehen verschiedene Preisstufen zur Verfügung.
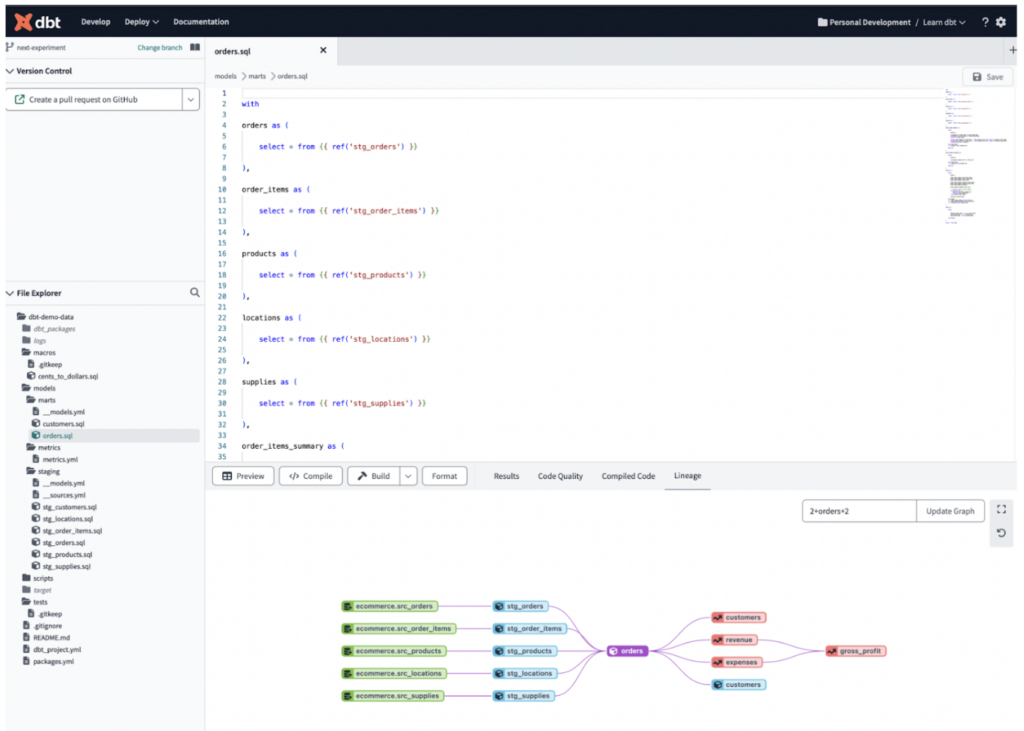
- dbt Core – die kostenfreie, codebasierte Version von dbt, die sich mit den meisten IDEs wie z. B. Visual Studio Code nutzen lässt. Wie dbt Cloud kann sie an ein Repository Ihrer Wahl angebunden und mit Tools wie Apache Airflow gemeinsam orchestriert werden, um Ihre Daten-Pipelines zu koordinieren.
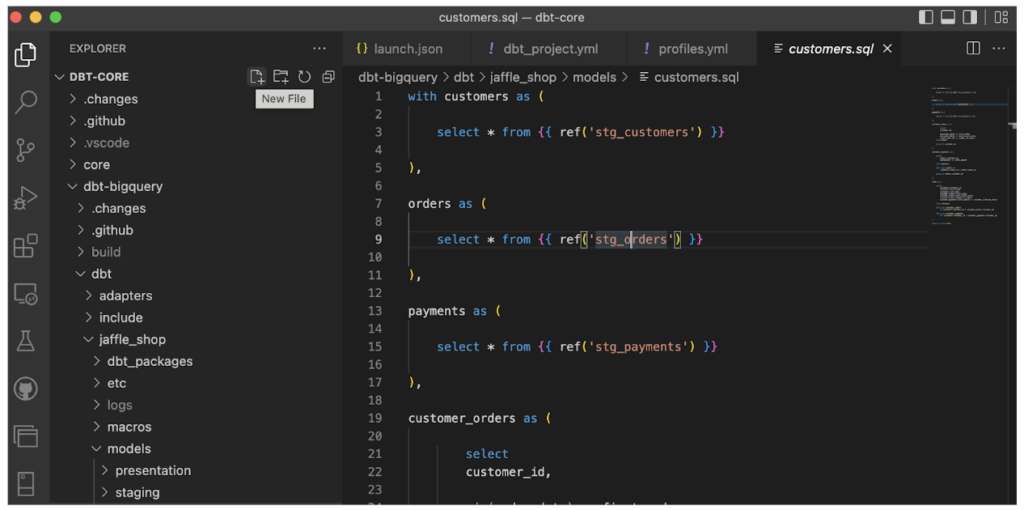
Neben der Koordination von Entwicklung und Deployment verschiedener Transformationsjobs ermöglicht dbt Unit-Tests Ihrer Daten und liefert über die Catalog-Funktionen Data Lineage – damit lässt sich der End-to-End-Fluss Ihrer ELT-Pipelines deutlich einfacher dokumentieren.
dbt ist mit zahlreichen Data-Warehouse- und Data-Lake-Angeboten kompatibel, darunter Snowflake, BigQuery, Redshift, Databricks und Starburst – und damit eine beliebte Wahl bei größeren Unternehmen, die mehrere dieser Plattformen einsetzen.
Der DoiT Bake-Off: unsere Bewertung
Ascend und dbt sind also offensichtlich beide effektive Tools für die Datentransformation und bringen jeweils eigene Stärken mit. Doch welches eignet sich besser für einen typischen Cloud-Data-Pipeline-Use-Case? Wir sind in folgenden Schritten vorgegangen, um beide Dienste in einem Bake-Off gegeneinander antreten zu lassen.
Unser Szenario: Bulk-Erfassung und -Transformation täglicher Wetterdaten für den Monat August – mit Millionen von Datensätzen, die aus Google Cloud Storage aufgenommen und anschließend in Snowflake bzw. Google BigQuery jeweils sowohl in Ascend.io als auch in dbt Cloud durch Daten-Pipelines geschickt werden.
Unsere Pseudo-Pipeline besteht aus den folgenden Standardschritten:
- Einlesen der täglichen Rohwetterdaten aus dem gewählten Data Warehouse und Zusammenführen mehrerer Tagesextrakte in einer einzigen Tabelle für die weitere Analyse.
- Segmentierung dieser Daten in unterschiedliche Kategorien (jeweils für heißes, mildes und kaltes Wetter) – mit grundlegenden Transformationen auf dem zusammengeführten Datensatz.
- Komplexere Aggregationen und statistische Transformationen auf den aufgeteilten Datensätzen – einschließlich eines Joins der transformierten Daten mit einer Locations-Lookup-Tabelle, die Ortscodes für unsere Wetterregionen enthält.
- Ausgabe der finalen Datensätze in einen Pseudo-Data-Mart bzw. eine Präsentationsschicht im jeweils gewählten Data Warehouse.
In unserem Fall möchten wir zunächst aus Entwicklersicht die Zeit vergleichen, die für den Aufbau solcher Prozesse in Ascend.io bzw. dbt nötig ist – schließlich ist die Bauzeit Ihrer Datenlösungen eine zentrale Stellschraube für die Performance Ihres Teams.
Sobald die Jobs gebaut sind, prüfen wir folgende Aspekte für die Bewertung im Bake-Off und für die Total Cost of Ownership beider Lösungen:
- Die Laufzeiten des gesamten Pipeline-Sets von Anfang bis Ende (sowohl mit Hot- als auch Cold-Starts für die Ascend-Pipeline, da im Hintergrund Spark-Infrastruktur zum Einsatz kommt)
- Die in beiden Pipelines verbrauchten Credits (für Snowflake) und gescannten Bytes (für BigQuery)
- Das Error Handling – wir provozieren in beiden Pipelines Fehler und untersuchen, wie die jeweiligen Recovery-Lösungen aussehen
- Das Hinzufügen neuer Wetterdatendateien zu den Pipelines und der daraus resultierende erneute Lauf zur Aktualisierung der Datensätze, um zu prüfen, wie die Pipelines bei neu eintreffenden Daten performen
- Das Maß an Interaktion und Steuerung der zugrundeliegenden Data Warehouses – z. B. das Stoppen virtueller Warehouses in Snowflake, automatisches Partitionieren in Ascend-Jobs sowie viele weitere typische Aufgaben der Pipeline-Orchestrierung
Nachdem wir nun die Spielregeln für diesen Bake-Off festgelegt haben, bauen wir das Szenario auf und schauen, wie unsere Wetterdaten in beiden Lösungen angereichert werden.
Der DoiT Bake-Off: so bauen wir unseren Case auf
Gehen wir den Entwicklungsprozess sowohl auf der Ascend- als auch auf der dbt-Seite Schritt für Schritt durch.
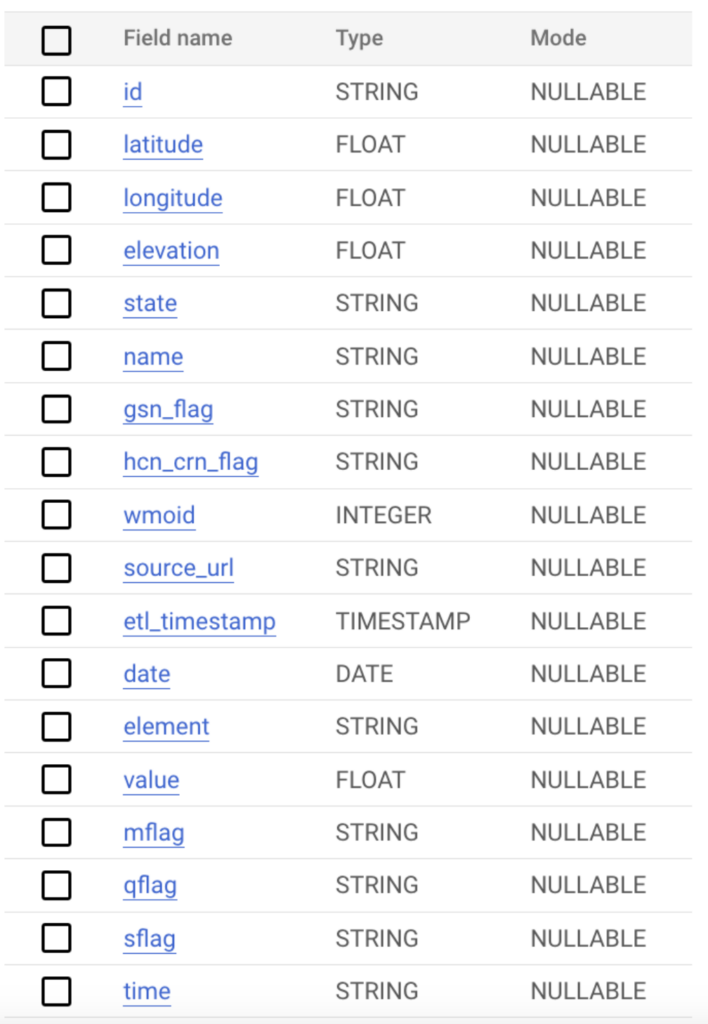
Für unsere Fallstudie haben wir die Wetterdaten aus den öffentlichen ghcn_d-Datasets von Google bezogen.
Um ein ausreichendes Datenvolumen zu erreichen, haben wir alle Felder aus diesen Daten ausgewählt und gemäß der untenstehenden Abfrage Tagesdateien für den Zeitraum vom 1. bis einschließlich 31. August 2023 erzeugt.
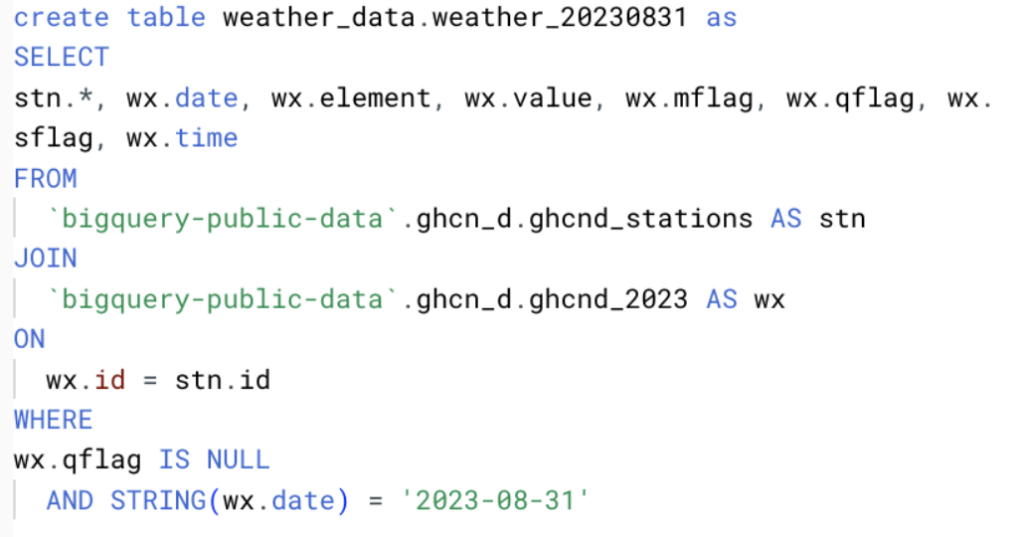
Die Daten haben in diesem Fall das unten gezeigte Schema und insgesamt mehrere Millionen Datensätze. Um verschiedene Szenarien zu testen, haben wir diese Daten in BigQuery-Tabellen und in Google Cloud Storage abgelegt – so lassen sich plattformübergreifend unterschiedliche Ingestion-Methoden prüfen.
Entwicklungsprozess in Ascend
In Ascend.io legen Sie eine Daten-Pipeline an, indem Sie Dataflows erstellen. Diese werden wiederum in Data Services gespeichert, was Ihnen für Ihre verschiedenen Daten-Pipelines ein gemeinsames Sicherheitsmodell liefert – wie in unserer Playground-Umgebung sichtbar.
Ascends Dataflows bieten Ihnen verschiedene Komponenten für Ingest/Read, Transform und Deliver/Write, die Sie in jedem Schritt Ihrer Pipeline einsetzen können.
Für unsere Pipeline möchten wir zunächst Read-Komponenten verwenden, um unsere initialen Wetterdatendateien direkt aus GCS oder BigQuery aufzunehmen.
Anschließend nutzen wir Transform-Komponenten, um die Daten für unseren Prozess aufzubereiten. Für diesen Bake-Off habe ich BigQuery SQL verwendet, da es mein vertrautester SQL-Dialekt ist; in Ascend stehen Ihnen aber verschiedene Sprachen wie Python, Spark SQL oder SnowSQL (sofern aktiviert) zur Verfügung, um Ihre Transformationen zu bauen.
Zum Schluss verwenden wir eine Write-Komponente, um die Ausgabe unserer vollständig transformierten Pipeline zurück in das Data Warehouse unserer Wahl zu schreiben.
Die unten abgebildete Pipeline ist diejenige, die ich für diesen Bake-Off aufgebaut habe. Sie besteht aus drei Datenrouten für unterschiedliche Wärme-/Kältegrade in unserer abschließenden Analyse:
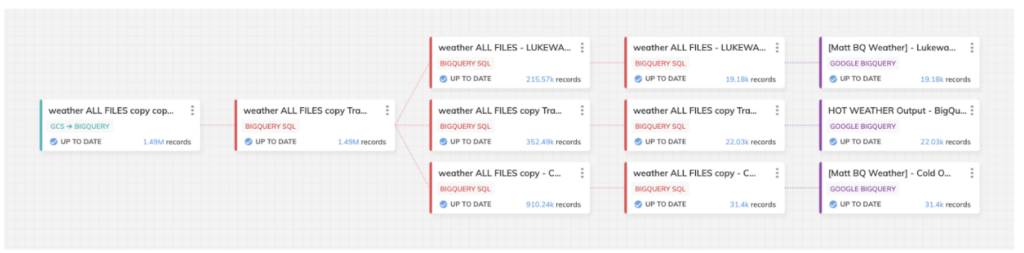
Das Pipeline-Design war in BigQuery und Snowflake identisch; der Screenshot stammt aus dem für BigQuery konzipierten Template.
Für unseren Read-Konnektor wollten wir zunächst die Verbindung zu den Dateien in unserem GCS-Bucket (Google Cloud Storage) einrichten. Dafür benötigten wir einen Service Account mit Zugriff auf den entsprechenden Bucket.
Da wir mehrere Wetterdateien haben, lässt sich in Ascend ein Präfix angeben, sodass das Tool weiß, dass es alle Dateien mit ähnlicher Namenskonvention für unsere Pipeline einlesen soll.
Außerdem haben wir Header-Zeilen in unsere CSV-Dateien aufgenommen, daher müssen wir in der Read-Komponente von Ascend die Option zum Ausschließen dieser Zeilen setzen.
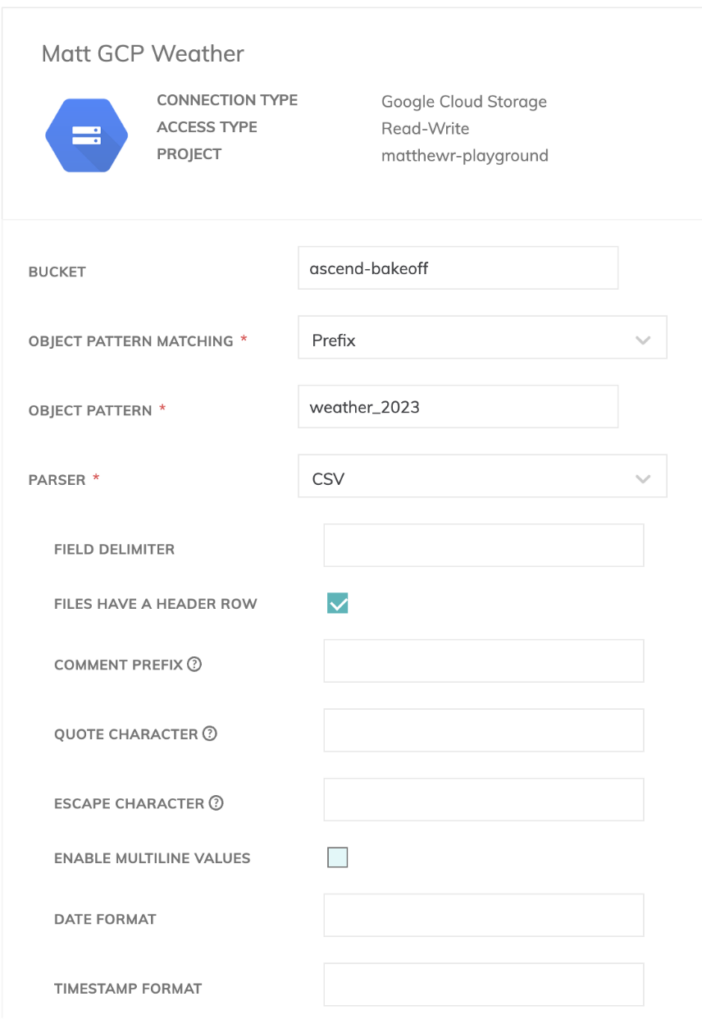
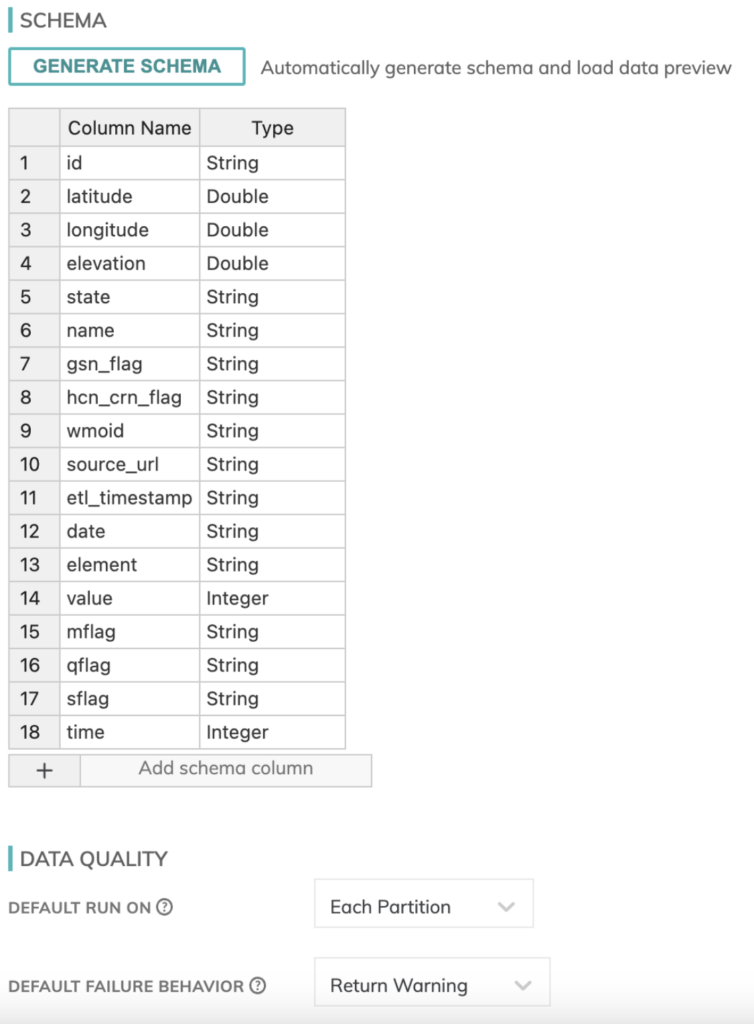
Wir müssen auch ein Schema für unsere Wetterdaten definieren. Glücklicherweise verfügt Ascend über einen integrierten Schema-Detector für die Read-Komponenten, sodass das relativ einfach von der Hand ging.
Hier lassen sich auch Datenqualitätsprüfungen und das Verhalten im Fehlerfall festlegen, um Ihre Jobs end-to-end zu steuern.
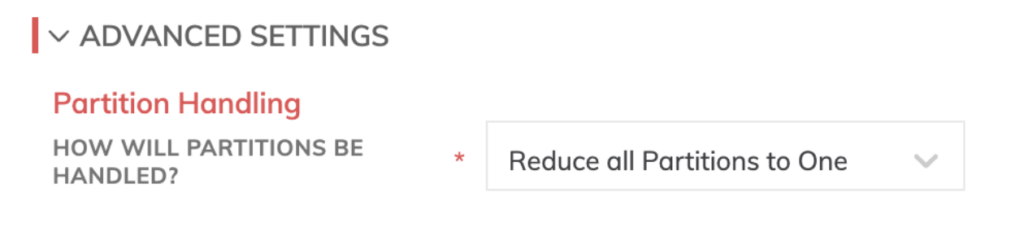
Eine weitere interessante Funktion der Ascend-Plattform ist die pipeline-spezifische Dataset-Partitionierung. Sie segmentiert Ihre Daten in sinnvolle Blöcke und verarbeitet diese unabhängig voneinander – das beschleunigt den Durchsatz Ihrer Pipelines im jeweiligen Data Warehouse.

Wie Sie an einem 20-Tage-Ausschnitt unserer Daten erkennen, sind die Partitionen jeweils auf einen Tag unserer Wetterdateien zugeschnitten.
Auch die Transformationen ließen sich in Ascend einfach einrichten. Sie wählen lediglich Ihre bevorzugte Sprache und schreiben den Code im Hauptfenster der Komponente, wie unten gezeigt.
Eine Anmerkung: Ähnlich wie die Macro-Sprache von dbt nutzt Ascend Jinja-Logik, um auf Komponenten aus vorigen Pipeline-Schritten zu verweisen. Engineers, die mit diesem Stil vertraut sind, fühlen sich auf beiden Plattformen schnell zu Hause.
Um diesen Abschnitt nicht zu lang werden zu lassen, zeige ich hier zur Illustration nur eine einfache Transformationskomponente. Beachten Sie aber, dass wir einen vollständigen Referenzleitfaden für die Transformationen dieser Beispiel-Pipeline in einem GitHub-Repository hinterlegt haben – der Link findet sich am Ende dieses Beitrags.
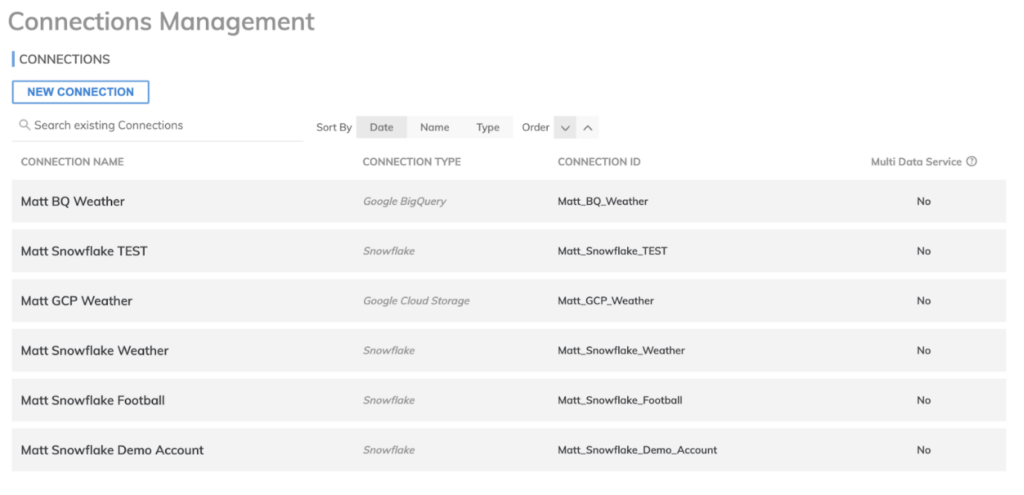
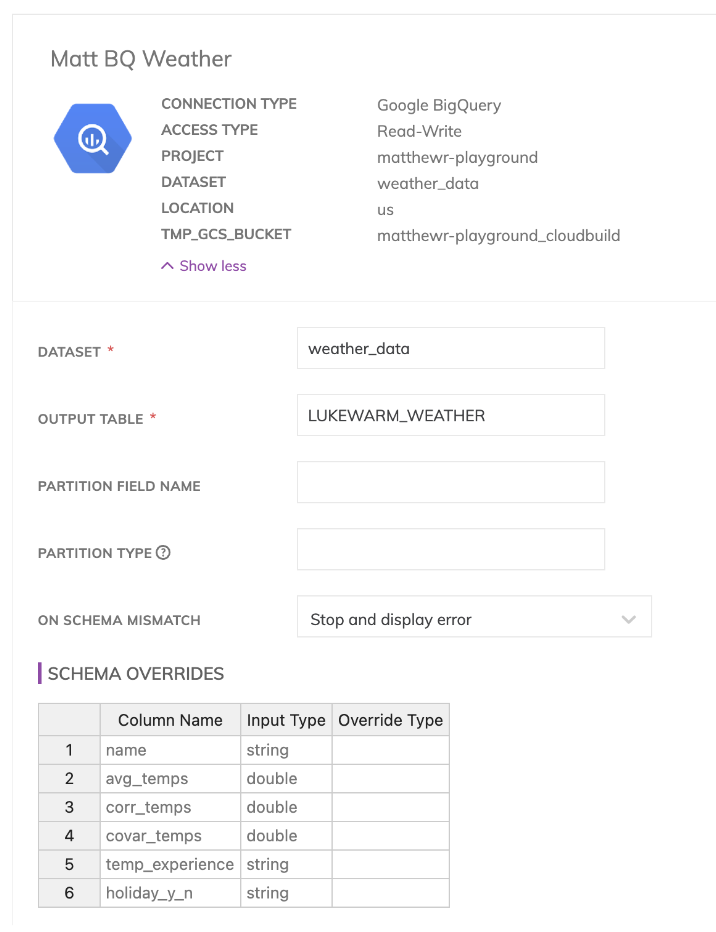
Schließlich mussten wir für unsere Write- bzw. "Reverse-ETL"-Komponenten erneut eine Verbindung zu unserem BigQuery-Data-Warehouse angeben.
Verbindungen lassen sich im Admin-Bereich von Ascend.io einrichten, wie hier zu sehen. Sie sind sowohl für Read- als auch Write-Komponenten essenziell, und Ascend.io unterstützt eine Vielzahl von Verbindungen, etwa zu Snowflake- oder BigQuery-Data-Warehouses oder zu Storage-Buckets in jeder Cloud.
Die Write-Komponenten selbst sind dann recht einfach. Sie geben lediglich eine Verbindung an, das Ausgabeschema, dann – je nach Data Warehouse – den Namen der Zieltabelle sowie weitere cloud-spezifische Optionen (etwa den Dataset-Namen in BigQuery oder das Schema in Snowflake).
Beachten Sie: Ascend materialisiert die Daten standardmäßig bei jedem Transformationsschritt der Pipeline in den Snowflake- bzw. BigQuery-Data-Planes. Daher ist es nicht zwingend erforderlich, einen Output-Konnektor zurück ins Data Warehouse anzulegen – er steht aber zur Verfügung, falls Sie am Ende noch Schema-Anpassungen vornehmen möchten, die keine weitere Transformationslogik beinhalten.
Was den Gesamtaufwand betrifft: Auch wenn mein Vorgehen und die Erläuterungen hier nach mehreren Schritten aussehen, habe ich diese Pipeline in rund 10 Minuten komplett gebaut – inklusive der Zeit für das Einrichten der Verbindungen zu GCS, BigQuery und Snowflake in meinen Ascend.io-Playground-Accounts für diese Demo.
Erwähnenswert ist: Wann immer – wie in unseren Spielregeln vorgesehen – neue Wetterdateien hinzukamen, hat unser Ascend Data Service diese automatisch erkannt, und die Pipeline ließ sich nach Belieben für die neuen Dateien bzw. Datenergänzungen erneut ausführen.
Das Tolle an Ascend für diesen Use-Case: Meine Pipeline ist nun aufgesetzt und für den Rest ihres Lebenszyklus relativ wartungsarm. Es sind kaum zusätzliche Arbeiten nötig, um Logik zu ändern oder neue Schritte einzubauen. Wenn solche Änderungen anfallen, erkennt der Automation Controller sie und ermittelt automatisch, welche Abschnitte der Pipeline neu laufen müssen und welche Partitionen des Datasets ein Refresh benötigen. Noch beeindruckender: Das funktioniert über mehrere miteinander verbundene Pipelines hinweg – eine einzige Modelländerung wird vom Service automatisch über Dutzende von Verarbeitungsjobs und DAGs orchestriert, ohne dass ich selbst eingreifen muss. Ein dickes Plus für Ascend!
Entwicklungsprozess in dbt
Auf der dbt-Seite habe ich für diesen Bake-Off dbt Cloud über meinen kostenlosen Account genutzt. Das schien die naheliegendere Option, da dbt Cloud eine eigene integrierte Orchestrierung mitbringt und keinen Drittanbieter-Service wie Airflow benötigt – das ergibt einen faireren Vergleich zur All-in-one-Erfahrung von Ascend.
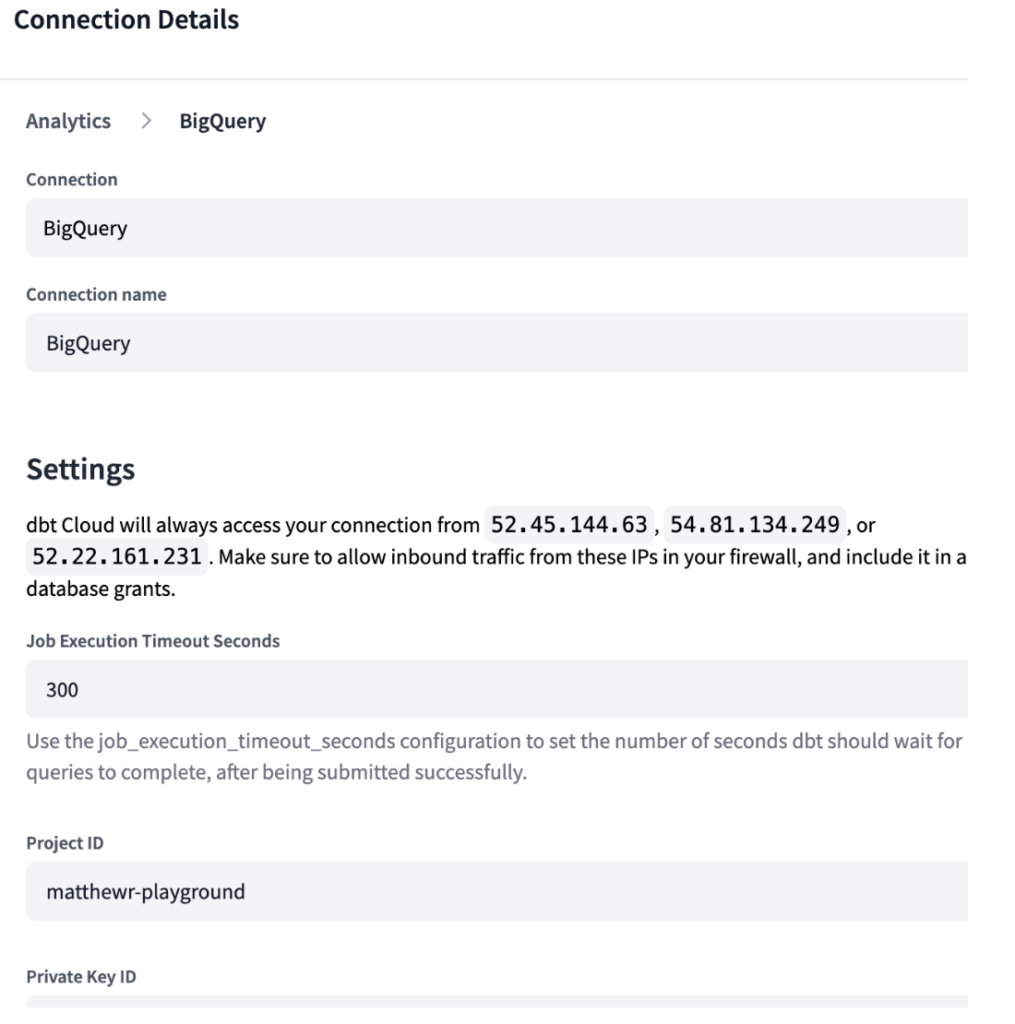
Ähnlich wie bei Ascend müssen Sie in dbt Cloud Ihre Entwicklungsumgebung definieren. Da dbt darauf ausgelegt ist, sich mit dem jeweiligen Data Warehouse zu verbinden, mussten wir Verbindungen sowohl für unsere BigQuery- als auch für unsere Snowflake-Umgebung anlegen, mit den unten gezeigten Zugangsdaten.
dbt selbst besitzt verschiedene Verzeichnisse, die das Grundgerüst seiner Pipelines bilden – darunter Models (mit den im jeweiligen DWH ausgeführten SQL-Jobs), Tests (Unit-Tests gegen diese Modelle), Macros (wiederverwendbare Logik für Ihre Jobs) und Seeds.
Für diese Pipeline haben wir die identische Logik aus unserer Ascend-Pipeline in Form verschiedener .sql-Modelldateien in dbt nachgebaut, um denselben Prozess zu replizieren.
Unten ist der DAG unseres in dbt gebauten Prozesses für die Bake-Off-Logik zu sehen:

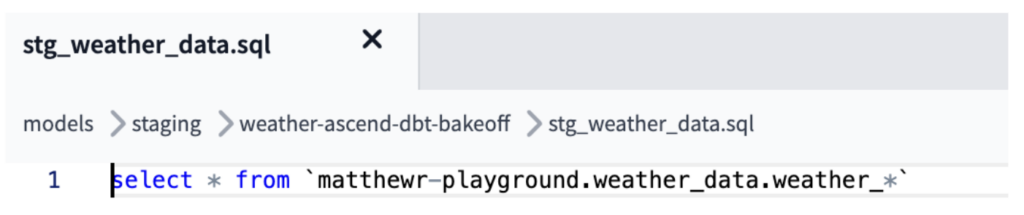
Um in diesem Fall die Aufnahme und Zusammenführung der CSV-Dateien zu replizieren, die wir aus den Ascend-Read-Konnektoren erhalten, kombiniert das Modell "stg_weather_data" in dbt die zahlreichen Quelldateien bzw. -tabellen – im Fall von GCS über External-Source-Logik bzw. mittels Wildcard-Logik in BigQuery, wie es das Ascend-Pendant tut (siehe unten).
Damit ließ sich auch das in unseren Spielregeln genannte Szenario der hinzugefügten Dateien abdecken: Die Wildcard-Klausel ist so ausgelegt, dass sie neue Dateien aufgreift, sobald diese in BigQuery geladen werden (alternativ lässt sich die Logik anpassen, um neue Dateien in GCS zu berücksichtigen).
Wir haben dann verschiedene dbt-Modelle in unterschiedlichen Verzeichnissen für die Staging-/Mart-Layer im Data Warehouse angelegt, wobei die finale Mart-Tabelle in unserem Beispiel die jeweils äquivalente Tabelle in unsere BigQuery- bzw. Snowflake-Data-Warehouses ausgibt. So erreichen wir dieselben Ergebnisse über exakt dieselbe SQL-Syntax wie unsere Ascend-Läufe – ein echter Bake-Off-Vergleich.
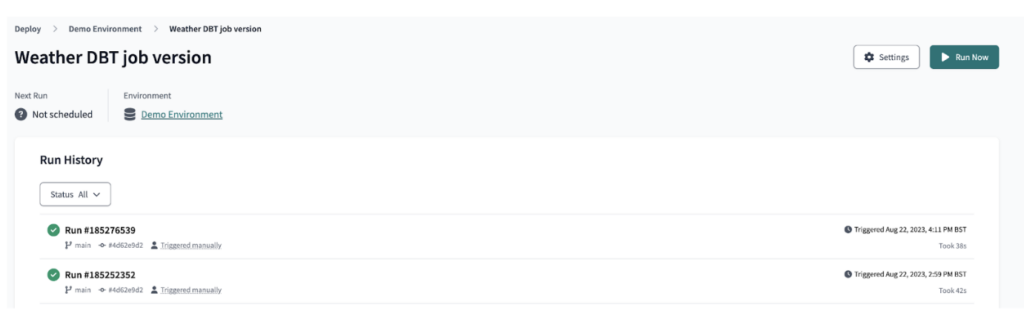
In dbt Cloud haben wir die dbt-Ausgabe anschließend als Job deployt, der den Pipeline-Lauf wie abgebildet orchestriert.
Durch das Konfigurieren der Orchestrierung des dbt-Cloud-Jobs lag die Gesamtentwicklungszeit etwas über der des vergleichbaren Ascend-Pipeline-Builds. Da dbt zudem eine codebasierte Lösung ist, mussten wir zusätzlich Zeit aufwenden, um die Standard-Ingestion-Seite der Pipeline (per .yml-Konfiguration) und die Ausgabe der finalen Präsentationsschicht-Tabelle zu konfigurieren – beides war beim Ascend-Pendant bereits in den Write-Konnektor integriert.
Die vergleichbare Pipeline ließ sich in dbt in rund 20 Minuten bauen.
Anzumerken ist außerdem: Anders als Ascend bietet dbt keine automatisierten Mechanismen, um Ihre Daten beim Laden in Partitionen aufzuteilen. Es fehlt zudem die Fähigkeit, neu im Quell-Bucket abgelegte Dateien zu erkennen und kurz nach deren Eintreffen automatisch inkrementelle Batch-Ingestions zu starten (egal ob in GCS oder BigQuery).
BigQuery-Partitionierung und -Clustering können in dbt-.yml-Dateien angewendet werden, allerdings ist dafür zusätzliche Konfiguration nötig – und es entspricht nicht den automatisch erzeugten Ingestion-Partitionen im Ascend-Tool.
Auch das Error Handling in dbt wird zwar über verschiedene Pakete wie Great Expectations unterstützt – aber wiederum müssen Sie diese Pakete eigens installieren und konfigurieren. Zudem ist Macro-Wissen über die Syntax dieser Pakete erforderlich, um die Logik in Ihre Jobs einzubauen, statt – wie in Ascend – einfach ein paar Checkboxen zu setzen.
Der DoiT Bake-Off: Ergebnisse
Und nun der Moment, auf den wir alle gewartet haben. Auf in den Ofen!
Unsere Tests beider Pipelines von Anfang bis Ende lieferten folgende Performance-Ergebnisse:
Laufzeiten
"Cold Start" – durchschnittliche Erstlaufzeiten der vollständigen Pipelines
- Ascend: 2 Min. 6 Sek.
- dbt: 47 Sek.
Anhand der initialen Laufzeiten sehen wir, dass die dbt-Cloud-Pipeline beim Cold Start schneller war. Das hängt aber wahrscheinlich mit der zugrundeliegenden Infrastruktur der Ascend-Pipelines zusammen: Im Hintergrund werden Kubernetes-Cluster spontan hochgefahren, um die Job-Ausführung zu übernehmen, und zwischen den Jobs wieder in den Idle-Modus versetzt, um Compute-Kosten zu sparen.
Daher haben wir einen weiteren Laufzeit-Check durchgeführt, um in einem Hot-Start-Szenario einen echten Apples-to-Apples-Vergleich zu erhalten – also wenn die Ascend-Cluster bereits aktiv sind.
"Hot Start" – durchschnittliche Folgelaufzeiten der vollständigen Pipelines
- Ascend: 10 Sek.
- dbt: 32 Sek.
Bei den Folge-Läufen war Ascend bei identischen Datenvolumen und identischem Transformationscode deutlich schneller. Das dürfte an der dynamischen und parallelisierten Natur der Ascend-Cluster liegen: Die Verarbeitung einzelner Schritte läuft multi-threaded und beschleunigt sich dadurch erheblich.
Vergleich: verbrauchte Snowflake Credits & BigQuery Bytes
Snowflake Credits pro Job
Bei den im Verlauf der gesamten Pipelines verbrauchten Credits haben wir Ascend und dbt im Bake-Off auf unterschiedliche Schemas in unserer Snowflake-Datenbank verteilt. Konkret nutzte die Ascend-Pipeline die Verbindungen "sources_ascend" und "ascend_t_conn", während die dbt-Pipeline die Schemas "dbt_mrichardson" und "public" verwendete.
Die Ascend-Pipeline war beim Verbrauch von Snowflake Credits deutlich effizienter als die dbt-Pipeline. Die insgesamt verbrauchten Credits waren:
- Verbrauch Ascend-Pipeline = 61,165 + 28,071 = 89,236 Credits
- Verbrauch dbt-Pipeline = 1924,652 + 33,685 = 1958,337 Credits

Diese große Lücke aus Snowflake-Sicht ist zum Teil auf die Partitionierungsfähigkeiten zurückzuführen, die Ascend auf unsere Wetterdaten anwendet. Da jede Datei inkrementell propagiert wurde, ohne dass beim Ingest eine vollständige Reduktion erforderlich war, wurde für die Pipeline – und auch während ihrer Entwicklung – deutlich weniger Compute benötigt. Die Lücke lässt sich auch durch weitere Funktionen der Ascend-Plattform zur Kosteneinsparung und Compute-Steuerung erklären, etwa das Abschalten von Snowflake Virtual Warehouses, sobald die Pipeline-Verarbeitung abgeschlossen ist, um unnötige Laufzeiten zu vermeiden.
Verbrauchte BigQuery-Slots pro Job
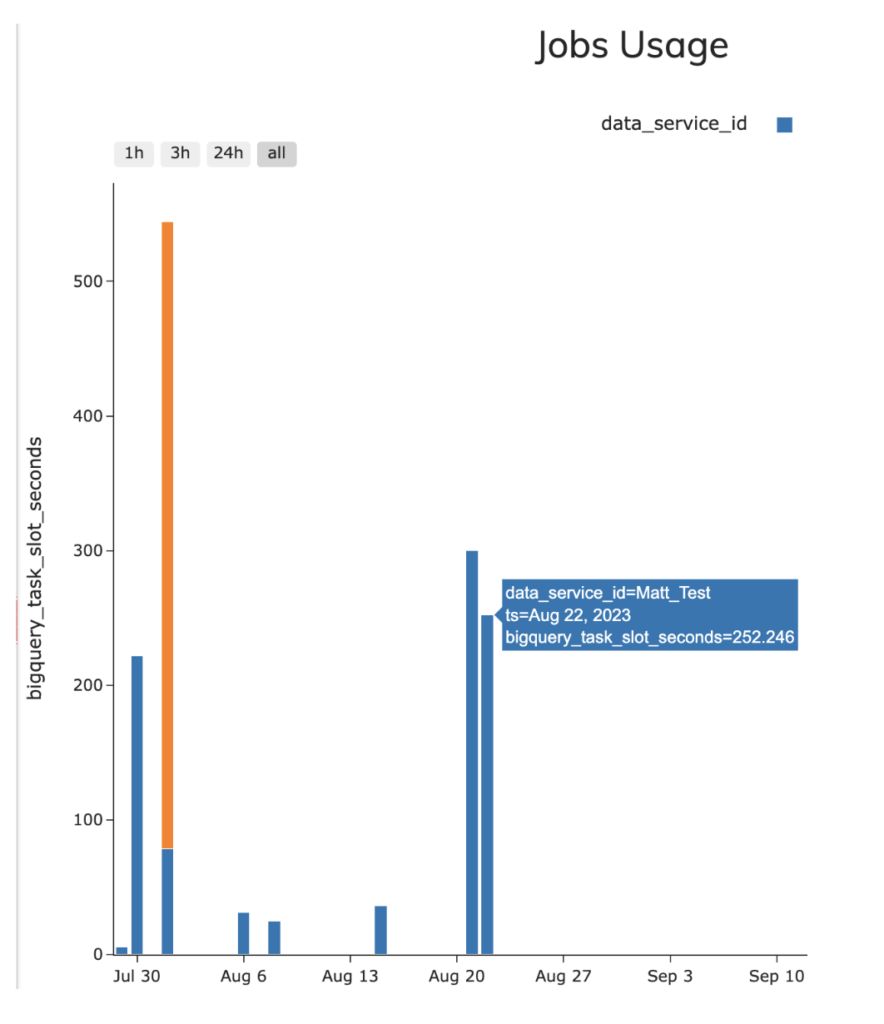
- Ascend – 4,18 Slots/Sek. im Schnitt (252,46 Slot-Sekunden insgesamt)
- dbt – 3,2 Slots/Sek. im Schnitt (189,34 Slot-Sekunden insgesamt)
Auf der BigQuery-Seite konnten beide Pipelines die BigQuery-Jobs aus Slot-Sicht recht effektiv ausführen, wobei dbt Cloud im Mittel über die Job-Ausführung hinweg etwas effizienter war. Beim genaueren Hinsehen zeigte sich, dass dieser leichte Unterschied an meinen Run-Settings im Ascend-Data-Service im Vergleich zu meinem Test-DAG in dbt lag – konkret an der Parallelität der jeweiligen Läufe. In Ascend liefen mehr Schritte meines Pseudo-ETL-Prozesses parallel, was im Vergleich zu meinem einfachen dbt-Beispiel zu höherer Slot-Konkurrenz in Ascend führte (bedingt durch die threads-Einstellung in meiner dbt-Konfiguration).
Zur Probe habe ich meinen dbt-Pipeline-Lauf um die Option –threads:4 erweitert, um die Parallelität meiner dbt-Pipeline zu erhöhen. Im erneuten Lauf zeigte sich dann eine sehr ähnliche durchschnittliche Slot-pro-Sekunde-Performance von rund 4,3 Slots/Sek. – wegen der durch den parallelen Lauf etwas höheren Konkurrenz um Slot-Ressourcen.
Zur Auswertung dieser Statistiken habe ich die Beispielabfrage zur information_schema-View JOBS verwendet, um beide Pipelines zu prüfen (im begleitenden GitHub-Repo enthalten). Erwähnenswert ist allerdings, dass das Ascend-Interface bereits eine eigene Ansicht zur Messung der BQ-Slot-Auslastung und des Snowflake-Credit-Verbrauchs für Ascend-Pipelines mitbringt – wie im folgenden Screenshot zu sehen.
Szenarien für das Error Handling
Wir haben außerdem einige Error-Handling-Szenarien über beide Pipelines getestet, namentlich:
- Pipelines, die bei 70 % der Ladepunkte sowie mitten in den Transformationen angehalten wurden – durch eingebaute Fehler, die typische Bugs im Code oder in den eingelesenen Daten simulieren. Anschließend haben wir versucht, die Pipeline aus diesem Fehlerzustand neu zu starten, um das Verhalten zu beobachten.
- Hinzufügen einer neuen, fehlerhaften CSV-Datei zu den Pipelines, um sie absichtlich aus dem Tritt zu bringen.
Hier unsere Erkenntnisse aus den direkten Tests:
Error Handling in Ascend
- Sowohl der Ausfall an der 70-%-Marke eines Pipeline-Laufs als auch das Hinzufügen einer neuen, fehlerhaften CSV-Datei zum Bucket schlugen kontrolliert ("graceful") fehl. Ascend bietet uns erweiterte Einstellungen, um das Pipeline-Verhalten beim Auftreten solcher Fehler zu steuern. Auch die Wiederherstellung nach einem Fehler verlief in Ascend deutlich eleganter: Da jede Pipeline-Stufe materialisiert wird, konnte die Ausführung an der letzten vollständigen Komponente angesetzt und genau am Fehlerpunkt fortgesetzt werden. Damit ließen sich erhebliche Recompute-Kosten vermeiden, die ein vollständiger erneuter Pipeline-Lauf verursacht hätte.
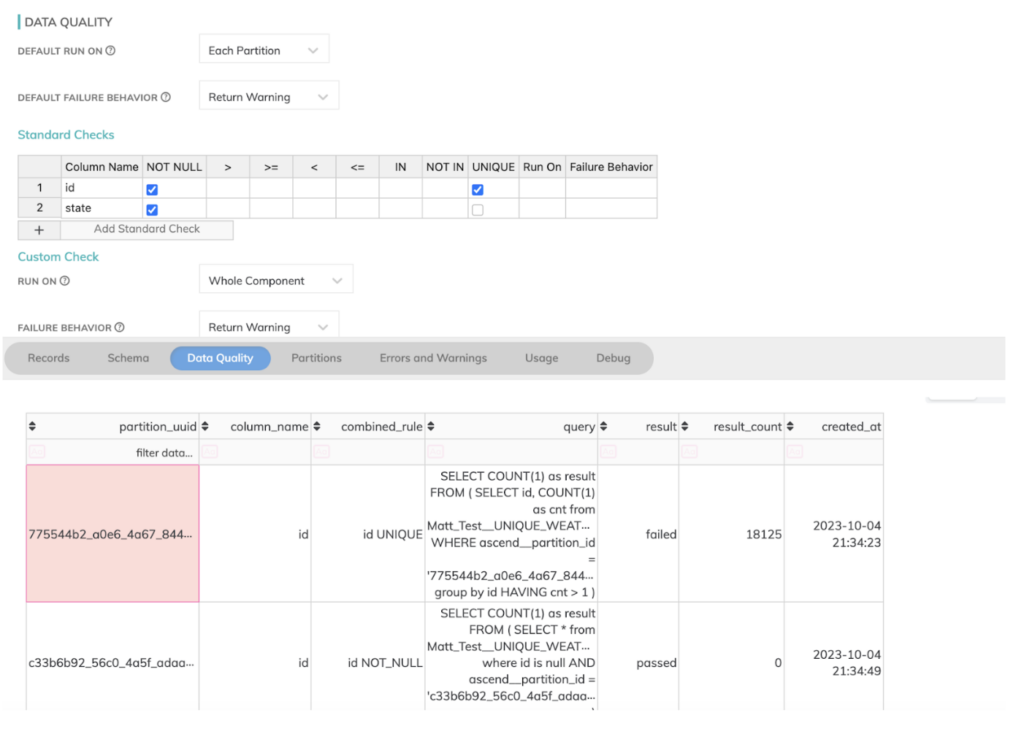
- Darüber hinaus stellt Ascend.io – ähnlich wie dbt – Datenqualitätsprüfungen bereit, die hilfreich sind, um Probleme in unseren fehlerhaften CSV-Dateien zu erkennen und sie aus dem System fernzuhalten. Das ist alles unter der Haube eingebaut und erfordert nur sehr wenig Zusatzkonfiguration, wie unten im Data-Quality-Tab von Ascend zu sehen, in dem ich einige fehlerhafte Feldwerte in unsere Quelldaten eingefügt hatte.
Error Handling in dbt
Die oben genannten Szenarien passten weniger gut zu dbt. Wir konnten Fehler zwar – ähnlich wie in der Ascend-Pipeline – in einer Error-Handling-Tabelle ablegen. Allerdings setzten diese Fähigkeiten den Download zusätzlicher dbt-Pakete voraus (insbesondere bietet das von catalogia bereitgestellte Paket dbt-expectations gute Funktionalität auf der Datenqualitätsseite – das sei hier explizit erwähnt). Und auch wenn wir einen Restart-Prozess in unserer Pipeline implementieren konnten, bedeutete das entweder einen manuellen erneuten Job-Lauf oder zusätzliche Fehler-Konfiguration in dbt Cloud in den Retry-Settings unserer Jobs.
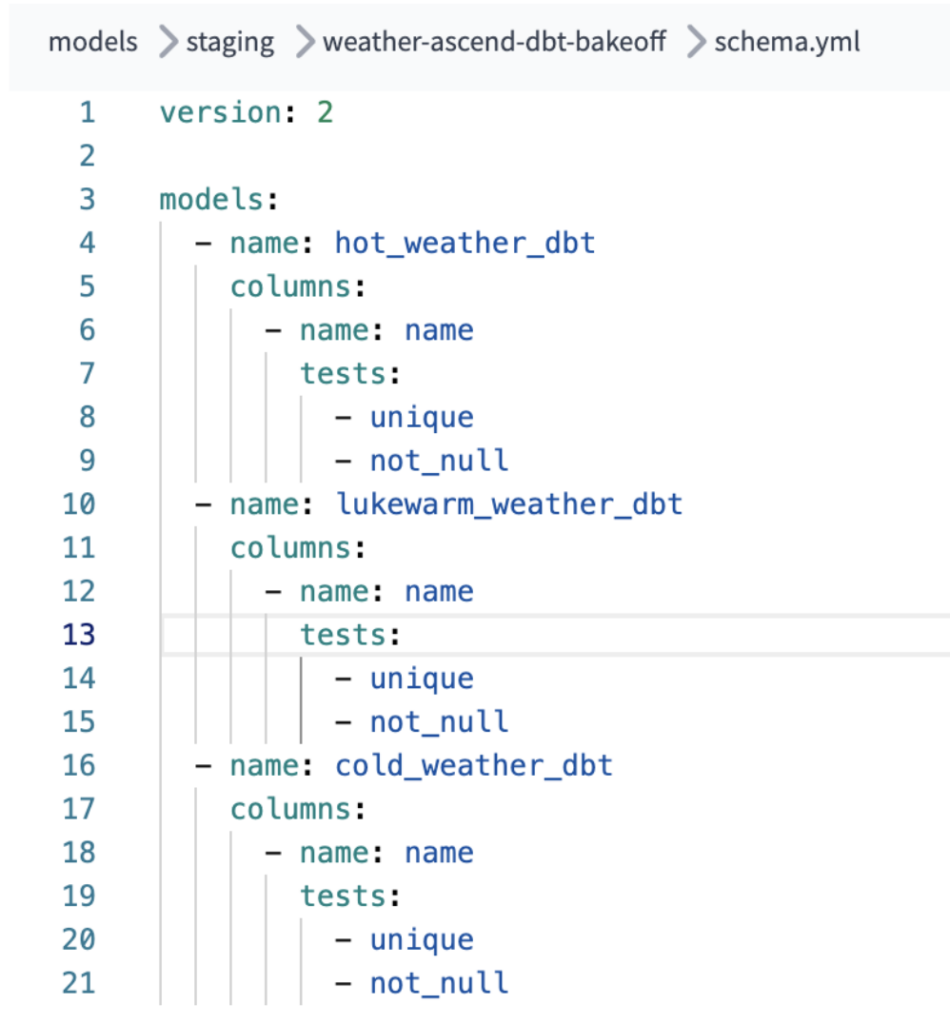
Außerdem war zusätzliche Konfiguration nötig, um Not-null- und Unique-Tests für jedes unserer dbt-Modelle zu ermöglichen, damit unsere dbt-Pipeline diese Prüfungen durchführt. Der Zusatzaufwand hielt sich zwar in Grenzen, könnte aber Engineers verwirren, die mit der Projektkonfiguration in dbt Core / dbt Cloud weniger vertraut sind.
Fazit
Aus unseren Tests an der Wetterdaten-Fallstudie in Ascend.io und dbt geht klar hervor, dass beide Dienste die Anforderungen typischer Datentransformations-Use-Cases erfüllen. Nach umfassenden Tests der nativen Funktionen beider Dienste sowie der Drittanbieter-Erweiterungen zeigt sich aber auch: Welches Toolset für Sie das richtige ist, hängt davon ab, welches besser zu Ihren Anforderungen passt.
Mit Ascend.io haben Sie ein All-in-one-Tool für Cloud Data Pipelines, das Ihre Daten-Pipelines unter der Haube automatisch optimiert und orchestriert. Es bietet eine benutzerfreundlichere UI, die den Aufbau von Pipelines für Engineers unterschiedlicher Erfahrungsstufen einfach und effizient macht. Integrierte Performance-Optimierungen sorgen dafür, dass Ihre Pipelines reibungslos laufen – ohne dass tiefgehendes Spezialwissen über Dateninfrastruktur oder stundenlange manuelle Coding-Arbeit nötig sind.
Ascend.io ist unserer Einschätzung nach für Ihre Cloud-Data-Pipeline-Anforderungen einen Test wert – insbesondere dann, wenn Ihre Datenmanagement-Prozesse von weniger Wartungsaufwand und weniger zu pflegenden Orchestrierungs-Tools profitieren würden. Die unkomplizierte Job-Einrichtung sowie die out-of-the-box verfügbaren Einstellungen zur Reduzierung der Cloud-Compute-Kosten machen Ascend zu einer starken Alternative zu code-fokussierten Tools wie dbt – je nach Use-Case.
Die in Ascend und dbt gebauten Pipelines aus diesem Artikel finden Sie zur Referenz im GitHub-Repository hier.