Comparamos cara a cara dos herramientas de transformación de datos para construir cloud data pipelines.

Casi todos los profesionales de datos han probado alguna herramienta de transformación, pero ¿cuál te conviene a ti?
Algunos de los retos más importantes que enfrentan los clientes de DoiT tienen que ver con la transformación y el procesamiento de datos provenientes de distintas fuentes hacia múltiples destinos.
Muchos de nuestros clientes usan servicios de Data Warehousing como Snowflake o Google BigQuery para almacenar y administrar sus datos. Quieren saber cómo gestionarlos de forma eficaz sin tener que ejecutar y mantener manualmente el código de sus data pipelines.
Antes, con bases de datos relacionales e infraestructuras tradicionales de data warehouse, este era el terreno de las herramientas ETL: soluciones como SSIS, Informatica o SAS Data Integration Studio se usaban para gestionar la extracción, transformación y carga de datos desde el origen hasta el destino, depositándolos en el data warehouse de preferencia.
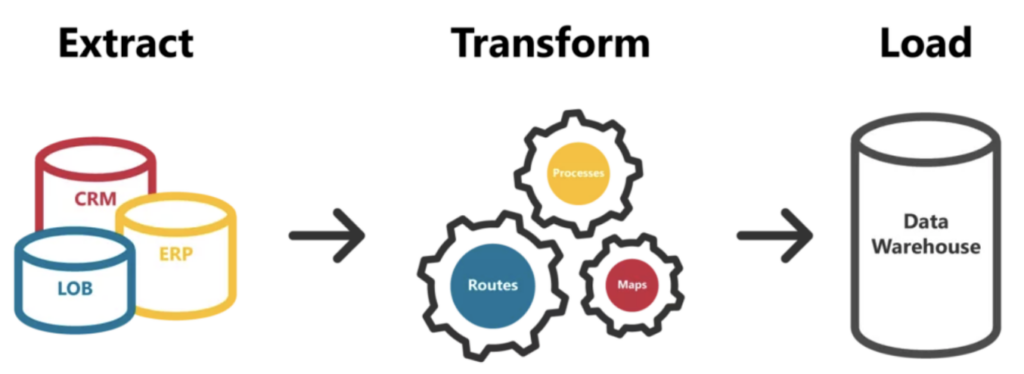
Pero la industria evolucionó con la aparición de los Cloud Data Warehouses como Snowflake, BigQuery, Redshift, etc. Estas plataformas de nueva generación, por su estructura y eficiencia, se adaptan mejor a un esquema ELT; manejan muy bien el trabajo de transformación cuando se ejecuta como workloads de pushdown directamente sobre el propio data warehouse. Esto vuelve innecesarias las herramientas mencionadas, ya que cada proveedor de nube suele tener su propia solución eficaz para la parte ‘EL’ del ELT y para cargar datos en los cloud data warehouses que admite de forma nativa.
¡Y aquí entra la herramienta de transformación!
En los últimos años, muchos de nuestros clientes han adoptado herramientas específicas de conexión de datos para encargarse de la extracción desde las fuentes, y herramientas de transformación para hacer los cálculos pesados dentro del data warehouse. Juntos, estos pasos de ingesta y transformación forman lo que hoy muchos llaman un cloud data pipeline.
Esto se traduce directamente en un mayor uso de herramientas como Fivetran para la primera parte de la solución y dbt para la segunda. Pero ¿y si existiera un conjunto alternativo de herramientas capaz de encargarse de la ingesta de datos en tus pipelines, ejecutar las transformaciones más exigentes y orquestar todo de forma eficiente, sin necesidad de sumar más herramientas como DAGs de Apache Airflow para coordinar tus jobs de transformación?
Conociendo Ascend.io
![]()
Ascend.io es un actor de peso en la Automatización de Data Pipelines, enfocado en construir los data pipelines más inteligentes del mundo.
Ascend es una plataforma única que detecta y propaga cambios a lo largo de tu ecosistema, asegura la precisión de los datos y cuantifica el costo de tus productos de datos. En definitiva, te permite gestionar y construir un pipeline de ingesta, ejecutar transformaciones complejas y orquestarlas como parte de un pipeline de negocio más amplio, ¡todo desde un solo lugar!
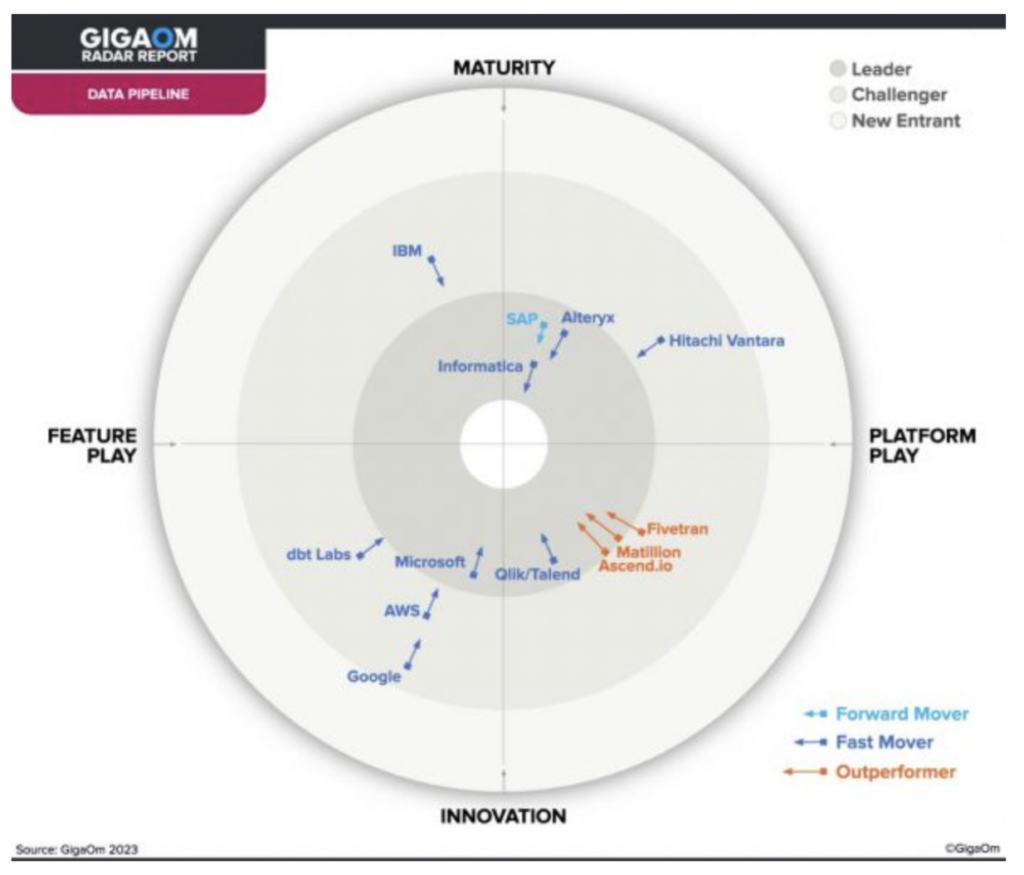
Un informe reciente de GigaOm identificó a Ascend como uno de los tres únicos líderes destacados en el espacio de Data Pipeline, lo que la convierte en una opción ideal para un data pipeline moderno.
El servicio de Ascend.io detecta cualquier cambio en tus fuentes y los propaga automáticamente a través de tu data pipeline mediante el Data Warehouse de tu preferencia, eliminando la necesidad de programar o ejecutar jobs manualmente para tus equipos.
Además, ofrece una integración de primer nivel con distintos proveedores de Data Warehouse mediante optimizaciones de tablas y vistas, como el particionamiento dentro de los propios dataflows de Ascend, optimizando el manejo de los datos a lo largo de tus pipelines en Ascend.
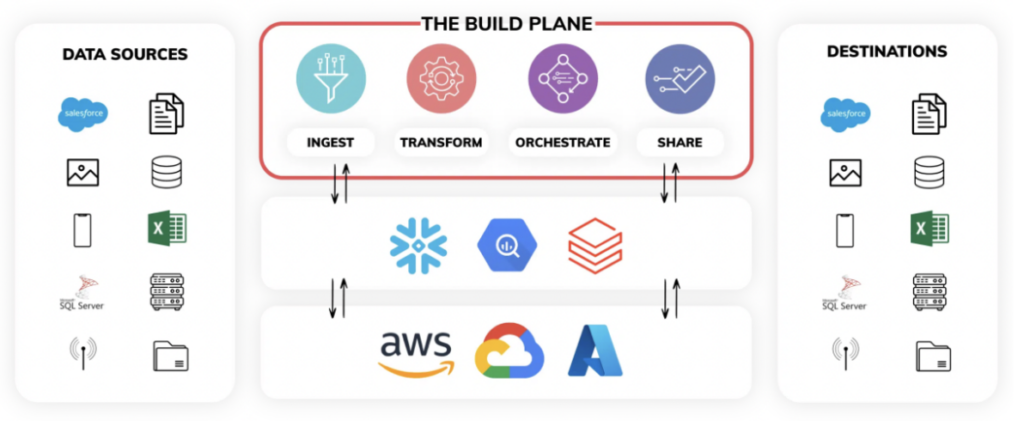
El servicio de data pipeline de Ascend, cuando se aprovecha al máximo, se compone de 3 planos principales:
- El Build Plane - Piensa en el build plane como un único panel de control para programar toda la lógica de ingesta y transformación del pipeline. También puedes programar pipelines en Ascend mediante código backend usando su SDK y CLI. La interfaz visualiza todo el linaje de datos y monitorea las operaciones en tiempo real.
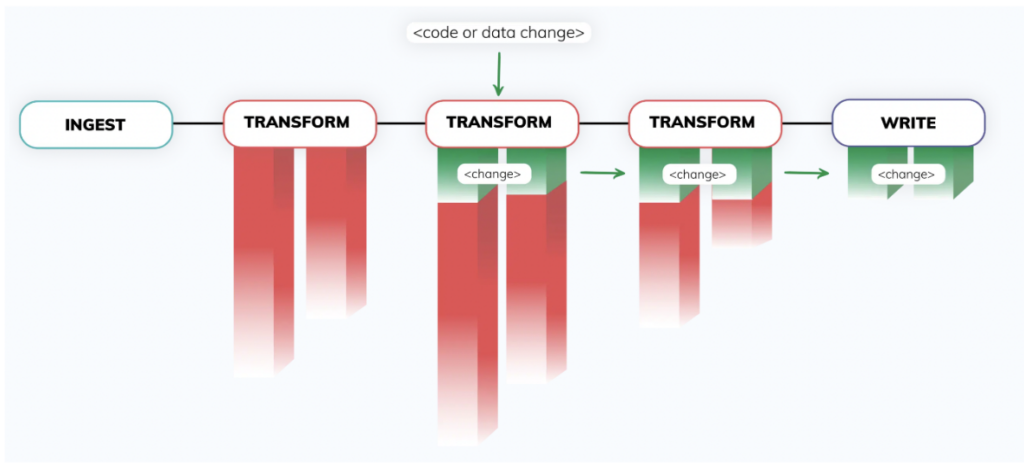
 2. El Control Plane - En el corazón de la plataforma Ascend hay un control plane sofisticado, impulsado por una tecnología única de fingerprinting. Este motor totalmente autónomo detecta de forma constante cambios en datos y código a lo largo de vastas redes de los data pipelines más complejos, y responde a esos cambios en tiempo real. Los data pipelines se mantienen sincronizados sin necesidad de código adicional de orquestación.
2. El Control Plane - En el corazón de la plataforma Ascend hay un control plane sofisticado, impulsado por una tecnología única de fingerprinting. Este motor totalmente autónomo detecta de forma constante cambios en datos y código a lo largo de vastas redes de los data pipelines más complejos, y responde a esos cambios en tiempo real. Los data pipelines se mantienen sincronizados sin necesidad de código adicional de orquestación.
- El Ops Plane - El ops plane de Ascend ayuda a integrar data pipelines inteligentes en el negocio. Aborda tres pilares clave de las operaciones de datos: aumenta la confianza del negocio, cuantifica los costos de procesamiento de datos y aporta transparencia. El ops plane monitorea las secuencias de workloads en tiempo real, a medida que los datos se ingieren y procesan a través de toda la red de pipelines vinculados.
Ascend hoy es compatible con las nubes de datos de Google BigQuery, Snowflake y Databricks, y la compatibilidad con otros servicios seguirá creciendo en el futuro cercano.
Sin duda es un servicio para tener muy en cuenta en workloads de cloud data pipeline, gracias a su potente motor de automatización y a que admite tanto desarrollo basado en UI como en código. ¡Nos entusiasma profundizar en cómo usarlo!
Conociendo dbt
![]()
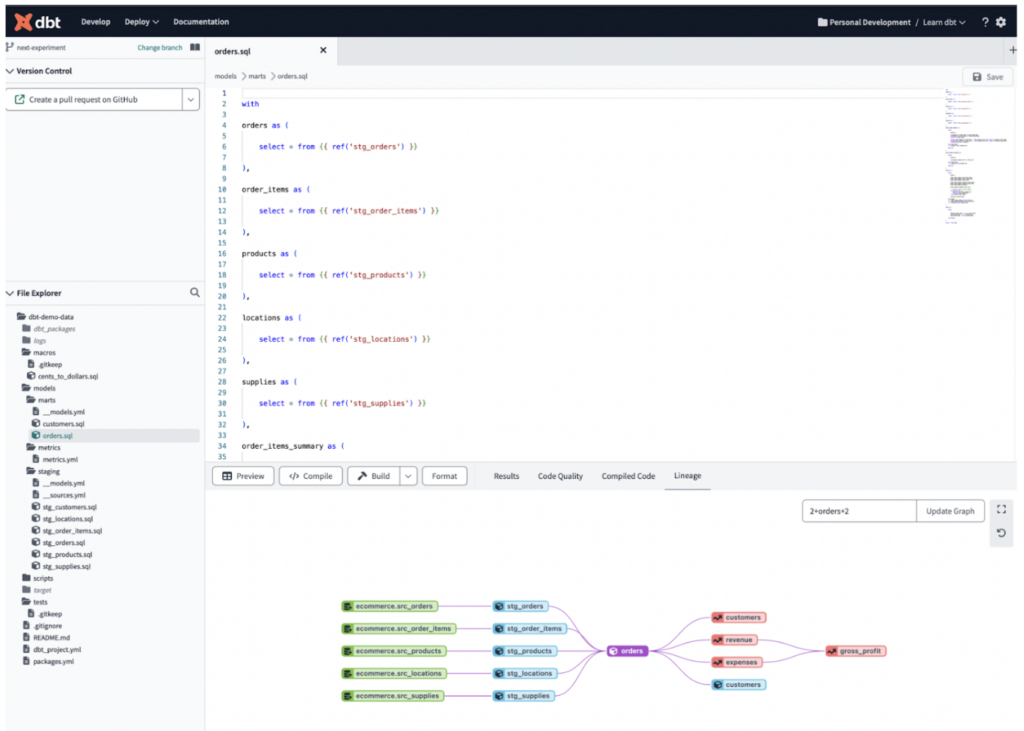
dbt es una herramienta de pipeline de transformación basada en SQL que permite a los equipos desplegar código de analítica de forma rápida y colaborativa, siguiendo buenas prácticas de ingeniería de software como modularidad, portabilidad, CI/CD y documentación. Permite que los equipos colaboren en tareas de desarrollo a través de repositorios y se ha posicionado como una herramienta muy popular en el mercado en los últimos años.
dbt viene en dos formatos:
- El servicio dbt Cloud: una versión de dbt basada en UI que también gestiona directamente el despliegue y la ejecución de modelos dbt. Tiene una versión gratuita para usuarios individuales y distintos rangos de Precios para equipos de desarrolladores.
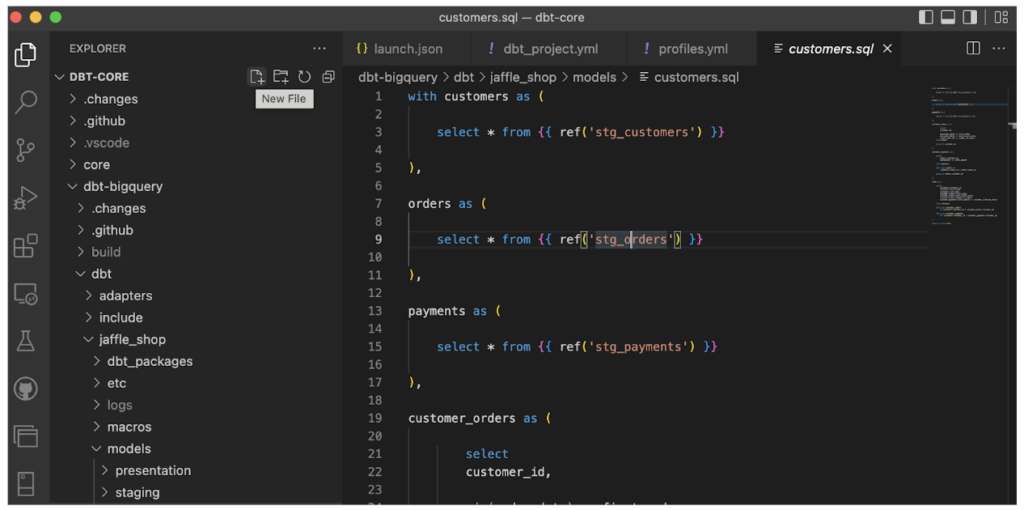
- dbt Core: la versión basada en código de dbt, gratuita y compatible con la mayoría de IDEs como Visual Studio Code, por ejemplo. Al igual que dbt Cloud, también puede vincularse al repositorio que prefieras y orquestarse junto con herramientas como Apache Airflow para coordinar tus data pipelines.
Además de coordinar el desarrollo y despliegue de distintos jobs de transformación, dbt te permite ejecutar pruebas unitarias sobre tus datos y ofrece linaje de datos a través de sus funciones de catalogación, lo que facilita enormemente documentar el flujo end-to-end de tus pipelines ELT.
dbt es compatible con varias soluciones de Data Warehousing y Data Lake, incluidas Snowflake, BigQuery, Redshift, Databricks y Starburst, lo que la hace una opción popular entre grandes empresas que utilizan varias de ellas.
El DoiT Bake-Off: nuestra evaluación
Está claro que tanto Ascend como dbt son herramientas eficaces para la transformación de datos y cada una tiene sus propias ventajas, pero ¿cuál se adapta mejor a un caso de uso típico de data pipeline? Seguimos los siguientes pasos para hacer un bake-off entre ambos servicios.
Nuestro escenario: la recopilación y transformación masiva de datos meteorológicos diarios del mes de agosto, con millones de registros ingeridos desde Google Cloud Storage, ejecutados luego a través de data pipelines en Snowflake y Google BigQuery por separado, tanto en Ascend.io como en dbt Cloud.
Nuestro pseudo pipeline tendrá los siguientes pasos estándar:
- Leer los datos meteorológicos diarios crudos desde el Data Warehouse de preferencia y combinar varios extractos diarios en una única tabla para análisis posteriores.
- Segmentar estos datos en distintas categorías (clima caliente, templado y frío respectivamente), aplicando transformaciones básicas sobre el dataset combinado para lograrlo.
- Aplicar transformaciones más avanzadas de agregación y estadísticas sobre los datasets divididos. Además, unir los datos transformados con una tabla de búsqueda de ubicaciones que contiene códigos de localización para nuestras zonas meteorológicas.
- Llevar los datasets finales a una capa pseudo data mart/de presentación en los data warehouses elegidos.
En nuestro caso, primero queremos comparar el tiempo que toma construir estos procesos desde la perspectiva de un desarrollador, tanto en Ascend.io como en dbt, ya que una variable clave para el rendimiento de tu equipo es cuánto tiempo se invierte en construir tus soluciones de datos.
Una vez construidos los jobs, queremos evaluar las siguientes áreas para nuestra valoración del bake-off y el costo total de propiedad de cada solución:
- Los tiempos de ejecución del conjunto completo de data pipelines, de inicio a fin (usando tanto hot starts como cold starts en el pipeline de Ascend, debido a la infraestructura de Spark subyacente)
- Los créditos consumidos (en Snowflake) y los bytes escaneados (en BigQuery) en ambos data pipelines
- El manejo de errores: introduciremos fallas en ambos pipelines e investigaremos las soluciones de recuperación de cada uno
- La incorporación de nuevos archivos de datos meteorológicos a los data pipelines y su consecuente re-ejecución para actualizar los datasets, con el fin de evaluar el rendimiento de cada pipeline cuando se ingieren datos nuevos
- El nivel de interacción y control sobre los Data Warehouses subyacentes; es decir, detener Virtual Warehouses en Snowflake, particionamiento automático dentro de los jobs de Ascend y muchas otras tareas comunes de orquestación de pipelines
Con las reglas del juego ya definidas para este bake-off, ¡desarrollemos el escenario y veamos cómo se enriquecen nuestros datos meteorológicos en ambas soluciones!
El DoiT Bake-Off: armando nuestro caso
Recorramos el proceso de desarrollo desde el lado de Ascend y desde el de dbt.
Para nuestro caso de estudio, tomamos los datos meteorológicos de los datasets públicos ghcn_d de Google.
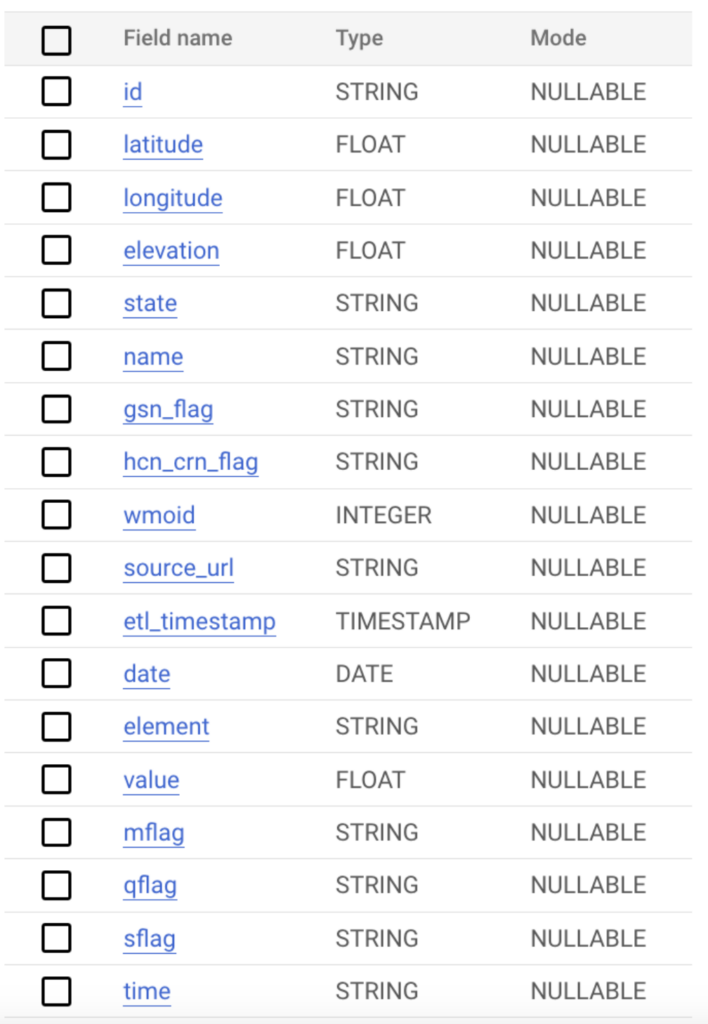
Para tener un buen volumen de datos, seleccionamos todos los campos y creamos archivos diarios entre el 1 y el 31 de agosto de 2023 inclusive, según la consulta de abajo.
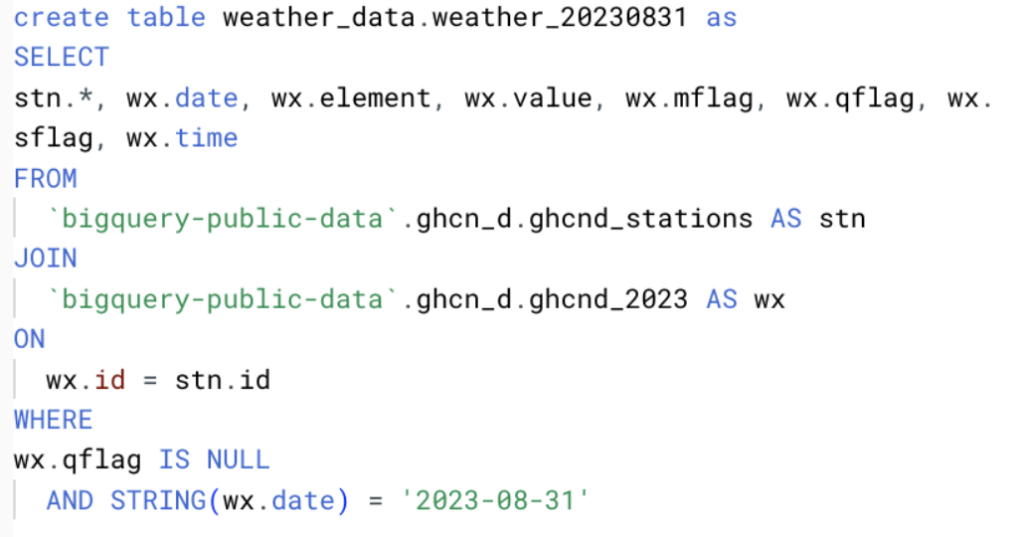
Los datos en este caso tienen el siguiente esquema y millones de registros en total. Para probar varios escenarios, almacenamos estos datos en tablas de BigQuery y en Google Cloud Storage, con el fin de evaluar distintos métodos de ingesta entre las plataformas.
Proceso de desarrollo en Ascend
En Ascend.io puedes crear un data pipeline mediante Dataflows, que a su vez se almacenan dentro de Data Services, lo que te brinda un modelo de seguridad compartido para tus distintos data pipelines, como puedes ver en nuestro entorno de pruebas.
Los Dataflows de Ascend te ofrecen distintos componentes de ingesta/lectura, transformación y entrega/escritura que puedes usar en cada paso de tu pipeline.
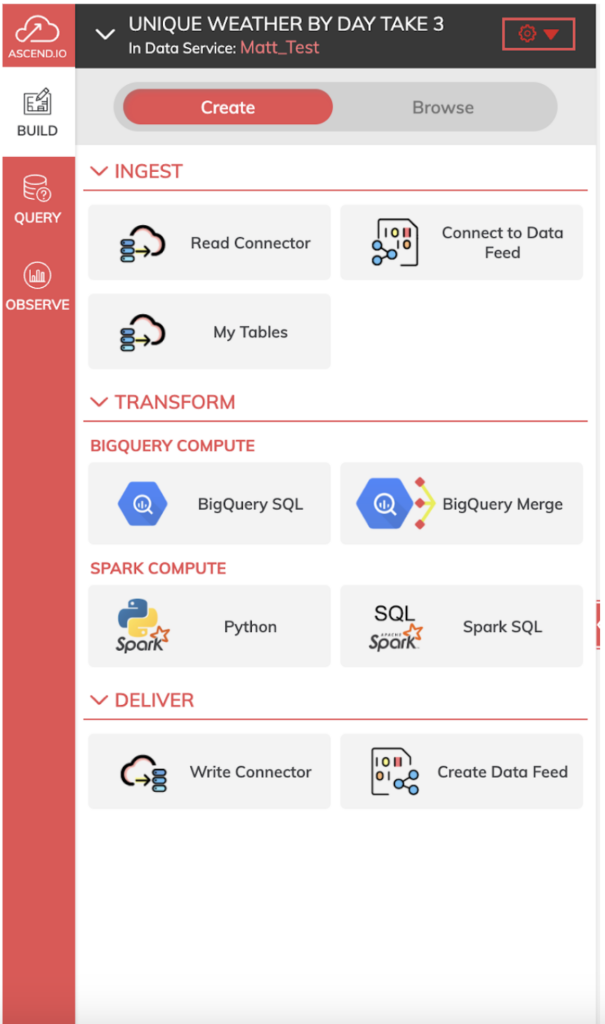
Para nuestro pipeline, primero queremos usar Read Components para ingerir los archivos iniciales de datos meteorológicos, ya sea desde GCS o directamente desde BigQuery.
Luego usamos componentes de transformación para dar forma a nuestros datos según el proceso. Para este bake-off usé BigQuery SQL, ya que es el sabor de SQL con el que estoy más familiarizado, pero tienes a tu disposición varios lenguajes como Python, Spark SQL o SnowSQL (si está habilitado) para construir tus transformaciones en Ascend.
Por último, usamos un componente de escritura para llevar el resultado del pipeline totalmente transformado de vuelta al data warehouse elegido.
El pipeline que se muestra abajo es el que armé para este bake-off. Está compuesto por tres rutas de datos para distintos grados de escenarios de clima caliente/frío en nuestro análisis final:
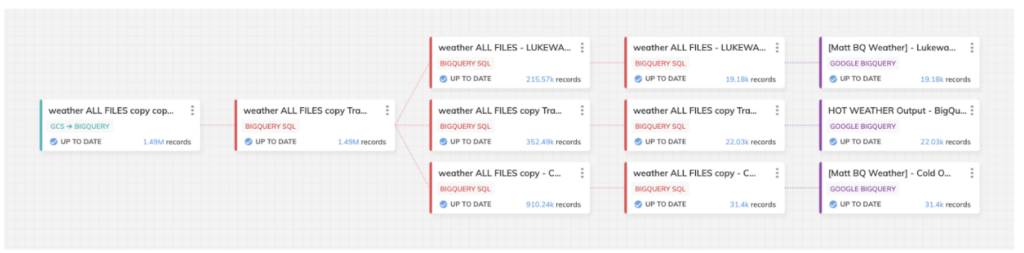
El diseño de este pipeline fue el mismo tanto en BigQuery como en Snowflake, pero la captura de pantalla corresponde a la plantilla diseñada para BigQuery.
Para nuestro read connector, primero quisimos configurar la conexión con los archivos en nuestro bucket de GCS (Google Cloud Storage). Para ello, necesitamos una service account con acceso al bucket en cuestión.
Como tenemos varios archivos meteorológicos, podemos especificar un prefijo para ellos en Ascend, de modo que sepa que debe ingerir todos los archivos con convenciones de nombre similares para nuestro pipeline.
También cargamos filas de encabezado en nuestros archivos CSV, así que necesitamos especificar la opción para excluirlas dentro del componente de lectura de Ascend.
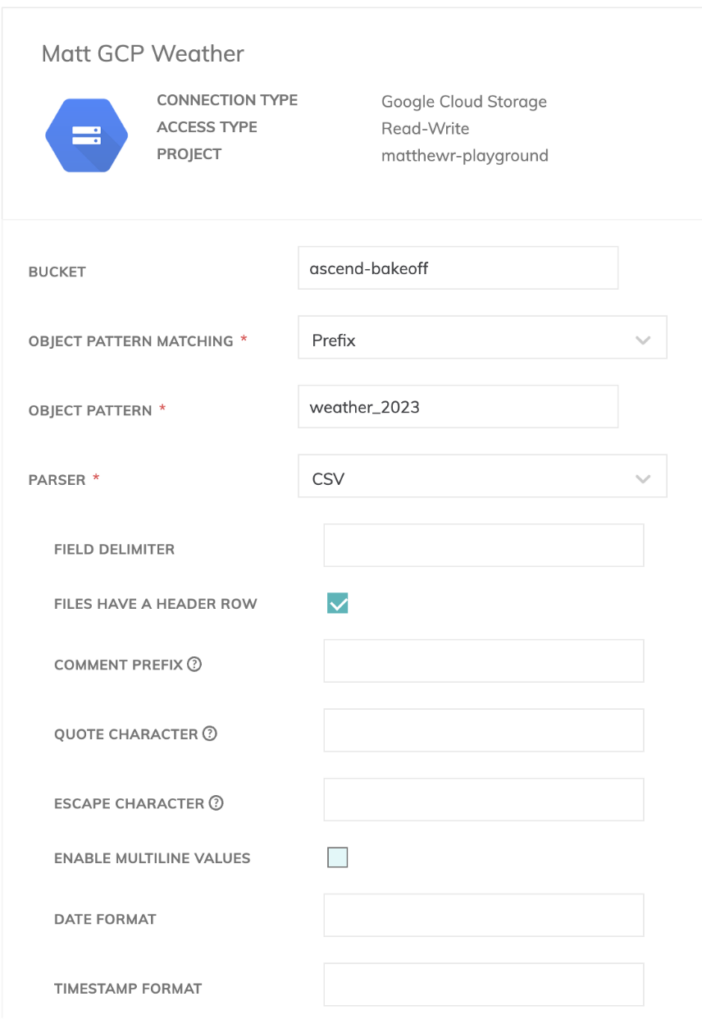
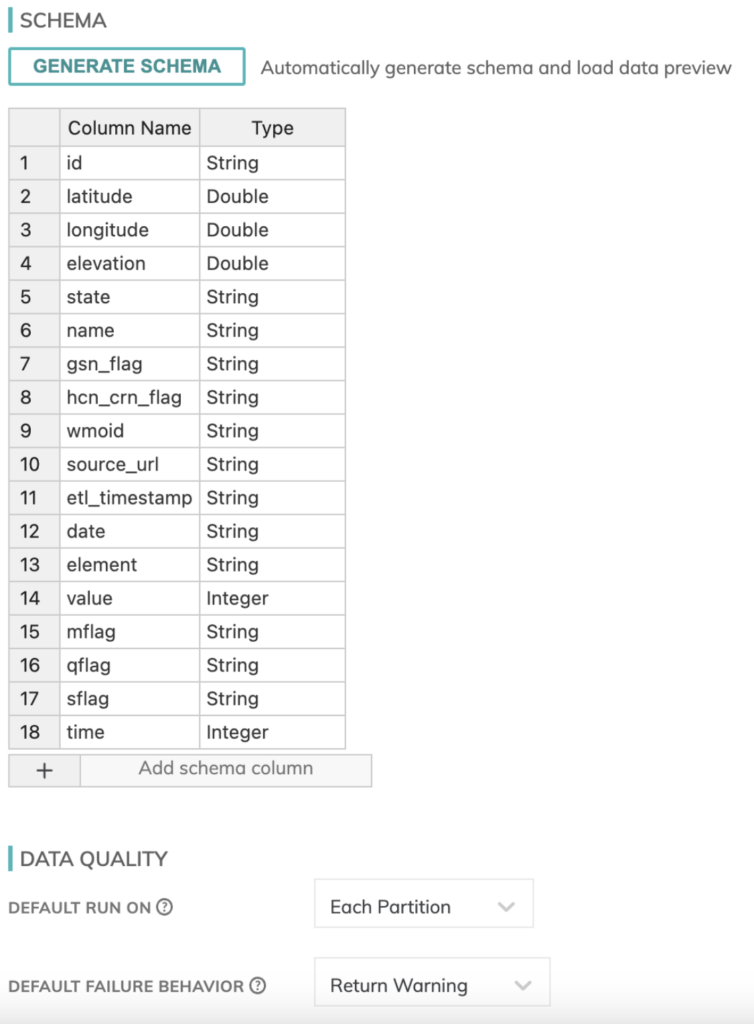
También necesitamos definir un esquema para nuestros datos meteorológicos. Por suerte, Ascend cuenta con un detector de esquemas integrado en los componentes de lectura, así que armarlo fue bastante sencillo.
Aquí también puedes definir validaciones de calidad de datos y comportamientos ante fallas, para gestionar tus jobs de inicio a fin.
Otra función interesante que ofrece la plataforma Ascend es el particionamiento de datasets específico de cada pipeline. Esto segmenta tus datos en bloques con sentido y los procesa de forma independiente, acelerando el throughput de tus data pipelines dentro del data warehouse de tu preferencia.

Como puedes ver en un subconjunto de 20 días de nuestros datos, las particiones quedan segmentadas: una por cada día de nuestros archivos meteorológicos.
En cuanto a las transformaciones, configurarlas en Ascend también fue sencillo. Solo necesitas especificar el lenguaje que prefieras y escribir el código en la ventana principal del componente, como se ilustra a continuación.
Vale la pena destacar que, al igual que el lenguaje de macros de dbt, Ascend usa lógica Jinja para referenciar nombres de componentes de pasos previos del pipeline. Los desarrolladores familiarizados con este estilo se sentirán cómodos en cualquiera de las dos plataformas.
Para no extender demasiado esta sección, agregué aquí solo un componente básico de transformación a modo de ilustración. Pero ten en cuenta que añadimos una guía de referencia completa de las transformaciones construidas para este pipeline de ejemplo en un repositorio de GitHub, vinculado al final de este post.
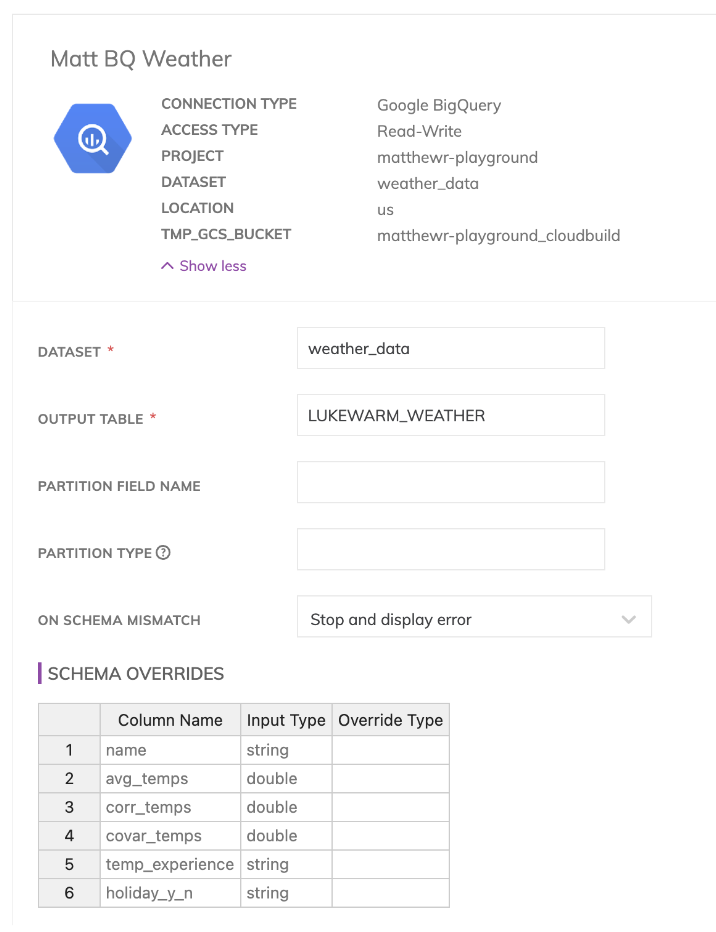
Por último, para nuestros componentes de escritura o de "reverse-ETL", nuevamente necesitamos especificar una conexión hacia nuestro data warehouse en BigQuery.
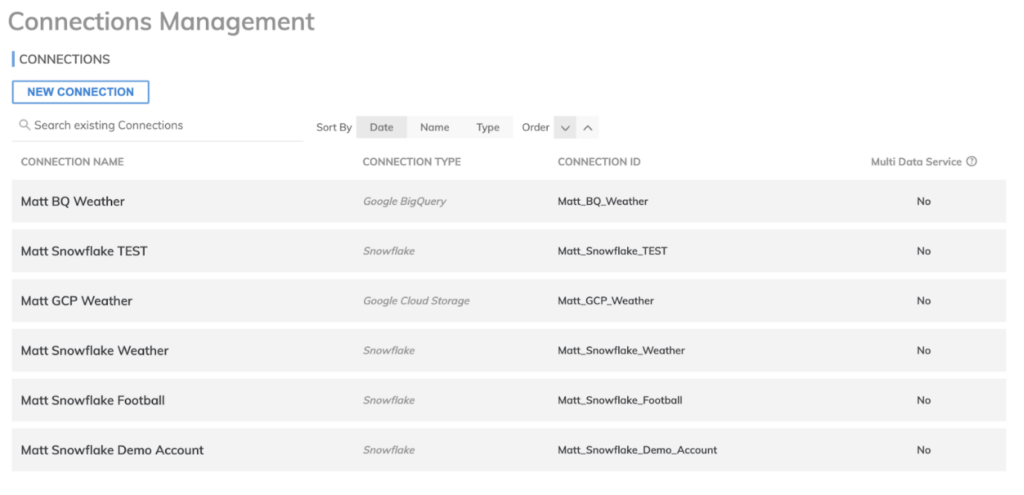
Nuestras conexiones se pueden configurar dentro del área de Admin en Ascend.io, como se ve aquí. Son fundamentales tanto para los componentes de lectura como de escritura, y Ascend.io admite distintas conexiones, como data warehouses Snowflake o BigQuery, o buckets de almacenamiento en cualquier nube.
A partir de ahí, los componentes de escritura son bastante sencillos. Solo necesitas especificar una conexión, el layout del esquema de salida, luego el nombre de la tabla de salida en el data warehouse elegido y cualquier opción adicional específica de la nube (como el nombre del dataset en BigQuery o el schema en Snowflake).
Ten en cuenta que Ascend funciona materializando los datos en cada paso de transformación del pipeline en los dataplanes de Snowflake o BigQuery por defecto. Por eso no es estrictamente necesario crear un conector de salida hacia el data warehouse, pero está disponible por si quieres hacer ajustes finales al esquema que no impliquen otra lógica de transformación.
En cuanto al esfuerzo total de desarrollo, a pesar de los varios pasos que parece tener mi proceso y la explicación aquí, este pipeline me tomó alrededor de 10 minutos en construirse en total e incluye el tiempo dedicado a configurar las conexiones a GCS, BigQuery y Snowflake en mis cuentas playground de Ascend.io para esta demo.
Vale la pena mencionar que cada vez que se agregaban nuevos archivos meteorológicos, conforme a nuestras reglas de juego originales, eran detectados automáticamente por nuestro data service de Ascend y el pipeline podía re-ejecutarse a voluntad sobre los nuevos archivos/datos.
Lo bueno de Ascend para este tipo de caso de uso es que, una vez configurado, mi pipeline requiere muy poco mantenimiento durante el resto de su ciclo de vida. Realmente no necesita mucho trabajo adicional para cambiar la lógica o agregar nuevos pasos al proceso. Cuando ocurren estos cambios, el controlador de automatización los detecta y descubre automáticamente qué secciones del pipeline deben volver a ejecutarse y qué particiones del dataset necesitan refrescarse. Y aún más impresionante: esto puede ocurrir en varios pipelines interconectados, lo que significa que un solo cambio de modelo será orquestado automáticamente por el servicio, disparando docenas de jobs de procesamiento y DAGs sin que yo tenga que hacer nada. ¡Un gran punto a favor del servicio Ascend!
Proceso de desarrollo en dbt
Para el lado dbt de este bake-off usé el servicio dbt Cloud con mi cuenta gratuita. Parecía la opción más natural porque dbt Cloud trae su propia orquestación integrada y no requiere un servicio de terceros como Airflow, lo que ofrece una comparación más justa frente a la experiencia integrada de Ascend.
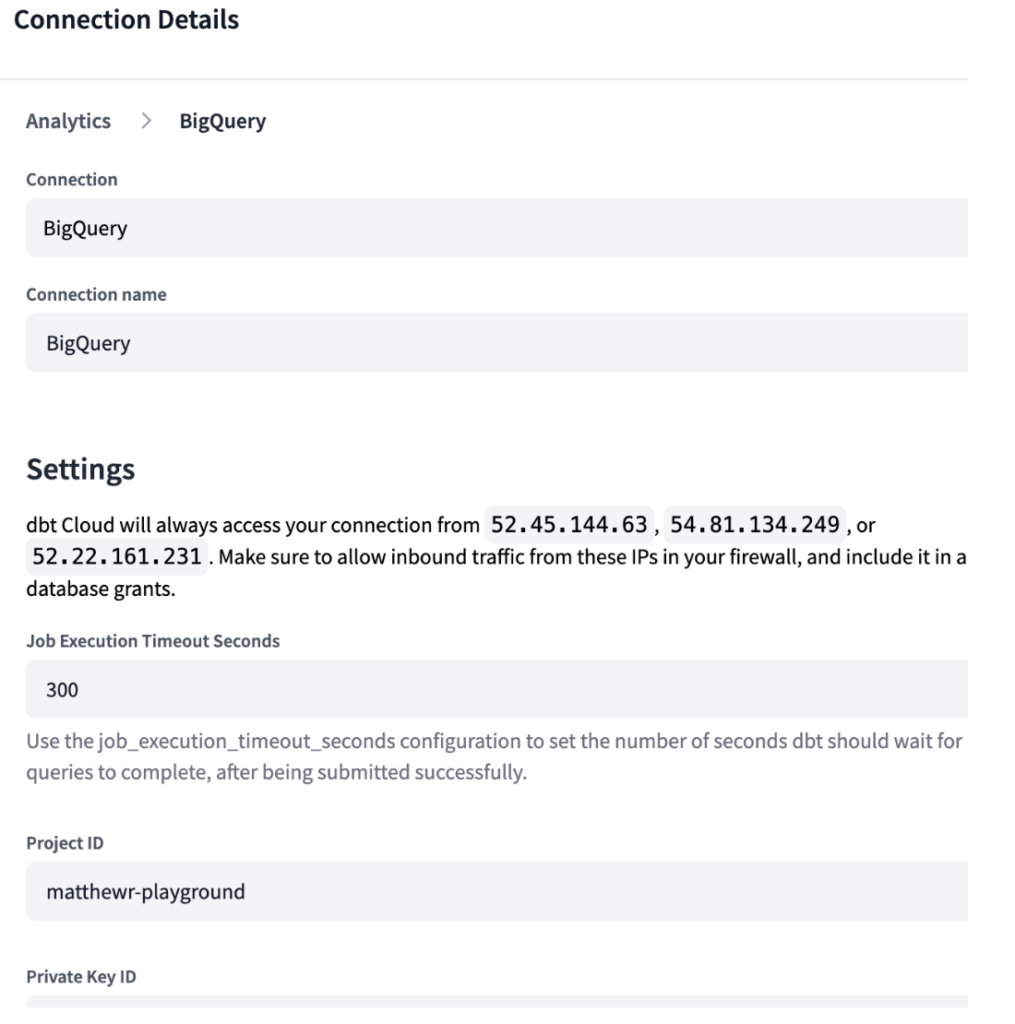
Al igual que en Ascend, en dbt Cloud necesitas especificar tu entorno de desarrollo. Como dbt está diseñado para conectarse al data warehouse de tu preferencia, tuvimos que crear conexiones tanto para nuestro entorno de BigQuery como para el de Snowflake, con las credenciales necesarias como se muestra abajo.
dbt cuenta con varios directorios que conforman la infraestructura de sus pipelines, incluidos Models (que contienen los jobs SQL ejecutados en tu DWH de preferencia), Tests (con pruebas unitarias contra dichos modelos), Macros (con lógica reutilizable para tus jobs) y Seeds, entre otros.
Para los efectos de este pipeline, replicamos en dbt la misma lógica de nuestro pipeline en Ascend mediante varios archivos de modelo .sql, para reproducir el mismo proceso.
Aquí abajo se muestra una vista del DAG de nuestro proceso construido en dbt para la lógica del bake-off:

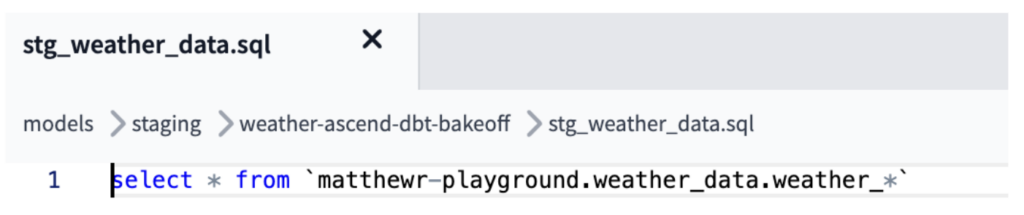
En este caso, para replicar la ingesta y combinación de los archivos CSV que obtenemos con los read connectors de Ascend, el modelo "stg_weather_data" en dbt combinó los múltiples archivos/tablas fuente usando lógica de external source en el caso de GCS, o lógica de wildcard desde BigQuery para unificar todos nuestros datos en un solo archivo, tal como en el job equivalente de Ascend (como se muestra abajo).
Esto permitió manejar el escenario de archivos adicionales agregados que mencionamos en nuestras reglas de juego, ya que la cláusula wildcard está diseñada para detectarlos a medida que se cargan nuevos archivos en BigQuery (o la lógica puede modificarse para detectar nuevos archivos agregados a GCS).
Luego creamos varios modelos dbt en distintos directorios para las capas de Staging/Mart del data warehousing, con la tabla mart final usada en nuestro ejemplo para generar la tabla equivalente en nuestros data warehouses de BigQuery o Snowflake, respectivamente. Esto nos permite obtener los mismos resultados con exactamente la misma sintaxis SQL que en nuestras corridas en Ascend, para una comparación de bake-off realmente justa.
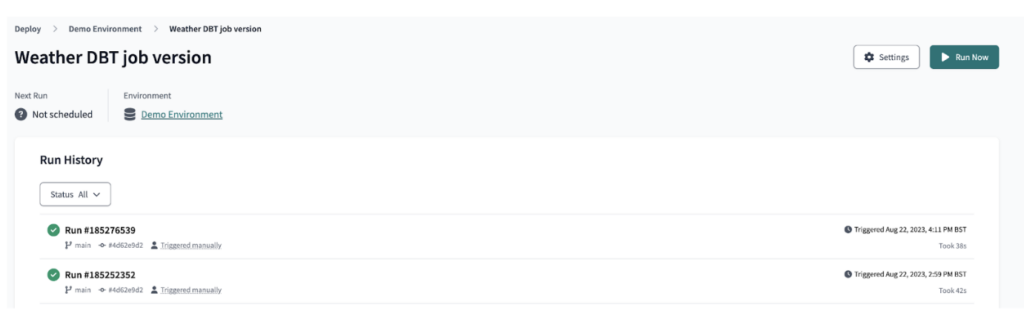
Usando dbt Cloud, luego desplegamos la salida de dbt como un job, que se utilizó para orquestar la ejecución del pipeline dbt como se ilustra.
Como consecuencia de configurar la orquestación del job en dbt Cloud, el tiempo total de desarrollo resultó ligeramente mayor que el del pipeline equivalente en Ascend. Además, al ser dbt una solución basada en código, también se necesitó tiempo extra para configurar la parte estándar de ingesta del pipeline (mediante archivos .yml) y la salida de la tabla final de la capa de presentación, que en el pipeline de Ascend ya venía integrada en el write connector.
Este pipeline equivalente tomó alrededor de 20 minutos en construirse en dbt.
También cabe destacar que, a diferencia de Ascend, dbt no cuenta con mecanismos automatizados para dividir tus datos en particiones durante la ingesta. Tampoco tiene la capacidad de detectar archivos adicionales agregados a tu bucket de origen e iniciar nuevas ingestas batch incrementales poco después de detectarlos (ya sea en GCS o en BigQuery).
Puedes aplicar particionamiento y clustering de BigQuery en tus archivos .yml de dbt, pero esto requiere configuración adicional y no es equivalente a las particiones de ingesta creadas automáticamente en Ascend.
Adicionalmente, aunque la lógica de manejo de errores en dbt está soportada mediante distintos paquetes como Great Expectations, esto también es algo que debes configurar instalando esos paquetes. También se requiere un buen conocimiento de la sintaxis de macros de estos paquetes para incorporar esta lógica en tus jobs, en lugar de un simple set de checkboxes como ofrece Ascend.
El DoiT Bake-Off: resultados
Y ahora, el momento que todos esperábamos. ¡A hornear!
Nuestras pruebas de ambos pipelines, de inicio a fin, arrojaron los siguientes resultados de rendimiento:
Tiempos de ejecución
"Cold Start" - tiempos promedio de la primera ejecución de los pipelines completos
- Ascend: 2 min 6 segundos
- dbt: 47 segundos
A grandes rasgos, en los tiempos iniciales se ve que el pipeline en dbt Cloud fue más rápido en la corrida cold-start. Pero esto probablemente se debe a la infraestructura subyacente de los pipelines de Ascend, donde los clusters de Kubernetes se levantan al vuelo para ejecutar los jobs y se dejan inactivos entre ejecuciones para reducir costos de cómputo.
Por eso hicimos otra medición para tener una comparación de manzanas con manzanas en un escenario de hot-start, cuando los clusters de Ascend ya estaban levantados.
"Hot Start" - tiempo promedio de las ejecuciones posteriores de los pipelines completos
- Ascend: 10 segundos
- dbt: 32 segundos
Las ejecuciones posteriores mostraron a Ascend mucho más rápido, con los mismos volúmenes de datos y el mismo código de transformación corriendo en ambos pipelines. Esto se debe probablemente a la naturaleza dinámica y paralelizada de los clusters de Ascend, lo que permite que el procesamiento de cada paso individual sea multi-threaded y, en consecuencia, mucho más rápido.
Comparación de Snowflake Credits consumidos y BigQuery Bytes
Snowflake credits por job
En cuanto a los Credits consumidos a lo largo de los pipelines completos para Ascend y dbt, los segmentamos para que cada uno usara distintos schemas dentro de nuestra base de datos Snowflake en el bake-off. En concreto, el pipeline de Ascend usó las conexiones "sources_ascend" y "ascend_t_conn", mientras que el pipeline de dbt usó los schemas "dbt_mrichardson" y "public".
El pipeline de Ascend fue notablemente más eficiente que el de dbt en cuanto a Snowflake credits consumidos. La cantidad total de credits utilizados fue:
- Consumo del pipeline Ascend = 61.165 + 28.071 = 89.236 credits
- Consumo del pipeline dbt = 1924.652 + 33.685 = 1958.337 credits

Esta amplia brecha desde la perspectiva de Snowflake se debe en parte a las capacidades de particionamiento que Ascend aplicó sobre nuestros datos meteorológicos. Como cada archivo se propagó de forma incremental sin requerir una reducción completa en la ingesta, se necesitó mucho menos cómputo para correr el pipeline y, de manera similar, durante su desarrollo. La diferencia también puede atribuirse a otras funciones de ahorro de costos y gestión de cómputo de la plataforma Ascend, como apagar los Snowflake Virtual Warehouses tan pronto el pipeline termina su procesamiento, evitando acumular tiempo de actividad innecesario.
BigQuery slots usados por job
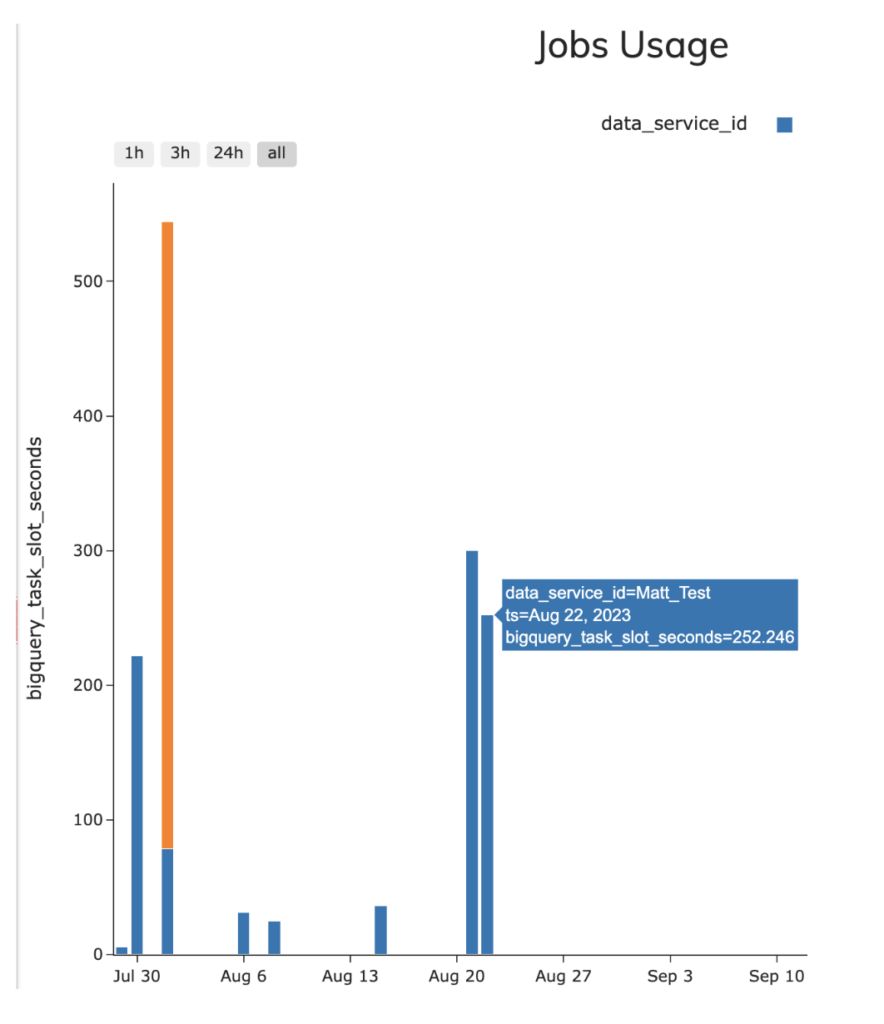
- Ascend - 4.18 slots promedio por segundo (252.46 slot seconds totales)
- dbt - 3.2 slots promedio por segundo (189.34 slot seconds totales)
En el frente de BigQuery, encontramos que ambos pipelines pudieron ejecutar los jobs de BigQuery de forma bastante eficiente desde la perspectiva de slots, siendo dbt Cloud levemente más eficiente en promedio durante la ejecución. Al revisar la razón detrás de esta pequeña diferencia en el uso de slots, esto se explica por la naturaleza de la configuración de ejecución de mi Data Service en Ascend frente a mi DAG de prueba construido en dbt, en términos del paralelismo de cada corrida; el primero ejecutó más pasos de mi pseudo proceso ETL en paralelo, generando una mayor contención de slots en Ascend frente a dbt en mi ejemplo básico (debido a la asignación de threads en mi configuración de dbt).
Para verificarlo, ajusté mi corrida del pipeline dbt agregando la opción –threads:4 para ampliar el paralelismo del pipeline y observé un rendimiento promedio de slots por segundo muy similar, alrededor de 4.3 slots por segundo, debido a la contención ligeramente mayor por recursos de slots cuando el pipeline se ejecutó nuevamente.
Para revisar esas estadísticas usé la consulta de muestra information_schema desde la vista JOBS para probar ambos pipelines (incluida en el repositorio de GitHub adjunto), aunque vale la pena destacar que en la interfaz de Ascend se incluye la siguiente vista para medir la utilización de BQ Slots y el consumo de Snowflake Credits para los pipelines ejecutados desde Ascend, como se muestra en la captura.
Escenarios de manejo de errores
También probamos algunos escenarios de manejo de errores en ambos pipelines, en particular:
- Pipelines detenidos al 70% de los puntos de carga del pipeline y también a mitad de las transformaciones, introduciendo errores que simulan bugs típicos en el código o en los datos ingeridos. Luego intentamos reiniciar el pipeline desde esa falla y observar qué pasaba.
- Agregar un nuevo archivo CSV con errores a los pipelines para hacerlos fallar deliberadamente.
Esto fue lo que encontramos al probar estos escenarios directamente.
Manejo de errores en Ascend
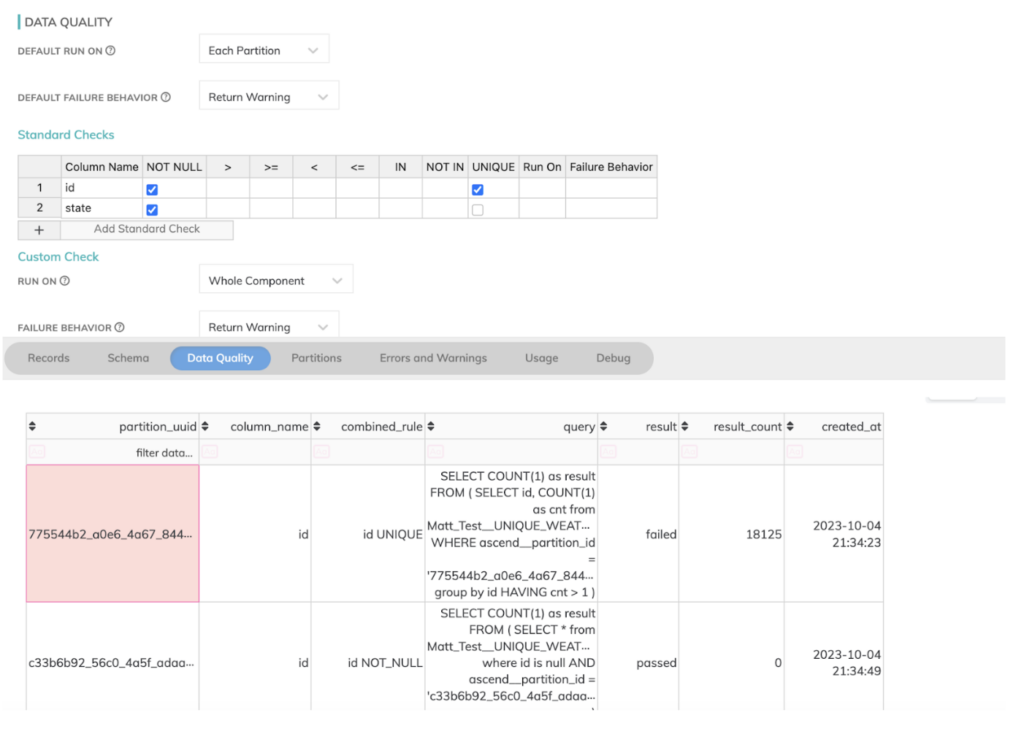
- Tanto el escenario de fallar al 70% de la corrida como el de agregar un nuevo CSV malformado al bucket fallaron de forma controlada. Ascend nos brinda configuraciones avanzadas para controlar el comportamiento del pipeline cuando ocurren este tipo de errores. La recuperación ante una falla en Ascend también fue mucho más elegante. Gracias a la materialización de cada etapa del pipeline, fue capaz de reanudar simplemente desde el último componente completo y reiniciar justo en el punto de la falla. Esto evitó una cantidad significativa de re-cómputo que habría sido necesario si se tuviera que volver a ejecutar el pipeline completo.
- Además, al igual que dbt, Ascend.io también ofrece validaciones de calidad de datos útiles para detectar problemas en nuestros archivos CSV defectuosos y evitar que entren al sistema. Todo esto está integrado y requiere muy poca configuración adicional para aprovecharlo, como se muestra abajo en la pestaña de calidad de datos de Ascend, donde inserté algunos valores de campo erróneos en nuestros archivos de origen.
Manejo de errores en dbt
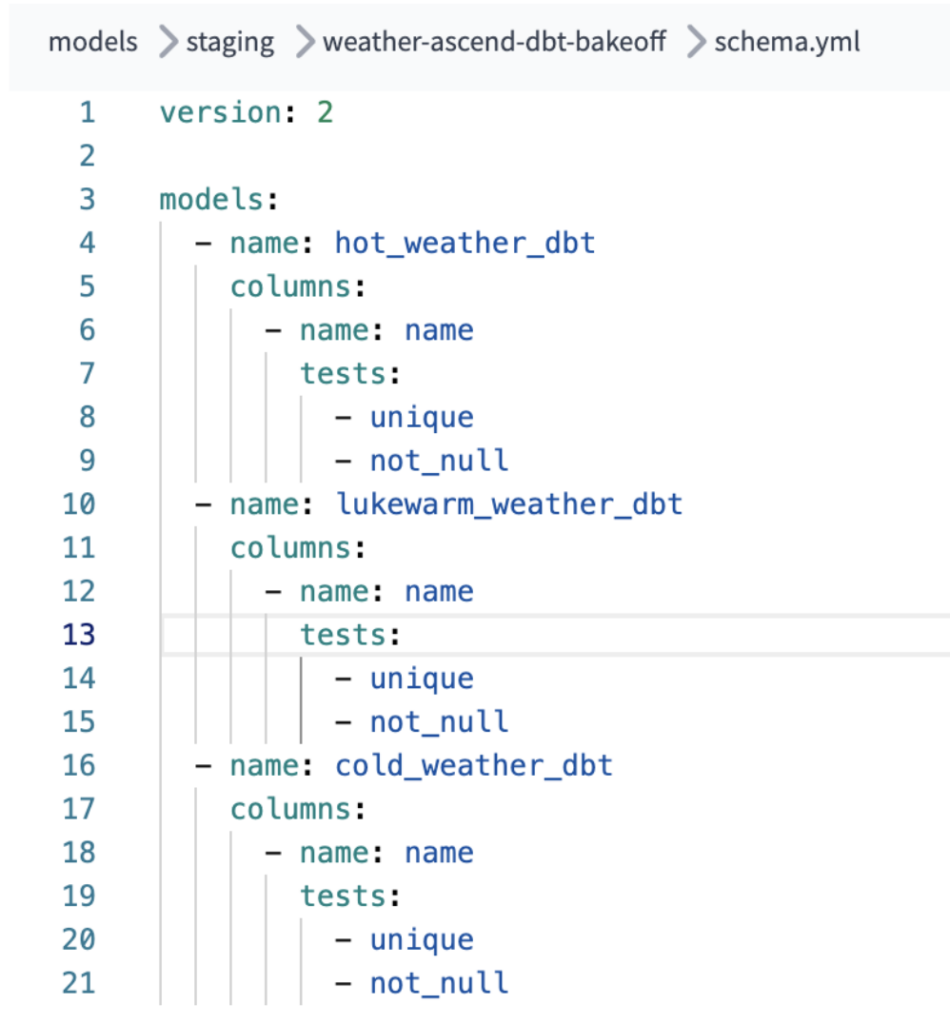
Los escenarios mencionados arriba no se adaptaron tan bien a dbt. Pudimos almacenar y conservar los errores en una tabla de manejo de errores similar al pipeline de Ascend. Aun así, estas capacidades requirieron descargar paquetes adicionales de dbt (en particular, vale la pena mencionar que el paquete dbt-expectations, ofrecido por catalogia, brinda buenas funcionalidades del lado de la calidad de datos). Y aunque pudimos implementar un proceso de reinicio en nuestro pipeline, esto implicó una re-ejecución manual de los jobs o una configuración adicional de errores agregada en dbt Cloud dentro de los retry settings de nuestros jobs.
También se requirió configuración adicional para permitir tests de not-null y unique en cada uno de nuestros modelos dbt, con el fin de que el pipeline ejecutara esas validaciones. No fue una cantidad excesiva de esfuerzo extra, pero podría hacer tropezar a desarrolladores menos familiarizados o con menos experiencia en la configuración de proyectos dbt Core / dbt Cloud.
Observaciones finales
De nuestras pruebas con el caso de estudio de datos meteorológicos en Ascend.io y dbt, queda claro que ambos servicios pueden cubrir las necesidades de casos de uso de transformación de datos. Sin embargo, tras pruebas exhaustivas de las funciones nativas de ambos y de sus extensiones de terceros, también se ve que el toolset adecuado para ti depende de cuál se ajuste mejor a tus necesidades.
Con Ascend.io tienes una herramienta integral de cloud data pipeline que optimiza y orquesta tus data pipelines de forma automática bajo el capó. Tiene una UI más amigable que vuelve la creación de pipelines simple y eficiente para desarrolladores de distintos niveles de experiencia. Incluye técnicas de mejora de rendimiento para que tus pipelines corran impecables, sin necesidad de un nivel experto de conocimiento en infraestructura de datos ni de horas de codificación manual.
Creemos que Ascend.io vale la pena probarlo para tus necesidades de cloud data pipeline, sobre todo cuando tus procesos de gestión de datos se beneficiarían de menos mantenimiento y de menos herramientas de orquestación que administrar. Su simplicidad para configurar jobs y sus opciones de reducción de costos de cómputo en la nube listas para usar hacen del servicio Ascend una gran alternativa a herramientas más enfocadas en código como dbt, según tu caso de uso.
Como referencia de este artículo, los pipelines construidos en Ascend y dbt pueden consultarse en el repositorio de Github aquí.