
Bases de données distribuées
Redis pour le cache chaud, Cassandra/CouchDB pour les gros volumes… Et s'il existait une base capable de tout faire ?
Choisir une base de données pour son prochain grand projet, c'est compliqué — au sens où il est difficile d'anticiper où votre projet vous mènera, et en changer par la suite l'est encore plus. Ma stratégie de prédilection consiste à choisir le bon outil pour la bonne tâche, ce qui peut me conduire à en cumuler plusieurs.
Mais s'il existait un produit suffisamment hybride pour couvrir plusieurs workloads ? Le proverbe qui trop embrasse mal étreint n'est pas dénué de vérité, mais après une plongée rapide dans la base Apache Ignite, je crois bien que nous tenons là ce fameux outil maître en tout.
.elementor-widget-theme-post-featured-image {
display:none;
}
Apache Ignite — un maître en tout ?
Peut-il remplacer Redis ?
Ou Hazelcast ? Les benchmarks disent que oui. C'est un cache distribué orienté RAM en priorité. Il passe à l'échelle nativement en découpant les données en partitions et en les répartissant entre les nœuds du cluster, avec rééquilibrage automatique.
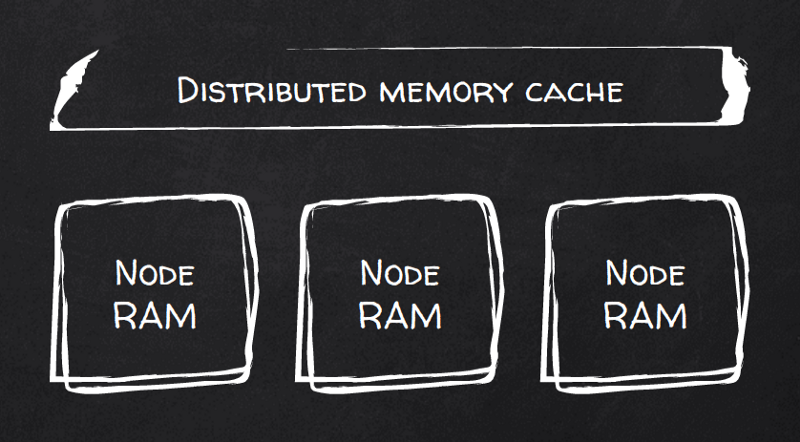
Les clients peuvent se connecter à n'importe quel nœud pour exécuter des requêtes, mais surtout, ils peuvent se connecter à tous les nœuds et utiliser un calcul simple pour interroger directement le bon nœud pour chaque clé donnée. Autrement dit, atteindre directement le nœud qui contient les données locales correspondant à une clé.
Persistance ?
Oui. Activez le flag persistenceEnabled (au prix de 8 lignes de configuration XML, tout de même) et votre RAM devient persistante. Ignite parle d'ailleurs de Durable RAM.
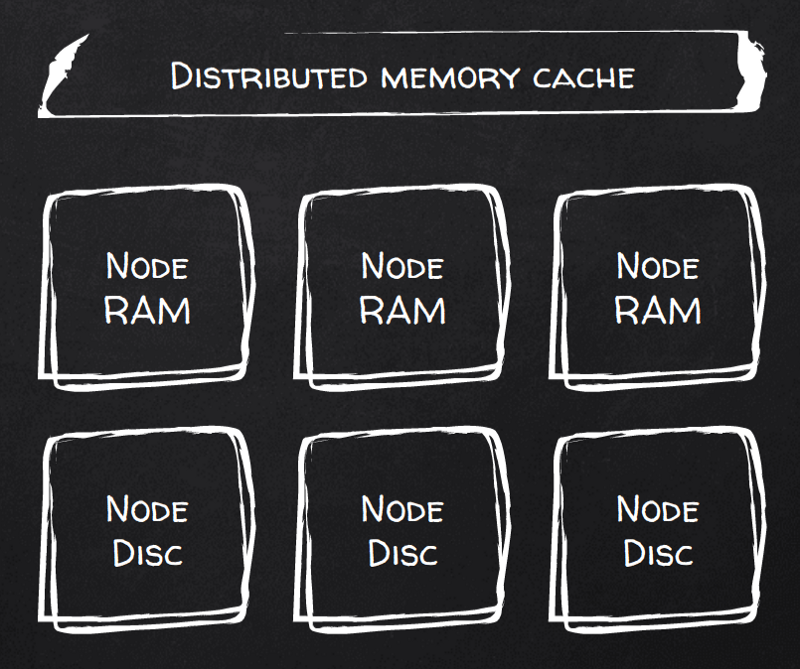
Désormais, chaque écriture de document est persistée. Vous pouvez paramétrer le nombre de copies (réplicas) ainsi que le niveau de cohérence en écriture — d'une cohérence faible, où les écritures sont acquittées dès leur passage dans le buffer cache de la copie primaire, à une cohérence forte, où elles ne sont acquittées au client qu'après un fsync garanti sur tous les nœuds répliqués.
De quoi avoir envie d'appeler ça Redis bien fait. Si vous avez déjà mis en place un cluster Redis, vous voyez ce que je veux dire.
Au-delà du clé/valeur
Beaucoup objecteront que comparer Redis et Apache Ignite n'est pas équitable. Apache Ignite va effectivement bien plus loin que le clé/valeur, avec notamment :
- Des opérations transactionnelles multi-clés
- La prise en charge de SQL ANSI-99, jointures distribuées comprises
- Le Grid Computing — chargez votre jar dans Ignite et estompez la frontière entre calcul et stockage au profit de la localité des données
- Le streaming de données
" Sympa, mais c'est cher ! "
Effectivement. La performance a un prix, mais au moins, ici, l'argent permet vraiment de l'acheter.
Reste que je n'ai peut-être pas besoin de cette performance, en tout cas pas dès le premier jour. Puis-je payer à l'usage ? Tout à fait ! C'est précisément ce qui a retenu toute mon attention quand j'ai commencé à explorer ce projet pour le compte de notre client.
Il suffit de baisser le ratio Mémoire/Disque autant que vous le souhaitez : la performance baissera en même temps que le coût. C'est exactement ce que je cherchais — un stockage clé/valeur peu coûteux, avec des performances correctes.
Le principe est aussi simple qu'on peut l'imaginer : Ignite case en RAM ce qu'il peut, et le reste va sur disque. Il gère automatiquement ce cache RAM chaud. Détail intéressant, Ignite se considère comme orienté mémoire avant tout : les écritures passent d'abord par la RAM avant d'être persistées sur disque ; les données fraîchement écrites deviennent donc, de fait, des données chaudes — pour le meilleur et pour le pire.
Jusqu'où peut-on descendre en coût ?
Pour tester, nous avons exécuté des benchmarks sur GKE (cluster Kubernetes managé par Google) avec 4 nœuds répartis sur 2 zones, 1 copie primaire et 1 réplica par partition de cache ; chaque nœud disposait de 2 vCPU / 16 Go de RAM et d'un disque persistant SSD de 1 To. Soit seulement ~250 $ par To et par mois !
Nous avons réussi à insérer 200 millions de documents de 512 caractères à 7 465 écritures/s, avec une latence médiane de seulement 1,59 ms. Et ce, sans aller jusqu'à l'optimisation fine, par exemple via un client intelligent sachant à quel nœud s'adresser pour chaque requête de clé.
Une fois ces données initiales en place, nous avons simulé un schéma de charge journalier avec 9 thin clients effectuant en parallèle des insertions, mises à jour et lectures aléatoires. Résultats :
- 3 682 insertions/s, latence médiane de 3,8 ms
- 4 229 mises à jour/s, latence médiane de 4,8 ms
- 3 952 lectures/s, latence médiane de 4,2 ms
Les chiffres peuvent paraître modestes, mais regardez le rapport qualité/prix — une base clé/valeur de 4 To pour ~1 000 $/mois avec une latence de réponse de l'ordre de la milliseconde, c'est une affaire !
Ce workload était totalement CPU bound, mais sur les 250 $ payés par nœud et par mois, 170 $ vont au stockage. Doubler la capacité CPU/RAM porterait donc le coût à ~320 $/mois par To, et je ne serais pas surpris d'obtenir un gain de performance proche du double [attention, spéculation].
Et puisque ce n'était pas encore assez bon marché, par curiosité, nous avons testé des disques persistants standard (donc magnétiques), ce qui ramène le coût total du To à 120 $/mois. Le système tenait encore 3 800 docs/s en lectures aléatoires avec une latence moyenne de 3,2 ms (uniquement des lectures, sans insertions ni mises à jour). Cela dit, je ne recommanderais pas cette configuration pour des workloads de production.
La solution miracle ?
Jusqu'ici, on pourrait croire qu'Ignite est ce qu'il y a de mieux au monde ! Mais dès qu'on s'en sert vraiment, les aspérités apparaissent. Un peu comme la différence entre faire du tourisme et émigrer :)
Examinons les volets Dev et Ops de l'équation.
Côté Dev, alors ?
Si vous baignez dans Java/Spring, vous serez en terrain connu. Et beaucoup de fonctionnalités semblent effectivement réservées à Java, comme le Streaming ou le Grid Computing.
Il existe des clients pour d'autres langages, mais on s'y sent un peu comme un enfant adoptif — officiellement, vous faites partie de la famille, mais l'êtes-vous vraiment ? La documentation est très, très centrée sur Java.
Prenez l'API REST, par exemple — un examen attentif révèle qu'il s'agit plutôt d'un HTTP RPC que d'une vraie API REST (au sens collections d'objets + CRUD). Un appel API REST typique ressemble à ceci :
GET /ignite?cmd=getorcreate&cacheName=test-cacheEt même cela reste limité. Par exemple, pour récupérer les métadonnées de partition d'un cache donné, il faut concocter la requête suivante :
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3&p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cacheÉlégant, n'est-ce pas ? Et j'ai dû passer par un proxy HTTP en mode sniffer pour la dénicher.
Et côté Ops ?
Beaucoup d'aspérités également. Nous l'avons exécuté sur GKE et il existe des guides officiels pour cela, mais je ne les considère pas comme prêts pour la production. Nous avons apporté de nombreuses améliorations, dont :
- Une configuration multi-zones avec zone-awareness prête à l'emploi. Par exemple, toutes les copies primaires sur les nœuds de la zone A et les réplicas sur les nœuds de la zone B.
- Un seul pod Ignite par nœud. Mieux vaut ne pas mélanger Ignite avec d'autres workloads dans votre cluster.
- Configuration des nœuds via un ConfigMap K8s plutôt qu'un pull depuis GitHub.
- Pas de disque dédié pour le WAL — sur GCP, les performances disque dépendent de la taille, donc dédier un disque rapide et volumineux serait du gaspillage.
Toutes nos améliorations sont disponibles dans le dépôt GitHub suivant : https://github.com/doitintl/ignite-gke
Mais d'autres difficultés subsistent, malheureusement :
- Je n'ai pas réussi à connecter IgniteVisor (l'outil CLI) au cluster. Il réclame un fichier de configuration XML(!) à l'ouverture de la connexion, et aucun de ceux que j'ai fournis n'a fonctionné, même en l'exécutant localement sur le nœud Ignite.
- Pas plus de chance avec la Web Console — son exécution nécessite de lancer les pods web-agent, web-frontend, web-backend et MongoDb(!). Mais le pire, c'est que les images Docker des composants web-* ont pris du retard et datent d'un an. En essayant de les construire moi-même, j'ai découvert que les Dockerfiles ne sont pas autonomes et exigent un build local préalable.
- La configuration vous oblige à écrire, ou plutôt à copier-coller, du XML très verbeux. Activer une simple propriété booléenne demande 8 lignes de XML, et ressemble à ceci :

- Il semble impossible de sauvegarder le cluster Ignite sans souscrire à un abonnement commercial chez GridGain. De simples snapshots de disque peuvent laisser les WAL incohérents entre les nœuds primaire/réplica, sauf à utiliser par exemple les snapshots crash-consistent d'Amazon EBS. Et même là, leur restauration reste délicate, car Ignite embarque les IDs des nœuds dans les données persistées, et les nouveaux nœuds devront correspondre. L'un des développeurs m'a indiqué que la fonctionnalité de snapshot arriverait prochainement dans la version open source.
Et le verdict ?
La technologie est très intéressante. On peut effectivement s'en servir comme d'un outil tout-en-un et faire tourner aussi bien des workloads rapides/coûteux que lents/économiques, et même les deux sur un même cluster.
Cela dit, un outillage peu accueillant et l'absence de sauvegardes rendent difficile sa recommandation pour un usage en production, ce qui est dommage au regard de toutes ses excellentes fonctionnalités.
J'espère que ces lacunes seront corrigées rapidement, afin que l'on puisse profiter pleinement de la richesse d'Ignite.
Et si vous voulez l'essayer dès aujourd'hui sur GCP, notre dépôt GitHub ignite-gke vous aidera à démarrer rapidement.
Enfin, il serait vraiment intéressant de voir Ignite passer au crible de Jepsen pour découvrir, en pratique, la qualité de ses garanties de cohérence.