
Bancos de dados distribuídos
Redis para cache quente; Cassandra/CouchDB para grandes volumes de dados… E se existisse um banco que fizesse tudo isso?
Escolher um banco de dados para o seu próximo grande projeto é difícil — no sentido de que é "difícil prever onde o projeto vai te levar" —, e trocar de banco depois é ainda mais complicado. Minha estratégia preferida é a da "ferramenta certa para cada tarefa", e por isso costumo acabar usando vários.
Mas e se houvesse um produto híbrido o suficiente para dar conta de múltiplos workloads? Há um fundo de verdade no ditado "quem faz tudo não faz nada bem feito", mas recentemente fiz um mergulho rápido no banco Apache Ignite e acho que talvez tenhamos achado esse "mestre de todas as artes".
.elementor-widget-theme-post-featured-image {
display:none;
}
Apache Ignite — um mestre de todas as artes?
Dá pra substituir o Redis?
Ou o Hazelcast? Os benchmarks dizem que sim. É um cache distribuído com prioridade em RAM. Ele escala de forma nativa, quebrando os dados em partições e distribuindo entre os nós do cluster, com rebalanceamento automático.
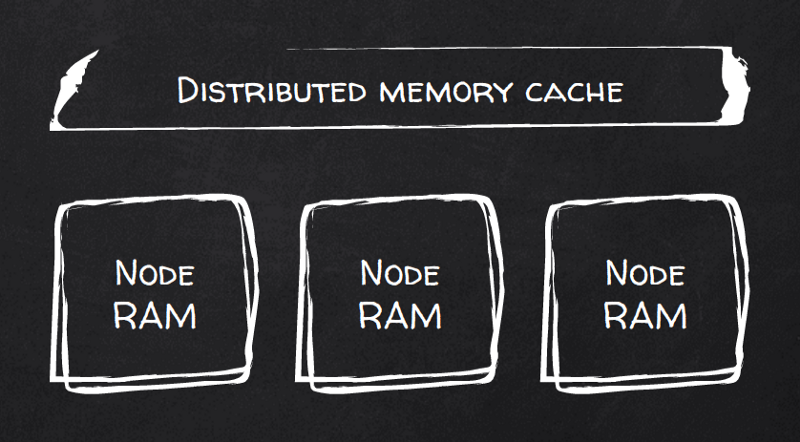
Os clientes podem se conectar a qualquer nó para rodar consultas, mas o melhor de tudo é que eles podem se conectar a todos os nós e usar uma matemática simples para consultar o nó certo para cada chave. Ou seja, ir direto ao nó que tem os dados locais daquela chave.
Persistência?
Tem. Basta ligar a flag persistenceEnabled (mesmo que sejam 8 linhas de XML) e a sua RAM passa a ser persistente. Aliás, o Ignite chama isso de "Durable RAM".
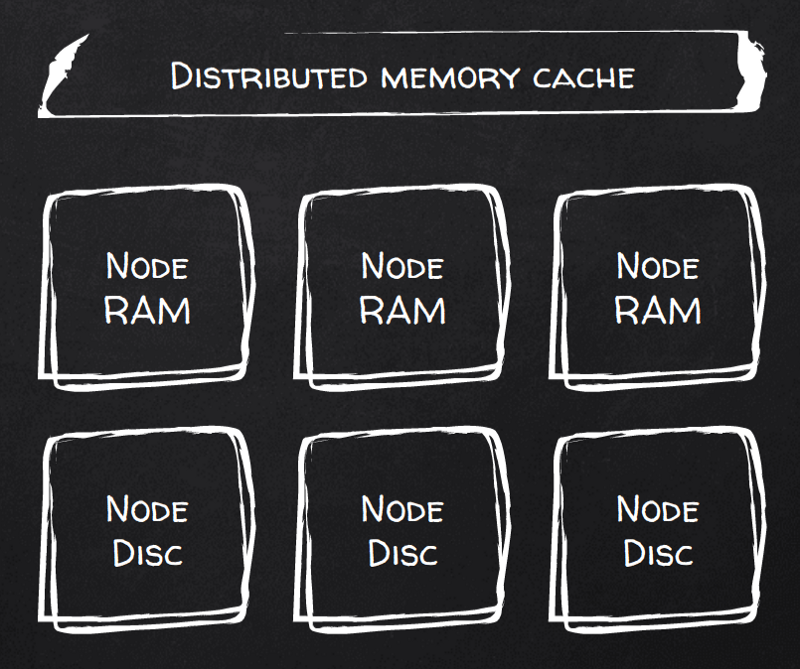
Agora cada gravação de documento é persistida. Você controla o número de cópias (réplicas) e também o nível de consistência de escrita — desde uma consistência fraca, em que as gravações são confirmadas depois de escritas no buffer cache da primeira cópia (primária), até uma consistência forte, em que as gravações têm fsync garantido em todos os nós replicados antes de serem confirmadas ao cliente.
Dá vontade de chamar isso de "Redis bem feito". Se você já mexeu com a configuração de cluster do Redis, sabe exatamente do que estou falando.
Além de chave/valor
Muita gente vai dizer que comparar Redis e Apache Ignite não é justo. Afinal, o Apache Ignite oferece muito mais do que chave/valor, incluindo:
- Operações transacionais multi-chave
- Suporte a SQL ANSI-99, com joins distribuídos
- Grid Computing — carregue seu jar no Ignite e dilua a fronteira entre computação e armazenamento, em favor da localidade dos dados
- Streaming de dados
"Legal, mas isso é caro!"
É mesmo. Performance custa dinheiro, mas pelo menos neste caso o dinheiro consegue comprar performance.
Só que talvez eu não precise dessa performance toda, ao menos não de cara. Dá pra pagar conforme o uso? Dá sim! Foi aí que esse projeto chamou minha atenção quando comecei a explorá-lo a pedido de um cliente.
Tudo o que você precisa fazer é reduzir a proporção Memória/Disco o quanto quiser, e a performance cai junto com o custo. Era exatamente isso que eu procurava — um armazenamento chave/valor barato com performance adequada.
Funciona da forma mais simples possível — o Ignite coloca em RAM o que dá, e o resto vai para o disco. Ele gerencia esse cache quente em RAM automaticamente. Curiosamente, o Ignite se considera memory-first, ou seja, as gravações vão primeiro para a RAM antes de serem persistidas em disco; o que significa que dados recém-escritos viram dados quentes — com o lado bom e o lado ruim disso.
Quão barato dá pra ficar?
Para testar, rodamos benchmarks no GKE (cluster Kubernetes gerenciado pelo Google) com 4 nós em 2 zonas, 1 cópia primária e 1 réplica para cada partição de cache; cada nó tinha 2 vCPUs / 16GB de RAM e 1TB de disco persistente SSD acoplado. Isso dá só uns US$ 250 por TB por mês!
Conseguimos inserir 200 milhões de documentos de 512 caracteres a 7.465 gravações/seg, com latência mediana de apenas 1,59ms. E isso sem nenhum ajuste fino de performance, como um cliente inteligente que sabe com qual nó conversar para cada chave.
Depois de carregar os dados iniciais, tentamos simular um padrão de carga diária com 9 thin clients fazendo inserções, atualizações e leituras aleatórias ao mesmo tempo, com os seguintes resultados:
- 3.682 inserções/s, latência mediana de 3,8ms
- 4.229 atualizações/s, latência mediana de 4,8ms
- 3.952 leituras/s, latência mediana de 4,2ms
Os números podem não impressionar à primeira vista, mas olhe o custo-benefício — um banco chave/valor de 4TB por cerca de US$ 1.000/mês, com latência de resposta na casa de um dígito de milissegundos. É uma pechincha!
Esse workload era totalmente CPU bound, mas US$ 170 dos US$ 250 por nó/mês vão para armazenamento. Então dobrar a capacidade de CPU/RAM levaria o custo a uns US$ 320/mês por TB, e eu não me surpreenderia se ganhássemos quase o dobro de performance [aviso de especulação aqui].
Como se isso não bastasse, por curiosidade testamos com discos persistentes padrão (ou seja, magnéticos), o que reduziu o custo total por TB para US$ 120/mês. Mesmo assim, mandamos 3.800 docs/seg em gets aleatórios, com latência média de 3,2ms (sem inserts ou updates, só leituras). Ainda assim, eu não recomendaria essa configuração para workloads de produção.
Bala de prata?
Até aqui pode parecer que o Ignite é "a melhor coisa do mundo!". Mas, assim que você começa a usar, as arestas aparecem. É como a diferença entre turismo e imigração :)
Vamos olhar tanto para Dev quanto para Ops nessa equação.
E como é do lado Dev?
Se você é nativo do mundo Java/Spring, vai se sentir em casa. E muita coisa, de fato, parece estar disponível só para Java, como Streaming ou Grid Computing.
Existem clientes para outras linguagens, mas você vai se sentir meio como filho adotivo — oficialmente faz parte da família, mas será mesmo? A documentação é muito, muito Java-cêntrica.
Veja a REST API, por exemplo — uma olhada mais de perto mostra que ela é mais um HTTP RPC do que uma verdadeira REST API (com coleções de objetos + CRUD). Uma chamada típica de REST API se parece com isto:
GET /ignite?cmd=getorcreate&cacheName=test-cacheMas até isso é limitado. Por exemplo, para obter os metadados de partição de um determinado cache, é preciso montar a seguinte requisição:
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3&p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cacheLindo, né? E precisei usar um proxy HTTP fazendo sniffing para descobrir isso.
E o lado Ops?
Muitas arestas também. Rodamos no GKE e existem guias oficiais para isso, mas eu não os consideraria production-ready. Fizemos várias melhorias, incluindo:
- Configuração multizona com zone-awareness de fábrica. Ex.: todas as cópias primárias ficam em nós da zona A e as réplicas em nós da zona B.
- Um pod do Ignite por nó. É melhor não misturar Ignite com outros workloads no seu cluster.
- Configuração de nós via ConfigMap do Kubernetes em vez de puxar do GitHub.
- Sem disco dedicado para WAL — no GCP, a performance do disco depende do tamanho, então ter um disco dedicado grande e rápido é dinheiro jogado fora.
Todas as nossas melhorias estão disponíveis neste repositório do GitHub: https://github.com/doitintl/ignite-gke
Mas, infelizmente, ainda há mais dificuldades:
- Não consegui fazer o IgniteVisor (a ferramenta CLI) se conectar ao cluster. Ele pede um arquivo de configuração XML(!) ao abrir a conexão, e nenhum dos que forneci funcionou, nem mesmo rodando localmente no nó do Ignite.
- Também não tive muita sorte com o Web Console — para rodá-lo, é preciso subir pods de web-agent, web-frontend, web-backend e MongoDb(!). Mas o pior é que as imagens Docker da parte web-* estão atrasadas e têm um ano de idade. Quando tentei buildar eu mesmo, descobri que os Dockerfiles não são autocontidos e exigem um build local antes.
- A configuração exige que você escreva, ou melhor, copie e cole, um XML extremamente verboso. Habilitar uma simples propriedade booleana exige 8 linhas de XML e fica assim:

- Pelo visto, não há como fazer backup do cluster Ignite a menos que você use uma assinatura comercial da GridGain. Tirar snapshots de disco simplesmente pode deixar você com WALs inconsistentes entre nós primários/réplicas, a não ser que use, por exemplo, snapshots crash-consistent do Amazon EBS. E mesmo assim, restaurá-los é bem complicado, já que o Ignite embute os IDs dos nós nos dados persistidos, e os novos nós precisam casar com esses IDs. Um dos desenvolvedores me disse que o recurso de snapshot deve chegar em breve à versão open source.
E o veredito?
A tecnologia é muito interessante. Dá, sim, para usá-la como ferramenta faz-tudo e rodar workloads tanto rápidos/caros quanto lentos/baratos, até mesmo no mesmo cluster.
Por outro lado, o ferramental pouco amigável e a falta de backups tornam difícil recomendar essa ferramenta para uso em produção, o que é uma pena diante de tantas funcionalidades excelentes.
Só espero que essas limitações sejam resolvidas em um futuro próximo, para que possamos aproveitar a grandiosidade do Ignite por completo.
E se você quiser brincar com ele hoje no GCP, nosso repositório ignite-gke no GitHub vai te ajudar a começar rapidamente.
Por fim, seria muito interessante ver o Ignite testado pelo Jepsen para descobrir o quão boas são as garantias de consistência dele na prática.