
Database distribuiti
Redis per la hot cache, Cassandra/CouchDB per dataset di grandi dimensioni… E se esistesse un DB capace di fare tutto?
Scegliere il database per il proprio prossimo grande progetto è difficile — nel senso che è difficile prevedere dove il progetto la porterà, e cambiarlo in corsa lo è ancora di più. La mia strategia di riferimento è "lo strumento giusto per ogni compito", quindi finisco spesso per usarne diversi.
Ma se esistesse un prodotto abbastanza ibrido da coprire workloads diversi? C'è un fondo di verità nel detto "chi sa fare tutto non eccelle in nulla", eppure di recente mi sono tuffato nel database Apache Ignite e credo di aver trovato proprio quel "maestro di tutto".
.elementor-widget-theme-post-featured-image {
display:none;
}
Apache Ignite — un maestro di tutti i mestieri?
Può sostituire Redis?
O Hazelcast? I benchmark dicono di sì. È una cache distribuita RAM-first. Scala in modo nativo suddividendo i dati in partizioni e distribuendole tra i nodi del cluster con ribilanciamento automatico.
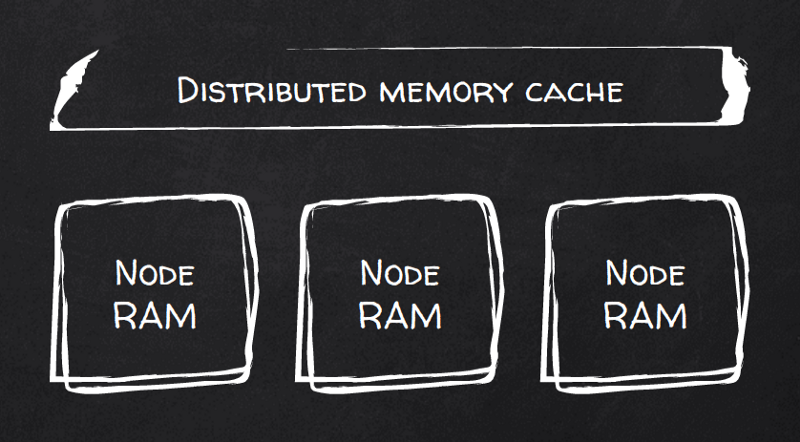
I client possono connettersi a un nodo qualsiasi per eseguire le query, ma soprattutto possono connettersi a tutti i nodi e usare semplici calcoli per interrogare il nodo giusto per ogni chiave. In altre parole, raggiungere direttamente il nodo che contiene i dati locali per una determinata chiave.
Persistenza?
C'è. Basta attivare il flag persistenceEnabled (con appena 8 righe di configurazione XML) e la RAM diventa persistente. Ignite la chiama infatti "Durable RAM".
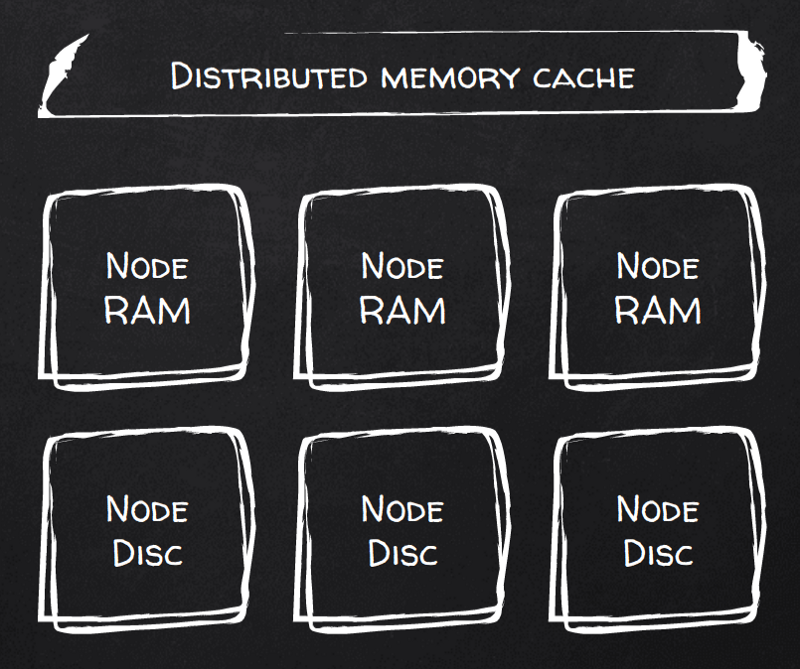
A questo punto ogni scrittura di documento viene resa persistente. Si può controllare il numero di copie (repliche) e il livello di consistenza in scrittura — da una consistenza debole, in cui le scritture vengono confermate dopo essere state scritte nella buffer cache della prima copia (primaria), a una consistenza forte, in cui prima della conferma al client le scritture devono passare per fsync su tutti i nodi replicati.
Mi viene da chiamarlo "Redis fatto bene". Se ha mai messo le mani sulla configurazione di un cluster Redis, sa di cosa parlo.
Oltre il key/value
Molti obietteranno che il confronto tra Redis e Apache Ignite non è equo. In effetti Apache Ignite offre molto più del semplice key/value, tra cui:
- Operazioni transazionali multi-chiave
- Supporto SQL ANSI-99, inclusi i join distribuiti
- Grid Computing — caricando il proprio jar in Ignite si sfuma il confine tra calcolo e archiviazione, a favore della località dei dati
- Data Streaming
"Bello, ma costa caro!"
Certo che sì. Le prestazioni costano, ma almeno in questo caso con i soldi le prestazioni le compri davvero.
E se non mi servissero tutte quelle prestazioni, almeno non dal primo giorno? Posso pagare a consumo? Sì! È qui che il progetto ha catturato la mia attenzione mentre lo esploravo per conto di un nostro cliente.
Basta abbassare il rapporto memoria/disco quanto si vuole e le prestazioni caleranno insieme ai costi. In effetti era proprio quello che cercavo: uno store key/value economico con prestazioni adeguate.
Funziona nel modo più semplice che si possa immaginare: Ignite carica in RAM ciò che ci sta, e il resto va su disco. Gestisce automaticamente quella hot cache in RAM. Curiosamente, Ignite si considera memory-first: le scritture finiscono prima in RAM e poi vengono rese persistenti su disco, quindi i dati appena scritti diventano di fatto dati "caldi", nel bene e nel male.
Quanto si può spendere poco?
Per il test abbiamo eseguito benchmark su GKE (cluster Kubernetes gestito da Google) con 4 nodi distribuiti su 2 zone, 1 copia primaria e 1 replica per ogni partizione di cache; ogni nodo aveva 2 vCPU, 16 GB di RAM e 1 TB di disco persistente SSD collegato. Sono appena ~250 $ per TB al mese!
Siamo riusciti a inserire 200 milioni di documenti da 512 caratteri a 7.465 scritture/sec con una latenza mediana di appena 1,59 ms. Il tutto senza addentrarci nel tuning delle prestazioni, ad esempio con un client smart che sappia con quale nodo dialogare per ogni richiesta di chiave.
Una volta caricati i dati iniziali abbiamo provato a simulare un pattern di carico giornaliero con 9 thin client che eseguivano in contemporanea inserimenti, aggiornamenti e letture casuali, ottenendo questi risultati:
- 3.682 inserimenti/s, latenza mediana 3,8 ms
- 4.229 aggiornamenti/s, latenza mediana 4,8 ms
- 3.952 letture/s, latenza mediana 4,2 ms
I numeri non sembreranno strabilianti, ma guardiamo il rapporto qualità/prezzo: un DB key/value da 4 TB a circa 1.000 $/mese con latenze di risposta nell'ordine di pochi millisecondi — è un affare!
Questo workload era completamente CPU-bound, ma 170 $ dei 250 $ per nodo/mese se ne vanno in storage. Quindi raddoppiando la capacità di CPU/RAM il costo salirebbe a ~320 $/mese per TB, e non mi sorprenderebbe vedere prestazioni quasi raddoppiate [attenzione: è solo una stima].
Come se non bastasse, per curiosità abbiamo provato a usare dischi persistenti standard (cioè magnetici), portando il costo totale per TB a 120 $/mese. Ha comunque retto 3.800 doc/sec su get casuali con una latenza media di 3,2 ms (solo letture, niente inserimenti o aggiornamenti). Detto questo, non consiglierei questa configurazione per workloads di produzione.
Pallottola d'argento?
Finora può sembrare che Ignite sia "la cosa più bella di sempre!". Ma quando si inizia a usarlo davvero, gli spigoli vivi vengono fuori. Un po' come la differenza tra fare il turista e trasferirsi a vivere in un posto :)
Vediamo entrambi i lati dell'equazione: Dev e Ops.
Come va lato Dev?
Se è di casa nel mondo Java/Spring si troverà a meraviglia. E molte funzionalità sembrano effettivamente disponibili solo per Java, come lo Streaming o il Grid Computing.
Esistono client per altri linguaggi, ma ci si sente un po' come un figlio adottivo: ufficialmente fa parte della famiglia, ma è davvero così? La documentazione è molto, molto Java-centrica.
Prendiamo l'API REST: a guardarla da vicino si scopre che è più una RPC su HTTP che una vera API REST (intesa come collezioni di oggetti + CRUD). Una tipica chiamata API REST si presenta così:
GET /ignite?cmd=getorcreate&cacheName=test-cacheE anche così l'ambito è limitato. Ad esempio, per ottenere i metadati delle partizioni di una determinata cache, bisogna confezionare una richiesta di questo tenore:
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3&p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cacheCarino, eh? E ho dovuto usare un proxy HTTP in modalità sniffing per riuscire a tirar fuori quella stringa.
E lato Ops?
Anche qui parecchi spigoli. Lo abbiamo eseguito su GKE: ci sono guide ufficiali, ma non le considererei pronte per la produzione. Abbiamo apportato diversi miglioramenti, tra cui:
- Setup multi-zona con zone-awareness nativa. Ad esempio, tutte le copie primarie risiedono sui nodi della zona A e le repliche sui nodi della zona B.
- Un solo pod Ignite per nodo. Meglio non mescolare Ignite con altri workloads nello stesso cluster.
- Configurazione dei nodi tramite ConfigMap di K8s anziché scaricata da GitHub.
- Nessun disco dedicato per il WAL: in GCP le prestazioni del disco dipendono dalla dimensione, quindi avere un disco dedicato grande e veloce è uno spreco di denaro.
Tutti i nostri miglioramenti sono disponibili in questo repository GitHub: https://github.com/doitintl/ignite-gke
Purtroppo, le difficoltà non finiscono qui:
- Non sono riuscito a far connettere IgniteVisor (lo strumento CLI) al cluster. All'apertura della connessione chiede un file di configurazione XML(!), e nessuno di quelli che ho fornito ha funzionato, nemmeno eseguendolo localmente sul nodo Ignite.
- Nemmeno con la Web Console è andata meglio: per eseguirla bisogna avviare i pod web-agent, web-frontend, web-backend e MongoDb(!). Ma la cosa peggiore è che le immagini Docker per la parte web-* sono ferme da circa un anno. Provando a costruirle da me, ho scoperto che i Dockerfile non sono autosufficienti e richiedono prima una build locale.
- La configurazione impone di scrivere, o meglio copia-incollare, XML estremamente verboso. Abilitare anche solo una semplice proprietà booleana richiede 8 righe di XML e si presenta così:

- Non sembra esserci modo di eseguire il backup del cluster Ignite senza sottoscrivere un abbonamento commerciale a GridGain. Limitarsi agli snapshot del disco rischia di lasciare WAL incoerenti tra nodi primari e repliche, a meno di ricorrere ad esempio agli snapshot crash-consistent di Amazon EBS. E anche in quel caso il ripristino è piuttosto complicato, perché Ignite incorpora gli ID dei nodi nei dati persistiti e i nuovi nodi devono corrispondere a quelli. Uno degli sviluppatori mi ha detto che la funzionalità di snapshot arriverà presto anche nella versione open-source.
E il verdetto qual è?
La tecnologia è molto interessante. Si può davvero usare come strumento tuttofare per eseguire workloads sia veloci e costosi sia lenti ed economici, anche sullo stesso cluster.
Tuttavia, strumenti poco amichevoli e la mancanza di backup rendono difficile consigliarlo in produzione, ed è un peccato considerando le sue numerose qualità.
Spero che queste lacune vengano colmate nel prossimo futuro, così da poter godere appieno delle potenzialità di Ignite.
E se già oggi vuole sperimentarlo su GCP, il nostro repository GitHub ignite-gke la aiuterà a partire in fretta.
Infine, sarà davvero interessante vedere Ignite messo alla prova da Jepsen per scoprire quanto siano solide in pratica le sue garanzie di consistenza.