
Bases de datos distribuidas
Redis para caché en caliente; Cassandra/CouchDB para datasets grandes… ¿Y si existiera una DB que pudiera con todo?
Elegir una base de datos para tu próximo gran proyecto es complicado —en el sentido de que es difícil anticipar a dónde te llevará el proyecto—, y migrar de base de datos lo es aún más. Mi estrategia de cabecera es la de "la herramienta adecuada para cada tarea", así que suelo terminar usando varias.
Pero ¿y si existiera un producto lo suficientemente híbrido como para cubrir múltiples workloads? Hay algo de cierto en eso de "quien mucho abarca, poco aprieta", pero hace poco hice una inmersión rápida en la base de datos Apache Ignite y creo que podríamos tener al "maestro de todos los oficios".
.elementor-widget-theme-post-featured-image {
display:none;
}
Apache Ignite — ¿maestro de todos los oficios?
¿Puede reemplazar a Redis?
¿O a Hazelcast? Los benchmarks dicen que sí. Es un caché distribuido que prioriza la RAM. Escala de forma nativa: divide los datos en particiones y los reparte entre los nodos del clúster con rebalanceo automático.
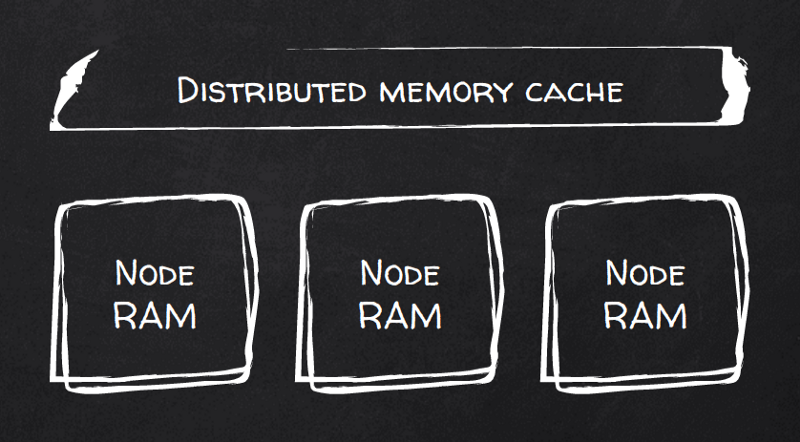
Los clientes pueden conectarse a cualquier nodo para ejecutar consultas, pero lo mejor es que pueden conectarse a todos los nodos y, con un cálculo simple, consultar el nodo correcto para cada clave dada. Es decir, llegar directo al nodo que contiene los datos locales para esa clave.
¿Persistencia?
Listo. Activa el flag persistenceEnabled (eso sí, con 8 líneas de configuración XML) y tu RAM pasa a ser persistente. De hecho, Ignite la llama "Durable RAM".
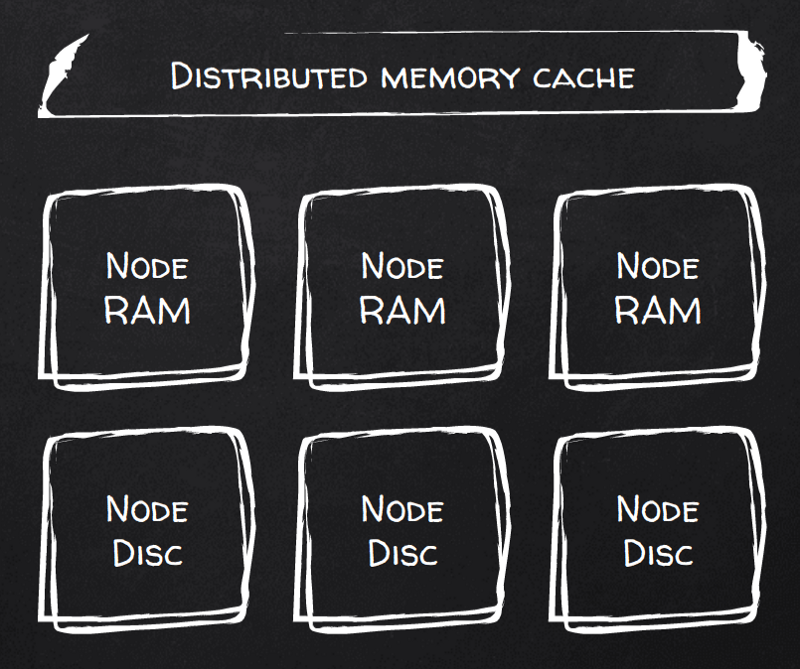
A partir de ahí, cada escritura de documento queda persistida. Puedes controlar la cantidad de copias (réplicas) y también el nivel de consistencia de escritura: desde una consistencia débil, en la que las escrituras se confirman después de pasar al buffer cache de la primera copia (primaria), hasta una consistencia fuerte, en la que se garantiza el fsync en cada nodo replicado antes de confirmárselas al cliente.
Da ganas de llamarlo "Redis bien hecho". Si alguna vez exploraste la configuración de un clúster de Redis, sabrás a qué me refiero.
Más allá de key/value
Muchos dirán que comparar Redis con Apache Ignite no es justo. Después de todo, Apache Ignite ofrece mucho más que key/value, por ejemplo:
- Operaciones transaccionales multi-clave
- Soporte de ANSI-99 SQL, incluyendo joins distribuidos
- Grid Computing — carga tu jar en Ignite y difumina la línea entre cómputo y almacenamiento a favor de la localidad de datos
- Data Streaming
"Genial, ¡pero eso es caro!"
Por supuesto que lo es. El rendimiento cuesta dinero, pero al menos en este caso el dinero sí se traduce en rendimiento.
Pero quizás no necesite ese rendimiento, al menos no desde el primer día. ¿Puedo pagar a medida que voy creciendo? ¡Claro que sí! Aquí fue donde el proyecto se ganó toda mi atención cuando empecé a explorarlo en nombre de nuestro cliente.
Lo único que tienes que hacer es bajar la relación Memoria/Disco tanto como quieras y el rendimiento bajará junto con el costo. De hecho, era justo lo que andaba buscando: un almacén key/value barato y con un rendimiento decente.
Funciona tan simple como uno se lo imagina: Ignite mete en RAM lo que cabe y el resto va al disco. Gestiona automáticamente ese caché caliente en RAM. Curiosamente, Ignite se considera memory-first, así que las escrituras van primero a RAM antes de persistirse en disco; es decir, los datos recién escritos pasan automáticamente a ser datos calientes, para bien y para mal.
¿Qué tan barato puede llegar a ser?
Para probarlo, corrimos benchmarks en GKE (clúster de Kubernetes administrado por Google) con 4 nodos en 2 zonas, 1 copia primaria y 1 réplica por cada partición de caché; cada nodo tenía 2 vCPUs / 16 GB de RAM y 1 TB de disco persistente SSD. ¡Eso son apenas ~$250 por TB al mes!
Logramos almacenar 200 millones de documentos de 512 caracteres a 7,465 escrituras/seg, con una latencia mediana de apenas 1.59 ms. Y eso sin entrar a fondo en el ajuste de rendimiento, como un cliente inteligente que sepa con qué nodo hablar para cada solicitud de clave.
Tras cargar los datos iniciales, intentamos simular un patrón de carga diaria con 9 thin clients haciendo inserts, updates y reads aleatorios al mismo tiempo, con estos resultados:
- 3,682 inserts/s, latencia mediana de 3.8 ms
- 4,229 updates/s, latencia mediana de 4.8 ms
- 3,952 reads/s, latencia mediana de 4.2 ms
Las cifras quizás no impresionen, pero fíjate en la relación valor/costo: una DB key/value de 4 TB por ~$1000/mes con latencia de respuesta de un solo dígito en milisegundos. ¡Es una ganga!
Este workload estaba totalmente limitado por CPU, pero $170 de los $250 por nodo/mes los pagas por almacenamiento. Así que duplicar la capacidad de CPU/RAM dejaría el costo en ~$320/mes por TB y no me sorprendería ver una mejora cercana al doble en rendimiento [advertencia: esto es especulación].
Por si no era lo bastante barato, por curiosidad probamos con discos persistentes estándar (es decir, magnéticos), bajando el costo total por TB a $120/mes. Aun así sostuvo 3,800 doc/seg en gets aleatorios con una latencia media de 3.2 ms (sin inserts ni updates, solo lecturas). Aun así, no recomendaría este setup para workloads en producción.
¿Bala de plata?
Hasta aquí podría parecer que Ignite es "¡lo mejor del mundo!". Pero apenas empiezas a usarlo, las asperezas salen a la luz. Como la diferencia entre el turismo y la inmigración :)
Veamos tanto Dev como Ops dentro de la ecuación.
Entonces, ¿cómo va Dev?
Si eres un nativo de Java/Spring, te sentirás como en casa. Y muchas cosas, de hecho, parecen estar disponibles solo para Java, como Streaming o Grid Computing.
Hay clientes para otros lenguajes, pero te sentirás un poco como un hijo adoptivo: oficialmente eres parte de la familia, pero ¿realmente lo eres? La documentación es muy, muy java-céntrica.
Toma como ejemplo la API REST: si la miras de cerca, te das cuenta de que es más HTTP RPC que una API REST de verdad (en el sentido de colecciones de objetos + CRUD). Una llamada típica a la API REST se ve así:
GET /ignite?cmd=getorcreate&cacheName=test-cachePero incluso eso es limitado. Por ejemplo, para obtener metadatos de partición de un caché dado, tienes que armar esta solicitud:
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3&p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cacheBonito, ¿eh? Y tuve que recurrir a un proxy HTTP con sniffing para sacar eso a la luz.
¿Y Ops?
También hay muchas asperezas. Lo corrimos en GKE y existen guías oficiales para hacerlo, pero no las consideraría listas para producción. Hicimos varias mejoras, entre ellas:
- Setup multizona con zone-awareness desde el primer momento. Por ejemplo, todas las copias primarias residirán en nodos de la zona A y las réplicas en nodos de la zona B.
- Un pod de Ignite por nodo. Mejor no mezclar Ignite con otros workloads en tu clúster.
- Configuración de nodos a través de un ConfigMap de K8s, en lugar de jalarla desde GitHub.
- Sin disco dedicado para el WAL: en GCP el rendimiento del disco depende del tamaño, así que tener un disco dedicado, grande y rápido es tirar dinero.
Todas nuestras mejoras están disponibles en este repo de GitHub: https://github.com/doitintl/ignite-gke
Pero, lamentablemente, hay más dificultades:
- No logré que IgniteVisor (la herramienta CLI) se conectara al clúster. Pide un archivo de configuración XML(!) al abrir una conexión, y ninguno de los que probé funcionó, ni siquiera ejecutándolo localmente en el nodo de Ignite.
- Tampoco tuve mucha suerte con la Web Console: ejecutarla requiere levantar pods de web-agent, web-frontend, web-backend y MongoDb(!). Pero lo peor es que las imágenes docker de la parte web-* están desactualizadas y tienen un año. Al intentar construirlas yo mismo, descubrí que los Dockerfiles no son autosuficientes y requieren primero un build local.
- La configuración te obliga a escribir, o más bien copiar y pegar, XML muy verboso. Habilitar una simple propiedad booleana requiere 8 líneas de XML y se ve así:

- Parece que no hay forma de respaldar el clúster de Ignite a menos que tengas una suscripción comercial de GridGain. Hacer snapshots de disco a secas puede dejar WALs inconsistentes entre nodos primarios/réplicas, salvo que uses, por ejemplo, los snapshots crash-consistent de Amazon EBS. Y aun así, restaurarlos es bastante complicado, porque Ignite incrusta los IDs de los nodos en los datos persistidos y los nuevos nodos tendrán que coincidir con esos. Uno de los desarrolladores me dijo que la funcionalidad de snapshot llegará pronto a la edición open-source.
¿Y el veredicto?
La tecnología es muy interesante. De hecho, puedes usarla como una herramienta todo en uno y correr workloads tanto rápidos/caros como lentos/baratos, incluso en el mismo clúster.
Sin embargo, lo poco amigable de las herramientas y la falta de respaldos hacen difícil recomendarla para uso en producción, lo cual es una pena considerando muchas de sus grandes funcionalidades.
Solo espero que esas carencias se resuelvan en un futuro cercano para poder disfrutar de Ignite en todo su esplendor.
Y si quieres probarlo hoy mismo en GCP, nuestro repo de GitHub ignite-gke te ayudará a arrancar rápido.
Por último, sería realmente interesante ver a Ignite puesto a prueba por Jepsen para descubrir qué tan buenas son sus garantías de consistencia en la práctica.