
Verteilte Datenbanken
Redis für den Hot Cache, Cassandra/CouchDB für große Datenmengen … Was, wenn eine DB all das könnte?
Die passende Datenbank für das nächste große Projekt zu wählen, ist schwierig – schon allein, weil sich kaum vorhersagen lässt, wohin das Projekt einen führt. Und ein späterer Wechsel ist noch schwieriger. Mein persönliches Vorgehen lautet: das richtige Werkzeug für die jeweilige Aufgabe – am Ende sind also meist mehrere im Einsatz.
Doch was wäre, wenn es ein Produkt gäbe, das vielseitig genug ist, um mehrere Workloads abzudecken? Am Spruch "Wer alles kann, kann nichts richtig" ist sicher etwas dran – trotzdem habe ich kürzlich einen Blick auf die Apache Ignite-Datenbank geworfen und glaube, hier könnten wir tatsächlich einen "Meister aller Klassen" gefunden haben.
.elementor-widget-theme-post-featured-image {
display:none;
}
Apache Ignite – Meister aller Klassen?
Kann Ignite Redis ersetzen?
Oder Hazelcast? Benchmarks sagen: Ja. Ignite ist ein verteilter Cache nach dem RAM-first-Prinzip. Er skaliert nativ, indem die Daten in Partitionen zerlegt und mit automatischem Rebalancing über die Cluster-Knoten verteilt werden.
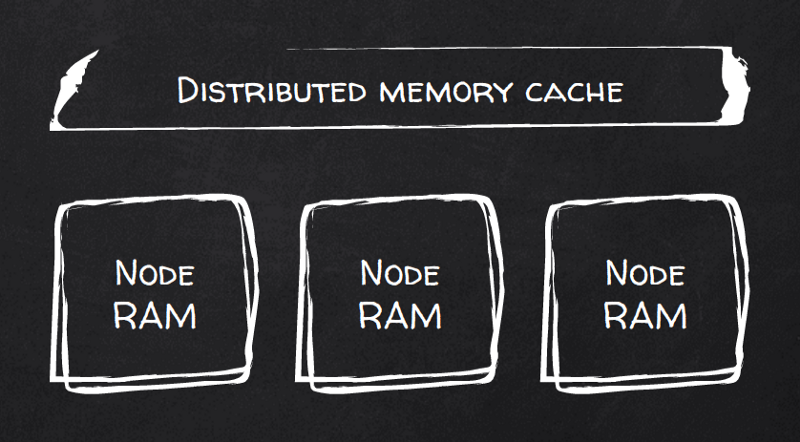
Clients können sich mit jedem beliebigen Knoten verbinden, um Abfragen auszuführen. Noch besser: Clients können sich auch mit allen Knoten verbinden und per einfacher Berechnung für jeden Schlüssel direkt den richtigen Knoten ansteuern – also genau jenen Knoten erreichen, der die lokalen Daten zum jeweiligen Schlüssel hält.
Persistenz?
Vorhanden. Setzen Sie das Flag persistenceEnabled (auch wenn das 8 Zeilen XML-Konfiguration kostet) und Ihr RAM ist dauerhaft. Ignite selbst nennt das "Durable RAM".
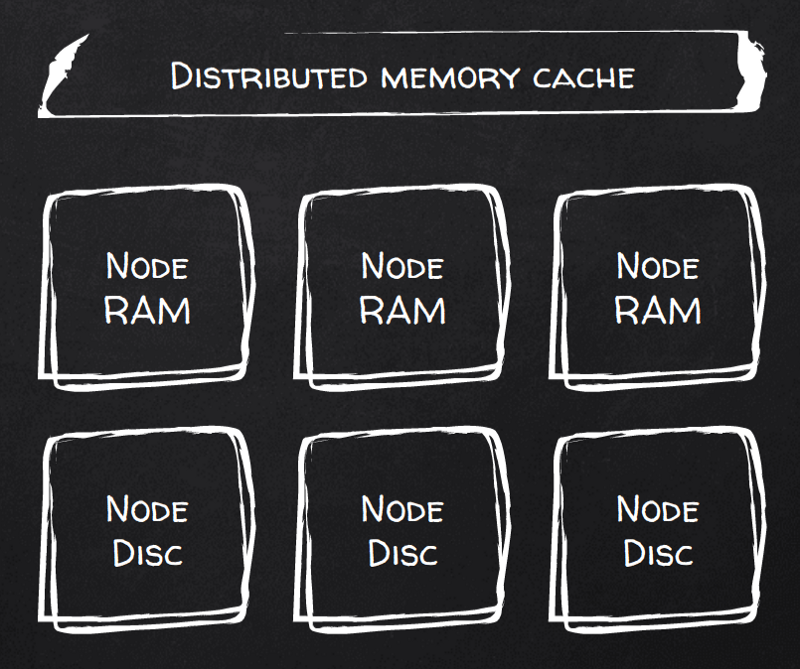
Damit wird jeder Schreibvorgang eines Dokuments persistent gespeichert. Sie steuern sowohl die Anzahl der Kopien (Replicas) als auch das Konsistenzlevel der Schreibvorgänge – von schwacher Konsistenz, bei der Writes bereits nach dem Eintrag in den Buffer Cache der ersten (Primary-)Kopie bestätigt werden, bis hin zu starker Konsistenz, bei der Writes garantiert auf jedem Replica-Knoten per fsync persistiert sind, bevor der Client eine Bestätigung erhält.
Man möchte es fast "Redis, aber richtig gemacht" nennen. Wer schon einmal ein Redis-Cluster aufgesetzt hat, weiß, was gemeint ist.
Mehr als nur Key/Value
Viele werden einwenden, ein Vergleich zwischen Redis und Apache Ignite sei unfair. Schließlich kann Apache Ignite weit mehr als Key/Value, unter anderem:
- Transaktionale Multi-Key-Operationen
- ANSI-99-SQL-Unterstützung inklusive verteilter Joins
- Grid Computing – laden Sie Ihre JAR in Ignite und lösen Sie die Grenze zwischen Compute und Storage zugunsten der Datenlokalität auf
- Data Streaming
"Cool, aber das ist teuer!"
Stimmt. Performance kostet Geld – aber in diesem Fall bekommen Sie für Ihr Geld auch wirklich Performance.
Vielleicht brauchen Sie diese Performance aber gar nicht, zumindest nicht von Tag eins an. Pay as you go? Genau das geht. An diesem Punkt hat das Projekt meine volle Aufmerksamkeit gewonnen, als ich es im Auftrag eines Kunden untersucht habe.
Sie senken einfach das Memory/Disk-Verhältnis so weit ab, wie Sie möchten – Performance und Kosten sinken parallel. Genau danach habe ich gesucht: einen günstigen Key/Value-Store mit ausreichender Performance.
Das Prinzip ist denkbar einfach: Was in den RAM passt, legt Ignite dort ab, der Rest landet auf der Festplatte. Den heißen RAM-Cache verwaltet Ignite automatisch. Interessant: Ignite versteht sich als memory-first, daher landen Writes zunächst im RAM, bevor sie auf die Disk persistiert werden – frisch geschriebene Daten werden also automatisch zu heißen Daten, mit allen Vor- und Nachteilen.
Wie günstig kann es werden?
Für unsere Tests haben wir Benchmarks auf GKE (Googles managed Kubernetes-Cluster) gefahren – mit 4 Knoten über 2 Zonen, je 1 Primary- und 1 Replica-Kopie pro Cache-Partition. Jeder Knoten verfügte über 2 vCPUs / 16 GB RAM und eine angeschlossene 1 TB SSD-Persistent-Disk. Das sind gerade einmal ~250 $ pro TB und Monat!
Wir konnten 200 Millionen 512 Zeichen lange Dokumente mit 7.465 Writes/Sek. ablegen, bei einer Median-Latenz von nur 1,59 ms. Und das ohne tiefergehendes Performance-Tuning, etwa einen smarten Client, der für jede Key-Anfrage weiß, welchen Knoten er ansprechen muss.
Nachdem die Initialdaten geladen waren, haben wir mit 9 Thin Clients ein typisches Tageslastmuster simuliert, die parallel zufällige Inserts, Updates und Reads ausführten – mit folgenden Ergebnissen:
- 3.682 Inserts/s, Median-Latenz 3,8 ms
- 4.229 Updates/s, Median-Latenz 4,8 ms
- 3.952 Reads/s, Median-Latenz 4,2 ms
Die Zahlen wirken vielleicht nicht spektakulär, aber das Preis-Leistungs-Verhältnis hat es in sich: 4 TB Key/Value-DB für ~1.000 $/Monat bei einstelligen Millisekunden Latenz – ein Schnäppchen!
Dieser Workload war komplett CPU-gebunden, dabei entfallen 170 $ der 250 $ pro Knoten und Monat auf den Storage. Eine Verdopplung der CPU-/RAM-Kapazität würde die Kosten auf rund 320 $/Monat pro TB heben – und ich wäre nicht überrascht, wenn die Performance dabei nahezu doppelt so hoch ausfiele [Vorsicht, Spekulation].
Falls das immer noch nicht günstig genug ist: Aus Neugier haben wir es mit Standard- (also magnetischen) Persistent Disks versucht und die TB-Kosten auf 120 $/Monat gedrückt. Das System lieferte immer noch 3.800 Dokumente/Sek. bei zufälligen Gets mit 3,2 ms mittlerer Latenz (nur Reads, keine Inserts oder Updates). Für produktive Workloads würde ich dieses Setup allerdings nicht empfehlen.
Allheilmittel?
Bislang könnte man meinen, Ignite sei "das Beste aller Zeiten". Doch sobald man es ernsthaft einsetzt, zeigen sich die Ecken und Kanten – wie der Unterschied zwischen Urlaub und Auswandern :)
Werfen wir einen Blick auf beide Seiten der Medaille: Dev und Ops.
Wie sieht es bei Dev aus?
Wer in der Java/Spring-Welt zu Hause ist, fühlt sich sofort heimisch. Vieles scheint tatsächlich nur für Java verfügbar zu sein – etwa Streaming oder Grid Computing.
Es gibt zwar Clients für andere Sprachen, doch man fühlt sich darin ein wenig wie ein Pflegekind: Offiziell gehört man zur Familie, aber so richtig? Die Dokumentation ist sehr, sehr Java-zentriert.
Nehmen wir die REST-API als Beispiel: Bei näherem Hinsehen entpuppt sie sich eher als HTTP-RPC denn als echte REST-API (im Sinne von Objekt-Collections + CRUD). Ein typischer REST-API-Aufruf sieht so aus:
GET /ignite?cmd=getorcreate&cacheName=test-cacheDoch selbst das ist im Funktionsumfang begrenzt. Um etwa Partitions-Metadaten für einen bestimmten Cache abzurufen, brauchen Sie folgenden Request:
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3&p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cacheHübsch, oder? Ich musste einen mitlauschenden HTTP-Proxy einsetzen, um das überhaupt herauszubekommen.
Und Ops?
Auch hier viele Ecken und Kanten. Wir haben Ignite auf GKE betrieben; offizielle Anleitungen dafür gibt es zwar, produktionsreif würde ich sie aber nicht nennen. Wir haben zahlreiche Verbesserungen vorgenommen, darunter:
- Multi-Zone-Setup mit Zone-Awareness von Haus aus. Beispiel: Alle Primary-Kopien liegen auf Knoten in Zone A, die Replicas auf Knoten in Zone B.
- Ein Ignite-Pod pro Knoten. Mischen Sie Ignite besser nicht mit anderen Workloads im Cluster.
- Knoten-Konfiguration über K8s ConfigMap statt per Pull aus GitHub.
- Keine dedizierte Disk für das WAL – in GCP hängt die Disk-Performance an der Größe, eine schnelle, große dedizierte Disk wäre also Geldverschwendung.
Alle unsere Verbesserungen finden Sie im folgenden GitHub-Repo: https://github.com/doitintl/ignite-gke
Es gibt aber leider noch weitere Stolpersteine:
- Ich habe IgniteVisor (das CLI-Tool) nicht dazu bringen können, sich mit dem Cluster zu verbinden. Beim Verbindungsaufbau verlangt es eine XML-Konfigurationsdatei (!), und keine der von mir bereitgestellten hat funktioniert – nicht einmal lokal auf dem Ignite-Knoten.
- Mit der Web Console hatten wir ebenfalls wenig Glück – ihr Betrieb erfordert das Starten von web-agent-, web-frontend-, web-backend- und MongoDB-(!)Pods. Das Schlimmste daran: Die Docker-Images für die web-*-Komponenten hinken hinterher und sind ein Jahr alt. Beim Versuch, sie selbst zu bauen, stellte ich fest, dass die Dockerfiles nicht self-contained sind und einen lokalen Build voraussetzen.
- Die Konfiguration verlangt das Schreiben – beziehungsweise Copy/Paste – sehr ausschweifender XML-Dateien. Schon das Aktivieren einer einfachen Boolean-Property erfordert 8 Zeilen XML und sieht so aus:

- Es scheint keine Möglichkeit zu geben, das Ignite-Cluster zu sichern, sofern Sie kein kommerzielles Abo bei GridGain haben. Reine Disk-Snapshots können zu inkonsistenten WALs zwischen Primary- und Replica-Knoten führen, sofern Sie nicht etwa Amazon-EBS-Crash-consistent-Snapshots einsetzen. Selbst dann ist die Wiederherstellung knifflig, da Ignite Knoten-IDs in den persistierten Daten einbettet und neue Knoten zu diesen passen müssen. Einer der Entwickler sagte mir, dass das Snapshot-Feature bald in die Open-Source-Edition Einzug halten soll.
Und das Fazit?
Die Technologie ist hochspannend. Sie können Ignite tatsächlich als Allround-Werkzeug einsetzen und sowohl schnelle/teure als auch langsame/günstige Workloads betreiben – sogar im selben Cluster.
Allerdings machen das wenig nutzerfreundliche Tooling und das Fehlen von Backups es schwer, das Tool für den Produktiveinsatz zu empfehlen. Schade, denn Ignite bringt viele großartige Features mit.
Ich hoffe, diese Schwächen werden in naher Zukunft behoben, damit wir Ignites Stärken in vollem Umfang ausschöpfen können.
Und wenn Sie heute schon auf GCP damit experimentieren möchten, hilft Ihnen unser ignite-gke GitHub-Repo bei einem schnellen Einstieg.
Spannend wäre es zu guter Letzt, Ignite einmal von Jepsen testen zu sehen, um herauszufinden, wie belastbar die Konsistenzgarantien in der Praxis tatsächlich sind.