
分散データベース
ホットキャッシュはRedis、大規模データはCassandra/CouchDB…これを1つでこなせるDBがあったら?
新しいプロジェクトのデータベース選びは難題です。「プロジェクトがこの先どう転ぶか読めない」という意味で難しく、しかも途中で乗り換えるのはさらに大変。私の基本方針は「適材適所」なので、結果的に複数のDBを抱え込むことも珍しくありません。
では、複数のworkloadsを1つでまかなえるくらい万能な製品があったらどうでしょうか。「器用貧乏」という言葉にも一理ありますが、最近 Apache Ignite を少し掘り下げてみたところ、これこそ「万能の達人」と呼べるかもしれないと感じました。
.elementor-widget-theme-post-featured-image {
display:none;
}
Apache Ignite — 万能の達人?
Redisの代わりになるか?
Hazelcastの代わりは?ベンチマークを見る限り、どちらもいけます。RAMファーストの分散キャッシュで、データをパーティションに分割してクラスタノード間に分散し、自動リバランスによってネイティブにスケールします。
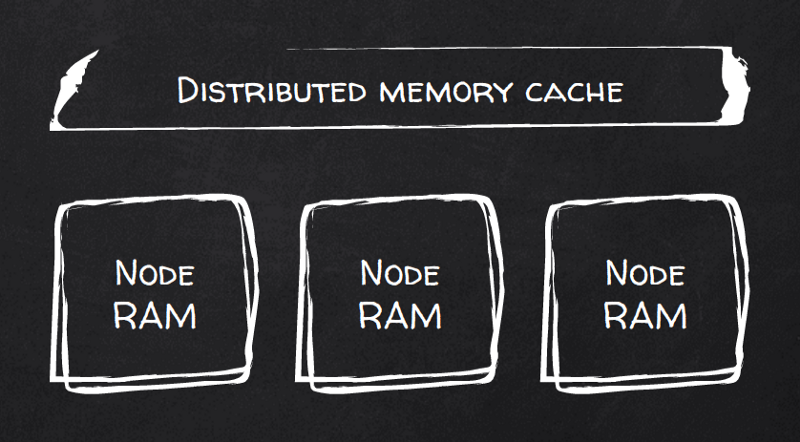
クライアントは任意のノードに接続してクエリを実行できますが、何より優れているのは、_すべての_ノードに接続したうえで、シンプルな計算によって キーごとに正しいノードへ直接問い合わせられる 点です。つまり、対象キーのローカルデータを保持するノードへ一発でアクセスできます。
永続化は?
もちろん対応しています。persistenceEnabled フラグを切り替えるだけ(とはいえXMLで8行必要)で、RAMがそのまま永続化されます。Ignite自身はこれを「Durable RAM」と呼んでいます。
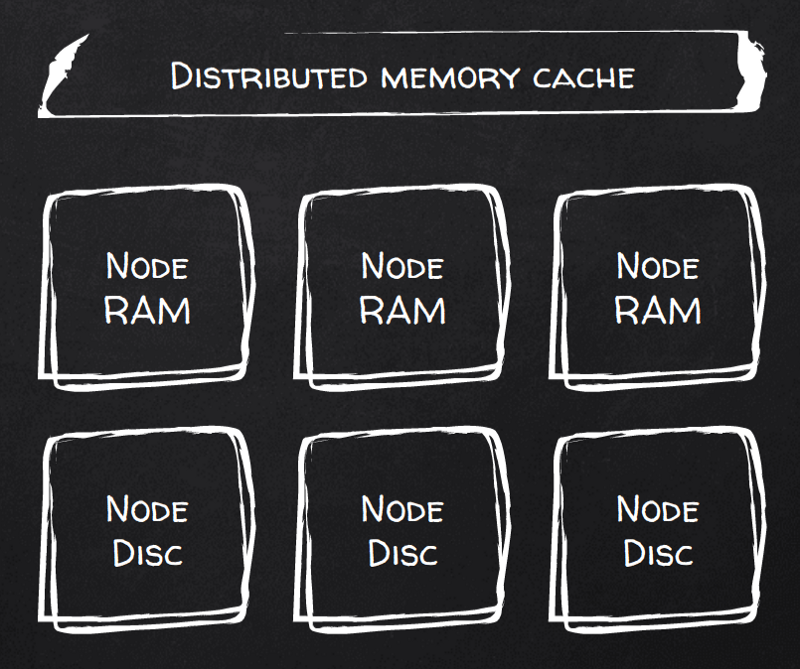
これにより、すべての書き込みが永続化されます。コピー(レプリカ)の数や書き込み一貫性レベルも調整可能で、プライマリコピーのバッファキャッシュに書き込まれた時点でACKを返す弱い一貫性から、すべてのレプリカノードでfsync完了を保証してからACKを返す強い一貫性まで選択できます。
これはまさに「正しく作られたRedis」と呼びたくなる完成度です。Redisのクラスタ構築をやったことがある方なら、この感覚はすぐ伝わるはずです。
Key/Valueにとどまらない
RedisとApache Igniteを並べて比較するのはフェアじゃない、という意見もあるでしょう。なにしろApache Igniteはkey/valueの域を超え、次のような機能まで備えているからです。
- マルチキーのトランザクション操作
- 分散JOINを含むANSI-99 SQLサポート
- グリッドコンピューティング — jarをIgniteにロードし、データローカリティを軸にコンピュートとストレージの境界を曖昧にできる
- データストリーミング
「いいね、でも高いんでしょ?」
確かに高くつきます。性能は金次第ですが、少なくともこの場合は金で性能が買えます。
とはいえ、初日からそこまでの性能が必要とは限りません。使った分だけ払う形にできるのか?もちろん可能です。クライアント案件で調べ始めたとき、まさにこの点に強く惹かれました。
方法はシンプルで、メモリ/ディスク比を好きなだけ下げれば、性能はコストに比例して下がっていきます。実は私が探していたのもこれ、つまり「そこそこの性能で安価なkey/valueストア」だったのです。
仕組みは想像どおりシンプルで、IgniteはRAMに収まる分はRAMに置き、残りはディスクに回します。ホットなRAMキャッシュは自動で管理されます。興味深いのは、Ignite自身があくまでメモリファーストを謳っている点で、書き込みはまずRAMに入ってからディスクへ永続化されます。つまり書き込まれたばかりのデータは事実上ホットデータとなり、これは良い面も悪い面もあります。
どこまで安くできるか?
テスト環境はGKE(Google管理のKubernetesクラスタ)で、2ゾーンにまたがる4ノード構成、各キャッシュパーティションごとにプライマリ1+レプリカ1、各ノードは2 vCPU / 16GB RAM、1TBのSSD永続ディスク付きです。これでTBあたり月額わずか約250ドル!
この構成で、512文字のドキュメントを2億件、7,465 writes/sec・中央値レイテンシ1.59msで投入できました。しかも、キーごとに通信先ノードを判別するスマートクライアントなどの性能チューニングは未実施の状態でです。
初期データ投入後は、9つのthinクライアントでランダムなinsert/update/readを同時実行し、日次の負荷パターンを再現してみました。結果は次のとおりです。
- 3,682 inserts/s、中央値レイテンシ3.8ms
- 4,229 updates/s、中央値レイテンシ4.8ms
- 3,952 reads/s、中央値レイテンシ4.2ms
数字単体ではインパクトに欠けるかもしれませんが、コスパに注目してください。4TBのkey/value DBが月額約1,000ドル、しかもレスポンスは一桁ミリ秒。これはお買い得です。
このworkloadは完全にCPUバウンドでしたが、ノードあたり月額250ドルのうち170ドルはストレージ代です。CPU/RAMを倍に増やしてもTBあたり月額約320ドルで収まる計算で、性能もほぼ倍近くまで伸びても不思議ではありません[あくまで推測ですが]。
これでも安くないという方のために、興味本位で標準(つまり磁気)永続ディスクに切り替えてみたところ、TBあたりの総コストは月額120ドルまで下がりました。それでもランダムgetで3,800 doc/sec、平均レイテンシ3.2msを叩き出しています(insertやupdateはなし、readのみ)。とはいえ、本番workloadにこの構成はおすすめしません。
銀の弾丸か?
ここまで読むと、Igniteは「史上最強!」のように見えるかもしれません。ところが、実際に使い始めるとあちこちで粗が見えてきます。観光と移住の違い、とでも言いましょうか :)
DevとOpsの両面から見てみましょう。
Dev側はどうか?
生粋のJava/Spring住民であれば、まさに我が家のような心地よさを感じるでしょう。実際、ストリーミングやグリッドコンピューティングなど、Java限定に見える機能も少なくありません。
他の言語向けのクライアントもありますが、どこか里子のような扱い、つまり「公式には家族の一員だけど、本当にそう?」という気分になります。ドキュメントもこれでもかというほどJava中心です。
例としてREST APIを見てみましょう。よく見るとこれは本物のREST API(オブジェクトコレクション + CRUD)というより、HTTP RPCに近いものです。典型的な呼び出しは次のような形になります。
GET /ignite?cmd=getorcreate&cacheName=test-cacheしかも、その範囲もかなり限られています。例えば、特定キャッシュのパーティションメタデータを取得しようとすると、次のようなリクエストを組み立てる羽目になります。
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3&p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cache洒落てますよね?しかもこれを突き止めるために、HTTPプロキシでパケットを覗き見るところまでやる羽目になりました。
Ops側は?
こちらにも粗が目立ちます。GKE上で動かしましたが、公式ガイドはあるものの本番運用に耐える内容とは言いがたいです。私たちは以下のような改善を多数加えました。
- ゾーンアウェアネスを備えたマルチゾーン構成を標準で実現。たとえば、すべてのプライマリコピーをゾーンAのノードに、レプリカをゾーンBのノードに配置。
- ノードあたりIgnite Pod 1個。クラスタ内でIgniteと他のworkloadsを混在させないのが無難です。
- GitHubから取得する代わりに、K8s ConfigMapでノード設定を管理。
- WAL専用ディスクは設けない — GCPではディスク性能がサイズに比例するため、高速かつ大容量の専用ディスクを用意するのはコストの無駄です。
これらの改善はすべて以下のGitHubリポジトリで公開しています: https://github.com/doitintl/ignite-gke
残念ながら、苦労はまだまだあります。
- IgniteVisor(CLIツール)をクラスタに接続できませんでした。接続時にXML設定ファイル(!)を要求してくるのですが、用意したものはどれも通らず、Igniteノード上でローカル実行しても駄目でした。
- Web Consoleもうまくいきません。動かすにはweb-agent、web-frontend、web-backend、さらにMongoDb(!)のPodを起動する必要があります。最悪なのは、web-*関連のDockerイメージが1年前から更新されておらず、自前でビルドしようとするとDockerfileが自己完結しておらず、事前にローカルビルドが必要と判明する点です。
- 設定には非常に冗長なXMLを書く(というかコピペする)必要があります。単純なboolean属性を1つ有効にするだけで8行のXMLが必要で、見た目はこんな感じです。

- GridGainの商用サブスクリプションを使わない限り、Igniteクラスタをバックアップする方法はなさそうです。単純にディスクスナップショットを取るだけでは、Amazon EBSのクラッシュ整合性スナップショットなどを使わない限り、プライマリ/レプリカ間でWALが不整合になる恐れがあります。仮に整合性が取れていても、Igniteは永続化データにノードIDを埋め込むため、新しいノードのIDを一致させる必要があり、リストアはかなり厄介です。開発者の一人によれば、スナップショット機能は近いうちにオープンソース版にも追加される予定とのことです。
結論は?
技術としては非常に興味深いものです。本当に万能ツールとして使え、高速・高コストのworkloadsと低速・低コストのworkloadsを、同じクラスタ上で同時に走らせることすら可能です。
しかし、ツール周りの不親切さとバックアップ機能の欠如により、本番利用として手放しでおすすめするのは難しい状況です。多くの優れた機能を考えると、これは非常に残念です。
これらの弱点が近いうちに解消され、Igniteの真価を存分に味わえる日が来ることを願うばかりです。
今すぐGCPで試してみたい方は、私たちのignite-gke GitHubリポジトリを使えばすぐに始められます。
最後に、JepsenでIgniteがテストされ、実運用での一貫性保証がどの程度のものか検証される日が来たら、それは非常に楽しみです。