
Commençons par un bref avertissement : DoiT International ne fait ni la promotion, ni l'apologie de la consommation de drogues licites ou illicites.
L'usage récréatif de la marijuana est illégal en Israël. Mais là où il y a une demande, il y a toujours une offre. Telegrass est un réseau dédié à l'achat de marijuana en Israël. Il s'appuie sur Telegram, une application de messagerie gratuite dont les communications sont chiffrées de bout en bout. Le réseau propose des livraisons rapides ainsi que la possibilité de laisser des avis sur les vendeurs. Le chiffre d'affaires mensuel de Telegrass est estimé à 17 millions de dollars.
Les utilisateurs peuvent consulter les avis sur les vendeurs afin de mieux choisir auprès de qui acheter. Un bot dédié les guide dans la rédaction d'un avis et leur permet de noter le vendeur sur 4 critères, chacun évalué de 0 à 5.
- Comment s'est passée la communication avec le vendeur ?
- Quelle était la qualité du produit ?
- Le prix était-il juste ?
- La livraison a-t-elle été ponctuelle ?
Acquisition des données
Commençons par récupérer les avis depuis Telegram. Nous utiliserons telethon, une bibliothèque Python pour interagir avec l'API de Telegram. Seul le corps du message nous intéresse : les avis étant publiés par des bots (après une modération humaine), les métadonnées du message présentent peu d'intérêt.
https://gist.github.com/avivl/884ec584b19f4c079153e2f5891181a6
Voici le fichier de configuration :
https://gist.github.com/avivl/007efb0db4a2ebcf5539f054bc82a5d8
Lançons-le :
python geth.py >reviews.txt
La sortie ressemble à ceci :
['ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע', 'חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17', 'חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.', '\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)', 'להגשת חוות דעת: @TelegrassBot לשירותכם!']
Comme vous pouvez le constater (même sans lire l'hébreu moderne), il s'agit d'un mélange de lettres, de symboles et de chiffres sans structure apparente (rappelons aussi que l'hébreu se lit de droite à gauche, contrairement à l'anglais). L'étape suivante consiste donc à préparer les données pour l'analyse.
Préparation des données
Avant de pouvoir interroger et analyser les données, il faut les préparer : les nettoyer et les structurer.
Or, écrire le code nécessaire est une tâche très chronophage et plutôt fastidieuse, jalonnée d'essais et d'erreurs. Heureusement pour nous, Google propose un nouveau service (encore en bêta) : Cloud Dataprep. Pour citer le site du produit :
Google Cloud Dataprep est un service de données intelligent qui permet d'explorer, de nettoyer et de préparer visuellement des données structurées et non structurées en vue de leur analyse. Cloud Dataprep est serverless et fonctionne à toute échelle. Aucune infrastructure à déployer ni à gérer. Une préparation des données simple, en quelques clics et sans code.
Je me suis dit que les données d'avis allaient donner du fil à retordre à Dataprep. Pourtant, en une soixantaine d'étapes triviales (listées ci-dessous) et sans écrire la moindre ligne de code, j'ai pu créer des données structurées à partir des notes. L'interface de DataPrep affiche la transformation en temps réel, ce qui permet de déboguer et d'ajuster le processus de manière visuelle. Certaines étapes consistaient à découper les données selon des caractères ou des motifs, et à supprimer les lignes contenant des valeurs invalides.
Enfin, Cloud Dataprep prend nativement en charge l'écriture des données vers une grande variété de sources. Pour ma part, j'ai opté pour Google BigQuery, la base de données analytique serverless de Google.
https://gist.github.com/avivl/3ec0d5fb38f054c8a7e8b673148321c7
Les données sont désormais propres et bien structurées.
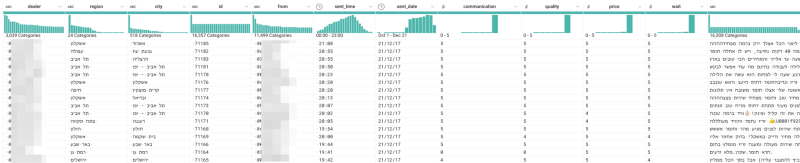 Interface utilisateur de Google Cloud Dataprep
Interface utilisateur de Google Cloud Dataprep
Analyse
Maintenant que les données sont propres et bien rangées, il est temps de les analyser. Voyons comment le prix est lié aux autres notes grâce à la fonction CORR() de BigQuery, qui calcule le coefficient de corrélation de Pearson. Un coefficient de -1 indique une forte corrélation négative, +1 une forte corrélation positive, et 0 signifie l'absence de corrélation.
https://gist.github.com/avivl/ed30a0c2d1978ea4eaa0f6b9c51ec5b6
price_wait, price_communication, price_quality
0,679, 0,774, 0,793
Les facteurs les plus corrélés à la satisfaction sont donc le prix et la qualité du produit. Peut-on faire confiance à ces notes ? Les notes en ligne sont souvent sujettes à un biais d'auto-sélection. Vérifions si les avis sur Telegrass présentent le même problème.
https://gist.github.com/avivl/e9ecfdb9342a23af9a6515b40d581e4e
D'après les résultats, soit nos vendeurs sont irréprochables sur tous les plans, soit les notes des utilisateurs sont biaisées, soit les gens ont tendance à se montrer plus positifs après avoir consommé le produit ☺️
Voyons à présent quels sont les bigrammes les plus fréquents et s'ils sont corrélés aux notes élevées.
https://gist.github.com/avivl/0e6ddbfdf1d7a4ee3d16c60bb0d18708
Les bigrammes les plus fréquents sont :
- Mec génial
- Produit incroyable
- Vivement recommandé
On constate une forte corrélation entre les notes élevées et les bigrammes les plus courants dans les avis.
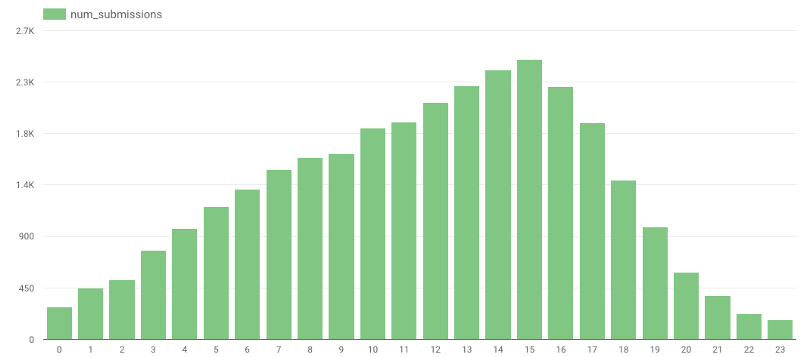
Pouvez-vous deviner à quel moment de la journée les avis sont le plus souvent publiés ? Intuitivement, j'aurais dit en fin de soirée ou pendant la nuit. Les données réelles m'ont pourtant donné tort :
https://gist.github.com/avivl/8e7e828509407676ba129c1f376a06a6
Vérifions maintenant s'il existe une corrélation entre la taille des villes et le nombre d'avis. Commençons par identifier les 20 villes qui génèrent le plus d'avis. Les résultats seront ajoutés à une nouvelle table (by_city).
https://gist.github.com/avivl/84b0b258e47236b30d298e05f0335e74
Ajoutons à présent une nouvelle colonne population que nous remplirons (jeu de mots assumé) avec les données du Bureau central des statistiques d'Israël (chiffres de fin 2016). Voyons les résultats :
Avant même de comparer les résultats, un fait saute aux yeux. Près de 1 % des habitants de Tel-Aviv publient des avis sur Telegrass ! Pas seulement consommer le produit ou l'acheter, mais participer activement à la communauté.
Examinons les premiers et les derniers résultats. Si vous connaissez un peu la démographie d'Israël, cela ne devrait guère vous surprendre. Tel-Aviv est une ville à la population jeune, pôle de nombreuses entreprises high tech, et la plus libérale d'Israël. Ses habitants sont très à l'aise avec la technologie et n'hésitent pas à donner leur avis. Au bas du classement figure Bnei Brak, ville majoritairement peuplée de personnes religieuses à faibles revenus, ce qui explique sans peine le faible volume d'avis publiés.
Il est maintenant temps de s'amuser un peu avec le ML grâce à TensorFlow. J'ai d'abord créé un jeu d'entraînement et un jeu de test.
https://gist.github.com/avivl/92454358fc144da18e0f3a0c962fe5ea
J'ai repris le code écrit par Akshay Pai en l'adaptant à mes besoins.
Une fois les données chargées et préparées, voici le code de ML :
https://gist.github.com/avivl/3f3e876286670e19698a4bcc60f2313d
Une fois l'entraînement terminé, j'ai utilisé model.predict pour prédire la note.
https://gist.github.com/avivl/70a83e35793d3800e6c1d25fc55f97e0
J'ai chargé le jeu de test et calculé la RMSE. Elle s'établit à 1,4 sur une échelle allant de 0 à 20 : les résultats ne sont pas exceptionnels, mais ils permettent tout de même de prédire assez bien la note numérique à partir du texte.
Pas besoin d'être un data scientist ou un data engineer chevronné pour tirer des enseignements intéressants d'un texte non structuré, sans écrire la moindre ligne de code pour le préparer à l'analyse. Vous pouvez ensuite l'exploiter avec BigQuery et TensorFlow pour en dégager des insights pertinents.