
Una breve premessa: DoiT International non promuove né incoraggia in alcun modo l'uso di sostanze, lecite o illecite.
In Israele l'uso ricreativo della marijuana è illegale. Ma dove c'è domanda, c'è sempre offerta. Telegrass è un network per l'acquisto di marijuana in Israele, che opera tramite Telegram: un'app di messaggistica gratuita con comunicazioni cifrate end-to-end. Il network garantisce consegne rapide e permette di lasciare recensioni sui venditori. Il fatturato mensile di Telegrass è stimato intorno ai 17 milioni di dollari.
Gli utenti possono consultare le recensioni sui venditori per scegliere meglio da chi acquistare. Un bot dedicato accompagna l'utente nella stesura della recensione e nella valutazione del venditore su 4 parametri, ciascuno con un punteggio da 0 a 5.
- Com'è stata la comunicazione con il venditore?
- Qual era la qualità del prodotto?
- Il prezzo era equo?
- La consegna è stata puntuale?
Acquisizione dei dati
Iniziamo recuperando le recensioni da Telegram. Useremo telethon, una libreria Python per interagire con le API di Telegram. Ci interessa solo il corpo del messaggio: dato che le recensioni sono inviate da bot (dopo una revisione umana), i metadati dei messaggi non sono particolarmente utili.
https://gist.github.com/avivl/884ec584b19f4c079153e2f5891181a6
Ecco il file di configurazione
https://gist.github.com/avivl/007efb0db4a2ebcf5539f054bc82a5d8
Eseguiamolo:
python geth.py >reviews.txt
L'output sarà più o meno questo:
['ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע', 'חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17', 'חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.', '\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)', 'להגשת חוות דעת: @TelegrassBot לשירותכם!']
Come si vede (anche senza conoscere l'ebraico moderno), si tratta di un insieme di lettere, simboli e numeri privo di una struttura riconoscibile (va inoltre ricordato che l'ebraico si legge da destra a sinistra, al contrario dell'inglese). Il passo successivo è quindi preparare i dati per l'analisi.
Preparazione dei dati
Prima di poter interrogare e analizzare i dati, è necessario prepararli: ripulirli e dare loro una struttura più solida.
Scrivere il codice per farlo è però un'operazione lunga e piuttosto noiosa, costellata di tentativi ed errori. Per fortuna è disponibile un nuovo servizio di Google (ancora in beta): Cloud Dataprep. Per citare il sito ufficiale del prodotto:
"Google Cloud Dataprep è un servizio dati intelligente per esplorare visivamente, ripulire e preparare dati strutturati e non strutturati per l'analisi. Cloud Dataprep è serverless e funziona a qualsiasi scala. Nessuna infrastruttura da implementare o gestire. Preparazione dei dati semplice, con pochi clic e senza scrivere codice."
Mi sono detto che i dati delle recensioni avrebbero messo davvero alla prova Dataprep. In appena una sessantina di passaggi banali (elencati di seguito) e senza scrivere una sola riga di codice, sono riuscito a ottenere dati strutturati a partire dalle valutazioni. L'interfaccia di DataPrep mostra le trasformazioni in tempo reale, consentendo un debug visivo e l'affinamento del processo. Alcuni passaggi prevedono la suddivisione dei dati in base a caratteri o pattern e l'eliminazione delle righe con valori non validi.
Infine, Cloud Dataprep supporta nativamente la scrittura dei dati risultanti su un'ampia gamma di destinazioni. Nel mio caso ho scelto Google BigQuery, il database analitico serverless di Google.
https://gist.github.com/avivl/3ec0d5fb38f054c8a7e8b673148321c7
Ora i dati sono puliti e ordinati.
 Interfaccia utente di Google Cloud Dataprep
Interfaccia utente di Google Cloud Dataprep
Analisi
Una volta sistemati i dati, è il momento di analizzarli. Vediamo come il prezzo è correlato alle altre valutazioni con la funzione CORR() di BigQuery, che calcola il coefficiente di correlazione di Pearson. Un coefficiente pari a -1 indica una forte correlazione negativa, +1 una forte correlazione positiva, mentre 0 segnala l'assenza di correlazione.
https://gist.github.com/avivl/ed30a0c2d1978ea4eaa0f6b9c51ec5b6
price_wait, price_communication, price_quality
0.679, 0.774, 0.793
Come si nota, le voci più correlate alla soddisfazione sono il prezzo e la qualità del prodotto. Possiamo fidarci delle valutazioni? In rete sono spesso soggette al self-selection bias. Vediamo se le recensioni di Telegrass presentano lo stesso problema.
https://gist.github.com/avivl/e9ecfdb9342a23af9a6515b40d581e4e
Stando ai risultati, o i venditori sono eccezionali sotto ogni aspetto, oppure c'è un bias nelle valutazioni degli utenti, oppure ancora dopo aver consumato il prodotto le persone tendono a essere più positive ☺️
Vediamo ora quali sono i bigrammi più ricorrenti e se sono correlati alle valutazioni più alte.
https://gist.github.com/avivl/0e6ddbfdf1d7a4ee3d16c60bb0d18708
I bigrammi più frequenti sono:
- Amazing man
- Awesome product
- Highly recommended
Si nota una forte correlazione tra i punteggi più alti e i bigrammi più ricorrenti nelle recensioni.
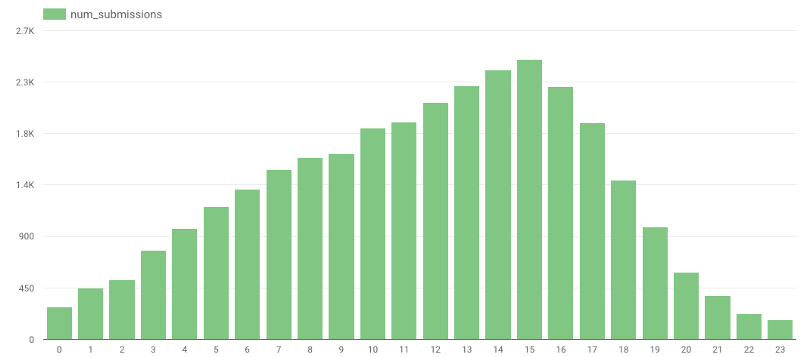
Provate a indovinare qual è la fascia oraria preferita per inviare una recensione. A occhio avrei detto la sera tardi o la notte, ma i dati mi hanno smentito:
https://gist.github.com/avivl/8e7e828509407676ba129c1f376a06a6
Vediamo ora se c'è correlazione tra le dimensioni della città e il numero di recensioni. Partiamo individuando le 20 città che producono più recensioni. I risultati verranno aggiunti a una nuova tabella (by_city).
https://gist.github.com/avivl/84b0b258e47236b30d298e05f0335e74
Aggiungiamo ora una nuova colonna "population" e la popoliamo (gioco di parole voluto) con i dati dell'Israel Central Bureau of Statistics (riferiti a fine 2016). Ecco i risultati:
Prima ancora di confrontare i risultati, un dato salta all'occhio. Quasi l'1% della popolazione di Tel Aviv scrive recensioni su Telegrass!, non si limita a usare il prodotto o ad acquistarlo, ma partecipa attivamente.
Concentriamoci sul primo e sull'ultimo risultato. Chi conosce anche solo a grandi linee la demografia di Israele non si stupirà. Tel Aviv è una città con una popolazione giovane, polo di numerose aziende high-tech e la più liberale del paese. I suoi abitanti sono molto inclini alla tecnologia e amano esprimere la propria opinione. In fondo alla classifica troviamo invece Bnei Brak, una città a forte presenza religiosa e con redditi bassi: è quindi piuttosto naturale che siano in pochi a scrivere recensioni.
È il momento di mettersi un po' alla prova con il ML usando TensorFlow. Per prima cosa ho creato un training set e un test set.
https://gist.github.com/avivl/92454358fc144da18e0f3a0c962fe5ea
Ho preso il codice scritto da Akshay Pai e l'ho adattato alle mie esigenze.
Dopo aver caricato e preparato i dati, il codice ML è il seguente:
https://gist.github.com/avivl/3f3e876286670e19698a4bcc60f2313d
Una volta completato il training, ho usato model.predict per stimare il punteggio.
https://gist.github.com/avivl/70a83e35793d3800e6c1d25fc55f97e0
Ho caricato il test set e calcolato l'RMSE. L'RMSE è pari a 1,4 su una scala da 0 a 20: non è un risultato eccezionale, ma permette comunque di prevedere con buona approssimazione il punteggio numerico a partire dal testo.
Non serve essere data scientist o data engineer a tempo pieno per ricavare insight interessanti da un testo non strutturato, senza scrivere una sola riga di codice per prepararlo all'analisi. A quel punto basta analizzarlo con BigQuery e TensorFlow per scoprire spunti di valore.