
Empecemos con un breve descargo: DoiT International no promueve, aprueba ni defiende el consumo de drogas, lícitas o ilícitas.
El uso recreativo de la marihuana es ilegal en Israel. Pero donde hay demanda, siempre hay oferta. Telegrass es una red para comprar marihuana en Israel. Funciona sobre Telegram, una aplicación de mensajería gratuita con cifrado de extremo a extremo. La red ofrece entregas rápidas y permite dejar reseñas sobre los vendedores. Se estima que la facturación mensual de Telegrass ronda los 17 millones de dólares.
Los usuarios pueden leer reseñas sobre los vendedores para tomar mejores decisiones de compra. Existe un bot convencional que ayuda al usuario a redactar la reseña y calificar al vendedor en 4 aspectos, cada uno con una puntuación de 0 a 5.
- ¿Cómo fue la comunicación con el vendedor?
- ¿Qué tal la calidad del producto?
- ¿El precio fue justo?
- ¿Llegó a tiempo?
Obtención de los datos
Empecemos por extraer las reseñas de Telegram. Vamos a usar telethon, una librería de Python para trabajar con la API de Telegram. Solo nos interesa el cuerpo del mensaje, ya que las reseñas las envían bots (tras cierta revisión humana), por lo que los metadatos del mensaje no aportan demasiado.
https://gist.github.com/avivl/884ec584b19f4c079153e2f5891181a6
Este es el archivo de configuración:
https://gist.github.com/avivl/007efb0db4a2ebcf5539f054bc82a5d8
Vamos a ejecutarlo:
python geth.py >reviews.txt
El resultado se ve más o menos así:
[‘ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע’, ‘חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17’, ‘חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.’, ‘\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)’, ‘להגשת חוות דעת: @TelegrassBot לשירותכם!’]
Como se puede ver (incluso si no lees hebreo moderno), hay una mezcla de letras, símbolos y números sin una estructura aparente (recuerda además que el hebreo se lee de derecha a izquierda, al contrario del inglés). Por eso, el siguiente paso es preparar los datos para el análisis.
Preparación de los datos
Antes de poder consultar y analizar los datos, hay que prepararlos: limpiarlos y darles más estructura.
Sin embargo, escribir el código para hacerlo es una tarea muy lenta y bastante tediosa, con mucho ensayo y error. Por suerte, existe un nuevo servicio de Google (todavía en beta): Cloud Dataprep. Citando el sitio del producto:
"Google Cloud Dataprep es un servicio de datos inteligente para explorar, limpiar y preparar visualmente datos estructurados y no estructurados con miras al análisis. Cloud Dataprep es serverless y funciona a cualquier escala. No hay infraestructura que desplegar ni administrar. Preparación de datos sencilla, con clics y sin código."
Pues bien, descubrí que los datos de las reseñas le podían dar batalla a Dataprep. Así que en apenas unos 60 pasos triviales (que se listan más abajo) y sin escribir ni una sola línea de código logré crear datos estructurados a partir de las calificaciones. La interfaz de DataPrep permite ver la transformación en tiempo real, lo que facilita depurar visualmente y ajustar el proceso. Algunos pasos consistieron en dividir los datos según caracteres o patrones y descartar filas con valores inválidos.
Por último, Cloud Dataprep admite de forma nativa la escritura de los datos resultantes en una gran variedad de orígenes. En mi caso, opté por Google BigQuery, la base de datos analítica serverless de Google.
https://gist.github.com/avivl/3ec0d5fb38f054c8a7e8b673148321c7
Ahora los datos están limpios y ordenados.
 Interfaz de Google Cloud Dataprep
Interfaz de Google Cloud Dataprep
Análisis
Una vez que los datos están limpios y ordenados, llega el momento de analizarlos. Veamos cómo se relaciona el precio con las demás calificaciones usando la función CORR() de BigQuery, que calcula el coeficiente de Correlación de Pearson. Un coeficiente de -1 indica una correlación negativa fuerte, +1 indica una correlación positiva fuerte y 0 significa que no hay correlación.
https://gist.github.com/avivl/ed30a0c2d1978ea4eaa0f6b9c51ec5b6
price_wait, price_communication, price_quality
0.679, 0.774, 0.793
Como se ve, lo que más se correlaciona con la satisfacción es el precio y la calidad del producto. ¿Podemos confiar en las calificaciones? Las puntuaciones online suelen estar afectadas por el sesgo de autoselección. Veamos si las reseñas de Telegrass tienen el mismo problema.
https://gist.github.com/avivl/e9ecfdb9342a23af9a6515b40d581e4e
A juzgar por los resultados, o nuestros vendedores son excelentes en todos los sentidos, o hay algo de sesgo en las calificaciones, o quizás después de usar el producto la gente tiende a estar de mejor humor ☺️
Veamos ahora cuáles son los bigramas más populares y si se correlacionan con las calificaciones altas.
https://gist.github.com/avivl/0e6ddbfdf1d7a4ee3d16c60bb0d18708
Los bigramas más populares son:
- Amazing man
- Awesome product
- Highly recommended
Se observa una alta correlación entre las puntuaciones altas y los bigramas más frecuentes en las reseñas.
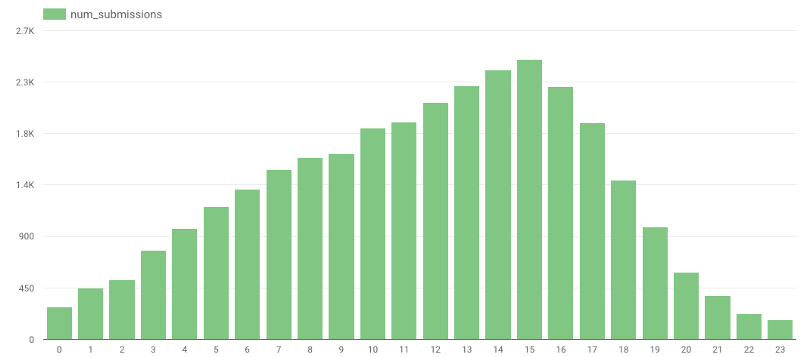
¿Adivinas cuál es el momento más popular para enviar una reseña? Si tuviera que adivinarlo, diría que en algún momento de la noche, pero los datos reales me demostraron lo contrario:
https://gist.github.com/avivl/8e7e828509407676ba129c1f376a06a6
Ahora veamos si existe correlación entre el tamaño de la ciudad y la cantidad de reseñas. Empecemos por obtener las 20 ciudades que más reseñas generan. Los resultados se agregarán a una nueva tabla (by_city).
https://gist.github.com/avivl/84b0b258e47236b30d298e05f0335e74
Ahora vamos a agregar una nueva columna de población y la llenaremos con datos de la Oficina Central de Estadística de Israel (cifras a fines de 2016). Veamos los resultados:
Antes de comparar los resultados, hay un dato que salta a la vista. ¡Casi el 1% de la población de Tel Aviv escribe reseñas en Telegrass! No se trata solo de usar el producto o comprarlo, sino de participar activamente.
Veamos los primeros y los últimos resultados. Si conoces un poco la demografía de Israel, no debería sorprenderte. Tel Aviv es una ciudad con población joven y centro de muchas empresas tecnológicas; es la ciudad más liberal de Israel. Su gente maneja muy bien la tecnología y no duda en opinar. En el otro extremo aparece Bnei Brak, una ciudad con predominio de población religiosa de bajos ingresos, así que es bastante obvio por qué no hay tantas personas escribiendo reseñas.
Ahora es momento de jugar un poco con ML usando TensorFlow. Primero creé un conjunto de entrenamiento y otro de prueba.
https://gist.github.com/avivl/92454358fc144da18e0f3a0c962fe5ea
Tomé el código escrito por Akshay Pai y lo ajusté un poco a mis necesidades.
Tras cargar los datos y prepararlos, el código de ML queda así:
https://gist.github.com/avivl/3f3e876286670e19698a4bcc60f2313d
Una vez terminado el entrenamiento, usé model.predict para predecir la puntuación.
https://gist.github.com/avivl/70a83e35793d3800e6c1d25fc55f97e0
Cargué el conjunto de prueba y calculé el RMSE. El RMSE es 1.4 y los valores van de 0 a 20, así que los resultados no son espectaculares, pero permiten predecir bastante bien la calificación numérica a partir del texto.
No hace falta ser un data scientist o data engineer con todas las de la ley para sacar conclusiones interesantes de un texto sin estructura, y sin escribir una sola línea de código para prepararlo. Después puedes analizarlo con BigQuery y TensorFlow para descubrir hallazgos interesantes.