
Vorab ein kurzer Hinweis: DoiT International befürwortet, duldet oder fördert weder legalen noch illegalen Drogenkonsum.
Der Konsum von Marihuana zu Freizeitzwecken ist in Israel verboten. Doch wo Nachfrage besteht, findet sich auch ein Angebot. Telegrass ist ein Netzwerk für den Marihuana-Kauf in Israel. Es setzt auf Telegram auf – einem kostenlosen Messenger mit Ende-zu-Ende-Verschlüsselung. Das Netzwerk verspricht schnelle Lieferungen und ermöglicht es, Verkäufer zu bewerten. Der monatliche Umsatz von Telegrass wird auf 17 Millionen US-Dollar geschätzt.
Über die Bewertungen können Nutzer einschätzen, bei wem sie kaufen wollen. Ein einfacher Bot führt durch den Bewertungsprozess und lässt den Verkäufer in 4 Kategorien auf einer Skala von 0 bis 5 bewerten:
- Wie war die Kommunikation mit dem Verkäufer?
- Wie war die Qualität des Produkts?
- War der Preis fair?
- Wurde pünktlich geliefert?
Datenerhebung
Beginnen wir damit, die Bewertungen aus Telegram abzugreifen. Wir setzen telethon ein – eine Python-Bibliothek für die Arbeit mit der Telegram-API. Uns interessiert nur der Nachrichtentext, denn die Bewertungen werden (nach kurzer manueller Prüfung) von Bots eingestellt; die Metadaten der Nachrichten geben daher nicht viel her.
https://gist.github.com/avivl/884ec584b19f4c079153e2f5891181a6
Hier die Konfigurationsdatei:
https://gist.github.com/avivl/007efb0db4a2ebcf5539f054bc82a5d8
Und ab geht's:
python geth.py >reviews.txt
Die Ausgabe sieht in etwa so aus:
[‘ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע’, ‘חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17’, ‘חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.’, ‘\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)’, ‘להגשת חוות דעת: @TelegrassBot לשירותכם!’]
Auch ohne Hebräischkenntnisse erkennt man: ein Mix aus Buchstaben, Symbolen und Zahlen ohne erkennbare Struktur (zudem wird Hebräisch von rechts nach links geschrieben, im Gegensatz zum Englischen). Im nächsten Schritt müssen wir die Daten daher für die Analyse aufbereiten.
Datenaufbereitung
Bevor wir die Daten abfragen und analysieren können, müssen wir sie aufbereiten – also bereinigen und stärker strukturieren.
Den entsprechenden Code zu schreiben, ist allerdings zeitraubend, vergleichsweise eintönig und mit viel Trial-and-Error verbunden. Zum Glück gibt es einen neuen Service von Google (noch in der Beta) – Cloud Dataprep. Zitat von der Produktseite:
"Google Cloud Dataprep ist ein intelligenter Daten-Service zum visuellen Erkunden, Bereinigen und Aufbereiten strukturierter und unstrukturierter Daten für Analysen. Cloud Dataprep ist serverless und skaliert beliebig. Es muss keine Infrastruktur bereitgestellt oder verwaltet werden. Datenaufbereitung per Klick – ganz ohne Code."
Ich war neugierig, ob die Bewertungsdaten Dataprep ins Schwitzen bringen. Und tatsächlich: In rund 60 trivialen Schritten (siehe unten) und ohne eine einzige Zeile Code habe ich aus den Bewertungen strukturierte Daten gemacht. Die Dataprep-Oberfläche zeigt die Transformationen in Echtzeit an, sodass sich der Prozess visuell prüfen und anpassen lässt. Einige Schritte teilten die Daten anhand bestimmter Zeichen oder Muster auf oder verwarfen Zeilen mit ungültigen Werten.
Cloud Dataprep schreibt das Ergebnis nativ in eine Vielzahl von Datenquellen. Ich habe mich für Google BigQuery entschieden – die serverlose Analysedatenbank von Google.
https://gist.github.com/avivl/3ec0d5fb38f054c8a7e8b673148321c7
Jetzt sind die Daten sauber und übersichtlich.
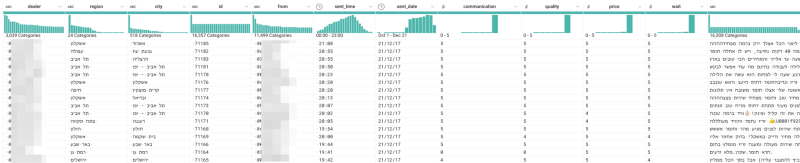 Benutzeroberfläche von Google Cloud Dataprep
Benutzeroberfläche von Google Cloud Dataprep
Analyse
Sind die Daten sauber, geht es an die Analyse. Mit der CORR()-Funktion von BigQuery prüfen wir, wie der Preis mit den anderen Bewertungen zusammenhängt – die Funktion berechnet den Pearson-Korrelationskoeffizienten. Ein Wert von -1 zeigt eine starke negative, +1 eine starke positive Korrelation; bei 0 besteht kein Zusammenhang.
https://gist.github.com/avivl/ed30a0c2d1978ea4eaa0f6b9c51ec5b6
price_wait, price_communication, price_quality
0,679, 0,774, 0,793
Wie man sieht, korrelieren Preis und Produktqualität am stärksten mit der Zufriedenheit. Können wir den Bewertungen trauen? Online-Bewertungen unterliegen häufig einem Self-Selection Bias. Schauen wir, ob das auch für Telegrass gilt.
https://gist.github.com/avivl/e9ecfdb9342a23af9a6515b40d581e4e
Die Ergebnisse legen nahe: Entweder sind unsere Verkäufer in jeder Hinsicht erstklassig, oder die Nutzerbewertungen sind verzerrt – oder die Leute sind nach dem Konsum schlicht entspannter ☺️
Sehen wir uns nun an, welche Bigramme am häufigsten vorkommen und ob sie mit hohen Bewertungen korrelieren.
https://gist.github.com/avivl/0e6ddbfdf1d7a4ee3d16c60bb0d18708
Die häufigsten Bigramme sind:
- Amazing man
- Awesome product
- Highly recommended
Es zeigt sich eine hohe Korrelation zwischen hohen Bewertungen und den häufigsten Bigrammen.
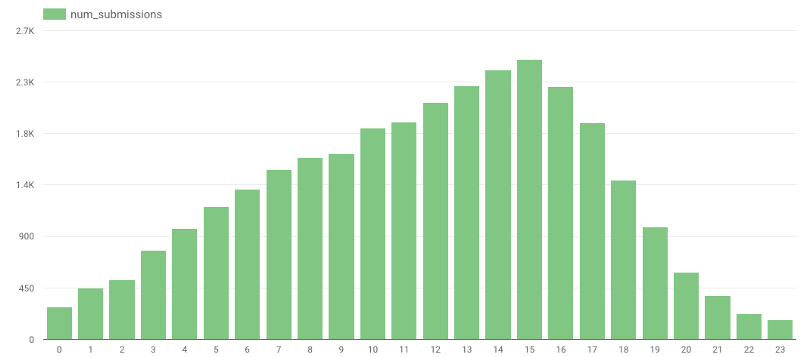
Können Sie raten, wann die meisten Bewertungen abgegeben werden? Spontan hätte ich auf den späten Abend oder die Nacht getippt – die tatsächlichen Daten haben mich eines Besseren belehrt:
https://gist.github.com/avivl/8e7e828509407676ba129c1f376a06a6
Als Nächstes prüfen wir, ob ein Zusammenhang zwischen Stadtgröße und Anzahl der Bewertungen besteht. Wir starten mit den 20 Städten, die die meisten Bewertungen liefern. Die Ergebnisse landen in einer neuen Tabelle (by_city).
https://gist.github.com/avivl/84b0b258e47236b30d298e05f0335e74
Nun ergänzen wir eine neue Spalte "population" mit Daten des israelischen Statistikamts (Stand: Ende 2016). Werfen wir einen Blick auf die Ergebnisse:
Bevor wir vergleichen, fällt eine Sache sofort ins Auge. Fast 1 % der Einwohner Tel Avivs schreiben Bewertungen auf Telegrass! Sie konsumieren oder kaufen also nicht nur, sondern beteiligen sich aktiv.
Schauen wir auf das erste und das letzte Ergebnis. Wer mit der Demografie Israels vertraut ist, wird kaum überrascht sein. Tel Aviv hat eine junge Bevölkerung, ist Standort vieler High-Tech-Unternehmen und die liberalste Stadt des Landes. Die Menschen sind technikaffin und teilen ihre Meinung gerne. Am Ende der Liste steht Bnei Brak: Die Stadt ist von einer einkommensschwachen, religiösen Bevölkerung geprägt – wenig überraschend, dass dort kaum Bewertungen verfasst werden.
Jetzt experimentieren wir ein wenig mit ML und TensorFlow. Zunächst habe ich einen Trainings- und einen Test-Datensatz erstellt.
https://gist.github.com/avivl/92454358fc144da18e0f3a0c962fe5ea
Ich habe den Code von Akshay Pai übernommen und an meine Anforderungen angepasst.
Nach dem Laden und Aufbereiten der Daten sieht der ML-Code so aus:
https://gist.github.com/avivl/3f3e876286670e19698a4bcc60f2313d
Nach Abschluss des Trainings habe ich mit model.predict den Score vorhergesagt.
https://gist.github.com/avivl/70a83e35793d3800e6c1d25fc55f97e0
Anschließend habe ich den Test-Datensatz geladen und den RMSE berechnet. Er liegt bei 1,4, die Werte bewegen sich zwischen 0 und 20 – nicht überragend, aber das Modell sagt aus dem Text recht zuverlässig die numerische Bewertung voraus.
Man muss also kein ausgewachsener Data Scientist oder Data Engineer sein, um aus unstrukturiertem Text spannende Erkenntnisse zu gewinnen – und das ohne eine einzige Zeile Code für die Datenaufbereitung. Anschließend lassen sich die Daten mit BigQuery und TensorFlow analysieren und liefern interessante Insights.