
Antes de tudo, um breve aviso — a DoiT International não promove, aprova nem incentiva o uso lícito ou ilícito de drogas.
O uso recreativo de maconha é ilegal em Israel. Mas onde há demanda, sempre aparece oferta. A Telegrass é uma rede de compra de maconha em Israel que funciona em cima do Telegram — um aplicativo de mensagens gratuito com criptografia de ponta a ponta. A rede oferece entregas rápidas e permite que os clientes avaliem os vendedores. O faturamento mensal da Telegrass é estimado em US$ 17 milhões.
Os usuários podem ler avaliações sobre os vendedores para decidir melhor de quem vão comprar. Existe um bot convencional que ajuda o usuário a escrever a avaliação e dar nota ao vendedor em 4 quesitos, com cada nota indo de 0 a 5.
- Como foi a comunicação com o vendedor?
- Qual foi a qualidade do produto?
- O preço foi justo?
- A entrega saiu no prazo?
Coleta dos dados
Vamos começar pegando as avaliações no Telegram. Para isso, usamos a telethon — uma biblioteca Python para trabalhar com a API do Telegram. Só nos interessa o corpo da mensagem, já que as avaliações são publicadas por bots (depois de uma revisão humana), então os metadados não trazem nada de muito relevante.
https://gist.github.com/avivl/884ec584b19f4c079153e2f5891181a6
E aqui está o arquivo de configuração:
https://gist.github.com/avivl/007efb0db4a2ebcf5539f054bc82a5d8
Hora de rodar:
python geth.py >reviews.txt
A saída fica mais ou menos assim:
[‘ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע’, ‘חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17’, ‘חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.’, ‘\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)’, ‘להגשת חוות דעת: @TelegrassBot לשירותכם!’]
Como dá para perceber (mesmo que você não leia hebraico moderno), há uma mistura de letras, símbolos e números sem nenhuma estrutura aparente (vale lembrar que o hebraico é escrito da direita para a esquerda, ao contrário do inglês). O próximo passo, então, é preparar esses dados para análise.
Preparação dos dados
Antes de consultar e analisar os dados, precisamos prepará-los — ou seja, limpá-los e dar a eles uma estrutura mais clara.
Só que escrever esse código costuma ser uma tarefa demorada e bem chata, com muita tentativa e erro. Por sorte, existe um serviço novo do Google (ainda em beta) — o Cloud Dataprep. Citando o site do produto:
"O Google Cloud Dataprep é um serviço inteligente de dados para explorar, limpar e preparar visualmente dados estruturados e não estruturados para análise. O Cloud Dataprep é serverless e funciona em qualquer escala. Não há infraestrutura para implantar ou gerenciar. Preparação de dados fácil, com cliques e sem código."
Pois bem, achei que os dados das avaliações poderiam dar trabalho ao Dataprep. Mas, em apenas 60 passos triviais (listados abaixo) e sem escrever uma única linha de código, consegui transformar as avaliações em dados estruturados. A interface do DataPrep mostra a transformação em tempo real, o que ajuda a depurar e ajustar o processo visualmente. Algumas etapas envolveram dividir os dados com base em caracteres ou padrões e descartar linhas com valores inválidos.
Por fim, o Cloud Dataprep tem suporte nativo para gravar o resultado em uma grande variedade de fontes de dados. No meu caso, optei pelo Google BigQuery — o banco de dados analítico serverless do Google.
https://gist.github.com/avivl/3ec0d5fb38f054c8a7e8b673148321c7
Agora os dados estão limpos e organizados.
 Interface do Google Cloud Dataprep
Interface do Google Cloud Dataprep
Análise
Com os dados todos arrumados, é hora de analisar. Vamos ver como o preço se relaciona com as outras notas usando a função CORR() do BigQuery, que calcula o coeficiente de Correlação de Pearson. Um coeficiente de -1 indica forte correlação negativa, +1 indica forte correlação positiva e zero significa que não há correlação.
https://gist.github.com/avivl/ed30a0c2d1978ea4eaa0f6b9c51ec5b6
price_wait,price_communication,price_quality
0,679, 0,774, 0,793
Como dá para ver, a satisfação tem maior correlação com o preço e a qualidade do produto. Mas será que dá para confiar nas notas? Avaliações online costumam sofrer com o viés de autosseleção. Vamos checar se as avaliações da Telegrass têm o mesmo problema.
https://gist.github.com/avivl/e9ecfdb9342a23af9a6515b40d581e4e
Pelos resultados, ou nossos vendedores são impecáveis em todos os quesitos, ou existe algum viés nas notas dos usuários — ou, quem sabe, depois de consumir o produto as pessoas ficam mais positivas mesmo☺️
Agora vamos ver quais são os bigramas mais populares e se eles têm relação com as notas altas.
https://gist.github.com/avivl/0e6ddbfdf1d7a4ee3d16c60bb0d18708
Os bigramas mais populares são:
- Cara incrível
- Produto sensacional
- Altamente recomendado
Dá para notar uma alta correlação entre as notas elevadas e os bigramas mais comuns nas avaliações.
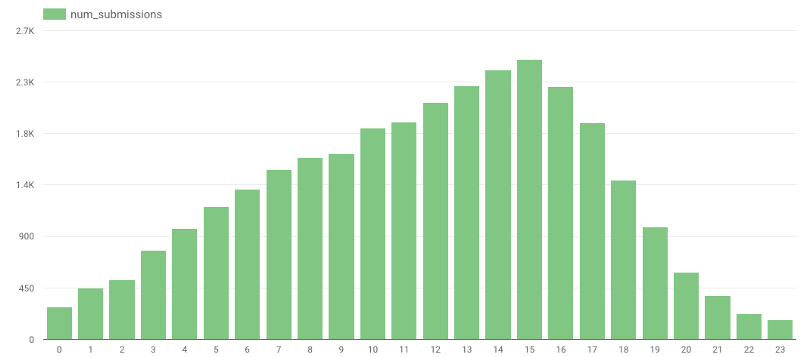
Você consegue adivinhar qual é o horário mais comum para enviar uma avaliação? Se eu tivesse que chutar, diria que é no final da noite ou de madrugada — mas os dados reais me desmentiram:
https://gist.github.com/avivl/8e7e828509407676ba129c1f376a06a6
Agora vamos verificar se existe correlação entre o tamanho da cidade e o número de avaliações. Vamos começar pegando as 20 cidades que mais geram avaliações. Os resultados vão para uma nova tabela (by_city).
https://gist.github.com/avivl/84b0b258e47236b30d298e05f0335e74
Agora adicionamos uma nova coluna de população e a preenchemos com dados do Instituto Central de Estatística de Israel (referentes ao final de 2016). Vamos aos resultados:
Antes de comparar os números, uma coisa salta aos olhos. Quase 1% da população de Tel-Aviv escreve avaliações na Telegrass! — e não estamos falando de quem só usa o produto ou compra, mas de quem participa ativamente.
Vamos olhar o primeiro e o último colocados. Se você conhece um pouco da demografia de Israel, não vai estranhar. Tel-Aviv tem população jovem, é um polo de empresas de tecnologia e a cidade mais liberal do país. As pessoas são bem antenadas em tecnologia e gostam de dar opinião. Na lanterna aparece Bnei Brak, uma cidade dominada por uma população religiosa de baixa renda, o que explica por que quase ninguém escreve avaliações.
Agora é hora de brincar um pouco com ML usando o TensorFlow. Primeiro, criei um conjunto de treinamento e outro de teste.
https://gist.github.com/avivl/92454358fc144da18e0f3a0c962fe5ea
Peguei o código escrito pelo Akshay Pai e adaptei às minhas necessidades.
Depois de carregar e preparar os dados, o código de ML ficou assim:
https://gist.github.com/avivl/3f3e876286670e19698a4bcc60f2313d
Concluído o treinamento, usei o model.predict para prever a pontuação.
https://gist.github.com/avivl/70a83e35793d3800e6c1d25fc55f97e0
Carreguei o conjunto de teste e calculei o RSME. O RMSE ficou em 1,4, e os valores variam de 0 a 20 — não é um resultado espetacular, mas dá para prever razoavelmente bem, a partir do texto, qual será a nota numérica.
Você não precisa ser um cientista ou engenheiro de dados de carteirinha para tirar insights interessantes de um texto não estruturado, sem escrever uma única linha de código para preparar os dados. Depois, é só analisar tudo no BigQuery e no TensorFlow para chegar a conclusões valiosas.