
はじめに一点お断りを。DoiT Internationalは、合法・違法を問わずいかなる薬物使用も推奨・容認・支持しません。
イスラエルでは嗜好目的のマリファナ使用は違法です。しかし、需要のあるところには必ず供給が生まれます。Telegrassは、イスラエルでマリファナを購入するためのネットワークです。エンドツーエンドで暗号化された無料チャットアプリTelegram上で運営されており、迅速な配達に加え、売り手へのレビュー投稿も可能です。Telegrassの月間取引額は1,700万ドルにのぼると推定されています。
ユーザーは売り手のレビューを参考にして、購入先をより的確に選べます。レビュー投稿用のボットが用意されており、以下の4項目について0〜5の範囲で売り手を評価する仕組みです。
- 売り手とのやり取りはどうだったか
- 商品の品質はどうだったか
- 価格は妥当だったか
- 時間どおりに配達されたか
データの取得
まずはTelegramからレビューを取得していきます。利用するのは、Telegram APIを扱うPythonライブラリtelethonです。レビューは(人の手によるチェックを経たうえで)ボットが投稿するため、メッセージのメタデータは特に重要ではなく、本文だけが必要になります。
https://gist.github.com/avivl/884ec584b19f4c079153e2f5891181a6
設定ファイルはこちらです。
https://gist.github.com/avivl/007efb0db4a2ebcf5539f054bc82a5d8
では実行してみましょう。
python geth.py >reviews.txt
出力は次のような形になります。
[‘ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע’, ‘חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17’, ‘חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.’, ‘\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)’, ‘להגשת חוות דעת: @TelegrassBot לשירותכם!’]
ご覧のとおり(現代ヘブライ語が読めなくても)、文字・記号・数字が明確な構造もないまま入り混じっています(ヘブライ語は英語と異なり右から左に書く言語である点も念頭に置いてください)。次のステップでは、このデータを分析向けに整える必要があります。
データの準備
クエリや分析を行う前に、データをクリーニングし、より構造化された形に整える必要があります。
とはいえ、そのためのコードを自分で書くのは試行錯誤の連続で、非常に時間がかかる退屈な作業です。幸い、Googleの新サービス(まだベータ版ですが)Cloud Dataprepがあります。製品サイトから引用します。
「Google Cloud Dataprepは、構造化・非構造化データを視覚的に探索・クリーニングし、分析用に整えるためのインテリジェントなデータサービスです。サーバーレスでどんな規模にも対応し、デプロイや管理が必要なインフラはありません。クリック操作だけで、コードを書かずに簡単にデータを準備できます。」
レビューデータはDataprepにとって手強い相手になりそうだと感じていましたが、結果として、わずか60ステップ程度のシンプルな操作(以下に列挙)で、しかも一行もコードを書かずに、評価データから構造化データを作り出せました。DataPrepのUIは変換結果をリアルタイムで確認できるため、視覚的にデバッグしながらプロセスを調整できます。文字やパターンに基づいてデータを分割したり、無効な値を含む行を削除したりするステップもありました。
さらにCloud Dataprepは、結果データをさまざまなデータソースへ書き出す機能を標準で備えています。今回はGoogleのサーバーレス分析データベースであるGoogle BigQueryを選びました。
https://gist.github.com/avivl/3ec0d5fb38f054c8a7e8b673148321c7
これでデータがきれいに整いました。
 Google Cloud DataprepのUI画面
Google Cloud DataprepのUI画面
分析
データが整ったら、いよいよ分析です。まずはBigQueryのCORR()関数で、価格と他の評価項目との関係を見てみましょう。この関数はピアソンの相関係数を算出します。係数が-1なら強い負の相関、+1なら強い正の相関、0なら相関なしを意味します。
https://gist.github.com/avivl/ed30a0c2d1978ea4eaa0f6b9c51ec5b6
price_wait,price_communication,price_quality
0.679, 0.774, 0.793
このとおり、満足度に最も強く相関しているのは価格と商品の品質でした。では、この評価は信頼できるのでしょうか。オンラインの評価は自己選択バイアスの影響を受けやすいことが知られています。Telegrassのレビューにも同じ傾向があるか確認してみましょう。
https://gist.github.com/avivl/e9ecfdb9342a23af9a6515b40d581e4e
結果から考えられる解釈は3つです。売り手が本当にあらゆる面で素晴らしいか、ユーザー評価に何らかのバイアスがあるか、あるいは商品を使った後の人はポジティブになりやすいのかもしれません☺️
続いて、最も多く登場するバイグラム(2語の組み合わせ)と高評価との相関を見てみましょう。
https://gist.github.com/avivl/0e6ddbfdf1d7a4ee3d16c60bb0d18708
最頻出のバイグラムは次のとおりです。
- Amazing man(すごい人)
- Awesome product(素晴らしい商品)
- Highly recommended(おすすめ)
高スコアと、レビュー内で頻出するバイグラムとの間には強い相関が見られます。
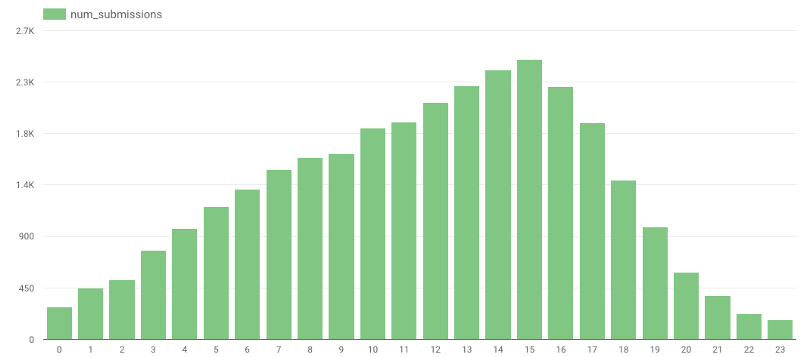
レビューが最も多く投稿される時間帯はいつだと思いますか? 直感的には夜遅くか深夜あたりかと思いきや、実際のデータは予想を裏切るものでした。
https://gist.github.com/avivl/8e7e828509407676ba129c1f376a06a6
次に、都市の規模とレビュー数の間に相関があるかを確認します。まずレビュー件数の多い上位20都市を取得し、結果を新しいテーブル(by_city)に追加します。
https://gist.github.com/avivl/84b0b258e47236b30d298e05f0335e74
続いてpopulation列を追加し、イスラエル中央統計局のデータ(2016年末時点)を入れていきます(populateにかけたダジャレです)。結果を見てみましょう。
結果を比較する前に、ひとつ目を引く事実があります。テルアビブの人口の約1%が、Telegrassでレビューを書いているのです! 単に商品を使ったり購入したりするだけでなく、能動的に参加していることになります。
上位と下位の結果を見てみましょう。イスラエルの人口動態を多少ご存じの方なら、これは特に意外ではないはずです。テルアビブは若年層が多く、ハイテク企業が集積する、イスラエルで最もリベラルな都市です。住民はテクノロジーに詳しく、意見表明にも積極的です。一方、最下位はBnei Brakでした。低所得層の宗教的住民が多数を占める街であり、レビュー投稿者が少ない理由は明白でしょう。
では、TensorFlowを使った機械学習にも少し触れてみましょう。まずはトレーニングセットとテストセットを作成しました。
https://gist.github.com/avivl/92454358fc144da18e0f3a0c962fe5ea
Akshay Pai氏のコードを、用途に合わせて少し手直しして使いました。
データを読み込んで前処理した後の機械学習コードがこちらです。
https://gist.github.com/avivl/3f3e876286670e19698a4bcc60f2313d
学習が終わったら、model.predictでスコアを予測します。
https://gist.github.com/avivl/70a83e35793d3800e6c1d25fc55f97e0
テストセットを読み込んでRMSEを算出した結果は1.4でした。値の範囲は0〜20なので圧倒的な精度とは言えませんが、テキストから数値評価をかなりよく予測できていることが分かります。
本職のデータサイエンティストやデータエンジニアでなくても、非構造化テキストから興味深い知見を引き出すことができます。しかも、分析の前処理にコードを一行も書く必要はありません。あとはBigQueryとTensorFlowで分析を進めれば、さらに面白いインサイトが得られます。